
基于词分布式表征的汉语框架排歧模型
2017-03-12 08:48张力文王瑞波
中文信息学报 2017年6期
张力文,王瑞波,2,李 茹,3,4,张 晟
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 软件学院,山西 太原 030006;3. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;4. 山西省大数据挖掘与智能技术协同创新中心,山西 太原 030006)
0 引言
框架排歧任务是框架语义分析的一个子任务[1]。具体是指从例句库中随机选出一条给定目标词的例句,根据该例句的上下文语境,计算机自动识别出该句所属的框架,排除歧义框架。此任务可以用来消除自然语言中动词的“一词多义”的现象,继而为后续的句子语义分析奠定了重要基础,也为机器翻译、信息检索、自动文摘等应用系统提供语义上的支持。因此,框架排歧任务已经成为框架语义分析中至关重要的一部分。
在框架语义分析中,英文的FrameNet作为一种重要的语义资源[2],得到许多研究者的关注。针对汉语,参照英语 FrameNet构建的汉语框架网[3]是一种重要的汉语语义分析和理解的资源。它是基于框架语义学理论,以汉语语料为依据构建的语义知识库。该知识库由词元库、框架库和例句库三部分组成。
目前对汉语框架排歧的研究,是将其看作一个分类问题。利用统计机器学习的方法,人工寻找并选择特征,建立分类器。然而,这样利用特征进行分类的做法主要存在两个方面的问题。首先,每种特征的特征标记集合较大,从而导致最终的特征矩阵维度较高且非常稀疏。其次,特征标记被认为相互独立,没有任何关联。
针对以上两点不足,本文提出基于距离和基于词相似度矩阵的排歧模型。首先从大规模的无标注语料中,训练词语以及句子的分布式表征,然后应用于上述框架排歧模型中。由于词语和句子分布式表征是低维向量,可以有效避免特征维度过高,并且这些向量还携带了大量的语义及句法信息,在一定程度上解决了特征之间无关联的问题。
本文的组织结构如下: 第一小节对相关的框架排歧任务进行介绍,并总结了传统方法对该任务的局限;第二小节提出了基于距离和基于词矩阵相似度的框架排歧的模型;第三小节叙述了实验语料、使用的分布式模型,以及一些实验设置;第四小节给出了实验结果,并进行相应的错误分析;第五小节与BaseLine做了对比,进行了T检验和Kappa检验,并对错误进行分析;最后,对全文进行了总结,并给出了进一步的研究方向。
1 相关工作
针对英文FrameNet的框架排歧的研究,一些传统的模型是基于条件随机场、支持向量机、最大熵等分类器建立模型,把框架识别看作多分类问题[4-5]。针对汉语框架,李茹[6]等提出基于依存分析的条件随机场模型进行汉语框架识别;李国臣[7]等研究了基于词元语义特征的汉语框架语义排歧方法。这些传统的方法,不可避免地选择了大量的词和句法特征,使得特征空间维数很大,并且特征之间关联较小。党帅兵[8]将词语的分布式表征信息,加入到最大熵分类模型中,初步验证了词分布式表征的有效性。本文首次尝试不使用传统的分类模型,直接使用词语的分布式表示,以避免特征选择及降低特征维数,并结合特征之间的关联性,进行框架排歧。
