
基于语义指向性特征提取的数据库优化访问方法
2017-01-20 07:46:53王旭辉
河南工程学院学报(自然科学版) 2016年4期
李 浩,王旭辉
(河南工程学院 计算机学院,河南 郑州 451191)
基于语义指向性特征提取的数据库优化访问方法
李 浩,王旭辉
(河南工程学院 计算机学院,河南 郑州 451191)
为通过语义指向性索引实现数据库的优化访问,提出了一种基于语义本体模型和关联指向性特征提取的数据库优化访问方法,进行了数据库存储机制和数据结构的分析,采用匹配投影法进行数据库访问过程中干扰信息和冗余信息的滤除,采用信息融合算法实现对数据库中词频信息的均衡控制和全局寻优,提取语义本体模型的关联指向性特征,以此为指向性索引路径进行数据库信息检索,实现数据库的优化访问.仿真结果表明,采用该方法进行Web数据库访问,语义特征的波束聚焦性较好,冗余信息得到了有效抑制,数据库访问的查准率高于传统算法,性能优越.
数据库;语义;特征提取;信息融合
随着计算机信息和网络技术的发展,大量的数据信息通过网络传输,海量的数据通过Web数据库进行存储和信息调度,需要研究一种有效的数据库访问方法,从海量数据中挖掘出有效的信息特征,实现数据的指向性分析,通过关键字信息查询和语义索引实现数据库的优化访问.研究数据库优化访问的方法,在提高数据库集成调度性能方面具有重要的意义,相关算法的研究受到了广大专家学者的重视.
对数据库访问和数据调度的过程,本质是对数据信息流进行语义关键信息分析,通过语义信息特征的提取,采用自适应波束形成和语义相关度特征分析方法进行数据库访问的关键信息索引,为数据库访问提供波束指向性,实现准确索引和查询的目的.对数据库访问的传统方法主要有基于时频特征查询的数据访问调度方法、基于语义关联维特征分析的数据库访问方法和基于统计信息特征分析的数据库访问方法[1-3].这些方法采用信息子空间建模和数据关联属性挖掘,结合查询接口进行数据库的优化访问,但存在计算开销较大、在数据库访问中受到关键词属性的粗糙集干扰较大等问题,导致数据库访问过程中的查准性能不好.对此,文献[4]提出了一种基于信息流减法聚类的语义网络数据库的访问和数据调度模型,采用模糊C均值方法对数据库中的关键信息进行聚类处理,结合语义调控目标函数进行数据库的层阶调度,提高访问能力,但是该算法在数据信息特征聚类中容易陷入局部最优解,导致数据库访问过程中的收敛性不好;文献[5]提出了一种基于关键字有向图模型构建的数据库访问方法,由于数据库知识存储的基本单元具有关联耦合性,在信息分离过程中容易出现错误,导致数据库访问的精度不高.针对上述问题,本研究提出了一种基于语义本体模型检索和语义关联指向性特征提取的数据库优化访问算法,通过仿真实验进行了性能验证.
1 数据库的信息存储机制与数据结构分析
1.1 数据库的信息存储机制与存储节点分布模型

图1 Web数据库信息存储和访问机制的总体结构Fig.1 Overall structure of information storage and access mechanism of the Web database
为了研究大型Web数据库的优化访问技术,首先需要分析海量数据在数据库中的存储机制.在大型Web数据库中,将大量的数据分布到多个服务节点中,通过云存储和Deep Web数据存储方式进行数据信息的聚类和融合,数据库的访问接口集成了查询接口模块、语义特征提取模块和查询信息的输出处理模块等.其中,Web数据库的查询接口模块是通过信息的输入和关键词查询路径索引方法实现Web数据库的发现、信息抽取及数据调度和访问的;语义特征提取模块通过生成语义实体模型检索查询结果;查询信息的输出处理模块包括Web数据库的选择、查询语言的转换和数据库访问结果的提交等.通过优化的数据库访问模块化设计,可实现数据访问结果的注释和信息的合并[6].根据上述分析,可得到典型的Web数据库信息存储和访问结构模型,如图1所示.
根据上述数据库的存储结构进行数据库存储节点分布模型的构建,Web数据库三层集成分布式存储结构的数学模型为
(1)
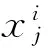
(2)
式中:x描述数据库中的文本集合,整个Web数据库系统的全文本内容的语义状态特征信息可表示为

(3)
其中,文本模块区域定位特征描述为
u=[u1,u2,…,uN]∈RmN.
