
P2P情境下基于用户兴趣的个人数字图书馆资源定位
2017-03-21 08:41,
中华医学图书情报杂志 2017年11期
,
近年来,个人计算机上存储的个性化信息资源数量大幅增长,有效管理和使用这些资源成为亟待解决的问题,因此个人数字图书馆应运而生。目前个人数字图书馆有两种形式:一种是基于服务器的个人信息空间,一般称作“My library”(我的图书馆)[1];另一种是基于PC的数字信息资源库,一般称作“Personal Digital Libraries”(PDLs)[2]。本文研究的是第二种形式。
作为个人信息工具,个人数字图书馆的职能主要有两种:一种是有效管理和使用个人计算机上的信息资源,这是个人数字图书馆最基本的职能;另一种是共享个人计算机上的信息资源,促进资源的有效利用和知识再生,这是个人数字图书馆的核心功能。信息搜索是资源共享的基础,没有合适的信息搜索机制就无法构建高效的资源共享平台。由于个人数字图书馆的分散性特点,其信息搜索及共享研究在传统的客户机/服务器模式下难以突破。为了解决这个问题,P2P(Peer to Peer)技术被引入了个人数字图书馆领域。
1 个人数字图书馆与P2P技术简介
大量学者对个人数字图书馆的资源共享进行了研究。王小立指出资源共享是个人数字图书馆的本质属性,其发展仍处于初始阶段,具有广阔的前景[3];陈春艳分析了阻碍个人数字图书馆资源共享的因素,指出传统的集中式模式(客户机/服务器和浏览器/服务器)阻碍了个人数字图书馆资源共享的发展[4];张哲对比了集中式和P2P两种模式,指出集中式模式共享成本高、效率低,不适合个人数字图书馆资源共享的发展,而P2P模式的去中心化与个人数字图书馆的分散性不谋而合,不需要服务器的参与,能充分发挥个人数字图书馆的能力,适合个人数字图书馆的发展[5]。
P2P即对等网络,是相对传统的客户机/服务器模式而言的。系统中每个节点的作用都是对等的,既可以充当服务器为其他节点提供资源和服务,也可以充当客户机享用其他节点的资源和服务。P2P技术因其良好的自组织能力和可扩展性,而受到业界的广泛关注,主要应用于搜索引擎、资源共享、协同工作和实时通讯等领域。目前,P2P技术在个人数字图书馆方面的应用研究较少,主要集中于文件共享模型的构建和信息搜索。王春梅等介绍了个人数字图书馆的共享现状,尝试用P2P技术构建简单的个人数字图书馆共享架构,并通过模拟实验验证了P2P应用于个人数字图书馆的可行性[6];厦门大学Xu Yanfei利用具有相同兴趣的个人数字图书馆形成社区,探讨了适合个人数字图书馆的P2P网络拓扑结构[7]。资源定位是P2P技术应用于个人数字图书馆需要突破的一个难题。张银犬等指出在分布式环境下个人数字图书馆的信息检索还是一个研究空白和难点,并结合P2P技术和Z39.50协议,对个人数字图书馆信息检索策略进行了初步探索[8]。
