
基于语义依存的汉语句子相似度改进算法
2017-03-01 10:26陈德锐
浙江工业大学学报 2017年1期
黄 洪,陈德锐
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
基于语义依存的汉语句子相似度改进算法
黄 洪,陈德锐
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
现有的基于语义依存的汉语句子相似度算法仅考虑了基于核心词的有效搭配对,根据两个句子有效搭配对的对应词是否是相同词和同义词将匹配权重简单地处理为0,0.5和1,而且未考虑不直接依存于核心词的其他词语,导致在计算句子相似度时区分度较低.改进算法通过综合计算核心词、关键词的语义相似度来确定更为精确的匹配权重,并且将不直接依存于核心词的其他词语对句子的影响也纳入句子相似度计算,以期达到全面刻画句子语义、提高算法的准确率和区分度的目的.实验结果表明改进算法比原算法具有更高的准确率以及更好的对句子的区分能力.
相似度;语义依存;词语语义;知网
相似度计算一直是人工智能领域的研究热点[1].句子相似度计算有着非常广泛的应用,例如在基于实例的机器翻译系统中,通过相似度计算匹配需要的译文;在自动问答系统[2]中,通过相似度计算进行问句检索;在信息检索系统中,通过相似度计算匹配用户所查找的内容.一般将句子相似度计算分为3个等级[3]:语法相似度、语义相似度和语用相似度,不过现阶段还难以有效地计算句子的语用相似度,通常只需要计算句子的语义相似度就能够满足现有大多数应用的实际需求.根据对句子的分析层次,句子相似度算法分为基于词语的方法和基于句法语义分析的方法.基于词语的方法简单易行,但是没有对句子进行句法结构分析,只利用句子的表层信息如句中词语的词频、词性等,而未考虑句子结构因素,主要有基于相同词的方法[4]、基于向量空间的方法[5]、基于语义词典的方法[6]、基于编辑距离的方法[7]等.基于句法语义分析的方法对句子进行全面的句法语义分析,找出句中词语的依存关系,并以此为基础计算相似度,主要有基于语义依存的方法[8].
李彬等[8]对句子进行句法分析,通过构建依存树,比较有效搭配对来计算相似度.该方法在比较两个句子的搭配对时只是简单地判断两个词语是否相同,或者是否是同义词,而且未考虑不直接依存于核心词的其他词语.针对这些问题提出一种改进算法,通过计算词语相似度来匹配不同词语,使其更好地体现句子的语义信息,并将不直接依存于核心词的词语纳入相似度计算中,从而更加全面地比较两个句子.
1 句子相似度计算
1.1 基于语义依存的句子相似度计算
基于语义依存的相似度算法首先要对句子进行全面的句法语义分析,选用哈工大社会计算与信息检索研究中心研制的语言技术平台(LTP)[9]对句子进行依存句法分析,该平台可以同时对一个句子进行分词、词性标注、依存句法分析等操作,将其转化为一棵结构化的依存句法分析树.例如“请大家再检查一遍是否已经填上自己的名字.”,经过依存句法分析后,句中各成分之间的关系如图1所示.

图1 依存句法分析Fig.1 The dependency parsing
李彬等[8]在基于语义依存进行句子相似度计算时,只考虑句子的有效搭配对,其中有效搭配对是由句子的核心词以及直接依存于核心词的名词、动词或形容词组成的词语对.以图1为例,该句的核心词是“请”,而直接依存于核心词的词语是“大家”和“检查”,其中“大家”是代词,“检查”是动词,所以该句的有效搭配对是“请_检查”.相似度计算公式为
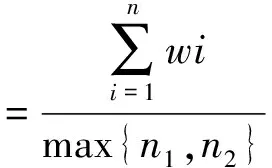
(1)
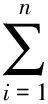
目前,一些学者提出了基于语义依存的相似度算法的改进算法,如刘宝艳等[10]提出了基于改进编辑距离和依存文法的相似度算法,先进行句法依存分析,再利用编辑距离计算相似度.王品等[11]在词形相似度的基础上融入语义依存相似度,分别用这两种方法计算相似度,再进行加权求和.王宏生等[12]把语义网和词形、语义依存相似度算法相结合,在语义网的基础上进行相似度计算.侯丽敏等[13]提出了融合语义词典和句法依存关系的相似度算法,也采用加权求和的方式计算相似度.考虑到刘宝艳、侯丽敏的算法没有明确给出权重的取值,王宏生的算法需要人工构建语义网,实用性较差,实验选用王品的算法作为对比.