(4)
假设存储节点的矢量分布轨迹di和dj为两个标度向量,数据库存储节点的分布向量之间的距离采用欧式距离,其计算公式为
(5)
通过对数据库存储节点分布结构的分析,可以估计数据库的规模.Web数据库的分布式节点在进行语义检索的过程中,输入控制参量采用单个节点适应度索引方式,可得到Web数据库访问的语义检索的控制参量输入:
(6)
设当前Web数据库的本体语义数据流是一个以三元组形式构建的本体模型,此时,语义特征的适应度和关联信息能有效表征数据库访问的关键词索引信息,可以此为依据进行数据库的访问和技术优化设计.
1.2 数据融合预处理
在进行了上述Web数据库的存储机制分析和存储节点分布模型构建的基础上,为提高对数据库访问的查准性能,需要进行数据融合处理以提高语义特征提取的指向性能力.在Web数据库中,海量数据在存储空间中的状态特征信息模型采用二元时间序列表达的方式可以描述为
(7)
式中:P为海量数据在数据库存储中的包络幅值,x(t)为输入关键词查询指向性信息参量,y(t)为干扰特征.x(t)与y(t)形成语义本体的互相关共轭关系,当X⊆U且R⊆A时,可得到数据库中信息访问的融合均衡控制方程:
(8)
式中:x0和y0为数据库访问的瞬时频率与中心频率,r为丢失信息流的干扰辐射半径.数据库的海量数据存储系统根据信息融合的空间结构形成一个包含n个矢量结合的存储空间组A={A1,A2,…,An},存储空间中的残差信号Rs投影在D中的基函数
z(t)=x(t)+iy(t)=a(t)eiθ(t),
(9)
式中:
(10)
采用匹配投影法进行数据库访问过程中干扰信息和冗余信息的滤除,通过信息融合实现对冗余数据的全局寻优.在数据库访问的语义特征提取寻优过程中,采用基于Dopplerlet的自适应特征匹配方法,可得到语义相关的词频融合状态方程:
(11)
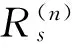
2 语义指向性特征的提取与数据库优化访问的实现
2.1 语义关联指向性特征的提取
在进行了上述数据库存储机制的分析和海量数据分布式存储节点结构模型构建的基础上,通过数据信息融合处理滤除数据库访问过程中的干扰和冗余信息,降低了数据存储的开销,以此为基础进行数据库访问算法的设计.为了克服传统方法计算开销过大、语义指向性聚焦能力不强的不足,提出了一种基于语义本体模型检索和语义关联指向性特征提取的数据库优化访问方法.采用主题树特征匹配方法构建语义本体模型,语义本体模型主要包含4层结构模型,分别为语义模型、数据模型、导航模型和表现模型[7-9].在语义本体模型中,通过数据库中的数据链聚类融合,可得到多个导向性聚类中心进行数据库访问的信息索引和指向性聚焦.在一个语义本体模型中,语义决策树采用一个三元组的形式K=(O,A,R)表示.其中,O是文本所属类别的对象集合,A是数据库的数据聚类属性集合,R是O和A之间的一个二元关系.设数据库中与语义信息相关的数据类别总数为m,语义特征信息流{xi}在数据库访问时间间隔jτ的自相关函数为
(12)
式中:N为采样的数据样本数.设E是对象集合O的一个子集,数据库中的语义指向性特征相互独立,语义信息的自相关信息为
E{h1(y1)h2(y2)}=E{h1(y1)}E{h2(y2)}.
(13)
定义E{[X-E(X)][Y-E(Y)]}为主题树特征匹配变量X与Y的协方差,记为Cov(X,Y).此时,假设输入语义主题树的随机变量X与Y分别是Web数据库的特征聚类融合中心的初始值,采用自相关协方差表示语义为
Cov(X,Y)=E{[X-E(X)][Y-E(Y)]}.
