
基于溯源的虚假信息传播控制方法
2017-01-17 05:18周雪妍林泽鸿张健沛印桂生
哈尔滨工程大学学报 2016年12期
杨 静,周雪妍,2,3,林泽鸿,张健沛,印桂生
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001;2.哈尔滨工程大学国家大学科技园,黑龙江哈尔滨150001;3.哈尔滨学院工学院,黑龙江哈尔滨150086;4.哈尔滨工程大学机电工程学院,黑龙江哈尔滨150001)
基于溯源的虚假信息传播控制方法
杨 静1,周雪妍1,2,3,林泽鸿3,4,张健沛1,印桂生1
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001;2.哈尔滨工程大学国家大学科技园,黑龙江哈尔滨150001;3.哈尔滨学院工学院,黑龙江哈尔滨150086;4.哈尔滨工程大学机电工程学院,黑龙江哈尔滨150001)
为了研究微博传播机制,本文提出一种基于溯源的虚假信息传播控制方法,根据微博转发关系和主题相关性得到级联集合,并结合用户关系网和信息级联关系网确定微博信息的真正发起者。通过文本情感分析和信息级联关系迭代计算节点的影响力指数和从众指数,提取微博信息早期重要参与者。综合发起者和早期重要参与者确定信息源头并进行评估。通过删除优质源头节点和全局高影响力节点来控制虚假信息的传播。在新浪微博数据集上通过实验验证了基于所有溯源节点的虚假信息控制策略效果最优。
微博;溯源;虚假信息;影响力指数;早期重要参与者;传播控制
作为一种新的在线社交媒体平台,微博已经成为互联网上民意的集中表达与反映,在很大程度上影响着社会舆论的走向[1]。各种不良话题开始借助于社区媒体这种跨地域、跨国界、开放式的通信方式进行传播。特别是反动、不利于社会安定的言论传播,需要找到话题的源头,锁定谣言的散布者以平息谣言。网络自身的传播特点为虚假信息的产生提供了生存的土壤。而且,由于网络传播的匿名即时,很多网民也在无意之中成为了谣言的传播者。可见,及时有效地对虚假信息进行传播控制时舆情分析与预警的关键。现有的虚假信息控制策略主要有两大类:一种是基于最早时间戳的节点控制策略,一般应用“封号”、“删除”、“禁言”等方式,这种方式没有考虑节点间交互关系,治标不治本;另一种方式是基于影响力的节点控制方法,主要应用PageRank等排序算法找出高影响力节点,这类方法大部分是基于不考虑语义的拓扑关系进行分析,也不适应个人意见鲜明表达的网络媒体。因此,如何结合时间因素、拓扑关系以及语义情感分析来进行虚假信息控制亟待解决。
基于此,提出一种基于溯源的虚假信息传播控制方法,可通过删除优质源头节点和全局高影响力节点快速控制虚假信息传播。
1 虚假信息及传播方式概述
对谣言的系统科学的研究始于二战,Knapp收集整理了1942年间的1000个战时谣言,根据谣言的不同目的和内容进行了分类,这项研究为后来谣言的相关理论研究奠定了重要基础。虚假信息传播有两类主要模型分别是一般传播模型和复杂传播模型[2]。1)一般传播模型是从感官的传染特性将疾病传播的模型进行套用的结果。著名的D-K模型[3]实际上是借助随机过程来分析谣言传播,它把受众按照谣言传播效果分成了3类,并假定其中两类人之间角色转换的概率满足一定数学分布。2)复杂传播模型是按照不同的拓扑结构应用复杂网络结构的一类传播模型。Zanette[4]首先将复杂网络理论应用于谣言传播的研究,在小世界网络上建立谣言传播模型,得出一些包括谣言传播临界值在内的结论。文献[5]认为传统的SIR分析偏向均匀传播网络研究。在线社会网络更适合第二类模型,同时其网络数据庞大,找到虚假信息传播的局域网络是研究的前提条件。