1.2 基于知网的词语相似度计算
词语相似度[14]指出现在文章不同位置的两个词语可以互相替换而不改变文章句法语义结构的程度,词语相似度计算通常需要使用诸如知网等特定的语义资源.知网是一个描述概念与概念之间以及概念所具有的属性之间的关系的知识系统.知网使用概念来描述词语,一个词语可以描述为多个概念,每个概念都用义原来描述,义原是知网中最小的意义单位.
义原之间一共有8种关系:上下位关系、同义关系、对义关系、反义关系、部件整体关系、材料成品关系、属性宿主关系以及事件角色关系.其中上下位关系最为重要,义原按照上下位关系组成一个树状的层次体系,也是目前大多数基于知网的词语相似度计算方法[15-17]的基础.实验选用刘群的方法进行词语相似度计算,公式为
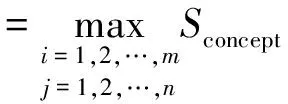
(2)
其中:W1和W2分别为两个词语;C1i和C2j分别为W1和W2中的概念,两个词语的相似度是各个概念的相似度的最大值.
1.3 对基于语义依存的相似度算法的改进
基于语义依存的相似度算法[8]体现了句中词语之间的相互关系,但在匹配有效搭配对时只是简单地判断两个词语是否相同,或者是否是同义词,然后取0,0.5或1的匹配权重,对不同搭配对的区分程度较低.当句子比较短的时候,搭配对的数量也相应较少,由于匹配权重只有3个可能取值,根据式(1)可以看出句子相似度的可能取值也比较少,即该方法对不同短句子的区分能力较差.另外,只是区分相同词、同义词和不同词也丢掉了词语的语义信息,从而影响计算结果的准确率.在匹配不同词语或搭配对时,可以深入挖掘词语的语义信息,即通过计算两个词语的相似度并将其作为它们的匹配权重.当两个词语的相似度越大,它们的匹配权重也就越大,基于此得到的句子相似度也相应越大,即两个句子所含词语的相似度越大,它们之间的相似度也就越大.考虑到词语相似度可以取0~1之间的任何值,这样既能加大不同词语或搭配对的区分度,又能充分利用词语的语义信息以提高句子相似度计算的准确性.
此外,基于语义依存的相似度算法未考虑不直接依存于核心词的词语的相似度,丢失了一部分句子信息,实际上这些词语对句子也有一定的影响,如果忽略它们,将无法区分那些搭配对相同但其他词语不同的句子.例如句子“他常常怀念从前在家乡的日子.”和“我很怀念大家一起奋斗的日子.”,它们的有效搭配对均为“怀念_日子”,如果不考虑其他词语,它们的相似度就是1,明显与实际情况不符.改进算法将会把这些词语也纳入句子相似度计算中,使得句子的信息更加完整.
将经过依存句法分析后的句中词语分为3类:核心词、关键词和其他词,其中核心词定义为依存句法分析后句子的核心词,关键词定义为直接依存于核心词的名词、动词和形容词,余下的其他词语定义为其他词.继续以图1为例,该句的核心词是“请”,关键词是“检查”,其他词是“大家”“再”“一”“遍”“是否”“已经”“填”“上”“自己”“的”“名字”.计算句子相似度时分为两部分:核心词和关键词的相似度、其他词的相似度,然后再对两部分进行加权求和.
假设句子S1,S2经过依存句法分析后得到句中词语集合{Wcore1,Wkey11,Wkey12,…,Wkey1m,Wother11,Wother12,…,Wother1p},{Wcore2,Wkey21,Wkey22,…,Wkey2n,Wother21,Wother22,…,Wother2q},核心词和关键词的相似度Spart1的计算公式为
Spart1=Sword(Wcore1,Wcore2)·Skeyword
(3)
其中Skeyword为两个句子关键词的相似度,计算公式为
(4)
其中ki为第i次计算时关键词相似矩阵的最大值.关键词相似矩阵分别以两个句子的关键词为行和列,矩阵元素为该行和该列对应的两个词语的相似度值,每次计算遍历整个矩阵,取出相似度最大值,再将其所在的行和列删除,继续下一次计算直到矩阵为空.类似的,其他词的相似度Spart2的计算公式为
(5)
其中oi为第i次计算时其他词相似矩阵的最大值.综上,整个句子的相似度计算公式为
Ssen(S1,S2)=αSpart1+βSpart2
α+β=1,0<β<α<1
(6)
改进算法在依存句法分析的基础上融入了词语语义相似度计算,能够从语义层面更加深入地比较两个句子,而且还考虑到了不直接依存于核心词的词语的相似度,对句子的理解更加充分.但是在时间复杂度方面,因为改进算法考虑了句子中的所有词语,所以它的时间复杂度O(mn+pq)要高于原算法的时间复杂度O(mn).