分布式环境下没有集中式环境中掌管全局信息的中央服务器,资源定位成为一大难题。在非结构化P2P网络中,洪泛是最常使用的一种检索策略。这种策略将查询消息向所有邻居进行广播,造成大量通讯开销,严重影响了搜索效率[9]。为了减少消息数量,一些学者提出了启发式搜索机制,利用搜索历史、节点状态等信息,将消息转发范围控制在局部存有目标资源几率较高的节点,可缩小搜索范围,提高搜索效率。基于兴趣的搜索机制就是启发式搜索中的一种[10]。文献[11]根据节点之间的交流历史创建兴趣捷径,从而改进Gnutella的搜索性能。何可等采用基于兴趣的完全二叉树P2P拓扑结构,提出了一种基于Flooding机制的双向资源搜索算法[12];陈香香等根据节点共享文件的差异将网络分域,并且利用预算值控制搜索范围[13]。以上研究将最主要的兴趣作为节点的唯一兴趣,但是节点往往有多个兴趣,当节点搜索其他兴趣的内容时,就无法体现基于兴趣搜索机制的优势。
在以上研究的基础上,针对个人数字图书馆搜索机制尚不完善的问题,本文提出一种基于P2P技术采用多兴趣的搜索机制的个人数字图书馆模型(Multi-Interest Personal Digital Library Model,MIPDLM)。
2 基于P2P技术的个人数字图书馆模型MIPDLM
2.1 兴趣的表示
作为个性化特征突出的个人信息工具,个人数字图书馆(PDL)所存储的资源(本文只研究文档类的资源)往往表现出一定的兴趣偏好。传统的兴趣表示通常只关注PDL最主要的兴趣,这种单一的、静态的兴趣表示方法无法兼顾PDLs多样的、动态变化的兴趣,导致PDL搜索效率低下。本文采用多兴趣表示方法, PDL可以加入多个兴趣簇,即使PDL拥有丰富的动态变化的兴趣,系统也能将搜索消息转发到相似度较高的兴趣簇,故可大大缩小搜索范围,提高搜索效率。