(14)
此时,得到两组信息流的自相关系数,表示关联指向性特征为
(15)
式中: ρxy是一个无量纲的量,修正每个向量vi进行特征聚类,以提高数据库访问过程中的语义波束指向性.假设波束指向的时延尺度系数为τ,对于连续的词频检索遍历x(t),其自相关函数C(τ)定义为
(16)
式(16)中,数据库访问的有用文本提取率x(t)与x(t+τ)的差别越来越大,语义信息召回的信息流x(t)与x(t+τ)完全无关,C(τ)作为自相关函数趋于0,此时得到的数据库访问结果是稳定可靠的.在数据库访问中,采用关键词索引方法,对任意两个词频信息X和Y构建Web数据库的语义本体模型的关联指向性特征分别为
(17)
(18)
(19)
式中:P(X)和P(Y)分别是访问词频信息X和Y得到的准确语义信息召回的概率密度函数,P(X∩Y)是联合访问词频信息X和Y所得到的准确语义信息召回的联合概率密度函数.通过分析上述关联指向性特征的提取结果,可采用波束形成方法进行数据库访问的语义词频信息聚焦,以提高数据库访问关键信息的波束指向性,实现数据的准确查询和访问.
2.2 数据库访问优化的实现
在进行关联指向性特征提取的基础上,为信息索引路径进行数据库的优化访问.假设数据库访问中的数据信息流为x(t),通过语义关联指向性特征构建多源节点,在海量数据的存储空间中形成新的映射.在数据存储空间中,数据存储节点的空间轨迹矢量场表示为X,采用特征值和特征向量信息模板匹配方法得到输出的融合代价为hi(t),数据库访问的干扰项为npi(t),采用异步迭代方法得到初始化的数据访问的融合中心离散度:
Xri(t)=X(t)×hi(t)+npi(t),
(20)
式中:hi(t)表示X(t)在Web数据库的语义本体加速分布融合函数,即数据库访问的语义词频信息的响应函数.为了提高访问精度,需要对冗余数据信息流进行特征压缩,得到特征压缩的控制函数
(21)
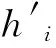
(22)
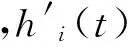
(23)
通过上述处理,得到最优访问的控制序列.输入关联指向性特征进行语义信息素聚焦,以此为索引变量进行词频分类,采用虚假最近邻点算法访问数据的K个近邻点,输入查询关键字keyword,执行输入的语义序列y(k),得到的查询结果输出为M(Q,R1),可表示为
y(k)=a(k)h(k)+n(k),
(24)
M(Q,R1)=M(keyword,p1)+M(search,p2),
(25)
式中: p1为数据库访问的查询样本测试集,p2为数据库访问的词频信息搜索训练集.通过上述处理,提高了数据库关键信息的查询性能,实现了数据库的优化访问.
3 仿真实验与结果分析

图2 数据库中海量数据信息采样时域波形Fig.2 Time domain waveform of massive datainformation sampling in the database
为测试本方法在实现Web数据库访问中的性能,进行仿真实验.实验的硬件环境:处理器为2.94 GHz的Intel(R)Core(TM)2 Duo CPU,内存为8 GB.采用Matlab仿真软件进行算法编程设计.首先,进行Web数据库的分布式存储结果模型设计,通过数据库的信息采样,进行数据库存储数据的语义本体模型的构建和关联指向性特征的提取.测试数据来自Deep Web的CWT200G数据库,信息以多媒体和文本信息的方式进行云存储分布,在数据库访问过程中,数据信息流从1 024 MB到100 GB均匀线性增长.为了测试数据库的访问性能,首先进行数据信息流的时域采样,数据采样的归一化初始频率f1=0.8 Hz,终止频率f2=0.15 Hz,数据访问的信道带宽B=1 028 Hz,冗余数据的干扰比特率为0.45 bps/s,在干扰强度为SNR=-5 dB和SNR=-8 dB条件下,进行数据库的访问和特征提取.根据上述仿真环境和参数的设定,进行数据库访问的实现过程仿真,以此作为一组样本实验集形成海量数据集合,得到数据采样的时域波形,如图2所示.
以上述采样的数据信息为测试样本集进行数据库语义关联指向性特征的提取,通过语义信息融合处理降低数据库访问过程中的特征干扰,滤除冗余信息,得到采用本方法和未进行冗余信息滤波处理的语义关联指向性特征提取结果,如图3所示.从图3可见,采用本方法进行Web数据库的数据访问,通过语义指向性特征的提取,提高了词频信息的聚焦性能,波束指向性较好,冗余信息的干扰得到了有效抑制,时频空间特征分布的聚类能力较强,提高了数据库准确访问的性能.
