
基于分类的微博情感分析算法研究及实现
2017-03-02 08:31:20杨艳霞
计算机与数字工程 2017年2期
杨艳霞
(武汉科技大学城市学院信息工程学部 武汉 430083)
基于分类的微博情感分析算法研究及实现
杨艳霞
(武汉科技大学城市学院信息工程学部 武汉 430083)
在当今信息化时代的背景下,微博作为一种社交平台获得了飞速的发展。随着微博信息的大量更新,为了避免用户迷失在信息的海洋里,对微博情感分析研究变得迫切和重要。目前相关研究还处于起步阶段,因此论文从微博信息出发,研究基于贝叶斯分类和SVM分类算法的微博情感挖掘的实现,通过分析实验结果,两种算法在处理速度和处理精度方面对两种算法各有优劣,对微博信息情感分析是有效的,有一定的参考价值。
贝叶斯分类; SVM; 机器学习; 情感分析
Class Number TP391.1
1 引言
作为信息和社交相结合的平台,微博平台以其独特的魅力吸引了大量用户对微博信息进行情感分析及情感转移研究。及时掌握公众对热点事件的态度和看法,便于政府部门掌握事件发生后的社会群体心理,为管理者提供决策依据,还可以实现微博营销、品牌宣传、客户关系管理、舆情监控等。情感分析主要是从文本中挖掘用户表达的观点以及情感极性判断,即判断一条微博信息表达情感的正、负、中性[1]。目前相关研究还处于起步阶段,因此本文从微博客用户信息出发,研究基于分类方法的微博作者情感挖掘的算法和系统的实现。
2 相关工作
2.1 信息采集
使用微博开放平台API挖掘数据是当今较为流行的数据获取方法,以新浪微博为例,新浪微博直接提供了SDK。在调用API之前,需要创建一个应用来获取app_key和app_secret完成用户的认证工作。然后,启动这个程序就会得到一个URL链接,通过该链接,获得其访问权限。
第二种方法:网络爬虫又称为网络蜘蛛,以极快的速度无间断地执行某项任务,以此收集信息。本文采用广度优先遍历方式获取用户信息。
爬取的微博信息包括的字段有消息ID、用户ID、用户名、屏幕名、用户头像、转发消息ID、消息内容、消息URL、来源、图片URL、音频URL、转发数、评论数等,信息完整可靠,便于开发者研究。
2.2 预处理
采用Lucene中文分词技术实现中文分词和关键词提取。停用词也称为功能词,在一般的文本中停用词通常是一些介词、代词、虚词等一些与情感无关的字符,如:的、我们、要、自己、之等。此外,大多数微博平台都支持文本、图片、表情、音频、视频等。因此,还需要处理一些在情感分析研究中没有实际意义的无关符号[2]。
2.3 特征选择
经过文本分词后,选择哪些关键字作为文本的特征项主要考虑词频、区域位置和分词距离位置因素。
