
AlphaGos是学习达人吗
2017-03-13 23:56叶敏超
科学24小时 2017年3期
叶敏超
2017年年初,一位取得在线对弈60连胜的神秘棋手Master震惊了世界围棋棋坛。在Master取得50连胜的时候,棋手古力在微博中这样评价道:“50连胜……虽然我也曾想过,但事
实摆在面前时,还是令我等职业棋士汗颜。也许我们曾经认为永恒不变的围棋定式、真理,会因Master的出现而发生颠覆性的改变……好好睡了吧,去迎接美好的明天与未来!”最终,在与古力进行最后一盘对决前,Master终于自己揭下面纱——正如人们猜测的那样,它果然是升级后的AlphaGo。此次代为执子走棋的,依然是AlphaGo团队中惟一懂围棋的工程师黄士杰(Aja Huang)博士。
AlphaGo的前辈——深蓝
从2016年起,AlphaGo就成了一个家喻户晓的名字。它是一个围棋游戏的计算机程序,最早由DeepMind公司在英国开发,后被Google公司收购。2015年10月,它成为在19×19的围棋棋盘上第一个打败专业棋手的计算机游戏程序。2016年3月,它在5場比赛中以4:1的比分击败了韩国棋手李世石,成为计算机游戏程序的又一个里程碑:第一次由计算机围棋程序打败了9段的专业级棋手。因此,AlphaGo被韩国棋院授予“名誉职业九段”证书。
其实计算机程序并非首次打败人类专业选手。早在1997年5月,IBM公司旗下的“深蓝”电脑就成功挑战国际象棋世界冠军卡斯巴罗夫。比赛在5月11日结束,最终深蓝以3.5:2.5的比分击败卡斯巴罗夫,成为首个在标准比赛时限内击败国际象棋世界冠军的电脑系统。既然深蓝早在10年前就取得了人机大战的胜利,那么10年之后,为什么AlphaGo的出现又会掀起如此大的波澜?这就要从它们不同的原理说起了。
深蓝取胜的秘诀是“穷举”,也就是穷举每一步所有可能的格局(落子方法),再根据当前格局穷举下一步格局。也就是说,事先就做成一棵博弈树。深蓝穷举搜索完整棵博弈树,也就遍历了所有可能的格局,然后通过对每一种格局进行评分,最终选择最优的解法。从当今的人工智能角度解读,深蓝的计算方式并不智能,只能用“暴力”去形容。深蓝之所以能取得胜利,靠的是计算机强大的穷举计算能力。当计算机的内存足够大,计算速度足够快时,这种穷举的算法应付国际象棋绰绰有余。那么,可以将这种方法运用到围棋上吗?答案是“不能”。原因就在于国际象棋与围棋规则的差异。国际象棋的棋盘只有64格,而围棋棋盘却有361格,从棋盘大小考虑,围棋的博弈树遍历的复杂度已经比国际象棋加大了好几十个量级。而围棋更复杂的计算在于其游戏规则。看似简单的游戏规则中,每一步的变化加上一些特殊规则所产生的计算复杂度是天文数字量级的。据测算,国际象棋的穷举复杂度为1046,而围棋格局的穷举复杂度需要10170。这样的计算复杂度,已经远远超越了计算机的运算能力。因此,围棋长期以来被认为是对人工智能最具挑战性的棋类游戏。
AlphaGo是如何学习的
AlphaGo的出现,是人工智能第一次成功挑战围棋这个棋类游戏,具有突破性的意义。那么,当博弈树穷举不再可行时,AlphaGo是如何进行决策的呢?于是,“学习”这一概念第一次在计算机程序对弈的领域中出现。所谓“学习”,就是将专业棋手的对弈输入计算机,计算机通过一定的算法,最终得到专业级的对弈策略。而近年来火了一把的深度神经网络,就成了AlphaGo学习的核心算法。在博弈中,AlphaGo使用“价值网络”(value networks)来评估棋盘中的位置,使用“策略网络”(policy networks)来确定棋子的移动。这些深度神经网络,通过对人类专家对弈的监督学习和增强学习来进行组合训练。