另一方面,针对社会网络信息传播模式的研究很多,相当数量的算法从提取社会网络中一组最有影响力的节点出发,基本思想是把这些节点作为种子从而使得信息能够得到更广泛的传播,其中包括通过博客信息级联的分析进行信息传播预测等[6-7]。微博信息传播的速度远大于博客,且传播模式也不同,如Dabeer等[8]分析了影响微博信息传播的因素,并提出了基于马尔科夫决策框架来度量信息传播效果。Lehmann等[9]跟踪了Twitter网络中的HashTag的扩散过程,发现流行病传播模式起着重要作用,其信息传播范围呈现“核裂变”式的几何级数式扩大。Yang等[10]预测了微博中信息传播的速度、规模和范围。Tsur等[11]结合博文内容与网络拓扑结构,利用线性回归方法预测给定时间内的信息扩散。王佰玲[12]提出针对网络数据流中活跃信息进行话题相关数据采集与分析方法,并对基于数据流的网络舆情热点话题发现、突发事件检测与实时跟踪等应用提供有利的数据资源。
而微博作为一个信息交互性极强的平台受到研究者的青睐,研究微博转发关系形成机制有助于了解微博中信息扩散的机理。如Yang等[13]利用微博的网络关系提出了线性影响力模型,预测信息扩散路径。Macskassy等[14]研究表明微博中大部分用户并不一定转发他们熟知的话题。Pal等[15]以原发微博数、参与会话数和转发数作为主要指标对用户的权威进行评估排序。
对微博平台虚假信息进行传播控制离不开节点影响力分析,影响力度量算法主要是分为基于个体的上下文角色和基于社会网络结构两类。大部分现有的微博影响力分析算法是传统算法的改进算法,如在Twitter数据集中分别利用个体的粉丝数目、被转发数以及被提及数来衡量个体的影响力。除此之外,微博中影响力分析还可以依靠扩散能力衡量影响力,如Bakshy等[16]在Twitter数据集中,根据URL构造传播级联树,用种子节点的扩散范围来衡量其影响力。Steeg等[17]利用转移熵理论刻画用户间的信息流,识别Twitter网络中有影响力的链接等。王永刚等[2]提出了一种社交网络虚假信息传播控制方法Fidic,针对社交网络中虚假信息传播时途经的用户序列,该方法基于PageRank并结合用户传播虚假信息时的指向关系来对用户进行评级。但以上这些方法大多数只是从节点的影响力角度评估,而没有同时评估节点容易被其他节点影响的程度。
2 微博信息级联及影响力分析
2.1 微博中的信息级联
微博是一个流行的社交平台,用户通过微博来随时随地发表自己的心情和观点。根据微博消息传播机制建立用户关系网络和微博转发网络,其中,关注关系对应用户关系网络,而转发关系对应针对特定主题的事件流级联关系网。表1为微博信息级联相关术语和概念中涉及的符号及含义。

表1 符号简表Table 1 Symbol profile
2.2 影响力指数和从众指数
影响力指数是衡量个体影响他人的能力,而从众指数是指容易被他人影响的程度。社会网络中高影响力通常指那些观点和意见总是被采纳的个体,因此在微博中提取关键人物需要考虑情感因素。微博中的转发中主要包括肯定和否定两种情感。一条从a到b的有向边蕴含着节点a相信/赞同(或不相信/不赞同)节点b。其中,赞同含义的边标注为肯定的(+),否则为否定的(-)。研究表明,网络信息传播取决于那些容易被其他人影响者之间的相互影响[9],所以在分析节点影响力的同时也应该量化节点容易被影响的程度。采用文献[18]中情感倾向分析方法容易得到标注情感的有向图G(V,E),其中每一条边按照其表达的情感信息被标注为肯定或否定。信息级联串进行标注后见图1(a)。
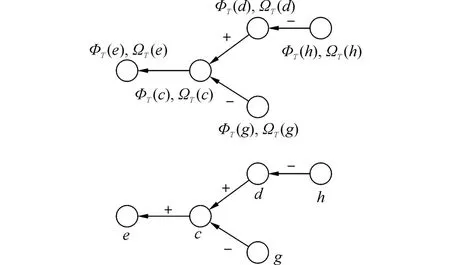
图1 级联信息情感标注及迭代计算Fig.1 Cascade after emotional labeling and index calculation
