
基于USGS生命周期模型的肿瘤流行病学数据管理研究
2017-03-21 06:06,,,
中华医学图书情报杂志 2017年12期
, , ,
随着“开放科学、开放数据”的推进与发展,以及科学数据共享协议的实施,科学数据共享的生态环境正在形成,数据管理、信息组织的研究与实践面临机遇与挑战[1]。由于海量开放数据标准不一,科研人员和相关领域决策者想要快速找到可比较、可分析的数据并不容易。因此,如何实现相关领域海量数据的有效管理与整合变得非常重要。
信息时代每天都会产生大量的新数据,新数据将旧数据淹没或覆盖,许多极具潜在价值的数据未能得到有效保存和管理,数据的利用率非常低。目前流行病学数据管理方法尚未形成统一的标准和模型,各医院临床数据管理中心开发的数据管理平台也不尽相同,无法实现数据的统一管理和分析。因此需要制定全面的数据管理计划,实现对海量数据进行科学化管理,即从数据采集、保存和共享的全过程进行数据管理,以确保数据得到良好的描述、存储,实现可访问、可重复利用,为研究人员重新使用和理解数据奠定基础。
近年来,恶性肿瘤的发病率不断攀升,恶性肿瘤已经成为我国乃至全世界最重要的公共卫生问题之一。
国家癌症中心发布的中国癌症报告显示,2013年我国癌症发病率为284.55/100 000,即平均每10万人就有284人新发癌症,癌症负担十分严重[2-3]。因此,本文选取肿瘤流行病数据作为分析对象,对科学数据的获取、处理、分析等环节进行管理研究,详细阐述数据从采集到发布的全生命周期,为相关科研人员进行科学数据的有效管理与整合提供借鉴,为科学数据的再利用、数据价值的再创造提供参考。
1 科学数据生命周期管理模型选型分析
对于规范化管理各类科学数据已有诸多相关研究,如科学数据众包处理研究[4],国内外开放科学数据的分布及特点分析[5],科学数据共享模式选择与情景分析[6],大数据环境下的科学数据共享模式研究[7]等。