
一种基于云计算的大数据关联规律挖掘分析方法
2017-03-02 11:07陈勇
无线电工程 2017年3期
陈 勇
(中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
一种基于云计算的大数据关联规律挖掘分析方法
陈 勇
(中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
随着云计算时代的到来,云计算为海量数据的挖掘分析提供了一种新的技术途径,能够有效地解决传统数据挖掘方法不能适应海量数据挖掘的问题。介绍了云计算的含义和特点,分析了运用云计算技术实现数据挖掘的优势,设计了基于MapReduce并行处理架构的关联规律挖掘算法,并开展了试验验证。试验结果表明,基于云计算平台的并行关联规律挖掘算法能够极大地提高数据挖掘的执行速度。
云计算;数据挖掘;大数据处理
0 引言
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的应用数据中提取隐藏在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程[1]。云计算采用分布式计算模式,将计算任务分配到不同的计算节点上,根据用户的业务需求动态组成相适应的计算和存储服务能力,云计算为存储和分析海量数据提供了高效的存储和计算平台[2-3]。云计算平台下的并行数据挖掘算法设计是解决大数据挖掘分析的关键技术,具有重要的理论意义和应用价值。
本文利用Hadoop中的MapReduce分布式并行计算框架设计了并行化的FP-Growth算法,实现了大规模数据的快速深度分析。
1 大数据关联规律挖掘的理论分析
1.1 关联规律挖掘理论
关联规律挖掘分析是一种重要的数据分析方法,主要用于发现存在于大量数据集中的数据属性取值之间的关联规律,关联规律挖掘的问题描述如下:
假定:I={i1,i2……,im}是所有数据属性可能取值的集合,D是所有交易记录的集合(即数据库),每条交易记录T是一些项目的集合,T包含在I中,即每条交易记录由若干个属性及其取值的键值对组成,每条交易记录可以用唯一的标识符TID来标识。设X为某些数据属性取值的集合,如果X包含在T中,则称交易记录T包含X,关联规律可表示为如下形式(X包含在T)=>(Y包含在T)的蕴涵式,这里X包含在I中,Y包含在I中,并且X∧Y=Ø。其意义在于一个事务中某些数据属性取值的出现,可推导出另一些数据属性取值在同一事务中也出现,可将(X包含在T)=>(Y包含在T)表示为X=>Y,此处,‘=>’称为‘关联’操作,X称为关联规律的先决条件,Y称为关联规律的结果[4]。
所有交易记录的集合D中的规律X=>Y有2个指标:支持度s(support)和置信度c(confidence),c表示规律的可信强度,c越高说明此规律的因果关系越强;s表示以整个数据库中的数据为背景,一项规律出现的频度,s越高说明此规律越具有应用价值。数据属性取值集合X的支持度s(X)是D中包含X的交易记录数量与D中所有交易记录数量之比。
规律X=>Y的支持度s定义为:在D中包含X∪Y的交易记录所占比例为s%,表示同时包含X和Y的交易记录数量与D中所有交易记录数量之比;规律X=>Y的置信度c定义为:在D中,c%的交易记录包含X的同时也包含Y,表示D中包含X的交易记录中有多大可能性包含Y。
最小支持度阈值minsupport表示数据属性取值集合在统计意义上的最低应用价值。最小置信度阈值minconfidence表示规律的最低可信度。一般由用户给定minconfidence和minsupport。置信度和支持度大于相应阈值的规律称为强关联规律,反之称为弱关联规律。发现关联规律的任务就是从数据库中发现那些置信度、支持度大小等于给定值的有效规律。
找出数据库D中所有大于等于用户指定最小支持度的数据属性取值集合(itemset),具有最小支持度的数据属性取值集合称为频繁项目集,项目集的支持度是指包含该项目集的交易记录数量。
利用频繁项目集生成所需要的关联规律,对每一频繁项目集A,找到A的所有非空子集a,如果比率满足support(A)/support(a)>=minconfidence,那么就可以生成关联规律a=>(A-a)。而support(A)/support(a)是规则a=>(A-a)的置信度。
1.2 关联规律挖掘算法