本文采用经典的向量空间模型(Vector Space Model,VSM)作为兴趣表示模型,VSM模型将现实中无法相互比较的兴趣转化为可以计算彼此相似度的向量,如PDLi的兴趣向量为{PDLi1,PDLi2,…,PDLik,…,PDLin},表示PDLi共有n个兴趣,其中PDLik是PDLi中第k(1≤k≤n)个兴趣向量。两个兴趣之间的相似度采用夹角余弦表示,夹角余弦值越大,表示两个兴趣之间的相似度越大;反之,两个兴趣之间的相似度越小。同理,搜索消息向量与文档向量之间的兴趣相似度也取其夹角余弦值。兴趣与PDL之间的相似度是指该兴趣与PDL中所有兴趣相似度的最大值。同理,搜索消息向量与PDL之间的兴趣相似度也是如此计算。
2.2 兴趣覆盖网络的构建
构建适合个人数字图书馆资源共享的兴趣覆盖网络。在MIPDLM模型动态构建过程中,系统需用到个人数字图书馆的一些数据信息。每个PDLi存储如下3方面的信息:一是PDLi共享文档的集合,二是PDLi的兴趣向量集合,三是两种邻居集合即簇内邻居集合和簇外邻居集合。簇内邻居集合存储与PDLi兴趣相似度较高的PDLs,簇外邻居集合存储与PDLi兴趣相似度较低的PDLs。簇内邻居和簇外邻居都包含一组(ip(PDLj),PDLjr)信息,其中簇内邻居集合中ip(PDLj)是PDLi簇内邻居PDLj的IP地址,PDLjr是与PDLi的第k个兴趣相对应的兴趣向量。相反,簇外邻居集合中ip(PDLj)是PDLi的簇外邻居PDLj的IP地址,PDLjr是与PDLi的第k个兴趣相对应的兴趣向量。大量的PDLs根据簇内邻居形成一个个兴趣簇,这些兴趣簇紧密地结合在一起组成一个兴趣覆盖网,这种网络类似于一个规则网络。为了保证“小世界”特性,PDLs通过少量的簇外邻居链接到其他的兴趣簇[14]。
本文采用全分布式非结构化的P2P网络结构。当PDLi加入网络时,首先初始化兴趣向量{PDLi1,PDLi2,…,PDLik,…,PDLin},针对每个兴趣PDLik,PDLi维护两个路由表CRPDLik和NCRPDLik,CRPDLik存储簇内邻居信息,NCRPDLik存储簇外邻居信息。PDLi利用随机漫步算法在网络中发出一个消息,选取收到消息的2m个PDLs作为初始值,分别将m个PDLs的IP和兴趣向量存入CRPDLik和NCRPDLik。PDLs的兴趣一直处于动态变化过程中,为了确保网络拓扑结构适应个人数字图书馆兴趣的变化,使兴趣相似度较高的PDLs始终聚集在一起,PDL定期检测每个兴趣PDLik的聚合度DPDLik。聚合度DPDLik的大小是PDLi与所有PDLik相应的簇内邻居兴趣相似度的平均值,如果DPDLik高于或等于某一临界值γ,说明当前PDLi与簇内邻居兴趣相似度较高,PDLi不需要搜寻新的簇内邻居;如果DPDLik低于某一临界值γ,说明当前PDLi与簇内邻居关于PDLik的兴趣相似度较低,系统会重新搜寻兴趣相似度较高的PDLs并加入CRPDLik中。