不同组织机构根据管理对象和使用场景提出了若干数据生命周期模型,如DCC审编生命周期模型(DCC Curation Lifecycle Model)[8]、UKDA数据生命周期模型(UK Data Archive Data Lifecycle)[9]、DataONE数据生命周期模型(DataONE Data Lifecycle)[10]、USGS科学数据生命周期模型(The USGS Science Data Lifecycle Model)[11]等。这些模型分别从不同角度描述了数据从产生、收集、描述、存储、发现、分析到再利用的生命周期[12]。其中,由英国数字审编中心(Digital Curation Center,DCC)提出的DCC审编生命周期模型,可指导机构或组织制定数据管理活动方案、构建标准与技术框架等,其适用对象是数据库;由英国数据仓储(UK Data Archive,UKDA)提出的UKDA数据生命周期模型,是面向社会经济研究数据的一种环形结构;由DataONE领导团队(DataONE Leadership Team)和DataONE社区共同提出的DataONE数据生命周期模型,是面向环境科学数据的一种环形结构。
由美国地质调查局(U.S.Geological Survey,USGS)提出的USGS科学数据生命周期模型,是密切围绕科学研究的全生命周期的一种链式结构,其适应对象为各领域科学数据。
USGS是面向科研过程提出的一种用来指导和说明数据管理活动与项目流程的框架,涵盖了研究数据从概念、保存到共享的全过程[13],包括数据管理计划、数据获取、数据处理、数据分析、数据保存、数据出版与共享6个关键环节。各环节可相互协作形成有机整体,亦可根据需要进行调整,以适应不同领域的应用(图1)。USGS模型可以为管理人员评估和改进科学数据的管理方法提供帮助,为科研人员做好数据的整合与管理工作提供指导,进而促进科学数据管理的发展。

图1 USGS数据生命周期模型
2 基于USGS的肿瘤数据生命周期管理模型构建
考虑到肿瘤领域科学数据数量大、来源多样、标准不一等特点,本文以USGS数据管理生命周期模型为指导框架,初步构建了肿瘤科学数据的管理流程。具体流程见图2。
