
关键短语抽取研究现状
2017-02-23 06:48:48李珊珊周耘立
现代计算机 2017年2期
李珊珊,周耘立
(四川大学计算机学院,成都 620065)
关键短语抽取研究现状
李珊珊,周耘立
(四川大学计算机学院,成都 620065)
在这个信息爆炸的社会,如何从大量的文本快速浏览读取重要信息,已经变得越来重要。关键短语抽取就是从文本中自动抽取文本中重要的并且能够代表文章主题的短语。关键短语可以帮助读者快速并且准确地了解文本信息内容。关键短语抽取方法可以分为无监督方法和有监督方法两种,下面分别对关键短语抽取的两种方法进行介绍。
关键短语抽取;候选关键短语;有监督方法;无监督方法
0 引言
关键短语是文本中代表主题的词和短语,关键短语抽取在信息检索任务和自然语言处理任务中都有着重要的作用,关键短语同样也是文本总结、观点挖掘、文本分类和检索索引等的基本任务[1]。尽管关键短语抽取已经做了许多研究工作,但是相比其他的自然语言处理研究工作,关键短语抽取仍然存在很大的挑战[2]。随着网络信息的发展,网络文本信息越来越多,如何从这些错综复杂的网络文本信息中快速浏览关键信息显得无比重要。因此关键短语抽取具有重大的现实意义。本文将对现有的关键短语抽取方法进行分析总结。
1 关键短语
关键短语是对文本内容的简单总结,关键短语对文本主题具有概括性的功能。关键短语有以下几个特点[3]:
覆盖性:关键短语应该是那些重要性程度高并且频繁出现的短语。如果不是一个频繁出现的候选短语,即使它的其他特征得分高,也不能作为关键短语抽取出来。
纯度:关键短语是只在一个主题下频繁出现的候选短语,而不是在整个文档中都频繁的候选短语。
短语性:当一个词与其他词构成候选短语共同出现的次数超过预期的标准值时,也就是它们同现频率大于一定的阈值时,候选短语才有可能成为关键短语。
完整性:抽取出来的关键短语应该是词语集合的全集而不是词语集合的某个子集。
关键短语抽取方法分为两步:第一步是利用一些启发式规则先抽取词,然后利用以上几个特征将词组合成短语作为候选短语;第二步是利用无监督方法或者有监督方法计算候选短语成为关键短语的得分,无监督的方法是最终选取得分前N的候选短语作为关键短语,有监督的方法是当得分超过某个阈值时,候选短语作为关键短语被抽取出来。
2 关键短语抽取有监督方法
关键短语抽取有监督方法是把关键短语抽取任务作为一个二分类任务。有监督方法是利用已标注的数据集训练一个分类器,对将来来的数据利用已经训练好的分类器进行关键短语的抽取。训练数据集中如果候选短语是标注的关键短语则作为正例,如果候选短语不是标注的关键短语则作为负例,这样产生的正例和负例一起进行训练,得到最终的分类器。不同的学习算法都可以用来训练分类器,包括朴素贝叶斯、决策树、bagging、boosting、多层感知器和支持向量机等分类算法[4]。
关键短语有监督抽取方法需要利用特征训练分类器,有监督方法利用的特征主要有两大特征:文本本身特征和文本之外的特征。
文本本身特征是只利用训练数据集的知识计算,包括:
统计特征:此特征从训练集里获得的统计信息,包括TF-IDF[5]、短语第一出现的相对位置、短语在训练数据集出现的次数等。
结构特征:表示短语出现在文章中的章节和段落特征。
句法特征:表示候选短语的句法模式,例如词性标注序列等。
文本之外的特征是利用除了训练数据集自己的知识之外其他的信息,例如词汇知识库(Wikipedia[6])信息、网络Web信息、相似文本的信息[7]、引文网络信息[8]等。
3 关键短语抽取无监督方法
由于关键短语抽取有监督方法需要大量的标注数据,但是获取带标注的语料很困难,所以研究者们提出了关键短语抽取无监督的方法。关键短语抽取无监督方法可以分为三类:基于图的排序方法、KeyCluster方法和基于主题的图的排序算法。
3.1 基于图的排序方法
传统上,一个候选短语的重要性经常被定义与文本中的其他候选短语的相关程度[9],如果某个候选短语与其他的候选短语相关高,并且其相关的候选短语重要性得分很高,那么这个候选短语的重要性得分也相对较高。研究人员计算候选短语之间的关联性使用同现频率和语义相似度,并从文档中收集的关联性信息表示成一个图[10]。
基于图的排序方法是为每个文本建立一个图,图的每个顶点是候选短语,图的边作为两个候选短语的连接,其中边的权值是两个候选短语共同出现的次数。然后通过递归算法获得每个候选短语的得分,最后抽取前N个候选短语作为关键短语。
3.2 KeyCluster方法
由于基于图的排序方法没有考虑主题对关键短语的影响,导致抽取的关键短语对主题的概括性差,所以研究者们提出了KeyCluster方法[11]。该方法是利用维基百科和基于共同出现的统计信息对候选短语进行聚类,然后抽取聚类簇中心的几个候选短语作为该主题下的关键短语。该方法可以选取所有主题下的关键短语,使得抽取出的关键短语能够概括所有主题。
3.2 基于主题的图的排序算法
KeyCluster方法虽然可以使抽取的关键短语具有主题更广发的概括性,但是却假设一篇文本的所有主题都是同等概率的,这显然是不合理的。所以研究者们提出了基于主题的图的排序算法,该方法在基于图的排序算法基础上加上主题对每个候选短语的影响[12],并且一篇文本的每个主题有不同的概率。基于主题的图的排序算法在保证抽取的关键短语能够覆盖文本的所有主题的同时,又为每个主题赋予不同的概率,实验效果优于KeyCluster方法。
4 性能评价
在关键短语抽取领域,一般采用召回率(Recall)、准确率(Precision)和F值来衡量关键短语抽取效果[13]。召回率又称查全率是指机器抽取正确关键短语个数占人工抽取关键短语总数的比率。准确率是机器抽取正确关键短语个数占机器抽取关键短语总数的比率。
令A表示机器抽取为关键短语且人工也抽取为关键短语的词语集合;B表示机器抽取为关键短语而人工抽取为非关键短语的词语集合;C表示机器抽取为非关键短语而人工抽取为关键短语的词语集合;D表示机器抽取为非关键短语且人工也抽取为非关键短语的词语集合。
召回率Recall由公式(1)计算得到。

精确率Precision由公式(2)计算得到。

