
云存储中数据完整性自适应审计方法
2017-02-21 11:45王惠峰李战怀赵晓南
计算机研究与发展 2017年1期
王惠峰 李战怀 张 晓 孙 鉴 赵晓南
(西北工业大学计算机学院 西安 710129)(wanghuifeng12@163.com)
云存储中数据完整性自适应审计方法
王惠峰 李战怀 张 晓 孙 鉴 赵晓南
(西北工业大学计算机学院 西安 710129)(wanghuifeng12@163.com)
作为云存储安全的重要问题,数据完整性验证技术受到学术界和工业界的广泛关注.为了验证云端数据完整性,研究者提出了多个数据完整性公开审计模型.然而,现有的数据完整性审计模型采用固定参数审计所有文件,浪费了大量计算资源,导致系统审计效率不高.为了提高系统的审计效率,提出了一种自适应数据持有性证明方法(self-adaptive provable data possession, SA-PDP),该方法基于文件属性和用户需求动态调整文件的审计方案,使得文件的审计需求和审计方案的执行强度高度匹配.为了增强审计方案更新的灵活性,依据不同的审计需求发起者,设计了2种审计方案动态更新算法.主动更新算法保证了审计系统的覆盖率,而被动更新算法能够及时满足文件的审计需求.实验结果表明:相较于传统方法,SA-PDP的审计总执行时间至少减少了50%,有效增加了系统审计文件的数量.此外,SA-PDP方法生成的审计方案的达标率比传统审计方法提高了30%.
数据安全;云存储;数据完整性验证;数据可持有性证明;自适应审计
云存储服务以其高性价比、良好的扩展性和按需付费等特点受到用户的普遍欢迎.同时,云存储服务面临许多安全威胁,云端文件的数据完整性容易遭受破坏.例如2011年3月谷歌Gmail邮箱出现故障,导致大约15万用户的数据丢失;2012年8月盛大云因物理服务器磁盘损坏造成用户数据丢失[1].EMC公司指出,64%的受调查企业在过去12个月中经历过数据丢失或宕机事故.数据完整性验证[1-2]作为云存储安全的重要问题,受到学术界和工业界的广泛关注.数据完整性验证能够及时发现数据损坏,为数据恢复赢得宝贵时间.但云存储中文件数量庞大,数据完整性验证面临沉重的审计负担,不合理的审计方案将严重影响系统的审计效率.因此,如何有效降低大规模文件的审计成本、提高系统的审计效率是一个亟需解决的重要问题.
近年来,研究人员针对数据完整性验证问题提出了多种解决方案[3-20].Juels等人[3]提出了一种可检索数据证明模型(proofs of retrievability, POR),要求返回指定位置的“哨兵”来检查文件损坏.但是“哨兵”数量固定,该模型只支持有限次数的审计,而重新布置“哨兵”代价高昂.Ateniese等人[4]提出一种数据持有性证明模型(provable data possession, PDP),采用随机抽样方式验证文件,使审计次数不受限制,并且PDP将认证信息与原始数据分离,保持了原始文件的独立性.PDP已经成为验证云存储数据完整性审计的主要方法.
针对PDP方法的数据动态更新、公开审计和协同存储等问题,研究人员进行了深入研究.Erway等人[6]利用等级数据跳表实现了支持数据动态更新的PDP模型,但中间节点计算复杂.王聪等人[9]利用merkle hash tree结构简化了中间节点计算过程.朱岩和王博洋等人[11-12]利用index-hash table二维表结构实现了数据的动态更新,该结构适合更新请求较少的情景.禹勇等人[13]指出了数据更新时面临的伪造攻击和重放攻击的问题,通过改进审计协议增强了系统的安全性.为了减轻用户的计算负担,基于代理的审计模型[9,14-15]将文件审计任务委托给第三方执行,并利用随机隐码技术实现了认证过程的隐私保护.此外,朱岩等人[16]提出了多云协同存储环境下的PDP方案,王化群等人[17]增强了该方案的安全性.贾小华等人[15]实现了多云环境下文件的批量审计.王博洋等人[12]提出了支持文件共享的PDP方案,实现了低成本的用户共享权限的授予与回收.付艳艳等人[20]提出了面向云存储的多副本数据完整性审计方案.
以上方案为解决云存储数据完整性审计问题提供了可行思路,为进一步研究数据完整性审计模型及算法奠定了良好的基础.然而,现有方案仅考虑了单个文件的审计问题,未考虑大规模文件的协调审计问题,统称为B-PDP(basic PDP)模型[15].在云存储环境下,面对大数据量和多样性的审计需求,现有方案存在的问题是:1)文件数量庞大,完成全域文件审计成本高;2)文件活跃程度不同,活跃文件不能及时得到审计,导致用户体验下降,不活跃文件可能被频繁审计带来了不必要的审计开销;3)文件被损坏概率不同,高强度审计所有文件将导致审计负载过重,在现实中不可行;4)采用单一审计策略容易造成某些文件长时间得不到审计,导致审计系统覆盖率不足.
为了解决以上问题,本文提出了一种综合考虑文件审计需求、审计效率和审计覆盖率的数据完整性自适应审计方法SA-PDP(self-adaptive provable data possession).该方法依据文件属性制定满足其安全需求的审计方案,协调完成全域文件的审计,具有低成本、高效率等特点,既能满足用户的审计需求,又能有效减少文件审计成本,提高系统的审计效率.
本文的主要工作及贡献如下:
1) 设计并实现了SA-PDP方法,该方法能够基于文件属性自适应调节数据完整性审计方案,使审计方案的执行强度与文件的审计需求高度匹配;
2) 提出了2种审计方案的动态更新算法,主动更新算法保证了审计系统的覆盖率,被动更新算法能够及时满足文件的审计需求;
3) 提出了文件审计方案的评价标准,通过计算审计方案的执行强度和文件的审计需求,动态描述了二者的匹配程度;
4) 实现了原型系统SA-PDP和B-PDP,分析了系统的存储开销和通信开销,并从审计效率和审计方案的匹配度方面进行了多组对比实验;相较于B-PDP方法,SA-PDP的审计总执行时间减少了50%,并且SA-PDP审计方案的达标率提高了30%.
1 系统模型和预备知识
本节首先对数据完整性审计的系统模型和相关概念进行了描述与定义,然后介绍预备知识.
1.1 数据完整性审计的系统模型
数据完整性审计系统由云存储用户、云存储服务器、第三方审计者组成,如图1所示.用户是云存储服务的使用者;云存储服务器为用户提供计算和存储服务;第三方审计者代替用户执行具体的审计任务,以减轻用户的审计负担.
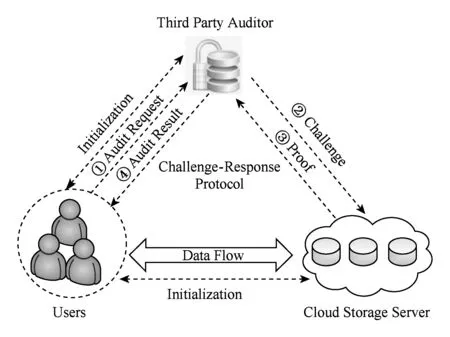
Fig. 1 System model for data integrity checking图1 数据完整性审计的系统模型
数据完整性审计[15]包含5个基本算法,分别是密钥生成算法KeyGen、数据块(data block)认证标签生成算法TagGen、挑战信息生成算法ChalGen、数据持有性证据生成算法ProofGen和证据验证算法Verify.
数据完整性审计过程分为3个阶段:
阶段1. 初始化阶段
用户使用KeyGen生成数据块认证标签的密钥对(sktag,pktag)和文件信息加密密钥skHash,使用TagGen生成文件数据块的认证标签集合Φ={φi|i∈[1,n]}和文件的摘要信息Minfo.用户发送(Minfo,skHash,pktag)给审计者,发送(M,Φ)给云存储服务器.
阶段2. 确认审计阶段
审计者使用ChalGen生成挑战信息C并发送给云存储服务器.云存储服务器使用ProofGen生成数据持有性证据信息P并返回给审计者.审计者使用Verify验证证据信息,若通过审计表明文件完好存储到云服务器,删除本地副本.
阶段3. 抽样审计阶段
定期执行阶段2,抽样检测云端数据的完整性.
1.2 审计系统的基本概念
审计系统通过制定文件的审计方案协调完成所有文件的审计任务,审计方案规定了文件的审计周期和识别率.
定义1. 审计周期T.指连续2次审计过程的间隔时间.审计周期越小,审计文件越频繁,同时意味着审计成本随之增大.
定义2. 识别率RR(recognition rate).指审计系统能够识别出文件损坏的概率.假设文件的数据块总数为n,数据块损坏个数为x且相互独立,被挑战数据块个数为c,则RR计算如下[4]:
(1)
文件的识别率不同,被查询数据块个数差异明显,如图2所示.例如,数据块总数为10 000的文件,当RR≥99%时,c≥450;当RR≥90%时,c≥228.
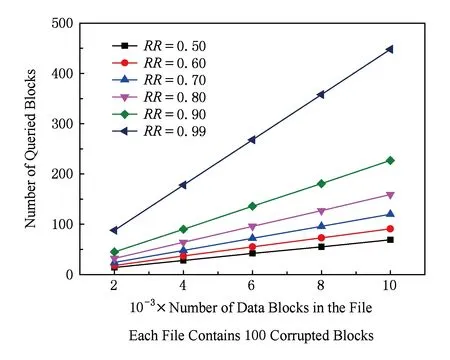
Fig. 2 The number of queried blocks under different RR图2 不同识别率下的查询数据块块数
定义3. 审计方案AP(audit plan).指执行文件审计的具体计划,AP由形如〈T,RR〉的二元序偶组成,T是文件的审计周期,RR是识别率.文件Mk的审计方案表示为APk.
文件M作为系统的审计对象,由n个数据块组成,每个数据块包含s个数据扇(data sector),表示为M={mij|i∈[1,n],j∈[1,s]}.数据块是验证文件完整性的基本单位,数据扇是文件读写的基本单位.文件的属性信息反映了文件审计需求,并据此确定文件的审计方案.
定义4. 文件属性.描述了文件状态和特征,由形式为〈d,h〉的二元序偶组成,d为文件的损坏概率,h为文件的访问热度.文件损坏概率预测文件遭到损坏的可能性大小;文件访问热度反映了文件在当前时间区间的活跃程度.文件Mk的属性记为Attrk(d,h).