2.1 数据管理计划
数据管理计划是用于描述整个数据生命周期内数据处理及相关质控的规范性文档,包括数据获取、处理、分析、存储、发布与共享的全过程,其主要目的是保证研究数据的完整性和可用性。基于USGS数据生命周期模型,制定肿瘤科学数据的管理计划和元数据标准,整合、分析不同来源的科学数据,帮助相关人员统筹项目“开始-发布-归档”过程中与肿瘤数据有关的所有活动,应对各阶段的评估、处理和记录要求,考虑每个阶段的方法、所需资源以及预期产出等。

图2 肿瘤科学数据生命周期模型构建流程
2.2 数据获取
USGS数据管理模型认为,以数据的可靠性和完整性为目标的数据获取是确保数据处理、分析以及评估数据可重复再利用的关键。鉴于此,管理人员应根据肿瘤数据源的特性,利用爬虫工具、ETL工具、数据提交工具等从世界卫生组织(World Health Organization,WHO)癌症研究中心(International Agency for Research on Cancer,IARC)、中国肿瘤登记年报等官方渠道采集肿瘤科学数据,进行数据去重、完整性评估、缺失值处理等工作,并将数据存储在数据库中。
2.3 数据处理
数据处理是对所获取数据(包括定义数据元素,整合不同数据集,提取、转换和加载等)进行的操作,目的是为后续集成和分析做准备。由于肿瘤科学数据来源多样、标准不一,管理人员需要构建数据整合标准化模型,使用各类自动化工具开展多样化的数据处理工作(包括数据标准化、噪音数据清洗、数据匿名化、数据分类、构建整合数据集等),形成各类派生数据,进而为数据的后续使用提供标准及基础。USGS数据管理模型可以实现医学数据与人口数据、气象环境数据、地理信息数据等其他类型数据的整合,为后续开展跨学科、跨领域的数据分析和服务提供支撑和保障。
2.4 数据分析