2 实 验
2.1 确定权重
改进算法的句子相似度由两部分组成,为了确定每部分的权重,针对性地构建了40对句子进行测试.这些句子分为4种类型:A类中每对句子的核心词和关键词基本相同,而且其他词也基本相同;B类中每对句子的核心词和关键词基本相同,但是其他词基本不同;C类中每对句子的核心词和关键词基本不同,但是其他词基本相同;D类中每对句子的核心词和关键词基本不同,而且其他词也基本不同.
由式(6)中的条件α+β=1,0<β<α<1可得α=1-β,0<β<0.5,然后联合式(3)和式(5),得出的结果代入式(6)中,就可以得到Ssen关于β的形如Ssen=aβ+b的一元二次方程.因为每一类句子都包含10对测试句,所以利用它们的平均值求解β,测试结果如图2所示.
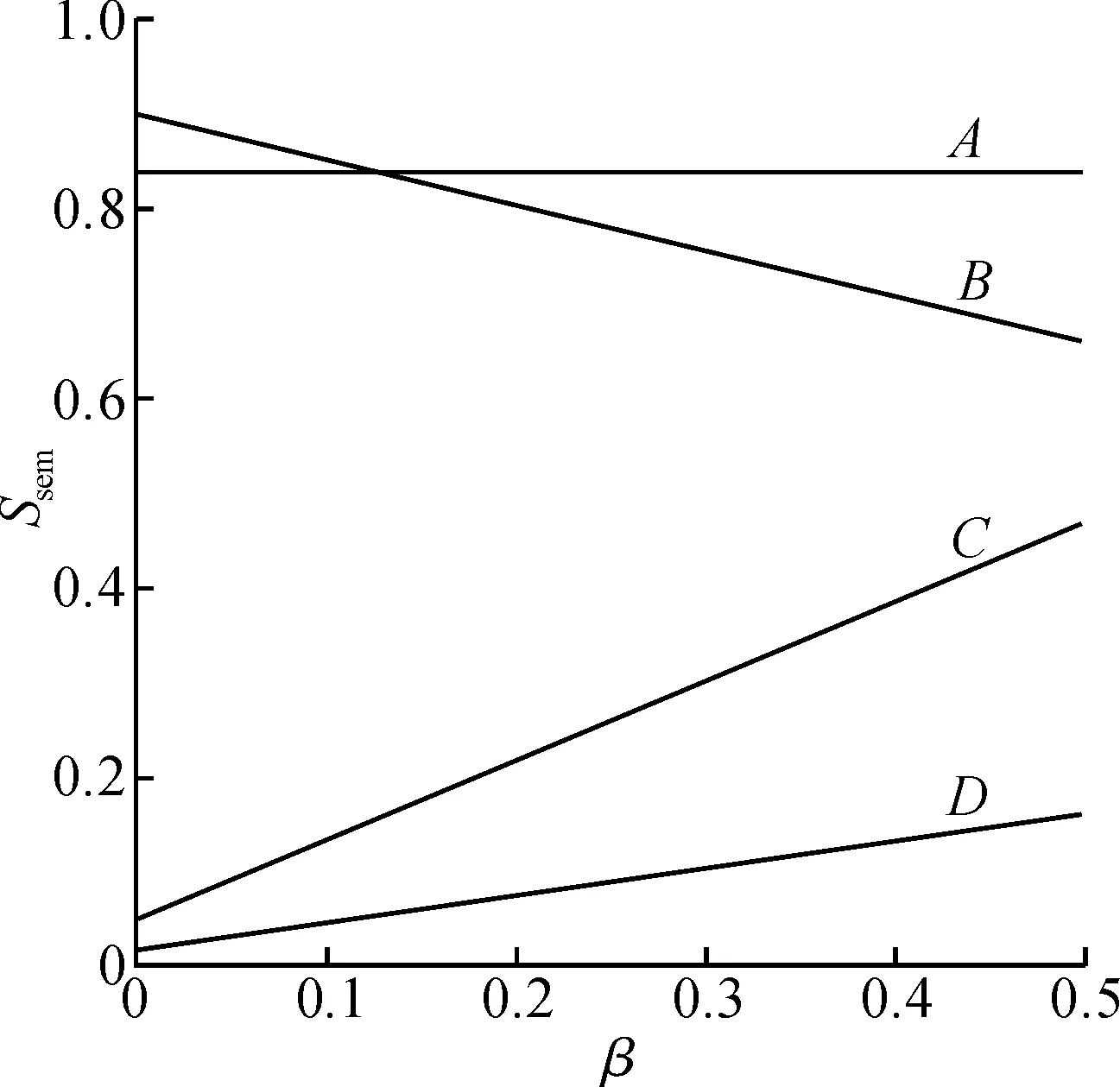
图2 β取值对句子相似度的影响Fig.2 The influence of β values on sentence similarity
根据测试句的构建规则,4类句子的相似度应满足SA>SB>SC>SD.假设直线A和直线B的交点为O,O点对应的β=0.12,那么β应满足0.12<β<0.5.再在该区间内以0.05为步长取值,并使用下一节的方法依次进行实验,实验结果表明,β=0.5时,准确率达到最高,所以最终的权重取值为α=0.5,β=0.5.
