
基于外部记忆单元和语义角色知识的文本复述判别模型
2017-03-12 08:30李天时王文辉常宝宝
中文信息学报 2017年6期
李天时,李 琦,王文辉,常宝宝
(北京大学 计算语言学教育部重点实验室,北京 100871)
0 引言

图1 英文文本复述判别句子实例
文本复述判别任务旨在判断给定的两句话是否表达相同的含义,该任务本质上是识别两句话之间的语义相关程度。在文本复述判别任务中,若两句话是复述关系,则定义两句话是等价的;若两句话不是复述关系,则定义两句话是不等价的。图1给出了等价和不等价的句对实例。上面一组句子是等价的, 下面一组句子是不等价的。第一组句子中两句话在词汇表达上虽然不同(尤其是加粗部分),但是两句话表达出相同的含义,表达了“美国参议院要发起对伊拉克战前严格的情报准备工作”。第二组句子中虽然两句话的主干表达了相同的含义,但是由于第一个句子比第二个句子多出一部分细节描述(句子中加黑部分),所以二者在语义上不是完全相同,是不等价的。识别复述关系对于自动问答[1]、抄袭检测[2]、机器翻译评价[3]等不同的任务都有重要作用。
目前做法可以分为基于特征的方法和基于多层次神经网络模型的方法,两类方法都是把该任务当作是二分类问题处理。不同之处在于,基于特征的方法把重点放在使用不同的特征捕获两句话的语义联系,基于多层次模型的方法对句子进行建模,在结合特征之上通过不同层次的模型挖掘更多不同层级的句子语义联系。前人的研究方法有如下的优点: ①基于特征的研究方法[4-6]通过机器翻译评价指标和N元组等特征就可以识别出两句话基本的语义联系,进而取得不错的效果。②基于多层次神经网络模型的研究方法[7-10]可以通过不同层次的网络自动学习到词汇、短语和句子片段等不同层级上的语义联系。而前人的工作中还存在以下不足: ①基于特征的研究方法中虽然使用了机器翻译评价指标等特征,但是这些特征不能提供足够的不同层次语义知识。语义角色标注和文本复述判别同为语义理解任务,二者有许多联系,语义角色知识可以帮助识别两句话中的不同层级的语义联系,而前人研究忽略了这个信息。②多层次的神经网络需要使用不同层次上的网络学习不同层级的语义知识,比如Socher等人[7]使用的树结构自动编码器或是Yin等人[10]使用的两层以上的卷积神经网络。这导致模型总层数多,容易加重梯度消失和梯度爆炸的问题,进而加大训练难度。
图2展示了一对互为复述关系的句子。从这两句话中我们可以看出: ①两句话在不同层次(词汇、短语、片段)上都有对应语义关联。比如“came up with”和“make”在表层用词不一样, “came up with”有想出、提出、追赶上等含义, “make”更是有开始、做、制造等不同含义,而在这两个句子中,结合上下文的语境,它们表达了“提出”这个相同的语义。②对于“came up with”和“make”这两个动作的中心动词来说,两句话中的相关的语义角色也在语义组块和角色类型上有强烈的对应关系。因此,学习不同层次语义联系,以及结合语义角色知识进行复述判别是十分有用的。

图2 互为复述关系句子实例及相关语义角色标注