数据分析是探索、阐释上述经过处理的数据的相关活动(包括总结、制图、统计分析、建模、假设检验、科学发现、得出结论等),从而形成不同层面的派生数据集,为科研人员提供多元化的数据服务。本文选取USGS数据管理模型对肿瘤发病数据集和相应的人口数据集进行整合分析,进而比较不同地区、不同年龄段、不同性别之间的肿瘤发病情况和趋势变化,为肿瘤流行病学研究及政策制定提供借鉴。
2.5 数据存储
数据存储是保证数据可长期使用和可访问的基础,是数据管理过程中最为重要也是最易被忽视的环节之一。在项目或任务前期和中期执行过程中,数据存储的重要性不言而喻;而在后期或项目结束后,由于预算、人力、时间等原因,数据有可能会被忽视、丢弃或损坏。为此,管理人员必须参照USGS模型,制定相关政策和标准,以促使科研人员长期保存肿瘤科学数据、元数据、辅助产品、附加文档等,确保相关数据的完整性、可用性和重用性,为后续的科学研究提供便利,发挥数据的潜在价值。
2.6 数据发布与共享
随着互联网、物联网以及新媒体技术的快速发展,数据发布的渠道更为多样化,数据共享更为便捷。数据同传统出版物一样可作为研究成果,其发布和共享亦是项目和任务的重要组成部分。管理人员应遵从USGS模型的相关准则对肿瘤科学数据进行共享和发布,提供数据的浏览、下载、分析等服务,为科研人员开展更为深入的研究节约时间,促进肿瘤知识的有效转化。
3 肿瘤科学数据管理的应用研究
基于USGS数据生命管理周期模型对肿瘤流行病学发病数据和对应的人口数据进行整合、分析、管理(包括制定数据管理计划、数据获取、数据处理、数据分析、数据存储、发布与共享等步骤),为相关人员做好数据整合与管理工作提供参考和借鉴。
3.1 数据管理计划
借助USGS科学数据生命周期模型进行癌症科学数据的管理,结合实际需求对USGS数据生命周期模型进行适当调整,制定详细的数据管理计划(图3)。首先,获取癌症科学数据,解读数据集的内容、格式等;其次,根据数据集的具体情况进行整合,初步分析数据;第三,通过科学的计算方法对数据进行再加工;最后对处理后的数据进行对比、分析和使用,并做好数据的存储和再利用。