E+={ce,dc}表示正向情感,E-={hd,gc}为否定情感。因此,社会网络G(V,E)可以由肯定情感子图G+(V,E+)和否定情感子图G-(V,E-)构成。G中节点v的影响力指数Φ(v)和从众指数Ω(v)为
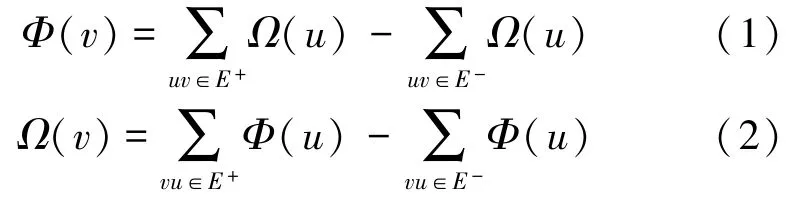
可见,两个互相依赖指数应通过递归循环进行计算。在某主题环境T下,对于任意v ÎV,初始化ΦT(v)=ΩT(v=1),迭代至收敛见图1(b)。
3 微博虚假信息控制方法
3.1 微博信息的溯源
网络信息的发起者和早期参与者决定了信息传递的规模,所以准确锁定信息的真正发起者和早期参与者是舆情分析的重要工作。发起者在微博中指原创博文的用户,但有人习惯复制别人的博文进行直接发布,所以需要结合用户关系网络来找出这部分节点;早期参与者指较早进入级联且影响力较高的重要节点。发起者和早期参与者提取算法的核心思想见算法1。
算法1:溯源算法(KP algorithm)
输入:社会网络G(V,E)
输出:主题T的溯源节点结合KPT,全局高影响力节点GPT
Begin
C←ExtractCascade(G);//级联提取
if级联C是基于语义的 then
ζ←ExtractSubgraph(C);//基于主题的子图提取
else
ζ={C}
对每一个主题T的级联集合GT∈ζ do
ITT←ExtractInitiator(GT) //提取真正发起者ITT
if级联集合GT不是情感标注网络then
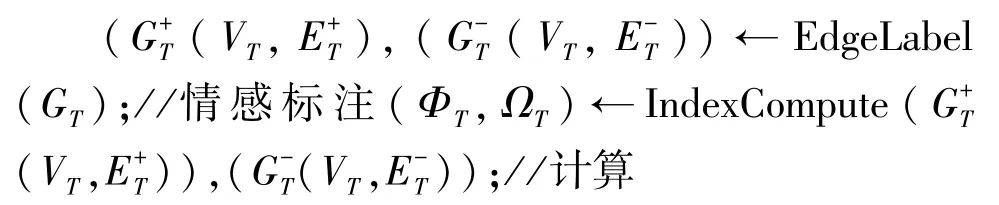
EPT←EarlyParticipants(ΦT,ΩT)//提取早期重要参与者EPT
GPT←GlobalParticipants(ΦT,ΩT)//提取全局重要参与者
KPT←(ITT,EPT)//ITT和EPT取并集
End
首先从特定时间段内的微博数据中提取出转发级联串,按关键词匹配划分为若干组同主题级联信息;其次,对特定主题T下级联集合提取真正的发起者ITT;再次,进行情感标注、影响力指数和从众指数计算,从而提取出早期重要参与者EAT;最后,ITT和EAT合并整合为关键人物KT完成微博信息溯源。具体包括级联提取、基于主题的子图提取、发起者提取、情感标注、指数计算、早期重要参与者提取六个主要部分。下面分别进行说明:
1)级联提取(ExtractCascade)主要按照微博中转发关系进行,E是社会网络图中的边,也可以理解为一个最短的级联。如果两个现有的级联有交集则合并为一个级联,得到一个较大的级联分支。
2)基于主题的子图提取(ExtractSubgraph)主要是把相同主题的子图放到一个集合中。现在有很多潜在语义挖掘算法在社会网络数据中有很好的应用。而微博中主题信息比较明显,应用关键词匹配的方法能够完成基于主题的子图提取,其核心思想是把出现相同关键词的级联放在一个集合中。如主题T的关键词为{k1,k2,k3},则同时含有这3个关键词的所有级联构成基于主题T的级联集合GT。
3)发起者提取算法(EarlyParticipants)找到所有的源节点并提取对应时间戳来提取真正发起者。因为部分用户有直接复制他人博文发布的习惯,所以应该结合用户关系网剔除这部分节点。具体思想是分析所有源节点之间的关系,取消晚于好友发布相同主题信息的节点作为发起者的权利。
4)情感标注(EdgeLabel)是为每一条边加注情感权值的过程。设微博转发边E={uv}表示u转发了v,且∀E Î ci⊂GT,如无评论直接转发则认定为正向情感E+,评论部分采用文献[18]常用情感词表进行匹配计算情感倾向。如果评论中含有多个情感词,则综合情感程度为其平均值,当其大于0.5时记为正向情感E→E+,否则记为否定情感E→E-。
5)指数计算(IndexCompute)为每个节点计算出影响力指数和从众指数(3.2节),对∀v Î ci⊂GT,初始化Φ(v)=Ω(v)=1,迭代计算并归一化处理影响力指数Φ(v)和从众指数Ω(v)。