因此,本文设计了一种轻量级单层记忆单元神经网络模型,该模型有如下优点: ①利用外部单层记忆单元来存储两句话中的不同层级语义联系,缩减整个模型网络层数,降低梯度消失和梯度爆炸的问题,模型易于训练。②加入语义角色知识作为特征,利用对应动词语义角色在两句话间的联系帮助复述判别。
1 文本复述判别模型
1.1 基于注意力机制的神经网络模型
本节先介绍实验使用的基础模型架构——基于注意力机制(attention)的单层循环神经网络复述判别模型。该模型由如下两个模块组成: 生成句子向量表示和利用逻辑斯蒂回归模型(LR)进行复述判别。
首先是生成句子向量表示模块。图3展示了利用注意力机制生成句子向量表示的部分架构,图中展示的注意力得分(Attention Value)是针对左边句子,根据注意力矩阵(Attention Map)按行求和之后再归一化得到的。右边句子的注意力得分可以类似地将注意力矩阵按列求和后归一化得到。
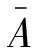
图3 基于注意力机制的循环神经网络模型部分架构
其中, 两句话的LSTM层在权重上是共享的,我们认为这样可以将两句话经过LSTM层后的表示映射到同一语义空间,方便后续识别两句话间的语义联系。在LSTM模型生成的新句子序列向量表示的基础上, 我们利用图3的软对齐的方式生成每句话固定维度的句子向量表示。首先生成s1和s2之间的注意力矩阵(Attention Map)M,M∈l1×l2。对于两句话中的任意两个词的原始词向量对
其中cos (·)是计算余弦相似度的函数。该矩阵表明了两句话词语之间的语义相关性。之后,我们通过式(4)和式(5)计算一句话中每个词语对另一句话的重要程度权重:
∀i∈[1,…,l1]
(4)
∀j∈[1,…,l2]
(5)
根据一句话中每个词语对另一句话的重要程度权重,我们就可以计算出考虑另一句话相关性的定长句子向量表示,如式(6)、式(7)所示。
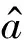
然后是LR模型复述判别模块(图4)。
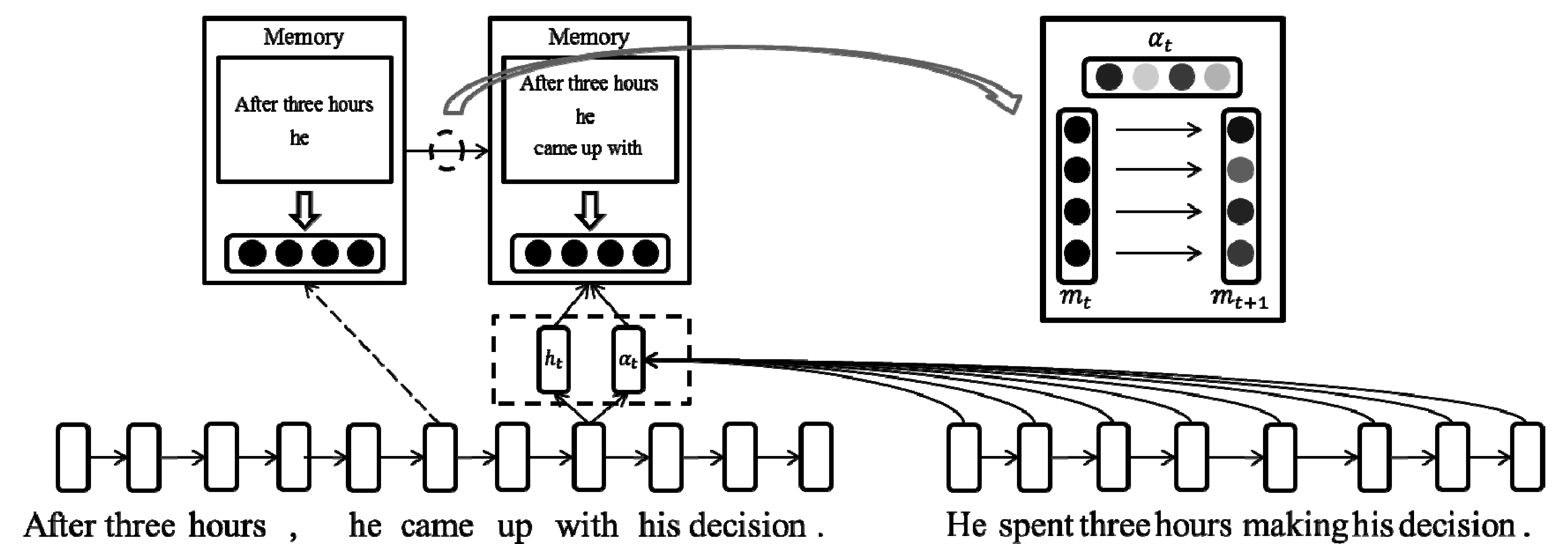
图4 基于单层记忆单元(Memory)的循环神经网络模型部分架构
其中xf是每一维由一个特征组成的特征向量表示,y∈[0,1]为最终逻辑斯蒂回归模型(LR)的分类输出。
这个模型有如下特点: 仅使用了单层LSTM,并使用单次Attention机制一次性捕获两句话中的相关语义联系。然而这个模型还存在一个明显的问题,Attention机制的输入端每个词的向量表示是由单层LSTM层生成的,这个向量表示虽然在一定程度上可以学习到前后文的语义依赖,但向量中包含的大部分语义信息还是词汇级别的语义信息。这就导致利用Attention机制生成的两句话相关联的向量表示也是以词汇级别的语义关联为主,不能真正学习到不同层次的语义联系。
1.2 基于外部记忆单元的循环神经网络模型