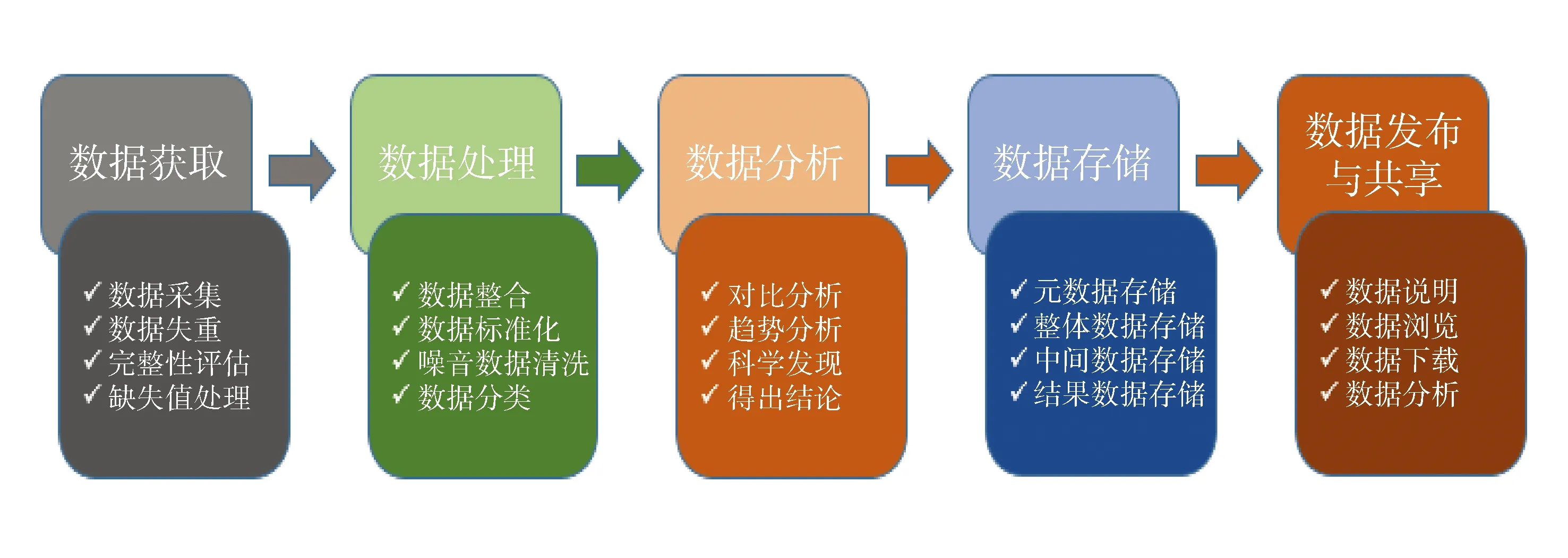
图3 癌症发病科学数据管理计划
3.2 数据获取
基于现有数据的开放程度、完整性及权威性考虑,选取IARC发布的五大洲癌症发病数据集CI5plus(Cancer Incidence in Five Continents Time Trends,http://ci5.iarc.fr/CI5plus/Default.aspx)进行整合分析。CI5plus数据集包含了截至2007年,118个地区的癌症发病数据以及与118个地区对应的人口数据。考虑到实际入选CI5数据集的时间、地域特征、代表性等因素,本文选取上海市和浙江省嘉善县1993-2007年的癌症发病数据和相应的人口数据进行整合、处理和分析。部分来源数据见表1和表2。
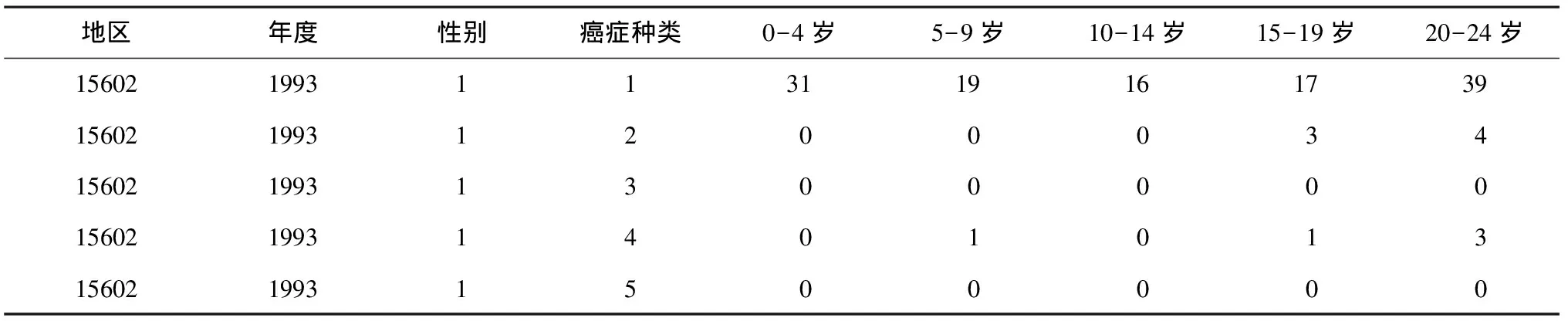
表1 上海1993年不同部位癌症在不同年龄段的发病人数

表2 上海1993-1997年不同性别在不同年龄段的人口数
其中,表1为1993年上海地区(地区编号为“15602”)不同部位癌症(如列CANCER中“4”代表“胃”)在不同年龄段(如“N5_9”为5-9岁)的发病人数分布情况,表2为1993-1997年上海不同性别(列性别中“1”为男性,“2”为女性)在不同年龄段的人口数。
3.3 数据处理
为了直观、全面地对上述原始数据进行对比分析,本文使用流行病学研究方法,分别从地区、癌症类别、年龄组、性别等维度对已有数据进行了整合。数据整合后,可以直观地了解到各地区不同年度、不同性别、不同癌症、不同年龄组的发病总数。如对表1中上海地区1993年男性各年龄段、各部位癌症的发病数据(即所有地区编号为“15602”、年度为“1993”、性别为“1”的数据项)进行整合,可得到1993年上海地区男性总发病人数为19 496。整合后的部分数据见表3(性别列“1”为男性,“2”为女性)。同时对各地区人口总数也进行了相应整合。