词频:词频是最常用的一种参数,它主要描述的是一个词在文本中出现的次数,一个词的重要程度与这个词在文本中出现的次数成正比,方法简单,易于使用,把它作为测量尺度之一。
区域位置:由于在文本分类的过程中,发现一个词出现在不同的位置对于文本所想表达的意思也存在一定的影响,例如同一个词出现在标题和文章段落所起的作用不同,出现在标题的词更能体现文本的主要内容,所以区域位置作为另一个考虑因素。
分词距离次序:一个词在文本中出现次序的不同,其表达的思想可能就不会相同,因此选取将这一因素考虑在内,用于文本关键词提取。
候选词权重计算,选取的候选词计算权重计算如式(1)所示:
weighti=α×tfi+β×loci+γ×disi
(1)
式(1)中weighti是候选词wordi的权重;tfi是其词频因子;disi是其区域位置因子;disi是其距离次序因子;α,β,γ是三个因子的调节因子。
对于词频因子采用式(1)(其中,fi为文本中该候选词的词频)来计算。记录各个词在文本中出现的位置,并对词在文本中出现的不同位置进行标注。如果一个词在文本中多次出现,那么对其就选取最靠前的位置点。这样在文本处理的过程中可以实现词语权重的计算,计公式如下:
loci=(wi-1)/(wi+1)
(2)
式(2)中wi是候选词在分词中被标记的位置值。通过实验,通过一个线性函数来标记分词距离次序值(其中i表示词语在文本中出现的次序;α,β均为可调节的常数因子)。
通过式(3)来计算距离次序权重:
disi=vali/lnvali
(3)
式(3)中vali该分词第一次出现位置到文本开头的距离。通过在子公式中引入对数函数,可以更好地刻画权重计算中特征项的非线性特点。
通过特征项的权重计算公式后,为了使文本分类达到良好的效果,需要考虑如何设定调整因子的值使得对于特征词的提取效果达到最好。这里采取机器学习的方法,通过训练样本来确定调整因子的值。采用最小均方误差(LMS)训练法则训练公式的调整因子。
第一步给定调整因子的值,然后通过计算记录各个词语在文本中的权重,并将结果按其权重值由高到低排序。假设第i个文本在第k次计算各文本词语权重并排序后的词语集合为V(k,i),而该文本的训练词语排序记为Vj。根据V(k,i)和Vj中词语权重排序的差异性,设排序差值:
(4)
式(4)中,sort(k,i,j)为i个文本中的第j个分词在训练排序集和第k次计算后的测试排序集中的排序次序。
接着,通过式(5)来调整各个调整因子(α,β,γ)的值:
w=w+η×diff×sec
(5)
式(5)中w为调整因子;diff是很小的常数因子;sec为当前的测试因子的取值。
2.4 文本分类算法