针对1.1中基础模型还存在的问题,本节引入外部记忆单元加以改进。本节中的模型只对生成句子向量部分表示进行变动,使用单层记忆单元替换基础模型中的注意力机制。我们利用单层的记忆单元存储一句话中对于另一句来说重要的语义信息,然后利用两个句子各自的记忆单元识别句子间的语义联系。在前人多层次的神经网络中,使用卷积网络的方法[8-10]由于每一层卷积窗口大小固定,只能学习有限的上下文知识,需要通过不同层次的网络学习不同层级语义知识;使用自动编码器[7]的方法更是需要依赖树状结构学习语义知识,网络本身就是多层次的。我们使用的单层次记忆单元网络基于LSTM,由于LSTM可以捕获前文的信息,所以随着我们记忆单元的更新,记忆单元中会不断加入相对于另一句话重要的语义知识,这些知识又同记忆单元之前存储的语义知识融合,形成不同层次的(词汇、短语、句子片段)语义知识存储单元。
记忆单元是一个独立的向量,每个句子都有一个独立的记忆单元,该记忆单元随着单向循环神经网络在句子中的前向传播进行更新。以图4为例,左边句子传播到“came”这个词时,对应左边句子的记忆单元中已经发现句子片段“After three hours”和词汇“he”同右边句子有强烈的语义联系,因此已经将它们的语义联系转化为向量表示。当句子传播到“with”时,读入该词后发现同前两个词组成的短语“came up with”和右边句子有明显的语义联系,则将这个语义联系也存储到记忆单元向量中。在我们的记忆单元向量中,向量的每一位本质上都表示一个不同的特征,我们可以利用向量αt控制记忆单元中的每一位进行不同的更新操作,αt中的每一位就对应着记忆向量中每一位的更新开关。按位进行不同更新的策略就使得记忆单元向量可以在每位上存储不同层次上的语义联系。每一次记忆单元更新对应的输入ht,该向量是单层LSTM输出的词向量经过空间映射后得到的新向量表示。我们使用ht而不直接使用LSTM层输出的向量作为更新记忆单元的输入也是为了使记忆单元中可以存储更丰富的不同层次的语义联系,而不单是词汇级别的联系。
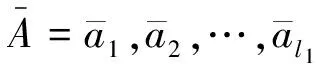
其中mt∈d$,ht∈d是基于LSTM的输出得到的向量,αt∈d是门向量(gate vector),用来控制保留多少原始记忆单元中信息并读入多少词t中信息。ht和αt的计算方法如下:
其中Wm、bm和Um∈d×2d均为网络参数。门向量αt是通过词t同s2中的每一个词计算一个相应的权重,然后将生成的权重序列通过最大池化操作生成的。直观上来讲,就是当前词t同s2中每个词计算其关联的重要程度,然后取每一维中的最大值作为其最重要程度的参考,然后根据该对s2的重要程度选择写入多少到s1的记忆单元中。句子s2的记忆单元可以使用类似的公式进行计算得到。因此,通过上述公式,我们对每个句子都生成了一个记忆单元,里面存储了该句子相对于另一句话来说不同层级上的重要语义知识,然后再利用这些语义知识进行最终复述判别。
在LR模型复述判别模块中,我们使用两个句子的记忆单元,再加上LSTM层输出序列的最终向量作为总的句子向量特征表示,希望利用原有句子表示的同时强化两句话中关联部分的语义联系。同上一节一样,我们不是直接使用句子向量作为LR模型的输入,而是先分别计算对应句子向量之间的余弦相似度,然后将余弦相似度作为输入的一部分。
1.3 加入语义角色特征
通过图2的例子可以看出语义角色知识也可以帮助文本复述判别挖掘不同层次的语义联系。因此,我们在基于单词记忆单元的循环神经网络模型基础上,通过加入句子中的语义角色知识进一步挖掘更多的不同层次语义关联。