Fig. 3 Audit queue for storing the audit projects图3 审计方案队列
1.3 预备知识
双线性对映射是执行数据完整性验证的基础函数,定义如下:存在2个阶数为p(p为大素数)的乘法循环群G1和G2,g是群G1的生成元.如果映射e:G1×G1→G2满足如下性质,则称e为双线性对映射:
1) 可计算性.存在一个高效的算法可以计算出映射e.
2) 双线性.对于所有u,v∈G1和a,b∈p,e(ua,vb)=e(u,v)ab均成立.
3) 非退化性.e(g,g)≠1G2,其中1G2表示群G2的单位元.
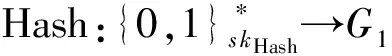
2 数据完整性自适应审计模型
本节首先介绍SA-PDP模型的审计流程,然后提出文件审计方案的生成和自适应更新方法,最后给出文件审计方案的评价标准.
2.1 自适应审计模型的审计流程
定义5. SA-PDP模型由5个基本算法组成:
1)PrePDP(ζM,1λ)→(keys,ζΦ,ζMinfo,ζ(0|1)).输入文件列表ζM和安全参数k,输出密钥、数据块认证标签列表ζΦ、文件的摘要信息列表ζMinfo、预处理结果列表ζ(0|1).
PrePDP算法循环执行文件的数据完整性审计过程[15]的初始化阶段和确认阶段完成文件的预处理.keys包括密钥对(sktag,pktag)和散列函数私钥skHash.输入安全参数λ,选择sktag,skHash∈G1作为标签私钥和散列函数私钥,计算pktag=gs ktag作为标签公钥.循环执行TagGen处理文件列表ζM,生成文件的认证标签集合.以文件Mk为例,生成数据块认证标签集合Φk.随机选取x1,k,x2,k,…,xs,k∈p,计算uj,k=gxj,k,j∈[1,s].计算数据块mi,k的认证标签φi,k如下:
(2)
2)AuditProGen(ζM)→ζAP.输入文件列表ζM,输出文件审计方案列表ζAP.以文件Mk为例,依据文件属性Attrk(d,h)生成文件的审计方案APk.
3)InsertQueue(ζAP)→ζQ.输入文件审计方案列表ζAP,输出审计队列ζQ.
生成文件审计方案列表后,依据审计周期构建多个审计方案队列,如图3所示.队列中每个节点由形如〈FIDk,Tk,rrk〉的三元组构成,FIDk是文件描述符,Tk是文件的审计周期,rrk是识别率.由InsertQueue算法将文件审计方案插入到相应的审计队列.
4)DeQueue(ζQ)→BufQueue.输入审计队列ζQ,输出审计缓存区BufQueue.
DeQueue算法定期从审计队列取出文件审计方案并放入审计缓存区BufQueue,成为待审计文件.
5)RunPDP(BufQueue)→{0|1}.输入审计缓冲区BufQueue,输出审计结果{0|1}.
RunPDP算法依次取出审计缓存区中文件审计方案〈FIDk,Tk,rrk〉,执行数据完整性审计,并输出审计结果.根据FIDk获得文件的摘要信息Minfo,k,运行ChalGen生成挑战信息Ck.依据识别率rrk计算被挑战数据块数量并随机挑选相应数量的数据块组成挑战集合Ik,为每个被挑战数据块生成一个随机值vi∈*p.选取随机值yk∈*p计算挑战戳Yk=(pktag)yk.发送Ck=({i,vi}i∈Ik,Yk)给云存储服务器.云存储服务器运行ProofGen生成数据持有性证据Pk.证据信息Pk由标签拥有证据TPk和数据块拥有证据DPk组成,计算如下:
(3)
其中,MPj是数据扇的线性集合,计算如下:
(4)
云服务器将数据持有性证据Pk发送给审计者.审计者运行Verify算法验证数据持有性证据Pk.首先计算挑战散列值的连乘积Hchal,k,计算如下:
(5)
然后,验证Pk是否满足下式:
DPk×e(Hchal,k,pktag)=e(TPk,gyk).
(6)
若满足式(6),输出1,表示文件完好;反之,输出0,表示文件被损坏.
SA-PDP审计过程由3个阶段组成:初始化阶段、审计方案生成阶段和定期审计阶段,如图4所示.1)初始化阶段进行PDP方案的预处理,生成数据块认证信息并确保数据及相应信息正确存储到云端;2)审计方案生成阶段,审计者依据文件的属性信息生成审计方案并创建文件审计队列;3)定期审计阶段,审计者定期从文件审计队列获取文件审计方案并执行数据完整性审计.