对人口和发病数据初步整合后,能够直观了解各地区、各年度、各癌症类别、各年龄组的发病情况,但还不能满足对不同地区、不同时期发病情况的对比分析和趋势分析要求。

表3 上海1993-1997年各性别的癌症发病总人数
为了实现这一目的,本文通过计算恶性肿瘤的发病率使其标准一致,从而具有可比性。本文所指的发病率为粗发病率,即某年该地登记的每10 万人口中恶性肿瘤的新发病例数,是反映人口发病情况最基本的指标。
按照上述公式计算各地区恶性肿瘤的发病率,均保留小数点后两位。如上海1993年男性的发病率为565.11/10万,即每10万人就有约565人新发癌症,其他年度发病率如表4所示。

表4 1993-2007年上海和嘉善恶性肿瘤发病率
3.4 数据分析
通过对比分析1993-2007年的发病率,可以发现上海恶性肿瘤发病率明显高于嘉善。随着时间的推移,两地发病率都呈逐年上升趋势,如2007年嘉善总发病率已上升至623.08/10万,比1993年上升了约77%(图4)。
另外,嘉善女性的发病率在同期均为最低,但其涨幅最为明显,相关部门应尽快采取措施控制嘉善地区女性发病增长速度。上海地区肿瘤发病率变化虽然较小,但发病率一直居高不下。
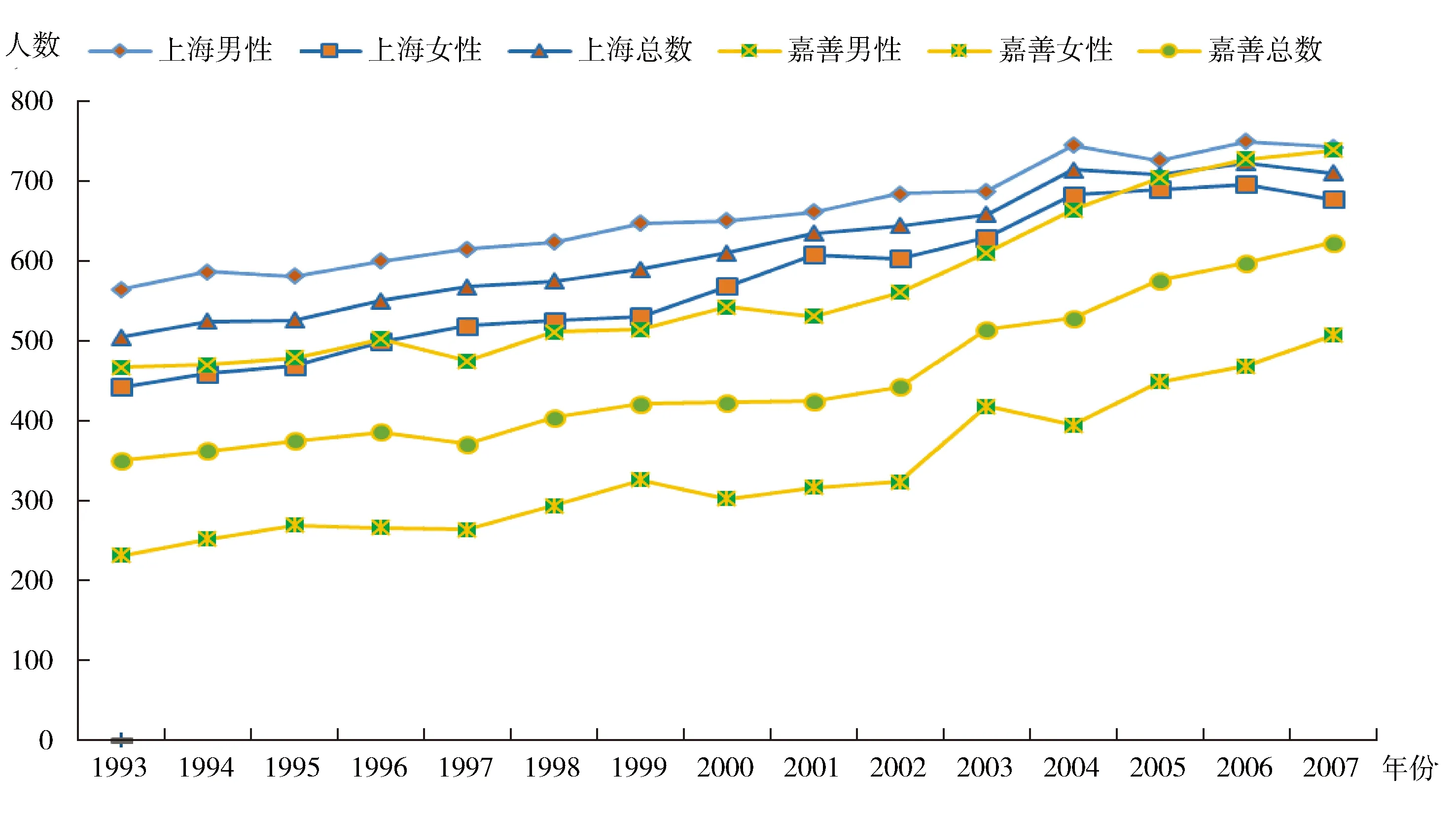
图4 1993-2007年上海和嘉善恶性肿瘤发病趋势
随着年龄的增长,两地发病率都呈现上升的趋势,且男性增长速度普遍快于女性,整体发病率也明显高于女性。1993-2007年上海和嘉善各年龄段恶性肿瘤发病率详见图5。
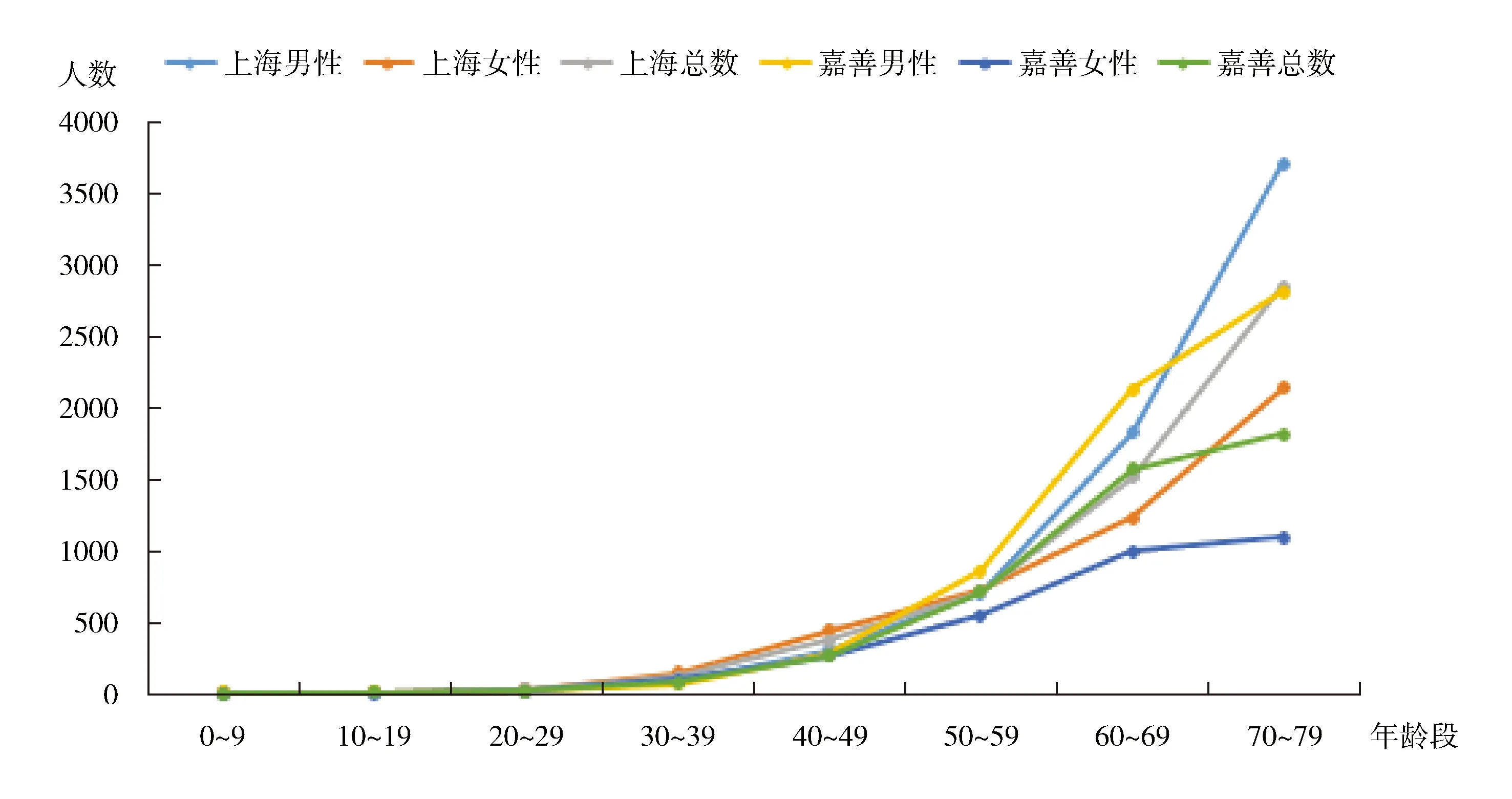
图5 1993-2007年上海和嘉善各年龄段恶性肿瘤发病率
综上,本文利用USGS数据生命周期管理模型,对部分肿瘤流行病学数据和相应的人口数据进行了整合分析,并借助流行病学研究方法和统计学方法对数据进行了处理,旨在实现数据的最大价值。
3.5 数据存储
本文所使用的数据均存储于中国工程科技知识中心医药卫生专业知识服务系统的MySQL数据库中,包括元数据、整体数据以及整合、分析过程中形成的中间数据和结果数据,并同步备份于另一数据库,以确保数据长期有效,可被随时访问。