首先是抽取句子语义角色特征。考虑到一句话中包含多个动词,但不是所有动词及其语义角色都对句子语义联系识别有帮助作用,尤其是句子中同另一句话语义不相关的动词。我们利用词向量去计算两句话间每个动词对的余弦相似度。预训练的词向量表示包含了词语在文章上下文中的语义信息,使用它计算出余弦相似度越大的动词对语义联系越相近。实验中,我们使用词向量间余弦相似度最大的动词对进行两句话的语义角色标注。我们认为这种做法可以在利用对识别句子语义联系最有用的语义角色特征的同时过滤了语义角色标注知识带来的噪声。具体步骤如下: ①使用词性标注器识别句子中的动词。②找出两句话中词向量余弦相似度最大的动词对。③利用该动词对和语义角色标注器对两句话进行语义角色标注。
其次,是利用上述方法抽取语义角色作为复述判别模型输入特征的一部分。对于一句话中的第t个词,其原始词向量表示为xt∈dword,其语义角色标签对应的特征向量表示为ft∈dsrl。我们将语义角色特征向量同词向量拼接起来,作为新的单词t的向量表示t,作为LSTM层的输入。
1.4 Dropout策略
考虑到复述判别的训练集较小,深层的神经网络容易产生过拟合的问题,我们在LSTM层的输出时使用Dropout策略来缓解过拟合的问题。Dropout策略指的是在训练阶段将向量中的每一维按照一定的概率p屏蔽,即进行清零操作,然后在测试阶段将该向量的每一维按照p的比例进行缩小。加入Dropout之后,计算方式如下:
其中p表示按照p大小的概率进行向量按维清零操作。
1.5 训练策略
本文中使用的最终分类模型是逻辑斯蒂回归模型。给定训练样例:
其中x(i)表示第i个训练句子对,y(i)∈{0,1}表示第i个训练样例正确分类结果。我们的网络模型可以使用式(17)概括:
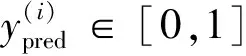
给定训练数据和模型预测结果,我们可以使用极大似然法估计模型参数,其中设模型预测结果是1和0的概率分别如式(18)所示。
则其似然函数为:
对于整个训练集来讲,总的对数似然函数为:
我们训练时使用随机梯度下降(stochastic gradient descent)算法进行梯度更新。
2 实验
2.1 实验设置
文本复述判别语料我们使用的是微软提供的MSRP语料,该语料中训练集包含4 508个句子对,测试集包含1 720个句子对。抽取语义角色特征时训练使用的语料是英文语义角色标注评测语料CoNLL-2005,使用的是Wang等人[12]提出的语义角色标注模型,词性标注器是斯坦福大学的CoreNLP工具包*斯坦福大学自然语言处理工具: Stanford CoreNLP。下载地址为https://stanfordnlp.github.io/CoreNLP/。。针对句子中每个词的语义角色形式也同Wang等人一样使用IOBES标记形式,初始词向量我们使用的是Glove词向量*Glove词向量是由斯坦福大学提供的一种英文词向量表示。下载地址: https://nlp.stanford.edu/projects/glove/.。
本文中提出的复述判别模型参数具体设置如下: 词向量维数100;语义角色特征向量维数60;LSTM隐层和输出层向量维数为100;LSTM层数为1;Memory向量维数100; Dropout 中p值取0.5;训练学习率为0.05;实验中采用mini-batch训练策略,batch大小为20。
