
基于深度卷积神经网络的红外场景理解算法
2017-03-22 10:18汤心溢高思莉
红外技术 2017年8期
王 晨,汤心溢,高思莉
基于深度卷积神经网络的红外场景理解算法
王 晨1,2,3,汤心溢1,3,高思莉1,3
(1. 中国科学院上海技术物理研究所,上海 200083;2. 中国科学院大学,北京 100049;3. 中国科学院红外探测与成像技术重点实验室,上海 200083)
采用深度学习的方法实现红外图像场景语义理解。首先,建立含有4类别前景目标和1个类别背景的用于语义分割研究的红外图像数据集。其次,以深度卷积神经网络为基础,结合条件随机场后处理优化模型,搭建端到端的红外语义分割算法框架并进行训练。最后,在可见光和红外测试集上对算法框架的输出结果进行评估分析。实验结果表明,采用深度学习的方法对红外图像进行语义分割能实现图像的像素级分类,并获得较高的预测精度。从而可以获得红外图像中景物的形状、种类、位置分布等信息,实现红外场景的语义理解。
红外图像;红外场景;语义分割;卷积神经网络
0 引言
图像语义分割能实现对输入图像每个像素进行分类,是对图像中的场景进行理解,广泛应用于机器人视觉、汽车辅助驾驶等领域,是现在国内外的研究热点。随着深度学习算法的不断发展,在诸多图像检测和识别方面取得比传统算法更高的精确度。采用深度卷积神经网络,可以实现端到端的语义信息预测,得到图像像素级的类别标签,并取得了更高的预测精度。Jonathan Long在CVPR 2015会议上提出了全卷积神经网络(FCN)[1],首次实现了端到端的语义分割卷积神经网络框架,达到了当时最高的预测精度。S. Zheng等人在ICCV2015会议上,提出CRFasRNN[2],将后处理conditional random field(CRF)算法表征成可训练的循环卷积网络结构,加入深度语义分割框架,在一个端到端的网络实现了对语义分割结果的边缘进一步优化,提高了在PASCAL VOC数据集上的预测精度。ICLR2015会议上,Liang-Chieh Chen等人将FCN结构进一步改进,Deeplab[3]框架大幅度减小了框架参数,提高了训练和预测速度,并采用全连接CRF方法对预测图进行后处理优化,进一步提高了语义分割的精度。Hyeonwoo Noh采用了卷积与反卷积对称的网络结构[4],并加入基于bounding box的前处理目标预估计方法,再一次刷新了预测精度。PASCALVOC作为目标检测和语义分割算法研究权威的竞赛平台,随着新的算法的提出,预测精度一直在刷新。
国际上对语义分割方法的研究主要是针对可见光图像的。然而,在实际应用中,由于可见光图像的采集受到光照、天气等条件影响,具有一定的局限性。红外图像作为热图像,能在光照条件较差的环境下弥补可见光成像效果差的不足,同时,红外探测系统在军事、航天等特定领域也具有广泛应用。因此,对红外图像进行场景理解具有重要意义。目前,公开发布的用于场景理解、语义分割算法研究的数据集主要是可见光图像,还没有相关的红外数据集。笔者参考PASCAL VOC和Cityscapes数据集的设计,建立了用于红外图像场景理解研究的数据集,并对红外图像的深度卷积神经网络语义分割算法进行研究。在红外数据集上采用深度卷积神经网络上实现了红外图像的语义分割,实现了对场景中景物像素级的分类,并采用交叉验证法对模型进行评估。证明了基于深度卷积神经网络的语义分割算法框架在红外图像场景理解上的可行性和有效性。
1 红外数据集建立
红外数据集采用“初航”红外探测器,在室外场景下采集街道场景图像,并对包含的4类别景物,采用4种固定灰度值进行人工标注。4类别景物包括:人、汽车、建筑、树木,类别号1~4表示(对每个类别细分的种类不作区分),1个背景,类别号0。如图1所示,为红外图像和对应的人工标签图。
1.1 红外图像预处理算法
原始数据为14bit,为了显示和制作标签图,采用预处理算法压缩成8bit图像。红外图像是景物的热辐射图像,图像的动态范围较大、噪声较大,图像中存在过亮和过暗的区域。采用基于整幅图像的增强算法,会受到这些区域的影响,造成图像的整体灰度偏暗或偏亮,造成细节的模糊。为了更好的显示红外图像,突出目标细节、抑制噪声,采用基于局部直方图增强的压缩算法能很好地满足需求。预处理算法由图像压缩和增强算法组成。
步骤1:对14bit红外数据进行直方图统计,采用阈值为20,宽度为10的滑动窗口对统计直方图进行截断,去除掉连续10个灰度值,所含像素个数均小于20的灰度范围,得到像素分布集中的灰度范围[min,max]。
步骤2:对红外图像进行线性映射到[0,255]。映射方程:

步骤3:采用限制对比度自适应直方图均衡增强算法(CLAHE)[5]对映射后的图像进行增强处理。得到8bit红外增强图像。
图2为采用基于全局直方图统计的图像压缩算法和本文算法的处理结果。相比之下,本文算法能更好地平衡图像整体的灰度,抑制过亮和过暗区域对全局显示的影响,更好地增强了低对比度区域的景物细节,限制了噪声的放大,得到细节清晰、视觉效果较好的红外灰度图像。
1.2 红外数据集参数
数量:1000张
尺寸:640×512
内容和格式:14bit原始数据“.mat”;8bit红外图像“.jpg”;彩色标签图“.png”;类别号标签图“.png”。

图1 红外数据集样本
Fig.1 Sample of infrared image datasets

图2 压缩效果对比
Fig.2 Comparison of compression results
2 深度卷积神经网络语义分割框架
2.1 语义分割框架原理
语义分割算法框架主要由深度卷积神经网络和条件随机场模型两部分构成。分别实现分割预测和分割结果的优化处理。语义分割框架是通过对传统卷积神经网络框架的修改获得的。传统卷积神经网络由卷积层、池化层后接全连接层,送入Softmax分类器进行分类。全连接层使得输出丢失了空间信息。将全连接层看作用覆盖原有输入区域的卷积核进行卷积。可以得到更为紧致的包含空间信息的输出图。卷积与池化操作使得得到的特征图尺寸缩小,为了得到与输入图像尺寸相同的预测图,框架引入反卷积层,采用双线性插值的方法对特征图进行上采样操作,可以得到与分类器类别数量个数相同的预测得分图,通过取最大操作,得到每个像素的类别评分最高的预测图。从而实现图像的语义分割。如图3所示,是采用卷积神经网络实现图像语义分割的基本流程。
2.2 初始化模型VGG-16简介
VGG-16[6]网络在ImageNet ILSVRC-2014竞赛中在定位和分类分别取得第一、二名的成绩。网络结构包含16个可训练参数层,如表1所示。此网络参数模型是在Imagenet数据集上进行训练得到的,经验证,作为语义分割框架的初始化模型,比AlexNet和GoogleNet取得更高的预测精度。
2.3 框架结构改进
对VGG网络结构进行了改进,在全卷积神经网络的框架的基础上,改变网络的步长大小,采用Hole算法改变连接方式,保证感受野的不变,不需要FCN的大尺度扩充,正常扩充下能得到更为紧致的预测图[3]。将该模型训练成一个更有效率和有效的紧致特征提取器,实现图像语义分割系统。框架主要做了如下改变:
2.3.1 Hole算法实现的紧致滑动窗特征提取器
同FCN框架一样将VGG-16网络的全卷连接层用卷积层替换,为了解决大步长32造成的预测评分图过于稀疏的问题,通过更改倒数两个池化层的步长,将步长减小到8。采用Hole算法,算法原理如图4,在保证感受野不变的同时跳过后两个池化层后的下采样,在其后面卷积层的滤波器像素与像素之间补0,来增加其长度。

图3 语义分割算法流程

表1 VGG-16框架

图4 hole算法示意图
2.3.2 框架计算加速
转换为卷积层的第一个全连接层,含有尺寸为7×7的滤波器4096个,减小其滤波器尺寸到4×4(或3×3),减小了网络的感受野尺寸。使得第一层全连接层的计算时间减小2~3倍。将全连接层的通道数减半到1024,在保证框架计算结果的情况下,进一步降低了计算时间和内存用量。
2.4 全连接条件随机场模型
由于语义分割框架采用对稀疏预测图进行上采样操作得到预测图,景物的边缘分割比较粗糙,预测精度较低。通常,CRF来平滑粗糙的分割预测结果图。
模型的能量函数[7]:

表示像素的标签。一元的势能(x)=-lg(x),(x)是由DCNN计算得到的标签概率。对于图像中一对像素,他们的成对势能是:
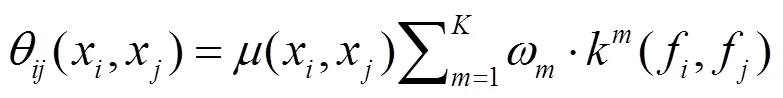
如果x¹x,(x,x)=1,其余条件,等于0。模型的因子图是全连接的,因为图像中任意两个像素组成像素对。每一个m是一个高斯核,由像素和决定其参数,参数m决定权重。核函数:
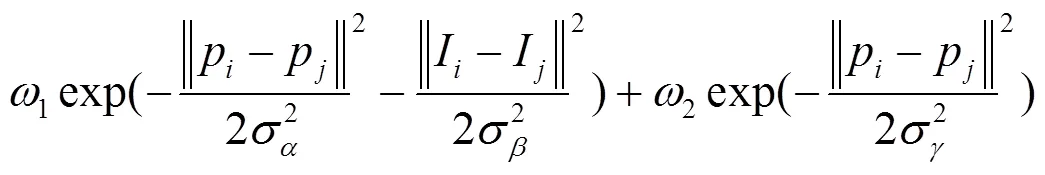
第一个核表示像素的位置和灰度信息,第二个核只表示像素的位置信息。超参数,和决定了高斯核的尺度。接着采用一个可分解的平均场近似方法,可以将CRF模型中信息的传输表示为在特征空间进行高斯核卷积操作。能大幅度降低运算复杂度、提升运算速度。
3 实验和评估
3.1 数据集
为了弥补自建数据集样本数量的不足,采用Cityscapes[8]数据集先进行预训练,再用红外数据集进行再训练。Cityscapes数据集主要用于城市街道场景境的语义理解,数据集内包含可见光彩色图像和标签图,其中训练集2975张,测试集500张,图像大小2048×1024。含有景物类别30种,包括道路,行人、小汽车、摩托车、植物、建筑、天空等。我们提取其中包含的8种景物的2973张图,将8种景物为4个大类别,人:人、骑行者;汽车:小汽车、公交车、卡车;建筑:房屋、墙;树木:植物。与我们建立的红外数据集相匹配。为了加快训练速度,将数据集的图像转换为灰度图像,并将原始图像和标签图尺寸缩小到1024×512。红外数据集包含1000个样本,随机抽取800个作为训练集,其余200个作为测试集。
3.2 训练
我们先用VGG-16模型在Cityscapes数据集进行训练,训练参数为:分类输出大小5(4类别和背景),mini-batch为5,初始化学习率0.001,每2000次循环,学习率乘以0.1,向量值0.9,权值衰减0.0005。训练8000次循环,得到模型1。然后,将模型1作为初始化模型,在红外数据集进行再训练。每4000次学习率乘以0.1,其他参数保持不变,训练8000次、16000次得到模型2,3。红外图像训练速度:0.33ms/frame。本实验在Ubuntu14.04系统上采用Caffe框架实现,采用CUDA进行处理,GPU型号:NVDIA GM200,内存12G。
3.3 评估
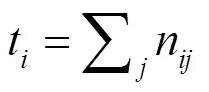



频率加权IU:

交叉验证法:由于红外数据集图像较少,采用5折交叉验证的方法在红外数据集上进行训练和验证,增加算法的随机性和客观性。将全部红外图像随机分成5份,轮流将其中4份作为训练集,1份作为验证集。5次计算结果的均值作为对算法精度的估计,见表2、表3。
3.4 结果分析
图5展示了深度卷积语义分割网络对红外图像的处理结果。从可视化结果上看,采用该算法框架得到比较理想的预测结果,分割结果与人工标注标签图比较相近,可以实现不同类别景物的分割和分类。在可见光和红外数据集训练8000次循环的模型1、2,mean IU分别达到0.670和0.531,见表2。当训练循环次数达到16000次,mean IU显著提高,达到0.719,见表2。加入CRF优化模型,预测精度结果变化不大,部分反而有所下降。但是从可视化结果看,采用CRF模型进行后处理,对目标的边缘精确度有显著提升,更接近标签图,但同时造成了部分边缘区域分割的错误。目前,在可见光数据集Cityscapes上,最好的模型SegModel,达到的mean IU为0.777,仅作为参照。