贝叶斯算法:贝叶斯分类算法是源于数学上的统计学,它是运用数学上概率统计知识进行分类的一种算法。在很多方面,都能应用到贝叶斯(Naïve Bayes,NB)分类算法,此算法可以应用在大型数据库中,并且方法简单、分类准确率高、速度快。贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪类概率最大,就认为此待分类项属于哪个类别。
贝叶斯分类分为三个阶段[3]:
第一阶段——准备工作阶段。这个阶段的任务是贝叶斯分类的必要准备。这一阶段主要是输入所有待分类数据,确定特征属性并根据特征属性进行一系列的处理输出训练样本。准备工作执行质量对整个过程都有着很重要的影响。
第二阶段——分类器训练阶段。这个阶段的任务就是生成分类器,计算每个类别在训练样本中的出现频率和每种特征属性划分对每个类别的条件概率估计,并记录其结果,根据分类结果确定所属类别。其输入是特征属性和训练样本,输出是分类器。
第三阶段——应用阶段。这个阶段的任务是利用分类器对待分类项进行分类。此阶段主要是对前两个步骤的一个整合,通过前两步的处理,归属出样本所属类别,实现分类工作。其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
另一种分类算法是支持向量机(SVM)算法,SVM是建立在统计学习理论的VC维理论和结构风险最小原理基础上的[4]。其基本思想是:通过将一个非线性的支持向量机映射将输入到一个更高维空间中使之变成线性的支持向量机,然后在这个新的空间选取最优的线性分类面,这种变换通常是利用定义适当的内积函数(即核函数)来实现的,在训练集中以支持向量(Support Vector)为基础。SVM算法具有扎实的理论基础,而且在文本分类的应用上也取得了很好的分类效果[5,8]。
2.5 构建情感词汇本体
中文微博作为互联网的产品,其文本信息形式多元化,用于表达倾向性的词语在不断变化,因此核心本体并不需要一次性构建完成。所以,在这个阶段的任务是收集能够表达人们意见的核心概念和关系,建立基础的情感词典。本文构建情感词汇本体是为了更完备地表达情感词汇所包含的语义信息,例如词汇的情感倾向性和词汇间的相似、转折和递进关系等,方便情感词的组织和共享,从而为公众情感分析研究提供有力的分析依据[6]。
本文主要抽取中国知网HowNet公布的情感分析用词集中的核心词汇作为构建词典的信息来源。该词汇集所包含的词汇种类(中文)和数量以及本体中选用的情感词汇的数量如表1所示[7]。