2.2 实验方法
现阶段汉语句子相似度计算还没有可用的公共测试集,一般需要人工构建测试语料.实验所用语料主要来自《汉语动词用法词典》和互联网,经过人工筛选后获得.最终构建的实验语料包含330条句子,这些句子分为标准集和测试集[18]:标准集含33条句子,测试集包括含99条句子的匹配集和含198条句子的噪声集.其中,匹配集含33×3条与标准集中对应句子相似的句子,噪声集中的所有句子均包含标准集中句子的关键词语,以起到噪声作用.
具体实验方法为:从标准集中依次抽取第i(1≤i≤33)条句子,与测试集中的所有句子计算相似度,选取相似度最大的3条句子,记这3条句子和匹配集中对应的3条句子相同的句子数量为ri,即找到的正确句子数量.因此,准确率P的计算公式为
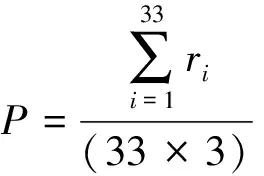
(7)
2.3 实验结果
分别用3种不同的句子相似度算法对实验语料进行了5次实验,每次实验都将匹配句和噪声句随机打乱以测试算法对不同句子的区分能力,其他设置保持不变.实验结果如表1所示,其中方法1是李彬等的算法[8],方法2是王品等的算法[11],方法3是笔者的算法.从表1中可以看出:方法2和方法3都优于方法1,主要是因为它们在语义依存的基础上考虑了其他因素,而且方法3的准确率更高,说明句中词语的语义比词频(词形)包含更多的句子信息.
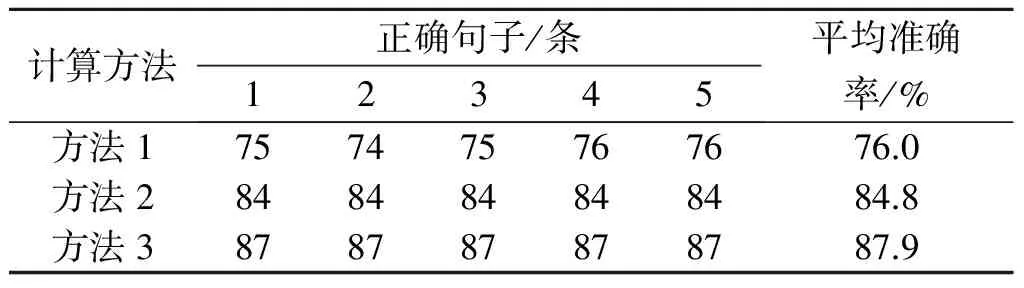
表1 实验结果
另外,方法1的实验结果略有波动,原因是该方法对不同句子的区分能力较差,可能会出现标准句、匹配句的相似度与标准句、噪声句的相似度相同的情况,因为每次实验都将匹配句和噪声句随机打乱,所以在选取相似度最大的3条句子时(相似度相同时取靠前的句子)匹配句和噪声句都有可能被选中.
3 结 论
对基于语义依存的句子相似度算法进行改进,通过对两个句子的核心词和关键词进行语义相似度计算来确定更加精确的匹配权重,而不是简单地根据是否是相同词或同义词而取0,0.5或1,并将不直接依存于核心词的其他词语也纳入相似度计算,从而更加完整地反映句子的含义.实验结果表明:改进算法在计算句子相似度时比原算法具有更高的准确率,而且正确句子的数量并未像原算法一样出现波动,即改进算法对不同句子的区分能力更强.