表2 预测精度对比

表3 红外数据集各类别IU结果

图5 语义分割结果
Fig.5 Semantic segmentation results
存在的问题:不同类别的景物分割精度存在差异,较大的物体,如汽车、建筑、树木,获得的分割精度较高,“人”所占空间比例较小,训练不够充分,预测精度较低。IU只有0.556,见表3。因此拉低了平均IU。对于像“人”这样的物体,占的像素较少,形态变化大,预测精度低,如何提高此类景物的预测精度,有待进一步研究和解决。CRF优化模型在可见光彩色图像的语义分割实验中,对预测精度提升明显。由于红外图像是灰度图像,没有颜色信息,边缘模糊,纹理缺失,采用CRF模型进行后处理优化边缘,有一定局限性,后处理算法有待进一步改进。
4 结论
为了实现红外图像场景的理解,本文将广泛用于可见光图像分析的深度学习语义分割算法框架应用于红外图像。通过自建红外数据集、在Caffe深度学习框架上构建基于深度卷积神经网络结合条件随机场模型构建算法框架,在红外数据集上对算法进行验证和评估。证明了深度学习算法在红外图像语义分割上的可行性和有效性。对于输入的红外图像,可以获得图像中每个像素的类别标签。进而,可以得到图像场景中景物的类别、位置分布、形状、占有的比例等信息,实现图像场景的高级语义理解。通过实验结果的观测和分析,对于较大的物体,如树木、建筑等,语义分割效果较好。一些特征比较复杂,所占像素较少的景物,如“人”,分割精度比较低。从模型架构和训练参数调整两方面进行优化和改进,提高此类景物的语义分割精度,并实现整体平均预测准确度的提高,是我们下一步要解决的问题。
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//, 2015: 1337-1342.
[2] Zheng S, Jayasumana S, Romeraparedes B, et al. Conditional random fields as recurrent neural networks[C]//, 2015:1529-1537.
[3] Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]., 2014(4):357-361.
[4] Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation[C]//, 2015: 1520-1528.
[5] Pizer S M, Amburn E P, Austin J D, et al. Adaptive Histogram equalization and its variations[J].,,, 1987, 39(3): 355-368.
[6] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[2014] [DB/OL]. arXiv preprint arXiv: 1409.1556.
[7] Krähenbühl P, Koltun V. Efficient Inference in fully connected CRFs with Gaussian edge potentials[C]//, 2012:109-117.
[8] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//, 2016: 3213-3223.
Infrared Scene Understanding Algorithm Based on Deep Convolutional Neural Network
WANG Chen1,2,3,TANG Xinyi1,3,GAO Sili1,3
(1.,200083,;2.,100049,;3.,,200083,)
We adopt a deep learning method to implement a semantic infrared image scene understanding. First, we build an infrared image dataset for the semantic segmentation research, consisting of four foreground object classes and one background class. Second, we build an end-to-end infrared semantic segmentation framework based on a deep convolutional neural network connected to a conditional random field refined model. Then, we train the model. Finally, we evaluate and analyze the outputs of the algorithm framework from both the visible and infrared datasets. Qualitatively, it is feasible to adopt a deep learning method to classify infrared images on a pixel level, and the predicted accuracy is satisfactory. We can obtain the features, classes, and positions of the objects in an infrared image to understand the infrared scene semantically.
infrared images,infrared scene,semantic segmentation,convolutional neural network
TP391.41
A
1001-8891(2017)08-0728-06
2016-10-06;
2016-10-31.
王晨(1989-),博士研究生,主要研究方向是图像处理与目标识别。E-mail:ilkame@sina.com。
国家“十二五”国防预研项目,上海物证重点实验室基金(2011xcwzk04),中国科学院青年创新促进会资助(2014216)。
猜你喜欢
环球时报(2022-05-23)2022-05-23
小资CHIC!ELEGANCE(2022年1期)2022-01-11
金桥(2021年4期)2021-05-21
数学物理学报(2020年3期)2020-07-27
开放教育研究(2020年2期)2020-03-31
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