为了定量分析本方法进行数据库优化访问的性能,以数据查准率为测试指标,在干扰强度为-10~10 dB时进行10 000次蒙特卡罗实验,采用本方法和文献[5]的关键字查询方法得到了查准率对比结果,如图4所示.从图4可见,采用本研究的语义指向性特征提取算法对数据库访问的查准率明显高于传统方法,抗干扰能力较强,表现出了较好的性能.

图3 语义关联指向性特征提取结果Fig.3 Results of semantic connection point to characteristic extraction
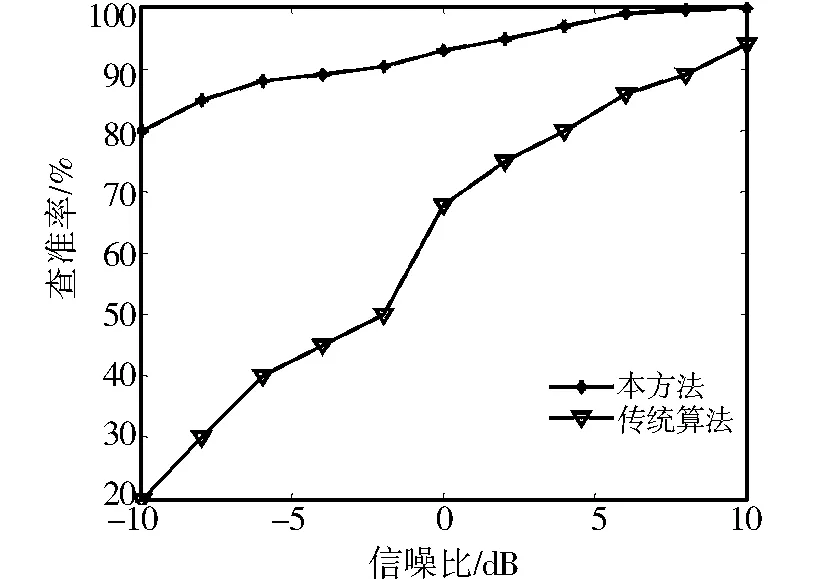
图4 性能对比Fig.4 Performance comparison
4 结语
研究了Web数据库的优化访问关键技术,提出了一种基于语义指向性特征提取的数据库优化访问算法.
[1] 辛宇,杨静,汤楚蘅,等.基于局部语义聚类的语义重叠社区发现算法[J].计算机研究与发展,2015,52(7):1510-1521.
[2] 陆兴华,陈平华.基于定量递归联合熵特征重构的缓冲区流量预测算法[J].计算机科学,2015,42(4):68-71.
[3] 王小英,刘庆杰.关系型数据库中数值数据的密文检索模型研究[J].计算机仿真,2013,30(11):409-411.
[4] CHONG F T,HECK M J R,RANGANATHAN P,et al.Data center energy efficiency:improving energy efficiency in data centers beyond technology scaling[J].IEEE Design & Test,2014,31(1):93-104.
[5] WANG L,ZHANG F,ARJONA A J,et al.GreenDCN:a general framework for achieving energy efficiency in data center networks[J].IEEE Journal on Selected Areas in Communications,2014,32(1):4-15.
[6] 卫星,张建军,石雷,等.云计算数据中心服务器数量动态配置策略[J].电子与信息学报,2015,37(8):2007-2013.
[7] 侯森,罗兴国,宋克.基于信息源聚类的最大熵加权信任分析算法[J].电子学报,2015,43(5):993-999.
[8] 罗亮,吴文峻,张飞.面向云计算数据中心的能耗建模方法[J].软件学报,2014,25(7):1371-1387.
[9] 章登义,吴文李,欧阳黜霏.基于语义度量的RDF图近似查询[J].电子学报,2015,43(7):1320-1328.
2016-01-28
李浩(1974-),男,河南洛阳人,副教授,研究方向为计算机网络与算法.
TP391
A
1674-330X(2016)04-0057-05
猜你喜欢
舰船科学技术(2023年11期)2023-07-22 08:05:12
园林科技(2021年3期)2022-01-19 03:17:48
人大建设(2018年11期)2019-01-31 02:40:50
测控技术(2018年1期)2018-11-25 09:43:42
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
新课程研究(2016年21期)2016-02-28 19:28:30
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
噪声与振动控制(2015年4期)2015-01-01 07:08:21