我们的实验模型也使用了前人在深度学习模型中使用过的特征,并加入到了逻辑斯蒂回归分类层。使用的特征分为两种: 第一种是Yin等人[10]在他们的卷积网络模型中也使用的八种机器翻译评价指标特征;第二种是 Socher 等人[7]自动编码器模型中使用的识别两句话中数字是否相同的特征。我们使用的特征和上面两种深度学习方法使用的特征在数量级上相同。
2.2 实验结果和分析
表1展示了本文中提出的模型在MSRP语料测试集上的效果。其中: LSTM是只使用一层LSTM的基础模型;LSTM+Attention是本文中提出的基于注意力机制的 LSTM 基础模型;EM-LSTM是本文提出的加入单层记忆单元的LSTM模型; EM-LSTM+SRL 在记忆单元基础上加入语义角色特征的模型。可以看出,随着模型的不断改进,实验效果也不断的提升。LSTM作为所有实验的对照组,在加入注意力机制后,效果有一定的提升,说明注意力机制确实可以抽取出句子中词汇级别的语义联系。当使用我们提出的单层记忆单元来取代原有注意力机制时,效果进一步提升,说明我们使用的记忆单元确实可以识别并存储两句话中更丰富的不同层次的语义联系。在加入语义角色特征后,实验结果在两种指标上都又有提升,这说明同为语义理解任务的语义角色知识确实可以帮助复述判别。
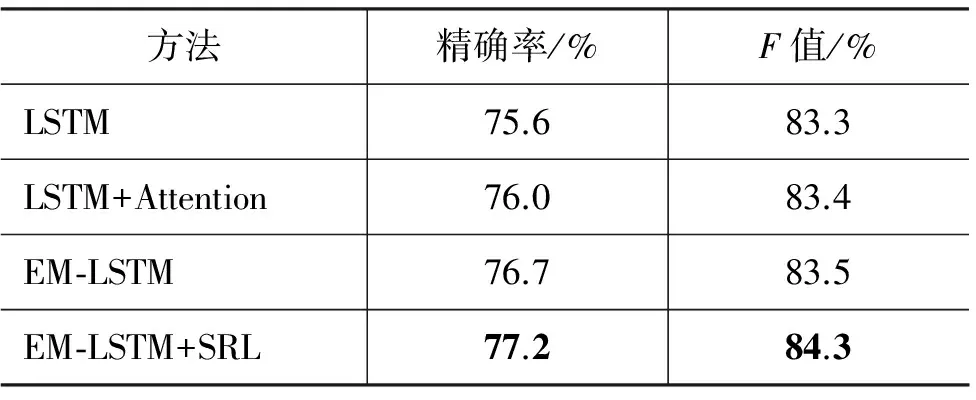
表 1 本文提出的模型在MSRP测试集上的实验结果
表2展示了在MSRP语料测试集上同前人方法比较的结果。其中: Majority表示按照训练集中占比最大的复述关系(两句话是复述关系)进行分类的结果;RAE为Socher等人[7]使用递归自动编码器模型识别的结果;A-LSTM是Yin等人[10]在实验部分提到的基于注意力机制的LSTM模型;ABCNN是Yin等人[10]提出的基于注意力机制的多层次卷积神经网络模型;EM-LSTM是本文提出模型的最好效果。同Socher等人提出的RAE相比,我们的模型达到的效果超过了他们利用自编码器结构上不同层次特征表示进行复述判别的效果。我们的实验结果虽然不如Yin等人的多层次卷积模型效果,但是也达到了一个有竞争力的效果。考虑到我们只使用了单层记忆单元存储句子间的语义联系,而他们模型最好的效果使用了两层卷积网络,并且每个卷积层可以拆分为纵向的三个子网络层,因此我们网络层数是远少于他们的。Yin等人在实验部分也给出了只使用一层CNN的效果,精确率为78.1%,F值为84.1%。可以看出,在F值指标上还不如我们模型的效果,这说明我们单层记忆单元的模型确实是有效的,可以在一定程度上达到同多层次模型一样的效果,学习到不同层级的语义联系。
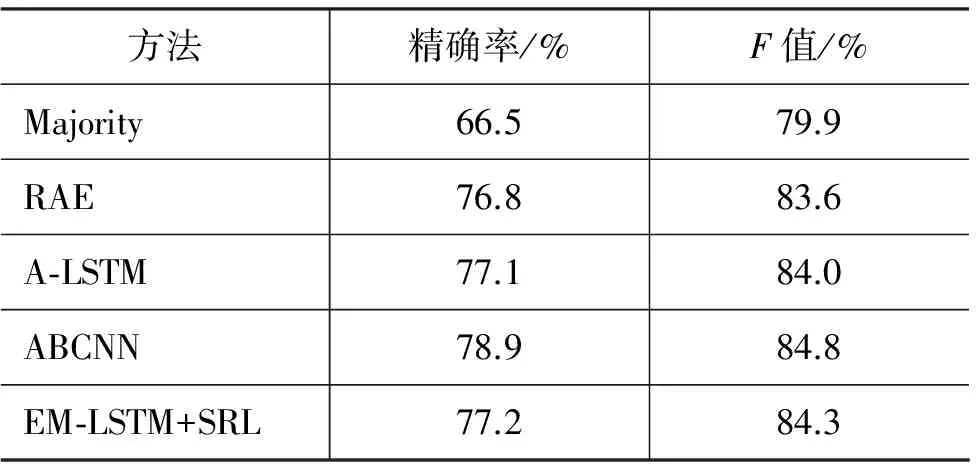
表 2 在MSRP测试集上的实验结果同前人比较
3 前人工作
