
一种具有降噪能力的概率主题模型
2017-03-02 08:31:06秦永彬黄瑞章
计算机与数字工程 2017年2期
李 晶 秦永彬 黄瑞章
(1.贵州省公共大数据重点实验室 贵阳 550025)(2.贵州大学计算机科学与技术学院 贵阳 550025)
一种具有降噪能力的概率主题模型
李 晶1,2秦永彬1,2黄瑞章1,2
(1.贵州省公共大数据重点实验室 贵阳 550025)(2.贵州大学计算机科学与技术学院 贵阳 550025)
大数据时代的到来使得文本数据的数据量暴增,因此准确而高效地识别和分析文本数据的潜在结构变得越来越重要。要从海量的数据中挖掘模式和知识,需要借助于强大的计算工具,所以机器学习科学家提出了概率主题模型。当前,以隐含狄利克雷分布(LDA)模型为代表的经典概率主题模型已经被广泛地应用到数据挖掘的各个方面。由于LDA模型对区分相似主题的能力非常差,影响了LDA的实际应用性能,为解决这一重要问题,论文基于LDA模型提出了一种名为NRLDA的新模型。考虑到相似主题的文本中存在大量的对区分不同主题没有贡献的噪音词语,在NRLDA中引入了相关变量来区分有用词和噪音词,使噪音词从一个噪音主题的词分布中产生,而有用词从多个特征主题的词分布中产生,从而削弱噪音词所带来的不良影响。此外,我们还使用吉布斯抽样方法对NRLDA的参数进行了推断,这些参数对分析文本数据中潜藏的结构有至关重要的作用。实验结果表明我们的NRLDA模型有较强的区分相似主题的能力,这同时也验证了我们建模思想的正确性。
概率主题模型; 隐含狄利克雷分布; 吉布斯抽样; 降噪
Class Number TP181
1 引言
大数据时代的到来使得各种类型数据的数据量急剧增加,而文本作为承载人类知识的最主要媒介,其增加的速度和幅度是其他类型的数据所不能比拟的,更好地把握和理解文本数据的潜在结构就变得越来越重要。人工去整理某文本语料库的文本结构所需要的时间开销是巨大的。当前,查找和管理文本数据的常见方法是搜索和链接,但这种方法只对词句做字面上是否全等的比对而忽略了潜藏在词句之下的文本结构,所以这种方法并不能帮助我们把握文本数据的结构。我们需要一种新的计算工具来帮助发现潜在的文本结构。基于这种需要,机器学习科学家提出了主题模型(Topic Model)[1],它是一类通过发现文本数据下潜藏的主题信息来呈现文本数据的结构的机器学习算法。这种挖掘出文本中的主题信息,然后利用主题信息来体现文本结构的方法非常符合人类对文本数据的认知习惯[2]。
主题模型经历了一个从简单到复杂的发展过程,其间诞生的比较著名的模型有概率的隐含语义分析(probabilistic Latent Semantic Analysis,pLSA)[3]和隐含狄利克雷分配(Latent Dirichlet Allocation,LDA)[4]等。迄今为止,LDA仍是最为经典、应用领域最广泛的主题模型。然而,LDA在某些情况下的性能表现不能让人满意,比如,其无监督机器学习模型[5]的天性决定了它不能对珍贵的监督信息加以利用;其基于大量词语的统计信息来挖掘主题信息的特点致使其针对短文本的主题信息挖掘的效果很差;其对文本挖掘主题信息前必须提前指定主题个数并且不能动态调整也给其带来了一定的局限性等。正是因为LDA算法优秀的同时又有许多有待进一步改进的地方,许多学者基于LDA提出了一些新的类LDA模型[6~9]来解决LDA所不能解决的问题。比如,针对LDA不能利用监督信息的缺陷,文献[6~7]分别在LDA模型的基础上提出了Labeled LDA和PLDA模型,这些模型能够利用文本的标签信息作为监督信息来帮助主题信息的挖掘;类似的,文献[8]提出的SCLDA模型把先验知识作为监督信息来指导主题信息的挖掘。并且这些文献中给出的实验结果均表明主题信息的挖掘效果均优于原始的LDA。再如,针对LDA对短文本的主题信息挖掘效果很差的问题,文献[9]基于LDA模型提出的DLDA模型采用长文本辅助短文本的方法,使对短文本主题信息的挖掘效果明显改善。