Fig. 4 Audit process of SA-PDP图4 SA-PDP的审计流程
2.2 文件审计方案的生成
文件审计方案规定了文件的审计周期和执行强度.审计方案由文件的审计需求决定,而文件属性信息是文件审计需求的集中体现.在文件审计方案生成时,首先记录文件的属性信息;然后,依据属性信息生成文件的审计方案.
文件属性记录了文件损坏概率和文件访问热度信息,由损坏概率级别dk、损坏次数、访问热度级别hk、访问次数组成,如图5所示.初始化阶段设置文件属性为0,在固定时间段内记录文件属性值.例如,在审计周期T0~T1之间,文件Mk属性值变动被及时记录到文件属性结构.为减少成本,此过程只记录属性变动的文件.记录时间段内损坏次数和访问次数是决定属性级别的依据,在时间段结束时进行属性级别更改,并重置损坏次数和访问次数值,进入下一个时间段执行.
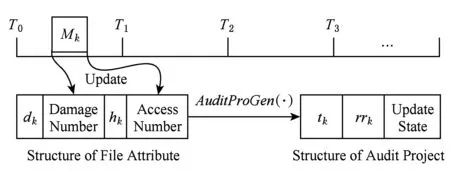
Fig. 5 Process of updating file attributes图5 文件属性的更新过程
在记录时间段结束时,依据文件损坏次数和访问次数设置文件损坏概率级别和文件访问热度级别,如表1、表2所示.设定损坏概率级别总数为dmax,访问热度级别总数为hmax,由表1可得dmax=3,由表2可得hmax=5.属性级别更新分为降级操作和升级操作.降级操作针对前一个审计周期属性中级别变动文件,检验当前审计周期内该文件属性,如果属性值低于当前属性级别的最低阈值则执行属性降级操作;反之,保持属性级别不变.升级操作针对当前审计周期属性变动的文件,依据文件属性映射表设定文件属性级别.当前审计周期结束时,重置属性级别变动文件的损坏次数和访问次数值.

Table 1 Mapping Table of Levels of Damage Probability
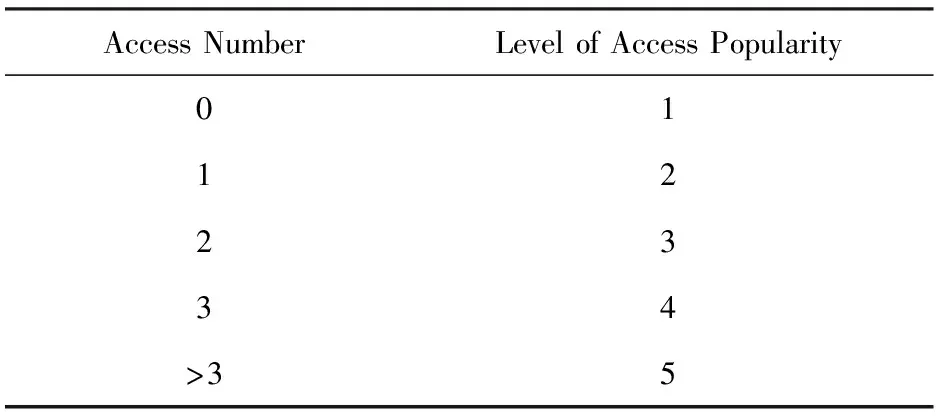
Table 2 Mapping Table of Levels of Access Popularity
审计方案由审计周期和识别率组成,依据服务等级协议设定审计周期级别LT和识别率级别LRR,如表3、表4所示.设定审计周期的级别总数为LTmax,识别率的级别总数为LRRmax,表3中LTmax=5,表4中LRRmax=3.