基于特征的文本复述判别方法通常利用不同的特征来获得不同的语义联系,进而进行复述判别。Wan等人[4]结合机器翻译评价指标BLEU值和一些基于依存关系和树上编辑距离的特征,使用支持向量机(support vector machine)进行分类。Mihalcea等人[13]结合点互信息(pointwise mutual information)、浅层语义分析和基于WordNet测量的词语相似度来生成一个统一的判断是否有复述关系的指标。Qiu等人[14]建立了一个可以检测两句话之间的不同点的架构,利用不同点的显著程度来判断两句话是否有复述关系。Kozareva等人[5]利用最长公共子序列(longest common subsequence)、N元组和WordNet等特征,尝试了支持向量机、k近邻、最大熵等分类器。Fernando等人[15]基于两句话的所有词建立了一个词语的相似度矩阵。Das等人[16]建立了一个两句话之间的对齐模型,并结合逻辑斯蒂回归分类器(logistic regression classifier)进行分类。Blacoe等人[17]利用神经网络语言模型生成词语向量表示,然后通过求和方式生成句子的向量表示特征,进而利用句子向量计算相似度。在诸多基于特征的方法中,效果最好的是Madnani等人[6]在2012年提出的,利用多个不同的机器翻译指标作为特征的分类模型。
虽然基于特征的方法可以捕获一定不同层次的语义信息,但是效果好坏依赖于特征的设计,并且捕获的语义层次有限。随着深度学习的发展,许多研究人员在使用特征的方法的基础上,将原有训练模型使用神经网络代替,并不断加深神经网络层数,旨在自动学习到更多的不同层次语义联系。2011年,Socher等人[7]使用自动编码器分别对两句话构建贪心的树结构网络,然后计算两个句子网络中不同层次节点之间的余弦相似度,最后将生成的矩阵通过池化的操作得到固定长宽的矩阵作为逻辑斯蒂回归的输入进行分类。更多的研究使用卷积神经网络来处理该任务,通常是两个句子分别建立多层卷积层,然后使用最后一层的结果作为LR的输入进行分类。2014年,Hu等人[8]利用卷积神经网络对句子进行建模。之后,Yin等人[9]针对不同层级的卷积层,引入两句话的相似度交互信息。更进一步,Yin等人[10]在之前卷积神经网络工作的基础上,加入注意力机制,利用两个句子相同层次上的网络向量计算注意力矩阵,通过该矩阵辅助指导不同层卷积层之间的更新。
在前人的工作中,基于特征的方法主要利用机器翻译等指标作为特征,而不同的机器翻译评价指标同质化严重,没有蕴含足够多的语义知识。基于多层次神经网络模型的方法为了挖掘不同层次的语义联系,使用了不同层次的网络,在训练时加重了梯度消失和梯度爆炸的问题。前人的卷积神经网络模型单是卷积层就使用两层以上,这增加了模型训练的难度。
4 总结
针对英文文本复述任务,本文提出了一种结合语义角色知识的轻量级单层记忆单元网络模型。该模型通过语义角色特征捕获了更多语义联系,并使用单层记忆单元存储了不同层次的语义联系,起到了压缩多层次网络模型层数的作用,便于模型训练。通过实验,我们的轻量级模型达到了与多层次神经网络模型接近的效果。
[1] Erwin Marsi, Emiel Krahmer. Explorations in sentence fusion[C]//Proceedings of the European Workshop on Natural Language Generation, 2005: 109-117.