[1] 徐彩虹,刘志,潘翔,等.一种基于实例学习的三维模型检索匹配方法[J].浙江工业大学学报,2012,40(3):326-330.
[2] 周永梅,陶红,陈姣姣,等.自动问答系统中的句子相似度算法的研究[J].计算机技术与发展,2012,40(5):75-78.
[3] CHATTERJEE N. A statistical approach for similarity measurement between sentences for EBMT[C]//Proceedings of Symposium on Translation Support Systems STRANS. Kanpur: Indian Institute of Technology,2001:122-131.
[4] 秦元巧,孙国强.改进的句子相似度计算在问答系统中的应用[J].微计算机信息,2011,27(8):206-208.
[5] 郑诚,李清,刘福君.改进的VSM算法及其在FAQ中的应用[J].计算机工程,2012,38(17):201-204.
[6] 程传鹏,吴志刚.一种基于知网的句子相似度计算方法[J].计算机工程与科学,2012,34(2):172-175.
[7] 叶焕倬,吴迪.基于改进编辑距离的相似重复记录清理算法[J].现代图书情报技术,2011,7(8):82-90.
[8] 李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2003,20(12):15-17.
[9] CHE Wanxiang, LI Zhenghua, LIU Ting. LTP: a Chinese language technology platform[C]//23rd International Conference on Computational Linguistics. Beijing: Tsinghua University Press,2010:13-16.
[10] 刘宝艳,林鸿飞,赵晶.基于改进编辑距离和依存文法的汉语句子相似度计算[J].计算机应用与软件,2008,25(7):33-34.
[11] 王品,黄广君.信息检索中的句子相似度计算[J].计算机工程,2011,37(12):38-40.
[12] 王宏生,张敏.一种基于语义网的相似度计算模型[J].微计算机信息,2011,27(7):227-228.
[13] 侯丽敏,张永强.面向课程的中文FAQ自动问答系统模型[J].计算机与现代化,2014(10):20-24.
[14] 刘端阳,王良芳.基于语义词典和词汇链的关键词提取算法[J].浙江工业大学学报,2013,41(5):545-551.
[15] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[16] 黄洪,丰旭.涉及地名的句子相似度计算方法的改进[J].浙江工业大学学报,2015,43(6):624-629.
[17] 刘杰,郭宇,汤世平,等.基于《知网》2008的词语相似度计算[J].小型微型计算机系统,2015,36(8):1728-1733.
[18] 李茹,王智强,李双红,等.基于框架语义分析的汉语句子相似度计算[J].计算机研究与发展,2013,50(8):1728-1736.
An improved Chinese sentence similarity algorithm based on semantic dependency
HUANG Hong, CHEN Derui
(College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China)
The existing Chinese sentence similarity algorithms based on semantic dependency only consider the effective word pairs based on the core word. Depending on whether or not the words in the effective word pairs of two sentences are same words or synonyms, it simply sets the matching weight to 0, 0.5 or 1. Those words which are not depended on the core word directly are not considered. This results in a bad discrimination in sentence similarity computing. In order to get a comprehensive characterization of sentence semantics and improve the accuracy and discrimination of the algorithm, the improved algorithm sets a more precise matching weight by computing the similarity of the core words and the key words, those words which are not depended on the core word directly are taken into the sentence similarity computation as well. The experimental results show that the improved algorithm has better accuracy and better discrimination than the original algorithms.
similarity; semantic dependency; word semantics; HowNet
(责任编辑:刘 岩)
2016-03-23
国家自然科学基金资助项目(61202202);浙江省人社厅钱江人才项目(QJ01302010)
黄 洪(1964—),男,江西丰城人,教授,研究方向为软件开发方法、智能电子商务和自然语言处理,E-mail:huanghong@zjut.edu.cn.
TP391
A
1006-4303(2017)01-0006-04
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年14期)2022-08-26
军事文摘(2022年14期)2022-08-26
军事文摘(2022年12期)2022-07-13
小天使·一年级语数英综合(2020年4期)2020-12-16
开放教育研究(2020年2期)2020-03-31
教书育人·教师新概念(2017年6期)2017-06-15
长江学术(2016年4期)2016-03-11
传奇故事(破茧成蝶)(2015年7期)2015-02-28