我们发现LDA模型区分相似主题的能力很差。假设某个文本语料库中的所有文档均来源于三个相似但又互不相同的主题,可以认为所有文档同属于一个大范畴下。使用LDA模型对该语料库进行主题信息的挖掘,并根据每篇文档中三个主题的概率分布情况对所有文章进行聚类,最后发现聚类结果很差。这是因为非常相似的主题会有许多共享的词语,这些共享的词语在这些相似的主题中都会频繁出现,即它们不是某一个主题下的特异性词语,而是这些相似主题所属的大范畴下的常见词语,例如,三个相似而又不同的主题分别是Linux操作系统、Windows操作系统和计算机操作系统,这三个主题同属于计算机这个大范畴下,那么经常出现于计算机这个主题下的词语,像“计算机”、“操作系统”、“用户界面”等,会频繁出现在这三个相似的主题下,这些词语并不是这三个主题中的某一个所特有的,它们并不会为区分这三个主题做贡献,则对于这三个主题而言,这些共享词语就是噪音词语。这些噪音词语对区分相似的主题不但没有贡献,反而会使得相似主题之间的界限变得更加模糊。LDA没有考虑噪音词语大量存在的情况,这导致它区分相似主题的能力很差,所以我们有必要削弱噪音词语带来的不良影响,即降噪。我们尚未见到有针对LDA的这一缺陷而提出解决方案的相关文献。
本文基于LDA模型提出一种具有降噪能力的新模型NRLDA(Noise Reduction LDA)。此模型中在NRLDA中引入了相关变量来区分有用词和噪音词,使噪音词从一个噪音主题的词分布中产生,而有用词则遵循LDA中词的生成过程从多个特征主题的词分布中产生,从而削弱噪音词所带来的不良影响;使用吉布斯抽样[10]的方法求解了NRLDA模型中的参数,并给出了详细、具体的吉布斯抽样公式;最后,在真实数据集上的对比实验表明,我们提出的NRLDA模型在区分相似主题上的表现上明显优于LDA,有较强的降噪能力。
2 LDA模型
LDA模型是一个贝叶斯概率图模型[11],其将每个文档视为潜在主题的混合分布来建模,每篇文档中的每个词都是由某个主题的词分布生成的。LDA的图模型如图1所示,图中用两个圆圈表示的节点是证据节点,代表可见的变量或参数,是已知的;图中用一个圆圈表示的节点是隐藏节点,代表隐含的变量或参数,是未知待求的;对应的生成过程如下所示。
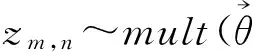
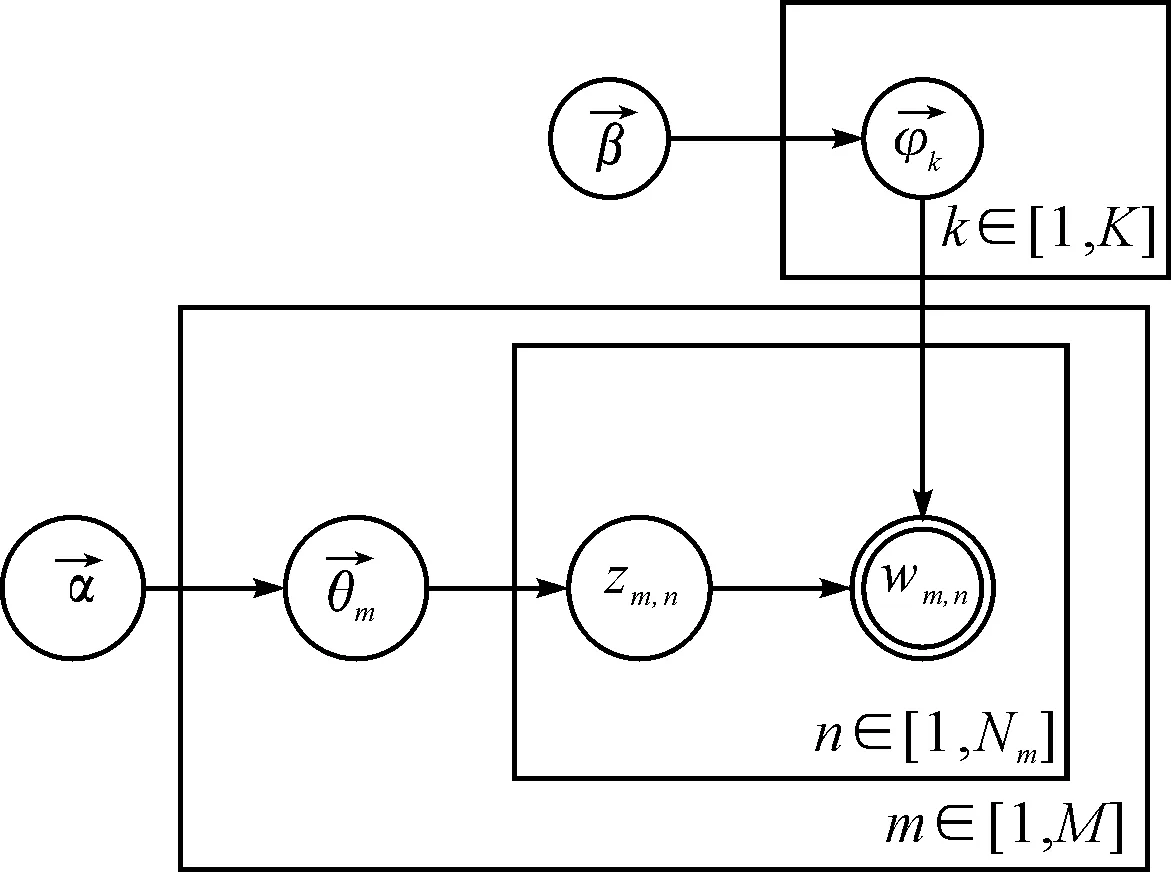
图1 LDA的图模型表示
3 NRLDA模型及其参数推断
3.1 NRLDA模型
本文在LDA的基础上提出了NRLDA模型,其图模型如图2所示,对应的生成过程如下:
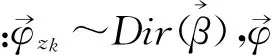
2) 对每一篇文档m∈{1,…,M}
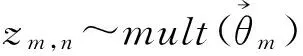

图2 NRLDA的图模型表示
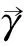
3.2 NRLDA模型的参数推断
根据NRLDA的图模型和生成过程,可以得到生成某一文档的似然函数,即给定超参数时,所有已知变量和隐含变量的联合分布:
(1)
(2)
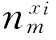
(3)
(4)

再由狄利克雷分布的期望公式可得:
(5)
(6)
4 实验
4.1 数据集