2.3 基于多兴趣的搜索机制
哈佛大学社会心理学教授Stanley Milgram在著名的连锁信实验中发现了典型的小世界现象。受该实验的启发,在搜索过程中,PDL将消息转发到与搜索信息兴趣相似度较高的PDL中,这些通过兴趣连接在一起的PDLs不停地将消息转发到它们认为最有可能拥有目标资源的PDLs中,可大幅度减少搜索范围。
基于多兴趣的算法流程见图1。其搜索过程如下:步骤①PDLi发起一个搜索消息q时,首先将q的搜索内容初始化为向量d,定义q的最大转发跳数TTLq,初始化q所经过的PDLs列表ADD和搜索到的文档列表DOC。其中,ADD存放消息q所经过的PDLs的IP,DOC存放搜索到的文档向量以及相应PDL的IP。计算PDLi中与d相似度最大的兴趣PDLik,在路由表CRPDLik中计算与d兴趣相似度最大的兴趣PDLjr。步骤②将搜索消息q转发到PDLj,把PDLj的IP添加到ADD中,计算d与PDLj中所有的共享文档的兴趣相似度。当高于阈值θ时,把该文档向量和IP添加到文档列表DOC中,将ttlq减1。如果TTLq等于0,搜索消息q返回PDLi,否则转到步骤③。步骤③计算CRPDLjr中与d相似度最大的兴趣PDLlm。如果列表ADD中含有PDLl的IP,说明消息q已经到达过PDLl。为了防止环路的产生,舍弃PDLl,按兴趣相似度由大到小的顺序继续在CRPDLjr中寻找,直到找到IP不在ADD中的PDLlm(如果CRPDLjr和NCRPDLjr中所有PDLs的IP都在列表ADD中,则搜索结束,消息q返回PDLi),其兴趣相似度值为value。如果value小于阈值λ,表明CRPDLjr中的PDLs与d兴趣相似度不高。在NCRPDLjr中搜寻与d相似度最大的兴趣PDLsn(检查相应的IP是否在列表ADD中,如果在列表ADD中则利用上面的方法寻找下一个兴趣),从PDLlm与PDLsn中选取与d兴趣相似度较大的那个兴趣作为PDLjr。如果value大于或等于阈值λ,表明CRPDLjr中的PDLs与d兴趣相似度较高,不必再去NCRPDLjr中寻找相似度更高的兴趣而将PDLlm作为新的PDLjr,重复步骤②。当消息返回到PDLi时,搜索到的文档将按与d兴趣相似度由大到小的顺序显示出来。
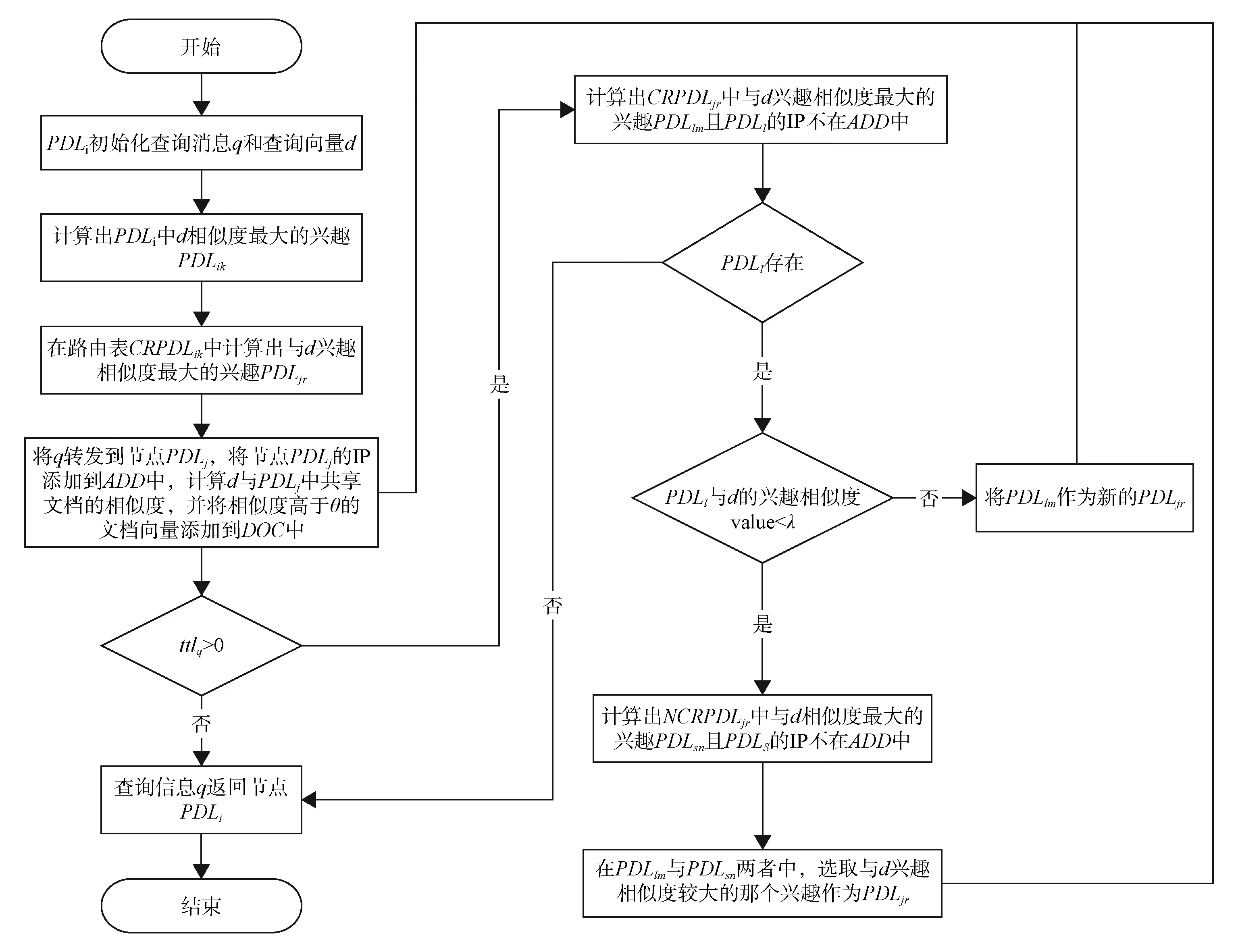
图1 个人数字图书馆基于多兴趣的资源定位算法流程