近年来,词语的分布式表示技术受到很多自然语言处理研究者的青睐。分布式语义模型可以从大规模无标注语料中自动学习到句法和语义信息,包括针对词语、句子以及文档的分布。
Karl Moritz首次提出将词语的分布式表示应用在词义消歧任务(WSD)[9],词义消歧任务与框架排歧任务的目标相同: 根据语境,为目标词选取一个合适的词义。不同的是,这里的词义是框架语义,而不是传统的词的词典义项。再者大部分传统的WSD任务只针对名词[10],而框架消歧任务主要是针对动词。近年来,有学者将分布式表示技术引入到框架语义分析的任务上。Hermann[11]提出基于分布式表征的框架排歧方法,在英文的FrameNet 语料上取得较好的结果。本文研究的是使用词语或句子的分布式对汉语框架排歧任务的有效性。
2 汉语框架排歧模型
2.1 汉语框架排歧任务
在一条例句中,给定一个可以激起多个框架的目标词,要求计算机能够基于上下文语境,从现有的框架库中,自动为该目标词选择一个适合的框架。其形式化表述如下: 给定一个句子,记为S。S是由词组成的一个序列,记为S=(w1,w2,…,wn),wi代表组成句子的第i个词,1≤i≤n。且目标词可以激起的框架集合记为F={f1,f2,…,fm}。本文首次使用高斯判别分析来解决汉语框架排歧任务。框架消歧任务可以描述为: 寻找唯一的f,使其满足,如式(1)所示。
本文提出了两种排歧模型: 一种假设存在框架向量及其所属的例句向量,基于高斯判别分析,为例句选取合适的框架,具体做法参见2.2节;另一种则假设不存在框架向量和例句向量,利用句子之间的相似度直接选取合适的框架,具体做法参见2.3节。
2.2 基于距离的汉语框架排歧模型
本模型假设存在框架向量,以及框架所属的例句向量。框架代表着一种语义场景,描述某语义场景的例句就属于表示该语义场景的框架;而每条例句又由词构成。基于以上两点,我们认为: 词向量、框架下的例句向量以及框架向量存在于同一空间中。如何表示框架下的例句向量和框架向量,以及如何判别例句的所属框架是本节讨论的内容。
2.2.1 框架例句以及框架的分布式表示
框架例句是由词组成的,可以通过词向量来表示例句向量。另外,也可以直接训练例句向量。因此,本节使用了两种表示方法: 一种是基于词向量的MEAN-POOLING,另一种是Doc2vec。
(1) 词向量的MEAN-POOLING(表1)

表1 构建例句向量的MEAN-POOLING方法
(2)Doc2vec。对于构建例句向量,我们使用了Mikolov在Word2vec的原理上提出的一种将短句变为向量的方法[12]。本文使用PV-DBOW算法,在中文维基百科上训练例句向量。
由于每个框架下的例句有一定的语义关联性,因我们将框架下的例句向量相加后再平均,得到框架向量的表示。
2.2.2 框架排歧步骤
首先用词向量把例句S表示为例句向量,并假设框架下例句的分布服从正态分布,则P(f/S)服从多维正态分布。这个分布中的两个参数: μ是均值向量,即上节所提出的框架向量,Σ是协方差,在本文中,我们假设是协方差相同。因而有:
P(S;μ,Σ)
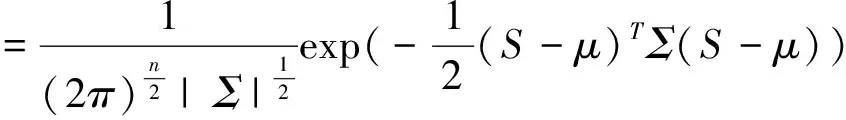