事实上,在挖掘关联规律的过程中找到所有的频繁项目集是核心问题。当找到所有的频繁项目集后,相应的关联规律将很容易产生。
Apriori算法是进行关联规律挖掘的常用方法,Apriori算法包括两步[5]:第1步,统计所有含一个属性-取值键值对出现的频率,并找出那些不小于最小支持度的属性-取值键值对集,即一维频繁项目集;从第2步开始进入一个循环处理过程直到找出所有频繁键值对集。这一循环过程可以描述如下:第k步中,根据第k-1步生成的(k-1)维频繁属性-取值键值对集产生k维候选属性-取值键值对集,然后对数据库进行搜索,得到候选属性-取值键值对集的支持度,与最小支持度比较,从而找到k维频繁属性-取值键值对集。Apriori算法对候选属性-取值键值对集进行甄别,删除那些不可能成为频繁属性-取值键值对集的候选属性-取值键值对集。这样就节省了花费在这些不合格候选属性-取值键值对集上的数据库搜索时间,但Apriori算法仍有以下缺点[6-7]:
每次计算属性-取值键值对集的支持度时,都需要对D中的全部记录进行一遍遍历比较。如果数据库规模很大,这种逐条比较的运算时间就会很长。
为了解决Apriori算法的上述缺点,FP-Growth算法采用以下策略:首先,将数据库中的内容映射到一棵频繁模式树(FP-Tree),但仍保留属性-取值键值对集的关联信息;然后,将FP树按照频繁模式投影,分为若干条件数据库,并分别挖掘每个数据库。
FP-Growth算法将一个大型数据库映射成比原数据库规模小很多的高密度的数据结构,避免了重复遍历数据库[8]。该算法基于FP树采取模式增长的递归策略,是一种无候选项集的挖掘方法,在进行频繁项集的挖掘时效率很高。FP-Growth算法的执行步骤如下:
① 遍历一次D得到所有频繁属性-取值键值对及其支持度数值,并对频繁属性-取值键值对按其支持度计数从高到低进行排序,并构建头表;
② 再次遍历D,将读取的每条记录按照第①步的频繁属性-取值键值对顺序进行排序,排序后以null为根结点构建一条FP树的路径,对路径上项的计数+1,在插入FP树过程中查找头表里对应的属性-取值键值对,建立链表索引;
③ 从头表尾部向上遍历频繁属性-取值键值对集,每次循环过程中从头表的链表里访问FP树得到条件模式,根据条件模式构建每个频繁属性-取值键值对的条件FP树;
④ 从条件FP树分单分支和多分支2种情况递归挖掘频繁属性-取值键值对集。
但是,对于海量数据而言,FP-Growth算法的时空复杂度仍然很高,因此,对于大数据挖掘应用而言,FP-Growth算法仍有进一步改进的必要[9]。在本项研究中,利用云计算平台Hadoop中的MapReduce分布式并行处理模型设计并行版的FP-Growth算法,通过充分发挥多机并行处理的优势,提高挖掘分析计算的效率,。
2 基于云计算的关联规律算法设计
2.1 Hadoop平台
Hadoop是Apache机构的一个开源产品,能够以分布式存储和并行计算方式处理海量数据。其分布式存储Hadoop Distributed File System(HDFS)能够在多个节点上存储数据,数据被分割成更小的数据块分别存储在不同节点上,因此,可以同时向多个节点上存储数据,也可以同时从多个节点上读取数据,除了HDFS文件系统外,Hadoop产品还包括并行处理模型MapReduce[10],将各类运算都抽象为Map运算[11]和Reduce运算[12],使得用户不必关心并行处理过程中的作业调度和节点间的数据交换等繁琐细节,只需专注业务处理逻辑,并充分利用计算机集群的协作能力实现高速业务运算[13-14]。
由于FP-Growth算法将数据库记录数据中的频繁部分在内存中映射成FP树,当数据规模很大时,FP树会很庞大,因此,算法中FP树的构建属于计算密集型业务。在本文中,基于MapReduce的并行处理模型来提高FP树的构建效率。
MapReduce并行处理模型的原理就是利用一个输入的键值对集合来产生一个输出的键值对集合[15-16]。MapReduce任务过程被分为Map环节和Reduce环节。Map环节负责把计算任务分解为多个作业,Reduce环节负责把分解后的多个作业的处理结果汇集起来,用户需要定义2个函数:Map和Reduce,Map函数接收输入数据,并分割成固定大小的片段,随后将每个片段进一步分解成一批键-值对
2.2 基于MapReduce的挖掘算法设计
基于MapReduce的并行FP-Growth算法设计如下:
第1步: 通过一次MapReduce任务统计属性-取值键值对的频繁度。FP-Growth算法在构造FP树之前需扫描一遍数据库统计属性-取值键值对的频繁度并排序,这实际上是FP-Growth算法的第①步。
第2步: 通过一次MR任务执行MR-FP算法计算频繁项集。在MR-FP算法中利用MapReduce并行处理模型对传统FP-Growth算法的第②、③、④步进行并行设计,这是算法的核心任务,通过此次MapReduce任务将FP-Growth算法中对各频繁属性-取值键值对的条件FP树的挖掘运算分发到各个节点,进行本地计算,再汇集各个节点的局部计算结果,形成最终结果。
基于Hadoop集群的MapReduce框架实现上述步骤的具体方法描述如下:
第1步:对所有的输入进行统计,统计出每一项的出现频率,这一点可以通过Hadoop下一个词频统计任务(wordcount任务)完成,对输出结果按照频率进行降序排列,得到词表F-list。
第2步:对所有F-list中的词进行分组,生成组表G-list,组号为id,将对应的输入分别在Map中进行输出。
第3步:当Reduce接收到Map端的输入后,对数据进行本地化的FP-Growth算法计算,将超过支持度阈值的项进行输出。
第4步:对结果进行聚合、排序以及相关的统计。
Map阶段算法的核心伪代码如下:
LoadG-List;
Generate Hash TableHfromG-List;
a[]←Split(Ti);
forj=|Ti|-1 to 0 do
HashNum←getHashNum(H,a[j]);
ifHashNum≠Nullthen
Delete all pairs which hash value isHashNuminH;
Call Output(
end
end
Reduce阶段算法的核心伪代码如下:
Procedure:Reducer(key=gid,value=DBgid)
LoadG-List
nowGroup←G-Listgid
LocalFPtree←clear;
foreachTiinDBgiddo
Define and clear a size K max heap:HP;
Call TopKFPGrowth(LocalFPtree,ai,HP);
foreachviinHPdo
Call Output(
end
end
3 实验计算与结果分析
为了验证所设计并行FP-Growth算法的正确性以及效率,搭建了一个Hadoop平台开展了相关实验,Hadoop平台计算机集群有28个计算节点,每个节点有1T的硬盘容量,6G的内存空间。实验使用的数据集共含有1百万行数据,每行包含的事物项个数约100个。
首先使用单机版的FP-Growth算法进行测试,将支持度阈值设为1%,单机版的FP-Growth算法会发生outofmemory错误,可见FP-Growth算法本身存在巨大的内存需求。
然后,使用并行版的FP-Growth算法进行测试,测试过程中设置不同的支持度阈值,进行了对比试验,对执行时间、挖掘出的规则数量进行测试,具体测试结果如表1所示。

表1 支持度阈值、运行时间、输出数目的关系
支持度与执行时间关系如图1所示。
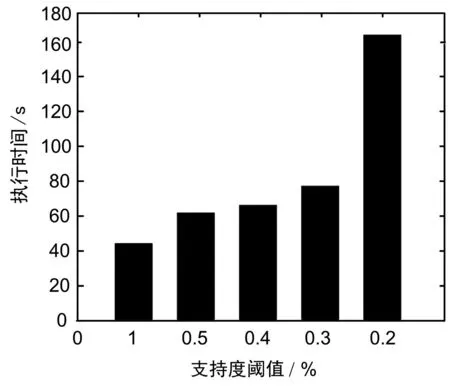
图1 支持度与执行时间关系
通过对实验数据的分析发现,随着支持度阈值的不断降低,无论是执行时间还是输出规则数目都会以指数级的速度增长,尤其是当阈值从0.2%降为0.1%时,输出的数目出现了快速增长,在单机条件下甚至出现运行失败的情况,这是由于阈值过小,剪枝之后的FP树依旧巨大,内存资源无法满足导致的。
并行版的FP-Growth算法非常适合于基于计算机集群的海量数据关联规律挖掘,当集群新增计算节点时,无需对算法进行任何修改就可以继续使用,算法效率与计算节点数量成正比。
4 结束语
关联规律挖掘是大数据分析常用的算法和基础性工具,本文针对海量的结构化数据,基于云计算平台开展了大数据关联规律挖掘算法研究,以发现数据中潜在关联模式和规律,研究成果解决了传统串行数据挖掘算法计算效率低的问题,在保证结果正确的前提下,能够快速地完成数据挖掘分析任务。
[1] 毛国君,段立娟,王 实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005:64-205.