Table 3 Mapping Table of Levels of Audit Period

Table 4 Mapping Table of Levels of Recognition Rate
确立文件审计周期级别LTk时,首先依据文件属性值〈dk,hk〉,分别计算由文件损坏概率确立的审计周期级别LTdk和由文件访问热度确立的审计周期级别LThk,然后取二者的最小值,计算如下:
LTk=min{LTdk,LThk}=
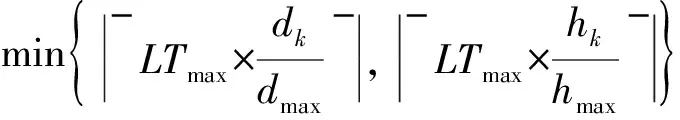
(7)
确立文件识别率级别LRRk时,首先依据文件属性值〈dk,hk〉,分别计算由文件损坏概率确立的识别率级别LRRdk和由文件访问热度确立的识别率级别LRRhk,然后取二者的最大值,计算如下:
LRRk=max{LRRdk,LRRhk}=

(8)
获得审计周期级别LTk和识别率的级别LRRk后,由表3、表4可得到文件的审计周期Tk和识别率rrk.
2.3 审计方案的自适应更新过程
定义6. SA-PDP审计方案自适应更新过程由2个算法组成:
1)UPGen(ζM)→ζAPU.输入属性值变动的文件列表ζMU,输出待更新的审计方案列表ζAPU.
在执行DeQueue(ζQ)后,检测文件的属性变化.如果文件属性变化不符合当前审计方案的阈值,执行审计方案更新操作.以Mk为例,根据变动的文件属性值Attrk,生成更新的文件审计方案APU,k.所有待更新的审计方案组成审计方案更新列表ζAPU.
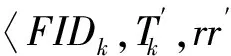
依据方案更新请求的发起者不同,审计方案更新算法分为主动更新算法(active audit plan self-adaptive update, AASU)和被动更新算法(lazy audit plan self-adaptive update, LASU).由审计者主动检测文件审计方案变更需求的算法,称为主动更新算法;由被审计文件发起的审计方案更新请求的算法,称为被动更新算法.主动更新算法保证审计系统具有高覆盖率,而被动更新算法能够及时满足文件的审计需求.为了便于描述,定义相关符号,如表5所示:

Table 5 Definition of Symbols of Update Algorithm
主动更新算法AASU在文件审计完成后,获取文件最新的属性值进行更新需求判断,如果原始方案的执行强度与审计需求不符,重新生成新方案并插入到新队列;否则,保持原有审计方案不变,插入到原始队列.AASU算法不仅能保证审计方案匹配度,并且覆盖了所有文件,具有通用性.AASU算法的不足在于无论文件属性变化与否,都需要进行方案更新检查,造成系统资源的浪费,并且AASU更新方案具有滞后性,对于属性发生变化的文件只有等到审计完成后才能执行审计方案的变更.
算法1. 审计方案的主动更新算法AASU.
输入:ζQ,Θ;
输出:ζQU.
① 在最大审计周期Tmax内:
② for (i=1;i≤LTmax;i++) {
③ for (j=1;j≤η;j++){
④ 获取并执行审计队列Qi中第j个审计方案APj;
⑤ 获取文件属性值〈dk,hk〉;
⑥ 计算审计方案的执行强度与文件审 计需求差χj;
⑦ if (χj>Θ)生成新审计方案并插入相应审计队列;
⑧ else 保持原始审计方案APj不变,插 入到原始队列;
⑨ }
⑩ }

与主动更新算法不同,被动更新算法LASU由属性变化的文件向审计方案队列发起审计方案更新请求,避免了大量审计方案的更新需求判断,并且提高了方案更新的时效性.
被动更新算法LASU增加了文件属性的更新状态位,以空间换时间,避免了完成审计后更新阈值的判断,并且文件属性变动后可以即刻修改文件的更新方案,解决了更新审计方案滞后的问题.
算法2. 审计方案的被动更新算法LASU.
输入:ζQ,Θ;
输出:ζQU.
① 在最大审计周期Tmax内:
② if (文件属性改变) {
③ 根据文件属性变化计算文件的审计需求差值χ;
④ if (χ>Θ){
⑤ 生成新审计方案并插入相应队列;
⑥ 设置S=1(默认为0);
⑦ }
⑧ }
⑨ for (i=1;i≤LTmax;i++) {
⑩ for (j=1;j≤η;j++){




2.4 文件审计方案的评价标准
审计方案的好坏由文件审计的执行总时间、系统可审计文件数量、审计方案的匹配度进行评价.为了论述方便,定义审计方案相关符号,如表6所示:

Table 6 Definition of Symbols of Audit Plan
定义7. 文件审计的执行总时间E.指审计期间内,所有被审计文件的执行时间总和.假设文件列表为{M1,M2,…,MN},对文件Mi共执行numi次审计,第j次的执行时间为εi,j,则E计算为
(9)
文件审计的执行总时间反映了系统的审计开销,执行总时间越大,审计代价越高.审计系统设计的目标是在满足审计需求的前提下,尽可能减少文件的总执行时间.
定义8. 系统可审计文件数量NUM.指在审计期间内,系统已经审计的文件总数.设定文件的审计周期从小到大排列为{T1,T2,…,TD},审计周期Ti中文件的平均执行时间为τi,则NUM的理论值为
(10)
其中,T0=0,表示开始时刻.由于在审计周期Ti内存在系统空闲情况,故系统可审计文件数量小于理论值.特别地,当系统以固定周期Ti审计文件,系统可审计文件数量计算为
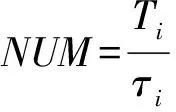
(11)
当审计周期Ti过小,导致系统审计能力迅速达到最大值;当审计周期Ti过大,虽然增加了审计文件数量,但将出现文件长时间不能审计而系统处于空闲的情况,不仅造成系统资源浪费,并导致用户体验下降.因此,应当将文件审计任务有序分布在多个审计周期内,既能充分利用系统计算资源,提高文件审计数量,又能及时满足文件的审计需求.
审计方案的匹配度反映了审计方案的执行强度是否适当,量化文件审计需求和审计方案的执行强度予以评价.
定义9. 审计需求R(audit requirement).指文件执行数据完整性审计的迫切程度,R∈(0,100].文件审计需求最大值表示为Rmax(默认值100).
文件审计需求和文件属性〈dk,hk〉密切相关,通过归一化方法将单个因素的影响映射到文件审计需求R的值域,并依据影响因素的权重值计算文件审计需求:
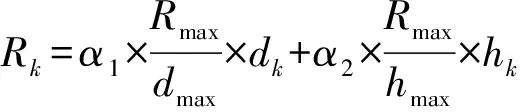
(12)
其中,α1和α2分别是损坏概率和访问热度的权重值,且α1+α2=1.假定dmax=10,hmax=10,α1=α2=0.5,文件属性Attr〈2,5〉,文件的安全需求Rk=35.
定义10. 审计方案执行强度(execution strength,ES).ES反映了审计方案检错能力和力度,它的最大值表示为ESmax(默认值100).
在文件审计方案〈tk,rrk〉中,文件审计周期分为LTmax个级别,识别率分为LRRmax个级别.审计方案的执行强度计算为

(13)其中,β1和β2分别是审计周期和识别率的权重值,且β1+β2=1.假定LTmax=10,LRRmax=10,β1=β2=0.5,对于审计方案AP〈2,5〉的执行强度ES=35.
定义11. 期望强度(EES).EES表示与文件审计需求相匹配的审计方案所需的最小执行强度,其计算为

(14)
定义12. 匹配度(match degree,MD).MD表示期望强度与文件实际执行强度的匹配程度,其计算为
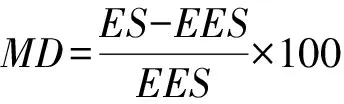
(15)
MD的大小反映了文件审计方案与最优化审计方案的偏离程度,MD数值为正表示审计方案的执行强度高于文件的审计需求;MD数值为负表示审计方案的执行强度弱于文件的审计需求;MD数值为0表示实际审计方案与文件审计需求正相符.MD过高浪费系统的计算资源,MD过低不能满足文件的审计需求.
3 实验结果与分析
3.1 实验环境
本文利用PBC库(pbc-0.5.14)实现了自适应审计的原型系统SA-PDP及对比系统B-PDP,采用C语言开发,系统参数为Ubuntu 12.04.3 LTS,Linux 3.8.0-29(x86_64),4x Intel®Xeon®CPU E5502 @ 1.87 GHz,内存16 GB,硬盘ATA Hitachi HTS54501 150 GB.在每个审计周期,按照二八定律生成不同热度的文件并随机损坏文件,测试文件大小1 MB.
3.2 存储开销和通信开销分析
为了完成文件自适应审计,云存储服务器首先记录文件的属性信息〈dk,hk〉,然后在文件审计时将其随证据信息一起返回给审计者,最后审计者依据文件属性〈dk,hk〉更新文件的审计方案〈FIDk,tk,rrk〉.本文方案额外增加的存储开销(单位为B)和通信开销分别为3|int|+|FID|+|float|和2|int|,其中|int|是整型变量的大小,|float|是浮点型变量的大小,|FID|是文件标识的大小.在原型系统SA-PDP中,|int|=4 B,|float|=4 B,|FID|=216 B.每个文件额外增加的存储开销和通信开销分别为232 B和8 B,在可接受的范围之内.
3.3 审计效率测试
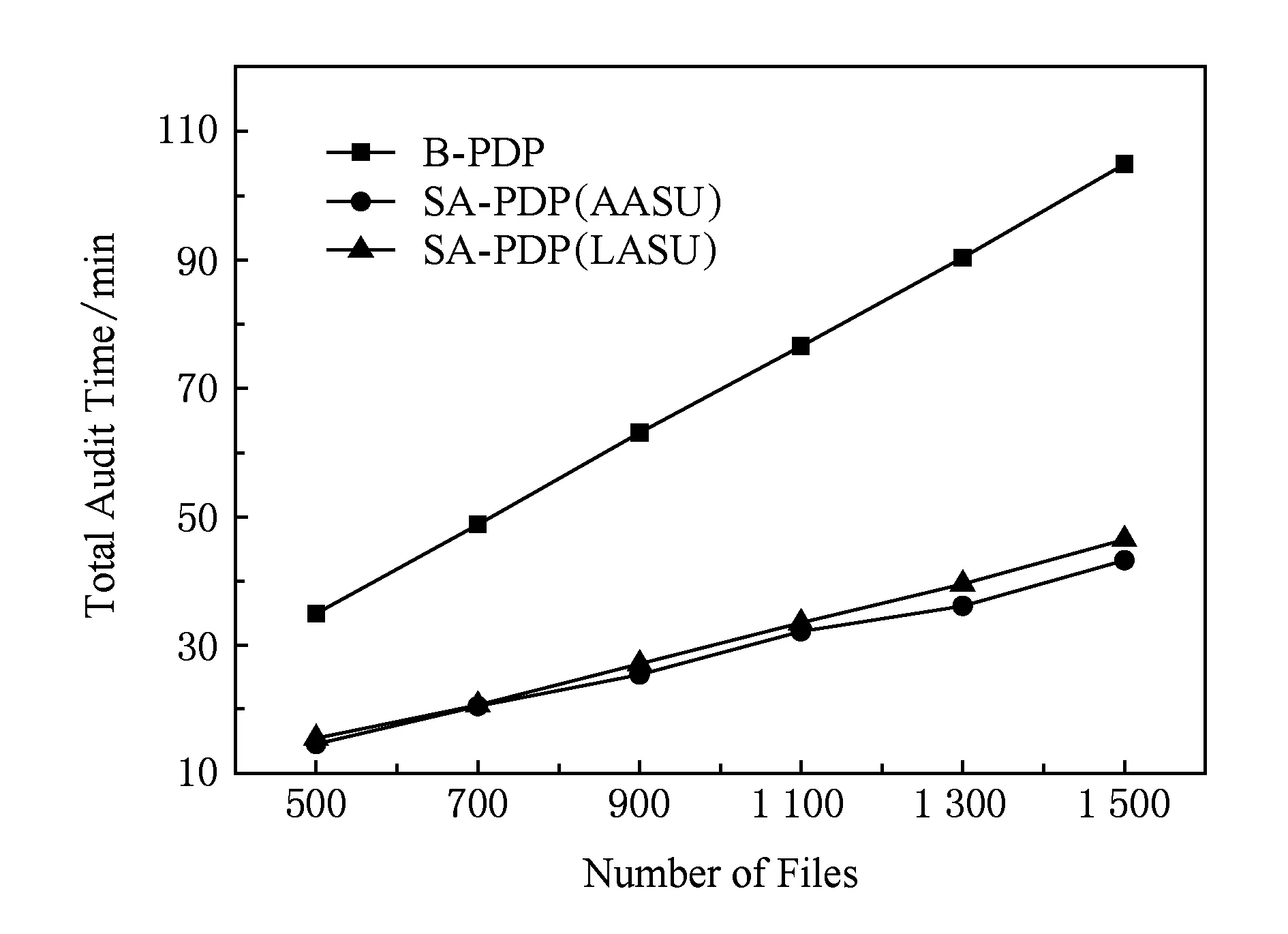
Fig. 6 Comparison of the total audit time at different numbers of files图6 不同文件数目下审计总执行时间对比
设定测试时间为72 h,文件数量为500~1 500,统计审计过程文件的总执行时间,如图6所示.相较于B-PDP,SA-PDP的文件总执行时间至少减少了50%,并且SA-PDP审计时间增长趋势平缓.这是因为,B-PDP按照固定频率审计文件造成文件被频繁审计,而SA-PDP按照文件审计需求把文件审计任务分布在多个时间周期内,消除了不必要的审计.SA-PDP节省时间越多,可以审计的文件数量越多.SA-PDP模型中LASU方法的审计执行时间略高于AASU方法.这是因为,采用LASU时,文件要求系统响应其审计请求,造成文件审计次数增多;LASU牺牲部分审计效率而增加了文件的审计强度.
设定测试时间为72 h,每小时向审计系统增加4 000个文件,测试系统可审计文件数量,如图7所示.审计初期,B-PDP审计文件数量多于SA-PDP,LASU方法审计文件多于AASU方法;而SA-PDP可审计文件最大能力明显高于B-PDP.SA-PDP方法将审计任务分布于多个周期,审计初期,部分文件不在审计周期内而不被审计.由于LASU方法主动提交审计请求使其初期审计文件次数多于AASU方法.审计后期,由于B-PDP频繁审计浪费大量计算资源,使系统过早达到审计极限.而LASU方法积极的审计特性牺牲了部分计算资源,使审计文件数量低于AASU方法.