在实验中使用到两个数据集,分别是News-sim-3和News-diff-3。这两个数据集都来源于经典的文本语料数据集20newsgroup[16],此数据集由20个类别的新闻文章构成,每个新闻类别下均包含大约1000篇新闻文章。我们从20个类别中选取3个彼此非常相似的类别,然后把这3个类别下的所有文章组成一个数据集,即News-sim-3;再从20个类别中选取3个彼此差异非常大的类别,然后把这3个类别下的所有文章组成一个数据集,即News-diff-3。
实验之前,先对这两个数据集做了一定的文本预处理,包括去除停用词,剔除词频过高或过低的词,过滤文章中的一些说明信息,排除过长和过短的文章等,以尽可能提高文本结构分析的效果。因为进行了文本预处理,所以News-sim-3和News-diff-3这两个数据集中的文章个数并不是三个类别中的文章数相加,事实上,这两个数据集中的文章数目均小于3000。数据集的基本信息如表3所示。
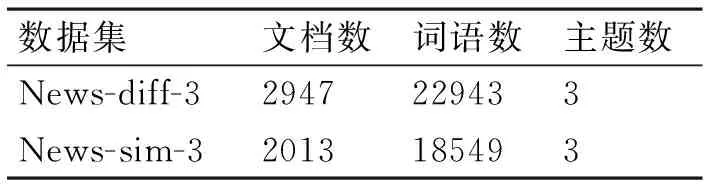
表3 数据集的基本信息
4.2 实验设计和评判标准
分别使用LDA和NRLDA分析News-sim-3和News-diff-3这两个数据集的文本结构。在得到数据集中每篇文章的主题分布情况后,依据出现概率最高的主题来对数据集中的文章进行聚类,然后检验聚类的效果。聚类效果越好说明模型对文本结构分析的能力越强。
因为事先已经知道了数据集中每篇文章所属的真实类别,所以就可以通过比对聚类结果和每篇文章的真实类别来评判聚类的效果。具体为通过计算数据集中所有文章的聚类结果和文章真实类别的NMI(正则化的互信息)值[17]来评判聚类结果的好坏。NMI是用来衡量两个分布的相似程度的,其值介于0和1之间,NMI的值越大,说明两个分布越相似,聚类效果越好。NMI的定义式如式(7)所示:
(7)
其中d表示数据集中的文章数量,dh表示真实类别是h的文章数量,cl表示实验结果中类l中的文章数量。
4.3 实验结果与分析
首先,将LDA模型和NRLDA模型分别应用到对数据集News-sim-3和News-diff-3的文本结构分析中,在每个数据集上都运行10次LDA算法和10次NRLDA算法,并记录每次实验结果的NMI值,最后求NMI的平均值,实验结果如表4所示。
表4中的结果显示,LDA模型分析数据集News-diff-3的结果较好,而分析数据集News-sim-3的结果则非常差。考虑到数据集News-sim-3中的文章来源于三个非常相似的主题,所以这个实验结果说明了LDA模型对相似主题的区分能力很差。表四中,NRLDA在两个数据集上的NMI结果是在NRLDA的参数b最优时得到的,下文中有针对参数b的取值对结果好坏影响的讨论。

表4 LDA和NRLDA分析不同数据集的结果

图3 LDA和NRLDA对News-sim-3分析结果对比

(8)
另外,可以通过调整γ0和γ1的值将b的方差控制得较小,以使整个语料库中所有的文章对应的b的取值相对集中。
因为p(xi=1)=b,则E(b)越大说明语料库中的每个词语wm,n对应的xi取值为1的可能性就越大,同时也意味着模型认为的噪音词语在语料库的所有词语中所占的比重越小。从图3可知,当E(b)的取值非常小时,NRLDA的NMI值甚至低于LDA的NMI值,这是因为此时模型认为的噪音词语所占比重非常大,而事实上语料库中噪音词语所占的真实比重并没有那么大,结果是,模型会把大量非噪音词语当成噪音词语来处理,使得大量原本带有明显主题倾向的词语被当成了无用的噪音词,文本结构的分析效果不如LDA是正常的;随着E(b)不断增大,模型认为的噪音词语所占的比重不断减小,NRLDA文本结构分析的效果逐渐改善并优于LDA模型;当E(b)增大到一定程度时,NMI取到最大值,文本结构分析效果达到最好,说明此时模型认为的噪音词语所占的比重和语料库中噪音词语所占的真实比重最接近;随着E(b)进一步增大,模型认为的噪音词语所占比重进一步减小,和语料库中噪音词语的真实比重相差越来越大,则文本结构分析的效果逐渐变差,反映到图3上就是NMI的值逐渐减小;直到E(b)增大到1时,模型认为的噪音词语所占比重非常小,此时NMLDA已经基本退化成了LDA,反映到图3上就是二者NMI的取值几乎相同。