(2)
所求概率的大小与框架例句向量和框架向量之间的欧氏距离负相关。因而,将模型简化,我们没有计算概率,而是直接通过距离大小来判别例句所属的框架。具体步骤参见表2。

表2 基于距离的框架排歧步骤
2.3 基于词相似度矩阵的汉语框架排歧模型
本模型假设不存在框架向量及其所属的例句向量。因而对于框架和例句,没有特定的向量表示。框架代表着一个语义场景,那么可以描述该语义场景的例句均属于该框架,因而框架例句之间有一定的语义联系及相似性。此外,每条例句都是由词构成,而词向量包含着句子的语义和句法信息。基于以上两点,我们直接使用例句中的词相似度来度量例句的相似度,最后利用例句间的相似度来判别例句所属的框架。
2.3.1 例句间的词相似度矩阵
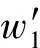
cos
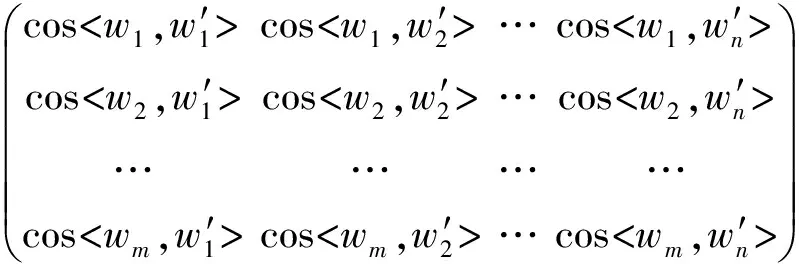
(3)
矩阵元素为两个词语的余弦相似度,即
(4)
E(w)为词w的词向量。矩阵中行代表测试例句的每一个词与训练例句中的每一个词的相似度,矩阵中的列代表训练例句中的每个词与测试例句的每个词的余弦相似度。基于上述词相似度矩阵,本文提出三种计算例句相似度的方法,如表3所示。

表3 三种例句相似度的测量方法
2.3.2 框架排歧步骤
基于词相似度矩阵的模型,只利用词的相似度,得到框架下例句的相似度,进而根据例句相似度判别其所属框架,具体步骤如表4所示。

表4 基于词相似度矩阵的框架排歧步骤
3 实验设置
3.1 实验语料
本文抽取汉语框架网(ChineseFrameNet) 中88个可以激起两个以上框架的词元中的2 067条句子作为语料来构造框架排歧实验。采用中文维基百科*使用zhwiki-latest-pages-articles.xml.bz2(2017-1-25).做为训练词向量和句向量的语料。WordEmbedding对本语料的覆盖率为94.58%,具体计算公式如式(5)所示。
覆盖率=词频向量*语料库中的某词语在语料库中出现的次数。×词语出现向量*语料库中的词是否在Word Embedding库中出现,若该词出现,向量的相应维度为1,未出现则为0。/语料总词数
(5)
3.2 评价指标
为了评价本文所提模型的性能,我们采用组块3×2交叉验证进行实验。具体做法是,将语料库切分成四个大小相同的子集,然后,通过两两组合,形成组块3×2份交叉验证实验。组块3×2交叉验证在模型估计和选择方面的优良性能已经被证明,具体可参考Wang等的工作[13]。
在组块3×2交叉验证的条件下,全部目标词的框架分类准确率(Accuracy)的计算公式如式(6)所示。
式(6)中,n为所选用词元的总数(本文n=88),Nkji为第i个词元的第j组块的第k折交叉实验中的测试例句总数,Ckji为第i个词元的第j组块的第k折交叉实验中的测试例句正确数。
3.3 参数设置
在训练词向量时,我们分别采用了Word2vec的CBOW以及Skip-Gram模型,以及GloVe型。按之前的经验将各模型的窗口设置为5,维度设置为100。分别探究每个模型训练的词向量对框架排歧任务的影响,寻找最优词向量模型。然后设置该模型窗口值及维度,探究不同窗口及维度对框架排歧模型准确率的影响。