要解释AlphaGo的学习原理,首先要从人工神经网络(artificial neural networks)开始谈起。人工神经网络简称神经网络,是一种模仿人类神经网络结构的计算模型。神经网络由多个神经元构成,每个神经元的结构包含数据输入、输入权值、输入函数、激活函数。各种数据输入后根据权值在输入函数中进行叠加,然后通过非线性的激活函数进行变换后输出。多个神经元组成了神经网络。最简单的神经网络包含一个输入层、一个隐层和一个输出层(见图 2)。其特征是从输入层输入,经过隐层,最终由输出层输出。训练神经网络的目的,就是根据若干训练样本给定的输入和输出,计算出权值。深度神经网络与单隐藏层神经网络的区别,在于它们的深度和网络的层数。传统的神经网络是浅层网络,由一个输入层和一个输出层组成,并且最多有一个隐层。隐层数目多于一个(不包括一个)的神经网络,才可称为深度神经网络(见图 3)。在深度神经网络中,每层神经元基于前一层输出在一组不同的特征上进行训练。进入神经网络越深,神经元识别的特征越复杂,因为这些特征是前一层特征的聚合和重组。这种特征的层次结构可以挖掘出非结构化的原始数据中的潜在结构。换言之,深度神经网络可以视为一种自动提取特征的方法。对于围棋落子这样的非结构化数据来说,深度神经网络就是很适合的一种学习方法。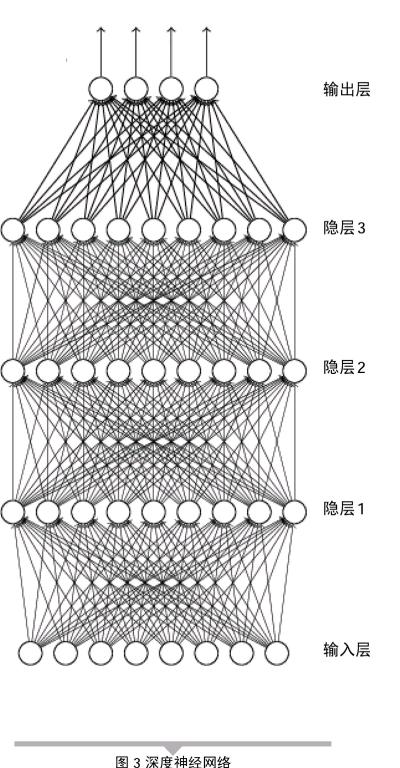
AlphaGo的学习流程包括三步(见图 4):第一步,使用监督学习训练策略网络。将3000万个专业棋手的落子位置以状态-动作对(s,a)作为输入,训练一个13层的监督学习策略网络;第二步,使用增强学习强化策略网络。该步骤中的策略网络与上一步骤结构相同,都是通过当前策略网络和之前迭代中随机选出的一个策略网络进行对弈(自我博弈),根据胜负对策略网络进行更新。第三步,增强学习价值网络。使用随机梯度下降方法,通过以状态-结果对(s,z)作为输入,训练价值网络的权重。完成以上三步学习流程后,AlphaGo就获取到了围棋落子的“知识”。接下来,AlphaGo只需将策略网络与价值网络结合在一起,然后就能通过使用蒙特卡洛树搜索法(Monte Carlo Tree Search,即MCTS)寻找到最佳落子方法了。
AlphaGo会超越人类吗
相较于“深蓝”的穷举搜索,AlphaGo才算是真正的机器学习。它巧妙使用了深度神经网络这种自动提取特征的学习方法,从杂乱的棋局中挖掘出潜在的隐含特征,甚至是那些“只可意会不可言传”的特征,学习到了专业棋手的落子套路。而自我博弈的增强学习方法,又成了AlphaGo温故知新、自我提升的强大工具。正因如此,AlphaGo才能突破极限,攻破围棋这个坚不可摧的人工智能堡垒。
AlphaGo的胜利让一些人产生了惶恐——今后人工智能是否能够完全超越人类的智慧,甚至统治人类?其实,我们大可不必惶恐。AlphaGo的深度神经网络和MCTS法都是由人类设计出来的,其学习知识的来源也都是人类的对弈。即便是看似“自我思考”的自我对弈,也仅仅是人类设计的增强学习算法。不但无需惶恐,而且我们还期待,随着人类智慧的发展,今后还将有更优秀的算法涌现出来,计算机的计算能力也会随着硬件技术的发展而得到很大提升。因此我们有理由相信,人工智能将会有能力攻克更多的难题,更好地为人类服务。让我们拭目以待吧。
猜你喜欢
华文教学与研究(2022年1期)2022-04-27
阅读与作文(小学高年级版)(2020年8期)2020-09-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
诗选刊(2019年8期)2019-08-12
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
北方音乐(2018年16期)2018-05-14
当代人(2018年3期)2018-03-21
下一代英才(2014年12期)2015-01-04