3 仿真实验
3.1 实验设置
从中国知网期刊论文数据库中选取实验文档。根据中国知网期刊论文数据库的学科分类,从基础科学、经济与管理科学等10个学科分类中分别选取20个兴趣主题,每个兴趣主题下载50篇论文。实验工具采用P2P通用网络模拟器PeerSim。
在PeerSim中生成一个网络规模为1 000个PDLs的全分布式非结构化P2P网络,将选取的10 000份文档散布在1 000个PDLs中,每个PDL的文档所涉及的兴趣数量不超过3个。
3.2 兴趣聚合度的确定
系统开始运行后,每个PDL都尝试启动聚合度检测程序,寻找兴趣相似度较高的PDLs。为了使PDLs不在同一时刻启动检测程序,所有PDLs在0-30分钟内随机选择某一时刻启动检测程序。第一次启动检测程序后,系统设定PDL定期启动一次检测程序,运行10个周期,计算搜索成功率。兴趣相似度较高的PDLs聚集在一起是MIPDLM模型正常运行的基础。阈值γ决定最小聚合度,选取合适的γ值是MIPDLM模型提高搜索效率的前提。为了验证阈值γ如何取值合适,实验测试了不同γ值下的搜索成功率,实验重复10次,每次系统都重新初始化网络,为每个PDL分配文档,TTL=6,实验结果取平均值(图2)
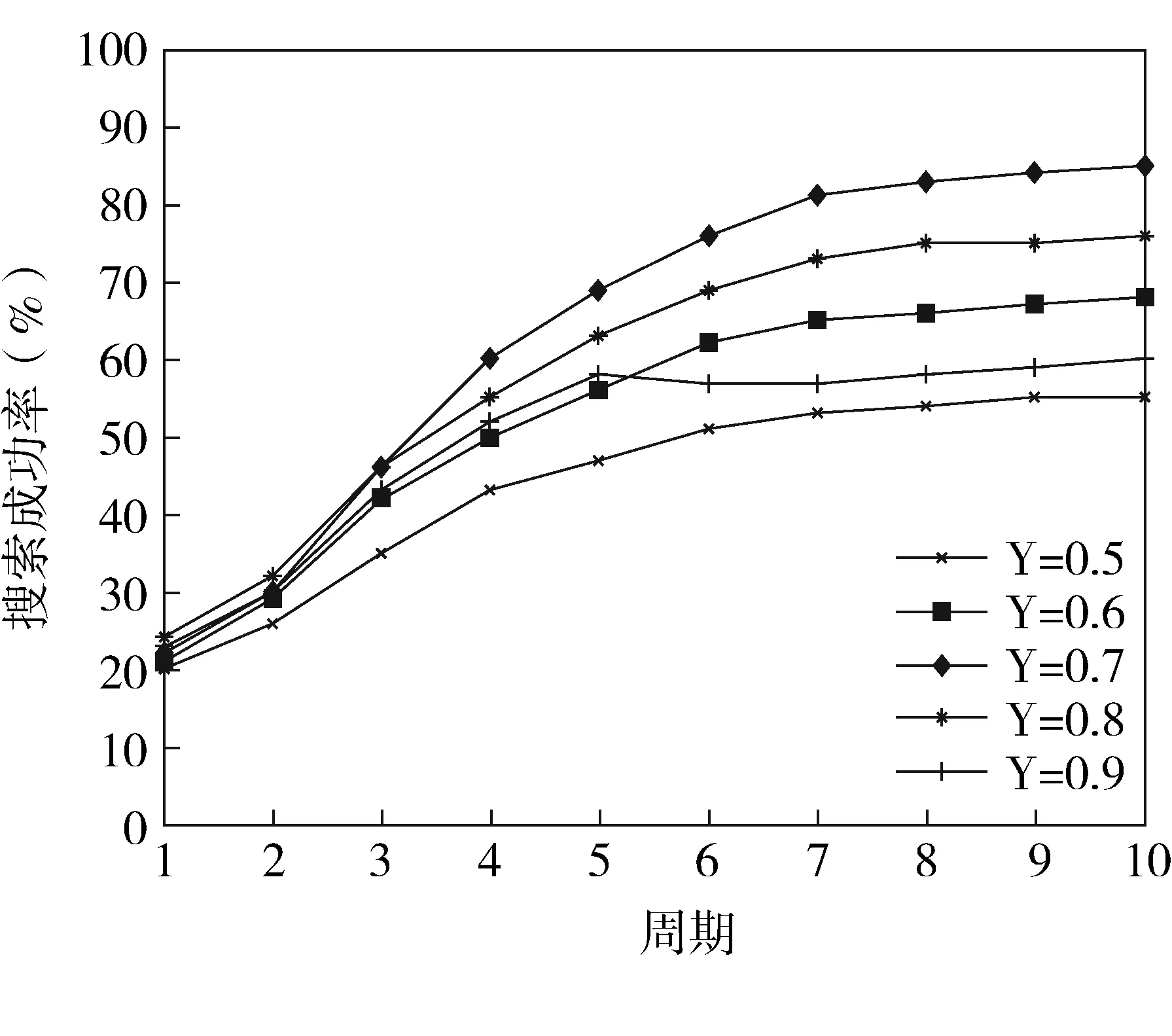
图2 不同γ值下的搜索成功率
从图2可以看出,当γ=0.5和γ=0.6时,聚合度太低,兴趣相似度较高的PDLs没能聚集在一起,搜索成功率较低;当γ=0.8和γ=0.9时,兴趣相似度较高的PDLs虽然聚集在一起,但是聚合度太高,节点无法通过兴趣相似度较低的PDLs搜索资源,搜索成功率仍然不高;当γ=0.7时,聚合度较为合适,兴趣相似度度较高的PDLs聚集在一起,搜索效果较为理想。以下实验中γ值均取0.7。
3.3 实验结果及分析
搜索机制的优劣主要取决于搜索成功率和平均路径长度等因素。搜索成功率是指搜索成功次数在搜索总次数中所占的比重,搜索成功率越高搜索性能越好;平均路径长度是指搜索路径长度的平均值,平均路径长度越长需要搜索的PDLs越多,在增加延迟的同时也加重了网络负载,较低的平均路径长度是搜索机制追求的重要目标。
随机漫步(Random Walk)是P2P网络中性能较为优越的一种搜索机制[15]。为了验证MIPDLM模型的性能,需对MIPDLM模型中搜索成功率和平均路径长度与Random Walk机制进行比较。MIPDLM网络模型运行一段时间,兴趣簇达到一个相对稳定的阶段后,随机选取PDL根据自己的兴趣进行搜索,TTL从1增加到10,每个TTL搜索200次,计算结果平均值。