这个对比实验表明,在区分相似主题的能力上,NRLDA模型明显要优于LDA模型,证明了NRLDA有较强的降噪能力。表4中NRLDA在两个数据集上取得的NMI值,就是在E(b)最优时得到的;NRLDA在News-diff-3上的实验结果表明NRLDA区分互相之间差别很大的主题的能力和LDA相当。
5 结语
本文针对LDA模型区分相似主题能力差的缺陷,在LDA模型的基础上,提出了一种具有一定降噪能力的新主题模型NRLDA,并通过在真实数据集上的一系列实验对NRLDA分析文本结构的效果进行了分析,证明了NRLDA模型有较强的区分相似主题的能力。与基于LDA模型做改进的其他模型相比,NRLDA模型对LDA模型的改进简洁而清晰,但效果却比较明显。尽管LDA是最为经典的主题模型,但其仍然存在许多缺陷,值得我们去改进,比如将个人的喜好作为监督信息融入到模型中去,我们正在进行这方面的工作。另外,相对于LDA模型,该模型虽然取得了较明显的性能改善,但如何更大程度地提高文本结构分析的能力,还有待进一步研究。
[1] Blei D M. Probabilistic topic models[J]. Communications of the ACM, 2012, 55(4): 77-84.
[2] Chang J, Gerrish S, Wang C, et al. Reading tea leaves: How humans interpret topic models[C]//Advances in neural information processing systems. Cambridge: MIT press, 2009: 288-296.
[3] Hofmann T. Probabilistic latent semantic indexing[C]//Proc of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. New York: ACM, 1999:50-57.
[4] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation [J]. The Journal of machine learning research, 2003,3:993-1022.
[5] Murphy K P. Machine learning: a probabilistic perspective [M]. Cambridge: MIT press,2012:9-16
[6] Ramage D, Hall D, Nallapati R, et al. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora[C]//Proc of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1. Stroudsburg: Association for Computational Linguistics,2009:248-256.
[7] Ramage D, Manning C D, Dumais S. Partially labeled topic models for interpretable text mining[C]//Proc of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. New York: ACM,2011:457-465.