Fig. 7 Comparison of the number of audit files at different audit time图7 不同审计时间内可审计文件数量对比
3.4 审计方案的匹配度比较
首先,依据一个测试实例,计算并比较不同模型审计方案的匹配度;然后,在实际运行环境中测试审计方案的动态匹配程度.
测试实例设计如下:按照二八定律划分不同热度、不同损坏概率的文件数量,计算采用不同模型生成的文件审计方案的匹配度.设定参数α1=α2=0.5,β1=β2=0.5,dmax=3,hmax=5,LTmax=5,LRRmax=3.由式(12)求得不同属性文件的审计需求.以属性〈1,1〉为例,该类型文件的审计需求R〈1,1〉=26.7.
表7显示了采用不同模型生成审计方案的匹配度.B-PDP模型针对所有文件统一采用适中执行强度的审计方案,即AP=〈72 h,95%〉.SA-PDP模型首先依据文件属性计算审计需求,然后由式(7)(8)生成与之对应的审计方案.根据文件的审计需求和生成的审计方案,结合式(14)(15)计算B-PDP模型和SA-PDP模型生成审计方案的匹配度.
可以看出,采用SA-PDP模型生成的审计方案匹配度为0,即文件审计方案执行强度与文件审计需求正相符;采用B-PDP模型针对所有文件采用固定审计方案,匹配度围绕0波动,表现为审计方案强于或者弱于文件的审计需求.因此,SA-PDP模型可以在满足文件审计需求的前提下执行适当强度的审计方案,克服了B-PDP模型采用过强或者过弱审计方案的问题,并将释放出的资源用于审计更多文件.
在实际运行环境中,当审计方案执行完毕后,计算审计方案的匹配度,图8显示了所有文件的审计方案在不同匹配度的分布.可以看到,B-PDP模型的审计方案较为平均地分布在不同匹配度;而SA-PDP模型的审计方案集中分布于匹配度0周围.在SA-PDP模型中,与文件审计请求匹配的审计方案比例达到53%,而在B-PDP模型中仅达到了20%.这就表明,相较于B-PDP,SA-PDP更能满足文件的审计需求,审计方案的匹配率提高了30%以上.此外,结合图6和图8可以看出,SA-PDP不仅满足了文件的审计请求,并有效减轻了系统的审计负担.
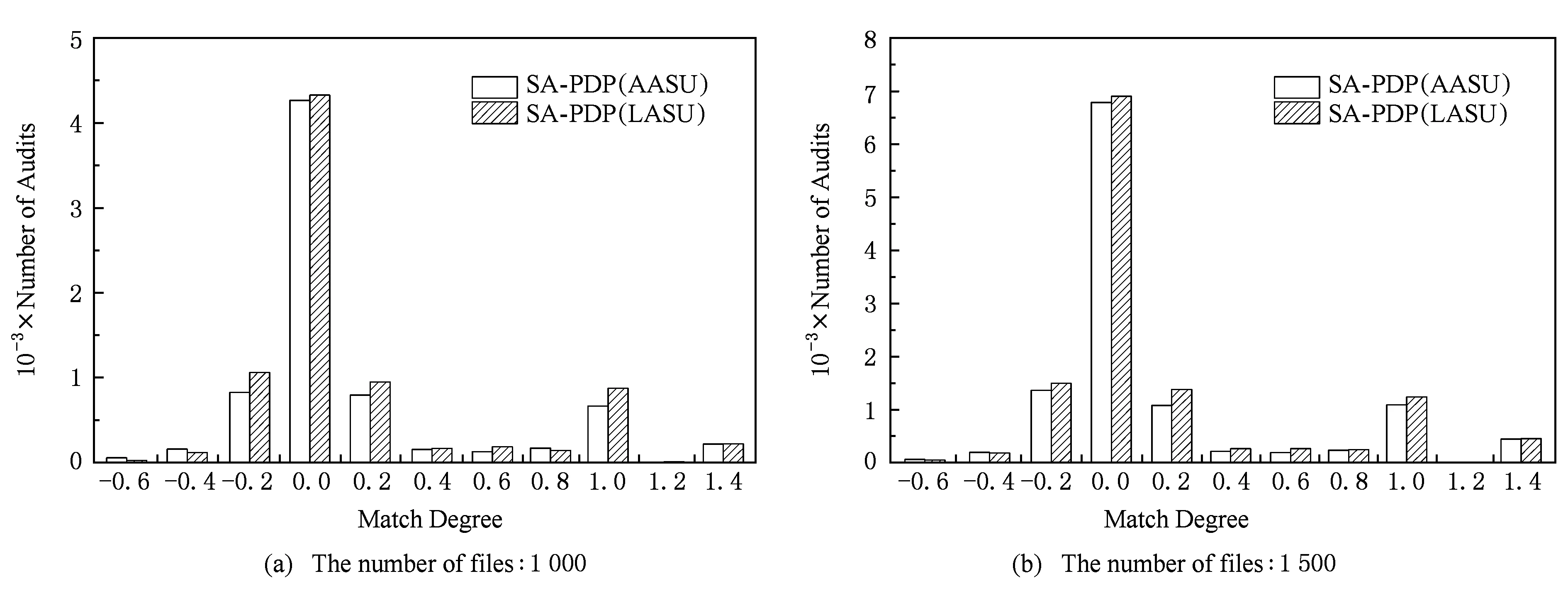
Fig. 9 The audit number of audit plans at different match degrees图9 审计次数在不同匹配度下的分布
图9比较了审计方案的主动更新算法AASU和被动更新算法LASU的文件审计次数.2种算法匹配度分布基本相同,表明2种审计方案更新算法在满足文件审计需求的效果基本一致.相较于主动更新算法AASU,被动更新算法LASU算法执行了更多次的审计.这是因为,被动更新算法LASU为了及时响应文件的审计请求,接收了更多热点文件的审计请求.这就表明,LASU算法在满足文件审计请求的同时,比AASU算法具有更强的审计强度.
4 结束语
本文设计并实现了一种云存储环境下数据完整性自适应审计方法SA-PDP.该方法能够基于文件的属性信息动态调整文件的审计方案,协调完成全域文件的审计,不仅能够满足文件的审计需求,还能有效减少了系统的审计成本,提高系统的审计效率.后续工作将针对审计代理的可扩展性和可用性问题进行深入研究.
[1]Tan Shuang, Jia Yan, Han Weihong. Research and development of provable data integrity in cloud storage[J]. Chinese Journal of Computers, 2015, 38(1): 164-177 (in Chinese)(谭霜, 贾焰, 韩伟红. 云存储中的数据完整性证明研究及进展[J]. 计算机学报, 2015, 38(1): 164-177)
[2]Li Hui, Sun Wenhai, Li Fenghua, et al. Secure and privacy-preserving data storage service in public cloud[J]. Journal of Computer Research and Development, 2014, 51(7): 1397-1409 (in Chinese)(李晖, 孙文海, 李凤华, 等. 公共云存储服务数据安全及隐私保护技术综述[J]. 计算机研究与发展, 2014, 51(7): 1397-1409)
[3]Juels A, Kaliski Jr B S. PORs: Proofs of retrievability for large files[C]Proc of the 14th ACM Conf on Computer and Communications Security. New York: ACM, 2007: 584-597
[4]Ateniese G, Burns R, Curtmola R, et al. Provable data possession at untrusted stores[C]Proc of the 14th ACM Conf on Computer and Communications Security. New York: ACM, 2007: 598-609
[5]Shacham H, Waters B. Compact proofs of retrievability[C]Proc of the 14th Int Conf on Theory and Application of Cryptology and Information Security. Berlin: Springer, 2008: 90-107
[6]Erway C, Küpçü A, Papamanthou C, et al. Dynamic provable data possession[C]Proc of the 16th ACM Conf on Computer and Communications Security. New York: ACM, 2009: 213-222
[7]Wang Qian, Wang Cong, Li Jin, et al. Enabling public verifiability and data dynamics for storage security in cloud computing[C]Proc of the 14th European Symp on Research in Computer Security. Berlin: Springer, 2009: 355-370