3.6 数据发布与共享
本文所涉及的数据均已发布于中国工程科技知识中心医药卫生专业知识服务系统平台(http://med.ckcest.cn/)。
该平台提供了数据的简要说明以及浏览、下载和分析(包括对不同地区、不同年龄段、不同性别、各类癌症数据的对比分析以及癌症发病情况随时间变化的趋势分析)等功能,以达到对数据有效管理与利用的目的,为相关人员获取与深入挖掘数据提供有效途径,也为重大战略决策的制定提供直观展示和可视化对比分析。
具体示例如图6、图7所示。
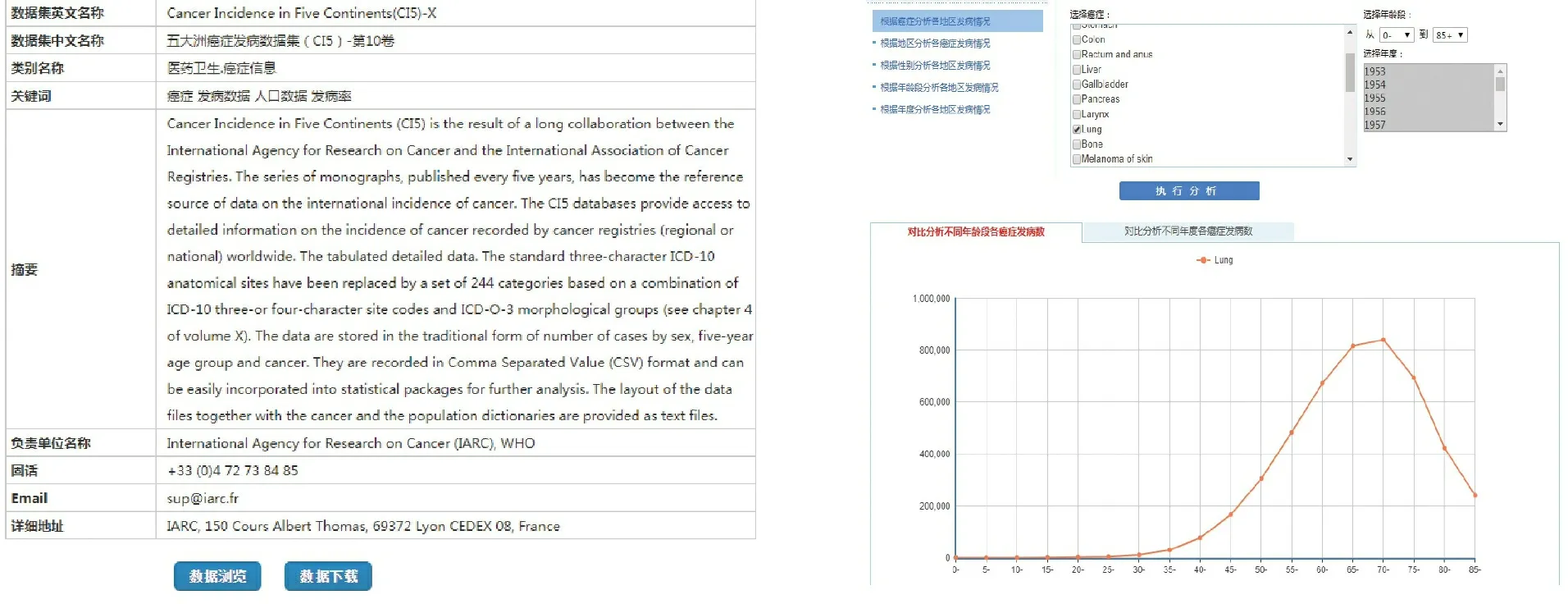
图6数据浏览与下载图7数据分析
4 结语
随着海量科学数据的开放与共享,相关研究人员和领域决策者面临着如何从海量数据中快速获取高质量的数据、如何对不同领域的数据进行科学整合、如何对各领域数据进行对比分析、如何实现数据价值最大化等一系列问题,因此选择合适的科学数据生命周期管理模型对数据进行全过程管理是十分关键且有意义的。
根据数据生命周期管理模型的要求,本文制定了具体的数据管理计划,并记录了数据使用的各个环节,能保证数据可被完整还原,为深度挖掘数据的价值提供保障。
通过整合分析后发现,数据生命周期管理模型在一定程度上解决了相关人员的数据管理问题,也为推动数据管理工作提供了借鉴。在数据泛滥的今天,选择合适的数据模型,做好数据的管理和再利用,充分挖掘数据的潜在价值十分重要。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
中老年保健(2021年9期)2021-08-24
铁道通信信号(2020年4期)2020-09-21
医学新知(2019年4期)2020-01-02
中国外汇(2019年13期)2019-10-10
民用飞机设计与研究(2019年2期)2019-08-05
消费导刊(2018年10期)2018-08-20