Mu提出一种词向量后处理的方法[14],本文认为训练好的词向量中都包含着一个公共向量,而且词向量均被相同的方向所支配。这两点会影响由词训练出的词向量的质量。本文将用这种后处理方法,对CBOW、Skip-Gram及GloVe训练出的词向量进行处理。
另外,本文还增加了随机初始化的词向量方法。设置了服从标准正态分布的随机向量。使用该随机向量,是为了与上述词向量模型进行比较。
4 实验分析
窗口值为5,向量维度为100时,各类词向量在框架排歧模型中的准确率如表5所示。
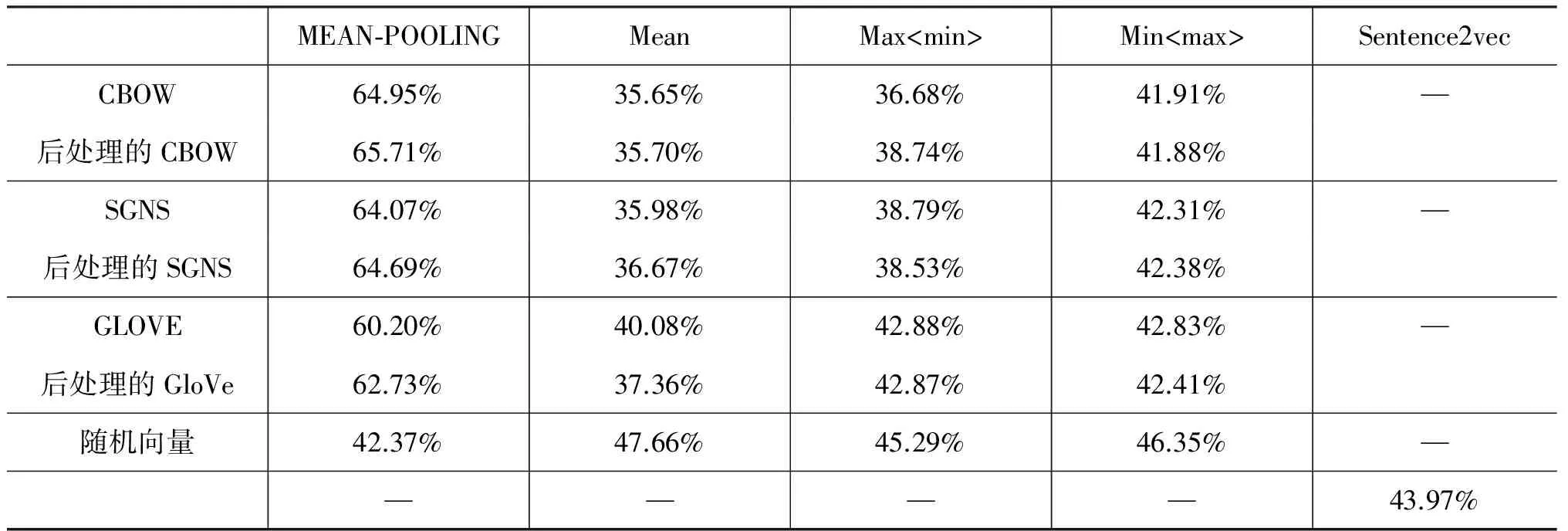
表5 各类词向量应用于框架排歧模型中的准确率
接下来,对表5的数据进行说明。第一行代表本文实验的所使用的模型方法,第一列代表的是本文实验所用的词向量。其中,CBOW、SGNS、GLOVE是分别使用Continuous Bag-of-Word模型、Skip-Gram模型及GloVe模型生成的词向量;后处理的CBOW 、后处理的SGNS、后处理的GLOVE 是使用文献[14]的方法对上述三类词向量进行后处理的词向量;“随机向量”是随机生成均值为0、方差为1的100维向量。当采用Sentence2vec模型时,输入的是句向量,在相应词向量准确率的位置为“-”。
由表5可得,用CBOW模型训练出的词向量进行后处理,得到的准确率最高。下面以该词向量作为研究对象,研究当窗口大小不同时对于框架排歧任务的影响,准确率如图1所示。

图1 词向量窗口不同时框架排歧的准确率
由图1可以看出,当窗口设置为5时,效果最好。因而,我们选定窗口值为5。然后比较不同维度的词向量对于框架排歧任务的影响,具体结果如图2所示。
综合表5、图1、图2,使用CBOW模型,将窗口设置为5,向量维度设置为100,并经过后处理的词向量,对框架排歧的效果是最好的。
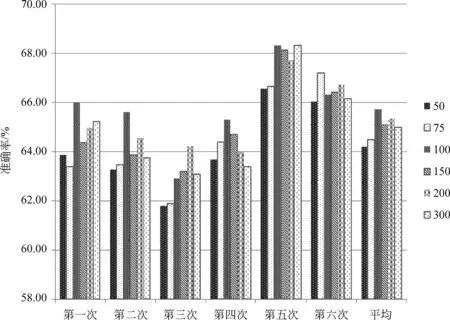
图2 词向量维度不同时框架排歧的准确率
5 错误分析
我们选取文献[15]中的框架排歧方法做为本文实验的BASELINE。由于本文的模型是基于词的分布表征,BASELINE只选取有关的词特征,不选取句法特征。所选特征为: 词包以及窗口为2的词特征。即BASELINE: WordFeature[-2,2]+BOW。具体结果如表6所示。

表6 BASELINE与MEAN-POOLING的比较
5.1 T检验
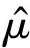
5.2 Kappa统计量分析
虽然使用两种方法得到的结果差异并不显著,但使用MEAN-POOLING方法,实验结果的精确度略低于BASELINE,本节对两种方法的实验结果进行Kappa统计量分析。对结果一致的部分进行检验,看一致的部分是否是由偶然因素影响的结果。计算如式(8)所示。
其中,P0为实际一致率,Pe为理论一致率。对以上六次实验做了Kappa统计量分析,得到具体结果如表7所示。

表7 每次实验的Kappa值