微博消息中使用大量的网络用语,这些网络上的非正式语言和传统词语有着很大区别,它们往往具有强烈的感情色彩[10]。有的是过去已经存在的词语,因为某个事件或某些热门话题而演变成了带有感情色彩的词语[9],比如:“拜金女、凤姐”。有的是过去没有的,新出现的网络新词,大多为错别字、谐音、字母缩写、也有象形字词,比如:“喜大普奔、JJWW、弓虽”。这些词语在基础情感词汇本体中是不存在的,但在情感倾向判别过程中有着重要作用,因此针对微博构建网络情感词本体是非常重要的[10]。网络情感词需要长时间的关注和搜集,现今还没有现成可用的情感词典,因此通过社交网络、博客、BBS、评论、微博,将收集并标注具有感情色彩的词语加入微博情感词汇本体之中是必要的补充。
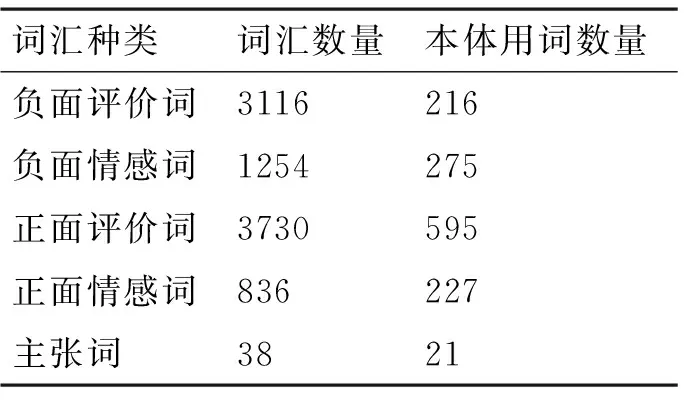
表1 HowNet情感分析用词数量及本体用词数量

表2 部分否定词、程度副词和连词集
3 系统实现
3.1 文本预处理
文本预处理过程是整个系统关键的一步,由于机器无法自动判断整个文本的类别属性,只有人工将中文文本数据处理为机器可以识别判断的数据,才能更好地处理数据。其实现过程如图1所示。
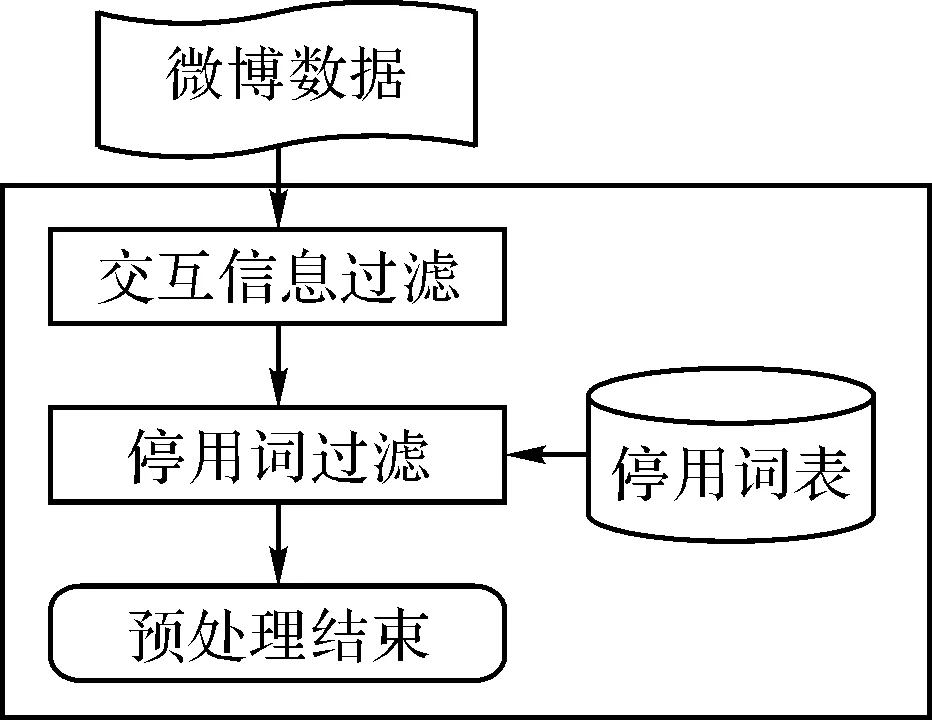
图1 微博文本预处理流程图
3.2 情感分析算法实现
分析系统总体框架包含贝叶斯分类子系统和SVM分类子系统。
实现贝叶斯算法分为以下几个步骤:
第一步:中文分词,借助于Lucene来实现中文分词;
第二步:关键词提取,主要借助于IKAnalyzer来获取关键字;
第三步:文本分类,判读文章关键词属于某一类的概率,然后通过比较不同类别的概率,出现在最大概率的文本就直接归类为该类。
贝叶斯分类子系统实现流程如图2所示。
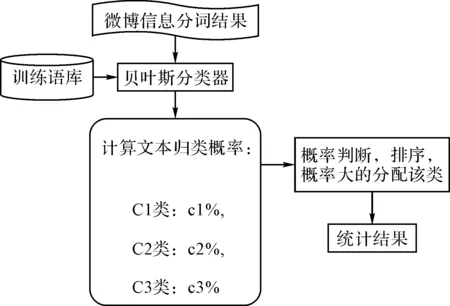
图2 贝叶斯分类器流程图
由于运算的数据量比较大,导致系统的运行时间很长,因此本文引入多线程和缓冲区技术,即先将微博信息保存在缓冲区里面,然后开启多个线程,分别计算某一条信息在给定的分类中的条件概率,计算出最可能的类别。各个线程互不影响。实验证明引入多线程和缓冲区技术使得程序的运行效率得到了明显的提高。
实现SVM分类算法主要借助LIBSVM的SVM模式识别和回归模型,先将文本转化为LIBSVM所需要的数字化矩阵,借助于SVM模型来判断文本分类的结果和准确性。SVM分类子系统实现流程如图3所示。
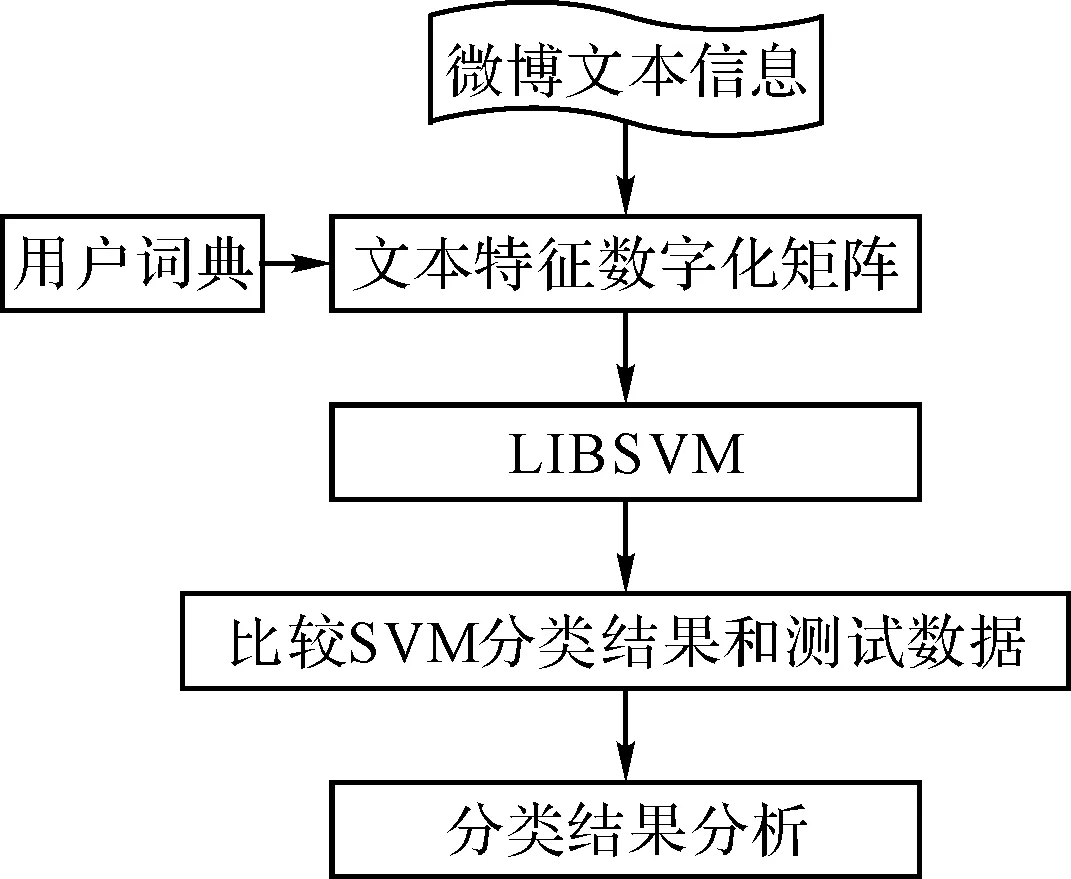
图3 SVM分类实现过程
通过构建的情感词典,将文本处理为LIBSVM所要实现的形式,本体的正、负极词汇如图4所示。

图4 构建用户情感词典图
最终通过训练语库的数字化矩阵生成分类界面,将待测试文本处理为同样的数字化矩阵,通过前面生成的分类界面,让机器自动判断,微博所属类别。文本信息处理的模型如图5所示。

图5 训练文本处理结果
4 实验结果
4.1 实验数据