[8]Qin Zhiguang, Wang Shiyu, Zhao Yang, et al. An auditing protocol for data storage in cloud computing with data dynamics[J]. Journal of Computer Research and Development, 2015, 52(10): 2192-2199 (in Chinese)(秦志光, 王士雨, 赵洋, 等. 云存储服务的动态数据完整性审计方[J]. 计算机研究与发展, 2015, 52(10): 2192-2199)
[9]Wang Cong, Chow S S M, Wang Qian, et al. Privacy-preserving public auditing for secure cloud storage[J]. IEEE Trans on Computers, 2013, 62(2): 362-375
[10]Zhu Yan, Wang Huaixi, Hu Zexing, et al. Efficient provable data possession for hybrid clouds[C]Proc of the 17th ACM Conf on Computer and Communications Security. New York: ACM, 2010: 756-758
[11]Zhu Yan, Ahn G J, Hu Hongxin, et al. Dynamic audit services for outsourced storages in clouds[J]. IEEE Trans on Services Computing, 2013, 6(2): 227-238
[12]Wang Boyang, Li Baochun, Li Hui. Oruta: Privacy-preserving public auditing for shared data in the cloud[J]. IEEE Trans on Cloud Computing, 2014, 2(1): 43-56
[13]Yu Yong, Ni Jianbing, Au M H, et al. Improved security of a dynamic remote data possession checking protocol for cloud storage[J]. Expert Systems with Applications, 2014, 41(17): 7789-7796
[14]Wang Boyang, Li Baochun, Li Hui. Knox: Privacy-preserving auditing for shared data with large groups in the cloud[C]Proc of the 10th Int Conf on Applied Cryptography and Network Security. Berlin: Springer, 2012: 507-525
[15]Yang Kan, Jia Xiaohua. An efficient and secure dynamic auditing protocol for data storage in cloud computing[J]. IEEE Trans on Parallel and Distributed Systems, 2013, 24(9): 1717-1726
[16]Zhu Yan, Hu Hongxin, Ahn G J, et al. Cooperative provable data possession for integrity verification in multicloud storage[J]. IEEE Trans on Parallel and Distributed Systems, 2012, 23(12): 2231-2244
[17]Wang Huaqun, Zhang Yuqing. On the knowledge soundness of a cooperative provable data possession scheme in multicloud storage[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(1): 264-267
[18]Wang Huaqun. Proxy provable data possession in public clouds[J]. IEEE Trans on Services Computing, 2013, 6(4): 551-559
[19]Wang Huaqun. Identity-based distributed provable data possession in multicloud storage[J]. IEEE Trans on Services Computing, 2015, 8(2): 328-340
[20]Fu Yanyan, Zhang Min, Chen Kaiqu, et al. Proofs of data possession of multiple copies[J]. Journal of Computer Research and Development, 2014, 51(7): 1410-1416 (in Chinese)(付艳艳, 张敏, 陈开渠, 等. 面向云存储的多副本文件完整性验证方案[J]. 计算机研究与发展, 2014, 51(7): 1410-1416)
Wang Huifeng, born in 1986. PhD candidate in Northwestern Polytechnical University. His main research interests include cloud computing, data security, and massive data storage.
Li Zhanhuai, born in 1961. Professor and PhD supervisor. His main research interests include database theory and massive data storage (lizhh@nwpu.edu.cn).
Zhang Xiao, born in 1978. PhD and associate professor. His main research interestes include green storage and massive data storage (zhangxiao@nwpu.edu.cn).