由表7可知每次实验的Kappa值均在[0.4,0.75]之间。说明两者的一致性可以接受,表明MEAN-POOLING的结果与BASELINE的结果中,一致的部分受偶然因素影响不大。
最后,我们收集了两类例句: ①BASELINE分类正确而MEAN-POOLING分类错误;②BASELINE分类错误而MEAN-POOLING分类正确。通过分析得到如下结论。
(1) 对于目标词附近多为代词、介词及附近词缺失的例句,BASELINE正往往表现得不好。例如,“分散范围之广,分布地区之多,都是其他民族所不能相比的”。目标词是“分散”,其左边没有词;以及“她记得离开中国时,养母带她登过长城。”目标词是“记得”,左边只有代词“她”。对于那些附近的词缺失或者多为无实际意义的词的例句,MEAN-POOLING不需要此类特定的特征,因而可以有效地解决这类句子的分类问题。相反,目标词附近多为实际词时,BASELINE分类要优于MEAN-POOLING。MEAN-POOLING的精确率略低,有可能是在语料库中适合于BASELINE分类的例句数量占优。
(2) 若某词元下某个框架的训练语料数量偏多。相比于MEAN-POOLING,BASELINE受影响较大。例如,词元“看”有三个框架,分别为“获知”“自主感知”“外观”。其中“获知”框架下的语料例句最少,而MEAN-POOLING正确分类“获知”框架下的例句要多于BASELINE。对于例句较少的框架,BASELINE由于训练例句较少,往往表现得不好。
6 总结与展望
本文使用CBOW、Skip-Gram和GloVe等流行的词向量训练模型,以及使用Doc2vec模型,从无标注的维基百科语料中学习词语及句子的分布式表征,后直接应用于基于距离和基于词相似度矩阵的框架排歧模型中,在基于距离的框架排歧模型中,最高得到了65.71% 的准确率。
在表现最好的MEAN-POOLING方法中,使用随机词向量进行实验,得到的准确率大大低于后处理的CBOW词向量。因而,进一步验证了: 从大量文本中,通过无监督学习,得到的词向量,携带了大量的语法及语义信息,可以有效地应用在框架排歧任务中。
因为精确率略低于BASELINE,随后又使用了T检验和Kappa检验对错误进行分析。可以发现将词的分布式表征应用于框架排歧模型,与BASELINE的实验结果并没有显著的差别,两者一致的部分受偶然因素影响结果不大,一致性可以接受。证明了本文方法的有效性。
文章最后通过分析两类例句我们得到: 词的分布式表征可以有效地避免传统分类模型严重依赖于特征选择的缺陷;当训练语料不平衡时,基于词分布式表征的排歧模型受影响较小。本文只是用了词的分布式表征,并没有考虑句子依存关系等句法特征。下一步工作主要是研究如何将依存关系与词的分布式表征有效结合,并将其应用于汉语框架排歧模型中。
[1] C Baker,M Ellsworth,K Erk. SemEval-2007 Task19: Frame Semantic Structure Extraction[C]//Proceedings of the 4th International Workshop on Semantic Evaluations.Prague, 2007:99-104.