数据包含两个部分:测试数据语料库和训练语料库。其中训练语料库包含998条情感分类数据,用于进行训练,作为待测数据的概率计算;待测试数据包含6626条微博数据,通过朴素贝叶斯分类器和LIBSVM分类器进行处理,最后完成分类统计工作。
4.2 贝叶斯模型测试结果
该测试结果包括文本总数以及正向情感,负向情感和中性情感。生成的文本分类柱状图如图6所示。

图6 贝叶斯文本分类结果
4.3 SVM模型测试结果
SVM算法实现文本分类结果包括输出迭代次数,二次规划求解最小值(SVM问题的最佳目标值),求解的常数项目标值b以及训练数据个数,支持的向量个数和最终的模型精确的比对结果。通过公式来计算实现文本分类,其分类结果如图7所示。
实验过程分析:贝叶斯算法实现过程,对于处理大量的文本信息需要耗费大量的时间,处理速度不够;而SVM算法的实现处理速度相对较快,究其原因在于该算法最关键的是找到合理的函数将文本处理成为需要的文本特征数字矩阵,函数的优劣决定结果的准确性,因为其处理数据是数字不需要大量的分词比较,所以在处理大量的文本情况下,SVM的效果更好。
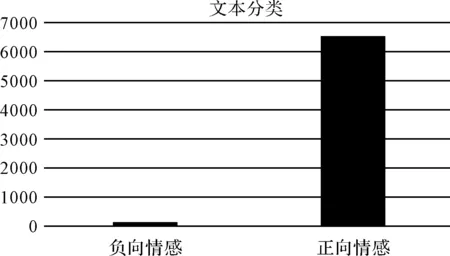
图7 基于SVM情感分类结果
实验结果分析:论文选取同样的测试文本,但实验结果存在较大的差异。采用贝叶斯算法对于文本分类结果包括三种类型,即正向情感和负向情感和中性情感,文本中正向情感和中性情感所占比例较大;而采用SVM算法实现文本分类时,对于中性情感,算法自动将其直接归类为正向情感,但同样都是负向情感所占比例较小。显然在分类准确性上贝叶斯算法占有优势。
5 结语
本文以新浪微博信息为研究对象,利用新浪微博提供的API和网络爬虫两种方法搜集数据;对数据进行预处理后,利用贝叶斯算法与SVM分类算法对数据进行情感分析,最终经过比较实验过程和实验结果,发现两种算法在分类速度和精度上各有优劣,两种算法对微博信息情感分析是有效的。同时为了提高程序的运行效率,本文还在程序中引入了缓冲池和多线程技术,使情感分析运行效率得到显著提高。
[1] 谢丽星,周明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-83. XIE Lixing, ZHOU Ming, SUN Maosong. Hierarchical Structure Based Hybrid Approach to Sentiment Analysis of Chinese MicroBlog and Its Feature Extraction[J]. Journal of Chinese Information Processing,2012,26(1):73-83.