搜索成功率如图3所示。在TTL相同的情况下,MIPDLM模型的搜索成功率明显高于Random Walk的。随着TTL不断增加,Random Walk的搜索成功率一直处于缓慢上升的趋势,并且在TTL<4之前搜索成功率上升的幅度较小。当TTL=10时,Random Walk的搜索成功率只有80%左右;当TTL=4时,MIPDLM模型的搜索成功率已接近80%,说明MIPDLM模型中由于PDLs形成兴趣簇,兴趣一致的PDLs聚集在一起,搜索消息转发到兴趣相似度较高的PDL中,可大大缩小搜索范围,绝大部分PDLs能在4跳内搜索到所需资源。搜索平均路径长度如图4所示。MIPDLM模型的搜索平均路径长度明显低于Random Walk的。Random Walk的平均路径长度随着TTL的增加不断攀升。当TTL=10时,Random Walk的平均路径长度已接近7。随着TTL的增加,MIPDLM模型的平均路径长度维持在4左右,再一次验证了MIPDLM模型中绝大部分PDLs能在4跳内搜索到所需资源。MIPDLM模型较低的平均路径长度可减少网络延迟,减轻网络负载。

图3 搜索成功率
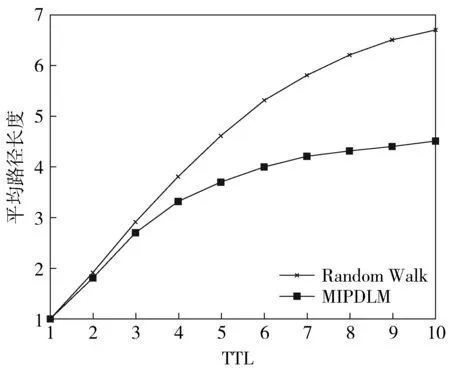
图4 平均路径长度
4 结语
本文提出了一种基于多兴趣的P2P资源定位机制,个人数字图书馆可根据兴趣分簇探讨基于多兴趣的搜索机制。随着兴趣的动态变化,个人数字图书馆不断调整簇内邻居,系统始终将兴趣相似度较高的个人数字图书馆聚集在一起形成P2P兴趣覆盖网络。仿真实验显示,MIPDLM模型中搜索消息不停地往兴趣相似度较高的个人数字图书馆转发,个人数字图书馆基本能在4跳内搜索到所需资源,可大大缩小搜索范围,提高搜索成功率,减少平均路径长度,减轻网络负载,提升个人数字图书馆的资源定位效率。本文为图书和档案共享系统的构建提供的新思路,有助于建立高效的分布式资源定位机制和共享模型。
猜你喜欢
当代水产(2022年6期)2022-06-29
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国生殖健康(2020年8期)2021-01-18
中国生殖健康(2018年3期)2018-11-06
电脑爱好者(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