[2] 王 轶,达新宇.分布式并行数据挖掘计算框架及其算法研究[J].微电子学与计算机,2006,23(9):223-225.
[3] 杨武军,郝 凯.基于贪心改进算法的云计算任务调度[J].传感器与微系统,2016,35(12):143-145.
[4] 李晓毅,徐兆棣.关联规则挖掘的算法分析[J].辽宁工程技术大学学报,2006,24(2):319-320.
[5] 朱小琴.Apriori算法的分析与改进[J].广西民族大学学报(自然科学版),2013,19(4):68-71.
[6] 陈丽芳.基于Apriori算法的购物篮分析[J].重庆工商大学学报(自然科学版),2014,31(5):84-89.
[7] 亓文娟,晏 杰.数据挖掘中关联规则Apriori算法[J].计算机系统应用,2013,22(4):121-124.
[8] 石云平.FP-Growth关联算法应用研究[J].计算机与信息技术,2008,10(6):12-14.
[9] 吕萍丽.浅谈Apriori算法[J].电脑知识与技术,2011,7(4):715-716.
[10] 郭景瞻,张文逵.Hadoop平台下的数据迁移设计与实现[J].信息技术与标准化,2014,38(9):39-41.
[11] 张 遥,蒋春娟.基于Hadoop集群的海量数据处理系统[J].网络安全技术与应用,2014,38(10):8-9.
[12] 宛 婉,周国祥.Hadoop平台的海量数据并行随机抽样[J].计算机工程与应用,2014,50(20):115-118.
[13] 刘师语,周渊平,杜 江.基于HADOOP分布式系统的数据处理分析[J].通信技术,2013,46(9):99-102.
[14] 陈吉荣,乐嘉锦.于Hadoop生态系统的大数据解决方案综述[J].计算机工程与科学,2013,35(10):27-35.
[15] 陈 娜,张金娟,刘智琼,等.基于Hadoop平台的电信大数据入库及查询性能优化研究[J].移动通信,2014,38(7):58-63.
[16] 蔡斌雷,任家东,朱世伟,等.基于Hadoop MapReduce的分布式数据流聚类算法研究[J].信息工程大学学报,2014,15(4):472-478.
[17] 杨 勇,高松松.基于MapReduce的关联规则并行增量更新算法[J].重庆邮电大学学报(自然科学版),2014,26(5):670-678.
[18] 张 帅,赵卓峰,丁维龙,等.基于MapReduce的城市道路旅行时间实测计算[J].计算机与数字工程,2014,299(9):1 542-1 546.
陈 勇 男,(1968—),高级工程师。主要研究方向:数据挖掘。
A Method of Mining Association Rules of Big Data Based on Cloud Computing
CHEN Yong
(The54thResearchInstituteofCETC,ShijiazhuangHebei050081,China)
With the cloud computing era coming,data mining methods based on cloud computing appear to be reliable and efficiency,compared to traditional centralized data mining approaches.In this paper,concepts,strengths and characteristics of cloud computing are introduced.A data mining algorithm based on MapReduce framework is presented.And experiments based on the algorithm are conducted.Experimental results show that the algorithm significantly improves data mining speed.
cloud computing;data mining;big data processing
10.3969/j.issn.1003-3106.2017.03.02
陈 勇.一种基于云计算的大数据关联规律挖掘分析方法[J].无线电工程,2017,47(3):8-11.
2016-12-23
中国博士后科学基金资助项目(2015M580217)。
TP311
A
1003-3106(2017)03-0008-04
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
大众投资指南(2021年35期)2021-02-16
电脑爱好者(2020年18期)2020-09-26
中国交通信息化(2020年1期)2020-07-27
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
电脑爱好者(2017年9期)2017-06-01
读者(2017年5期)2017-02-15
信息通信技术(2015年6期)2015-12-26
智能系统学报(2013年1期)2013-01-28