[2] Paul Clough, Robert Gaizauskas, Scott SL Piao, et al. Meter: Measuring text reuse[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002: 152-159.
[3] Chris Callison-Burch. Syntactic constraints on paraphrases extracted from parallel corpora[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2008: 196-205.
[4] Stephen Wan, MarkDras, Robert Dale, et al. Using dependency-based features to take the“parafarce” out of paraphrase[C]//Proceedings of the Australasian Language Technology Workshop, 2006.
[5] Zornitsa Kozareva, Andrés Montoyo. Paraphrase identification on the basis of supervised machine learning techniques[C]//Proceedings of the Advances in natural language processing. Springer, 2006: 524-533.
[6] Nitin Madnani, Joel Tetreault, Martin Chodorow. Re-examining machine translation metrics for paraphrase identification[C]//Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2012: 182-190.
[7] Richard Socher, Eric H Huang, Jeffrey Pennington, et al. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection[C]//Proceedings of the NIPS, 2011: 801-809.
[8] Baotian Hu, Zhengdong Lu, Hang Li, et al. Convolutional neural network architectures for matching natural language sentences[C]//Proceedings of the Advances in neural information processing systems, 2014: 2042-2050.
[9] Wenpeng Yin, Hinrich Schütze. Convolutional Neural Network for Paraphrase Identification[C]//Proceedings of the HLT-NAACL, 2015: 901-911.
[10] Wenpeng Yin, Hinrich Schütze, Bing Xiang, et al. Abcnn: Attention-based convolutional neural network for modeling sentence pairs[C]//Proceedings of the arXiv preprint arXiv:1512.05193, 2015.
[11] Hochreiter Sepp, Jürgen Schmidhuber. Long short-term memory[C]//Proceedings of the Neural computation, 1997: 1735-1780.
[12] Zhen Wang, Tingsong Jiang, Baobao Chang, et al. Chinese semantic role labeling with bidirectional recurrent neural networks[C]//Proceedings of the EMNLP, 2015: 1626-1631.
[13] Rada Mihalcea, Courtney Corley, Carlo Strapparava, et al. Corpus-based and knowledge-based measures of text semantic similarity[C]//Proceedings of the AAAI, 2006: 775-780.
[14] Long Qiu, Min-Yen Kan, Tat-Seng Chua. Paraphrase recognition via dissimilarity significance classification[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, 2006: 18-26.
[15] Samuel Fernando, Mark Stevenson. A semantic similarity approach to paraphrase detection[C]//Proceedings of the 11th Annual Research Colloquium of the UK Special Interest Group for Computational Linguistics, 2008: 45-52.
[16] Dipanjan Das, Noah A Smith. Paraphrase identification as probabilistic quasi-synchronous recognition[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009(1): 468-476.
[17] William Blacoe, Mirella Lapata. A comparison of vector-based representations for semantic composition[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012: 546-556.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