综合考虑召回率Recall和精确率Precision的情况下,提出了F值,由(3)计算得到。
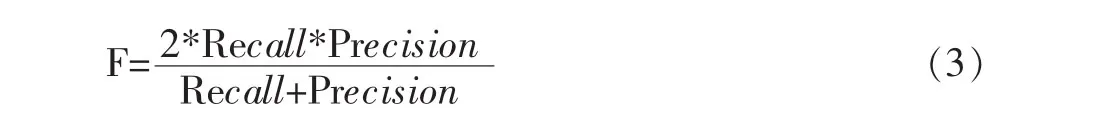
5 结语
本文对现有的关键短语抽取方法进行了分析总结,介绍了关键短语抽取无监督方法和关键短语抽取有监督方法的几个典型算法,并阐述了它们不足之处。尽管关键短语抽取方法已经做了大量的研究[14],但是相比较其他的自然语言处理任务仍有很大的不足和提升的空间。
[1]Florian Boudin.Reducing Over-Generation Errors for Automatic Keyphrase Extraction Using Integer Linear Programming,2015.
[2]Su Nam Kim,Olena Medelyan,Min-Yen Kan,Timothy Baldwin.Semeval-2010 task 5:Automatic Keyphrase Extraction from Scientific Articles,2010.
[3]M.Danilevsky,C.Wang,N.Desai,J.Guo,J.Han.Automatic Construction and Ranking of Topical Keyphrases on Collections of Short Documents,2014.
[4]K.S.Hasan,V.Ng.Automatic Keyphrase Extraction:A Survey of the State of the Art.2014.
[5]Gerard Salton,Christopher Buckley.Termweighting Approaches in Automatic Text Retrieval,1988.
[6]Olena Medelyan,Eibe Frank,and Ian H.Witten.Human-competitive Tagging using automatic Keyphrase Extraction,2009.
[7]Wan,X.,Xiao,J.Single Document Keyphrase Extraction Using Neighborhood Knowledge,2008.
[8]Caragea,Bulgarov,Godea,and Gollapalli.Citation-Enhanced Keyphrase Extraction from Research Papers:A Supervised Approach. 2014.
[9]Yutaka Matsuo,Mitsuru Ishizuka.Keyword Extraction from a Single Document Using Word Co-occurrence Statistical Information.2004. [10]Rada Mihalcea and Paul Tarau.TextRank:Bringing Order into Texts,2004.
[11]Zhi-yuan Liu,Chen Liang,Mao-song Sun.Topical Word Trigger Model for Keyphrase Extraction,2012.
[12]Zhi-yuan Liu,Wen-yi Huang,Yabin Zheng,Mao-song Sun.Automatic Keyphrase Extraction Via Topic Decomposition,2010.
[13]肖根胜.改进TF-IDF和谱分割的关键词自动抽取方法研究[D],2012.
[14]姚尧.自动关键短语抽取综述[J].现代计算机(专业版),2015.
Research Status of Keyphrase Extraction
LI Shan-shan,ZHOU Yun-li
(College of Computer Science,Sichuan University,Chengdu 610065)
In the society with information explosion,it is more important to scan and read significance information from the vast amounts of text. Keyphrase extraction is automatically extracted from the text on behalf of the topics of article and the important phrases.Kephrase can help the reader to understand the information of the text fast and exact.The method of keyphrase extraction is divided into supervised and unsupervised way,introduces two kinds of methods of extracting keyphrases.
Extract Keyphrases;Candidate Keyphrases;Supervised Method;Unsupervised Method
1007-1423(2017)02-0039-03
10.3969/j.issn.1007-1423.2017.02.010
李珊珊(1989-),女,江苏徐州人,硕士研究生,学生,研究方向为数据挖掘
2016-11-15
2017-01-05
周耘立(1990~),男,四川浦江人,硕士研究生,学生,研究方向为数据挖掘
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
NBA特刊(2014年7期)2014-04-29 00:44:03
中国商人(2013年1期)2013-12-04 08:52:52