[8] Yang Y, Downey D, Boyd-Graber J, et al. Efficient Methods for Incorporating Knowledge into Topic Models[C]//Proc of the 2015 conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics,2015:308-317.
[9] Jin O, Liu N N, Zhao K, et al. Transferring topical knowledge from auxiliary long texts for short text clustering[C]//Proc of the 20th ACM international conference on Information and knowledge management. New York: ACM,2011:775-784.
[10] Resnik P, Hardisty E. Gibbs sampling for the uninitiated[R]. Maryland Univ College Park Inst for Advanced Computer Studies,2010.
[11] Koller D, Friedman N. Probabilistic graphical models: principles and techniques [M]. Cambridge: MIT press,2009.
[12] Griffiths T L, Steyvers M. Finding scientific topics [J]. Proc of the National Academy of Sciences,2004,101(suppl 1):5228-5235.
[13] Murphy K P. Machine learning: a probabilistic perspective [M]. Cambridge: MIT press,2012:841-844.
[14] Jordan M I, Ghahramani Z, Jaakkola T S, et al. An introduction to variational methods for graphical models[J]. Machine learning,1999,37(2):183-233.
[15] Andrieu C, De Freitas N, Doucet A, et al. An introduction to MCMC for machine learning [J]. Machine learning,2003,50(1-2):5-43.
[16] UCI KDD 20 newsgroups entry [DB/OL]. [2013-05-10]. Http://Kdd.ics.uci.edu/databases/20newsgroups/20newsgroups.html
[17] Strehl A, Ghosh J, Mooney R. Impact of similarity measures on web-page clustering[C]//Proc of Workshop on Artificial Intelligence for Web Search Austin: AAAI Press. 2000:58-64.
A Probabilistic Topic Model with Noise Reduction Ability
LI Jing1,2QIN Yongbin1,2HUANG Ruizhang1,2
(1. Guizhou Provincial Key Laboratory of Public Big Data, Guiyang 550025) (2. College of Computer Science and Technology, Guizhou University, Guiyang 550025)
With the arrival of big data era, recognizing and analyzing the hidden structure of text data efficiently has been more and more important. Powerful computational tools are needed to help understand text data better. Probabilistic topic models, especially the Latent Dirichlet Allocation (referred as LDA) model, have been proposed and applied in machine learning and text mining widely. Because the LDA model has very poor ability to distinguish similar topics, which has a bad influence on its practical performance. In order to solve this important problem, a new topic model named Noise Reduction Latent Dirichlet Allocation (referred as NRLDA) is proposed on the basis of LDA. There are a lot noise words making no contribution to discriminating similar topics, so this phenomenon is taken into consideration by introducing new variables to distinguish the different generative processes of noise words and non-noise words, which is absolutely beyond LDA’s ability. Besides, a gibbs sampler is developed to infer NRLDA’s parameters which is critical to investigating the structure of text corpus. Experimental results show that NRLDA model has a much stronger ability to differentiate similar topics, which proves that the idea in our model is reasonable.
probabilistic topic model, LDA, gibbs sampling, noise reduction
2016年8月4日,
2016年9月20日
国家自然科学基金项目(编号:61540050;61462011);贵州省重大应用基础研究项目(编号:黔科合JZ字[2014]2001);贵州省科技厅联合基金(编号:黔科合LH字[2014]7636号);贵州大学研究生创新基金项目(编号:研理工2016051)资助。
李晶,男,硕士研究生,研究方向:机器学习与文本挖掘,数据库技术与应用系统。秦永彬,男,博士,副教授,硕士生导师,研究方向:智能计算与智慧计算,大数据分析与应用。黄瑞章,女,博士,副教授,硕士生导师,研究方向:机器学习,数据挖掘,自然语言理解。
TP181
10.3969/j.issn.1672-9722.2017.02.032
猜你喜欢
小学生学习指导(低年级)(2023年10期)2023-10-28 06:34:42
中学生数理化·八年级物理人教版(2023年3期)2023-03-21 00:40:06
小学科学(学生版)(2020年10期)2020-10-28 07:52:12
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
疯狂英语·新悦读(2019年10期)2019-12-13 09:02:32
中学生数理化·八年级物理人教版(2017年6期)2017-11-09 06:00:28
小火炬·阅读作文(2017年8期)2017-09-26 06:30:48
Coco薇(2017年9期)2017-09-07 22:09:28
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
语言与翻译(2015年4期)2015-07-18 11:07:45