Sun Jian, born in 1982. PhD candidate. His main research interestes include cloud storage and green storage (qwert3277@163.com).

Zhao Xiaonan, born in 1979. Lecturer and PhD. Her main research interestes include hierarchical storage and cloud storage (zhaoxn@nwpu.edu.cn).
A Self-Adaptive Audit Method of Data Integrity in the Cloud Storage
Wang Huifeng, Li Zhanhuai, Zhang Xiao, Sun Jian, and Zhao Xiaonan
(SchoolofComputerScience,NorthwesternPolytechnicalUniversity,Xi’an710129)
As an important issue of cloud storage security, data integrity checking has attracted a lot of attention from academia and industry. In order to verify data integrity in the cloud, the researchers have proposed many public audit schemes for data integrity. However, most of the existing schemes are inefficient and waste much computing resource because they adopt fixed parameters for auditing all the files. In other words, they have not considered the issue of coordinating and auditing the large-scale files. In order to improve the audit efficiency of the system, we propose a self-adaptive provable data possession (SA-PDP), which uses a self-adaptive algorithm to adjust the audit tasks for different files and manage the tasks by the audit queues. By the quantitative analysis of the audit requirements of files, it can dynamically adjust the audit plans, which guarantees the dynamic matching between the audit requirements of files and the execution strength of audit plans. In order to enhance the flexibility of updating audit plans, SA-PDP designs two different update algorithms of audit plans on the basis of different initiators. The active update algorithm ensures that the audit system has high coverage rate while the lazy update algorithm can make the audit system timely meet the audit requirements of files. Experimental results show that SA-PDP can reduce more than 50% of the total audit time than the traditional method. And SA-PDP effectively increases the number of audit files in the audit system. Compared with the traditional audit method, SA-PDP can improve the standard-reaching rate of audit plans by more than 30%.
data security; cloud storage; data integrity checking; provable data possession; self-adaptive audit
2015-10-12;
2016-02-16
国家“八六三”高技术研究发展计划基金项目(2013AA01A215);国家自然科学基金项目(61472323,61502392);中央高校基本科研业务费专项资金项目(3102015JSJ0009);华为创新基金项目(YB2014040023) This work was supported by the National High Technology Research and Development Program of China (863 Program) (2013AA01A215), the National Natural Science Foundation of China (61472323, 61502392), the Fundamental Research Funds for the Central Universities (3102015JSJ0009), and the Huawei Innovation Fund (YB2014040023).
张晓(zhangxiao@nwpu.edu.cn)
TP309.2
k是
符和数据块索引的连接,Wi,k=FID‖i,mij,k是文件Mk的数据块mi,k的第j个数据扇.文件Mk的认证标签集合为Φk={φi,k|i∈[1,n]}.循环生成各个文件列表的认证标签集合ζΦ={Φk|k∈[1,N]},N为文件总数.循环执行确认审计阶段操作,保证文件正确存储到云端.
猜你喜欢
好日子(2022年3期)2022-06-01
———占旭刚4
北广人物(2020年48期)2020-12-22
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
陕西画报(2018年6期)2018-02-25
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