[2] 周昆.基于改进向量空间模型的中文文本分类研究[D].北京:北京理工大学,2015. ZHOU Kun. Research of Chinese Text Classification based on Improved Vector Space Model[D]. Beijing: Beijing Institute of Technology,2015.
[3] 张鑫,马勇,曹鹏.基于贝叶斯分类算法的木马程序流量识别方法[C]//第27次全国计算机安全学术交流会,2012(8):115-117. ZHANG Xin, MA Yong, CAO Peng. Traffic Identifying Method for Trojan Detection upon Bayesian Classification Algorithm[C]//Netinfo Security,2012(8):115-117.
[4] 杨斌,路游.基于统计学习理论的支持向量机的分类方法[J].计算机技术与发展,2006(11):56-58. YANG Bin, LU You. Classification Method of Support Vector Machine Based on Statistical Learning Theory[J]. Computer Technology and Development,2006(11):56-58.
[5] 马金娜,田大钢.基于SVM的中文文本自动分类研究[J].计算机与现代化,2006(8):5-8. MA Jinna, TIAN Dagang. Research on Chinese-text Au-tomatic Classification Based on SVM[J]. Computer and Modernization,2006(8):5-8.
[6] K. T. Durant, M. D. Smith. Mining Sentiment Classification from Political Web Logs[C]//Proceedings of Workshop on Web Mining and Web Usage Analysis of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(WebKDD-2012), August,2012.
[7] Subject sentiment analysis research Based on ontology[EB/OL].http://www.docin.com/p-976811905.html.
[8] D. Gruhl, R. Guha, D. Liben-Nowell, et al. In-formation Diffusion Through Blogspace[C]//Proceedings of the 13th International Conference on World WideWeb,2013:491-501.
[9] 王晓东,王娟,张征.基于情感词汇本体的主观性句子倾向性计算[J].计算机应用,2012,32(6):1678-1681. WANG Xiaodong, WANG Juan, ZHANG Zheng. Computation on orientation for subjective sentence based on sentiment words ontology[J]. Journal of Computer Applications,2012,32(6):1678-1681.
[10] J. Bar-llan. An Outsider’s View on ‘Topic-oriented’ Blogging [C]//Proceedings of the Alt. Papers Track of the 13th International Conference on World Wide Web, 28-34, May,2013.
Microblog Sentiment Analysis Algorithm Research and Implementation Based on Classification
YANG Yanxia
(Department of Information Engineering, Wuhan University of Science and Technology City College, Wuhan 430083)
Under the background of today’s information age, microblog obtains a rapid development. With the news on the microblog updating, in order to avoid the users getting lost in the ocean of information, emotion analysis of the information becomes urgent and important. Based on the implementation of microblog emotion mining of Bayesian classifier and SVM classification algorithm, making comparison through the analysis of the experimental results in processing speed and accuracy, has a reference value.
Naive Bayes classifier, SVM, machine learning, sentiment analysis
2016年8月3日,
2016年9月18日
国家自然科学基金(编号:61502356);湖北省教育厅科学技术研究计划指导性项目:“基于Ontology的微博话题识别及倾向性研究”(编号:B2015360);湖北省教育厅人文社会科学研究计划指导性项目:“基于微博情感分析的大学生心理健康校园预警系统的建设与管理”资助。
杨艳霞,女,硕士研究生,副教授,研究方向:机器学习与智能计算。
TP391.1
10.3969/j.issn.1672-9722.2017.02.001
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
智富时代(2019年6期)2019-07-24 10:33:16
数理化解题研究(2017年4期)2017-05-04 04:07:54
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
高中生·天天向上(2016年9期)2016-11-22 09:10:34
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
传奇故事(破茧成蝶)(2015年7期)2015-02-28 09:29:18
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