[2] C J Fillmore. Frame Semantics[M]. Linguistics in the Moring Calm, Hanshin Publishing Co. Seoul, South Korea. 1982: 111-137.
[3] 王瑞波,李济洪,李国臣,杨耀文,等. 基于 Dropout正则化的汉语框架语义角色识别[J]. 中文信息学报,2017,31(1):147-154.
[4] Cosmin Adrian Bejan, Hathaway Chris. UTD-SRL: A Pipeline Architecture for Extracting Frame Semantic Structures[C]//Proceedings of the 45th Annual Meeting of Association for Computational Linguistics, 2007:460-463.
[5] Richard Johansson, Nugues Pierre. Semantic Structure Extraction using Nonprojective Dependency Trees[C]//Proceedings of the 4th International Work on Semantic Evaluations. Prague, 2007:227-230.
[6] Ru Li, Haijing Liu, Shuanghong Li. Chinese Frame Identification using T-CRF Model[C]//Proceedings of International Conference on Computional Linguistics. Beijing, 2010: 674 -682.
[7] 李国臣,张立凡,李茹,等.基于词元语义特征的汉语框架排歧研究[J].中文信息学报,2013,27(4):44-51.
[8] 党帅兵,李国臣,王瑞波,等.基于词分布表征的汉语框架排歧研究[J].中北大学学报,2015,36(3): 328-332,337.
[9] Das D,Ganchev K,Weston J,Hermann KM. Semantic Frame Identification With Distributed Word Representations[C]//Proceedings of Meeting of the Association for Computational Linguistics,2016,1: 1448-1458.
[10] Navigli R.Word Sense Disambiguation:A Survey[J].ACM Computing Survey.2009,41(2):1-69.
[11] Karl Moritz Hermann,Dipanjan Das,Jason Weston,Kuzman Ganchev. Semantic Frame Identification with Distributed Word Representations[C]//Proceedings of the Meeting of the Association for Computational Linguistics . Baltimore, USA.2014:1448-1458.
[12] Quoc Le,Mikolov T. Distributed Representations of Sentences and Documents[J].Computer Science,2014,4:1188-1196.
[13] Yu W, Ruibo W, Huichen J, et al. Blocked 3×2 cross-validated t-test for comparing supervised classification learning algorithms[J]. Neural computation, 2014, 26(1): 208-235.
[14] Mu J, Bhat S, Viswanath P. All-but-the-top: Simple and Effective Post-processing for Word Representations[DB/OL]. arXiv:1702.01417.
[15] 李济洪,高亚慧,王瑞波,等. 汉语框架识别中的歧义消解[J].中文信息学报,2011,25(3):38-44.
猜你喜欢
湖南电力(2022年3期)2022-07-07
通信技术(2021年12期)2022-01-25
计算机应用与软件(2018年9期)2018-09-26
制导与引信(2017年3期)2017-11-02
小天使·一年级语数英综合(2016年4期)2016-11-19
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2016年6期)2016-05-14
雷达与对抗(2015年3期)2015-12-09
小天使·一年级语数英综合(2015年10期)2015-10-14
外语教学理论与实践(2014年2期)2014-06-21