6)早期重要参与者提取(EarlyParticipants)是找到参与话题时间早且综合影响力高的节点。TT= Earliest{Ti|TiÎci⊂GT}为GT的发布时间,∀v Î ci⊂GT,τ=Φ(v)/Ω(v),则提取早期重要参与者v,应满足参与级联时间Tv较早,指数τ较高。
全局重要参与者GPT的节点集合为综合影响力τ=Φ(v)/Ω(v)在整个时间周期内的TOP-N,主要为控制策略做准备,不属于溯源节点集合。
3.2 微博信息的溯源
微博信息溯源模型是一个通用的模型,只要选定主题的关键词就可以溯源,因此,虚假信息同样适用该模型,如虚假信息“吉林发生严重破坏性地震”的关键词为{破坏性,严重地震,7级,吉林},谣言“哈尔滨下调取暖费”的关键词为{哈尔滨,取暖费,下调,供热}等,通过级联聚合就可以得到对应的GT,进而得到溯源节点集合。这些节点包括了微博中信息的真正发起者和早期重要参与者。主要控制策略为:
(a)删除时间戳较早的发起者ITT/2个;
(b)删除所有的发起者ITT个;
(c)删除综合影响力较高的早期参与者EPT/2个;
(d)删除所有的早期重要参与者EPT个;
(e)删除所有溯源集合内的节点KPT个;
(f)删除PR值最高的节点KPT个;
(g)删除策略(a)和(c)节点及(KPT-ITT/2-EAT/2)全局综合影响力指数τ最大节点,节点总数KPT个。
(h)删除KPT个全局综合影响力τ最大的节点。
其中,选中的节点的信息被其他用户转发所对应的直接链出边将被删除,设某虚假信息共覆盖了N个节点,经过传播控制后所达到的用户数量为NC,则虚假信息传播覆盖率δ=Nc/N×100%。δ越小则控制效果越好。实验部分将比较不同策略对虚假信息的控制效果,包括用PageRank等方法得到和溯源结果相等数量的高影响力节点(策略f),溯源节点结合综合影响力的控制策略(策略g),以及综合影响力控制策略(策略h),比较的指标为信息覆盖率。
4 实验验证及控制策略分析
4.1 基于虚假消息的级联提取
本文数据来自于中国内地知名微博网站——新浪微博,新浪微博自2009年10月正式向公众开放,已经有注册用户近6亿,日均活跃用户近1亿。微博信息的时效性强,大部分完整的话题会在短时间内淡出。本文选取2014年上半年部分数据(涉及博文465 546 132条)进行分析,本文算法主要是应用信息溯源结果进行虚假信息进行传播控制,所以需要删除对信息传播没有贡献的孤立节点。虽然已经删除了对信息传播没有贡献的节点,级联提取结果中仍然有近76%为不大于3的简单级联。算法在数据源中提取出不同的级联并按拓扑结构分为204个。其中最常见的级联为仅一次转发的级联,图2给出了出现频率较高的12种级联形状。
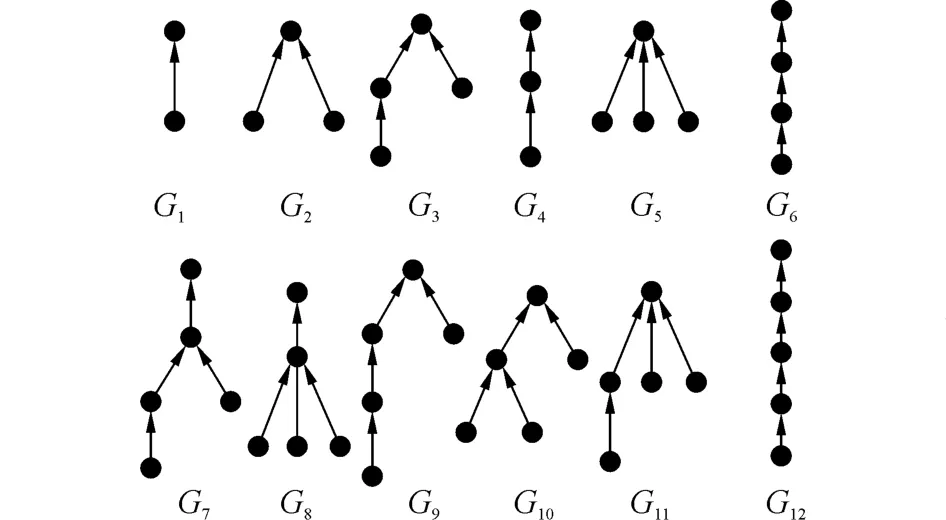
图2 出现频率高的常见级联拓扑结构Fig.2 Basic high frequency cascade topology structure
对所有数据都进行分析会增加控制成本,因此应用关键词匹配的方法能够完成基于主题的子图提取,其核心思想是把出现相同关键词的级联放在一个集合中。主题T的关键词为{k1,k2,k3},则同时含有这该集合中若干个关键词的所有级联构成基于主题T的级联集合GT,如谣言“哈尔滨下调取暖费”的关键词为{哈尔滨,取暖费,下调,供热},则包含其中任何一个关键字的博文构成的级联都放入一个集合中。因为本文关注的是突发事件和虚假信息这类持续时间相对较短,但是舆论影响较大的微博信息的溯源。表2为精简后的微博虚假信息集合。微博条数在本文实验中为级联数目。
4.2 发起者
一个新闻事件虽然具有相同的关键词,但会因为关注角度不同和时间推移有不同的内容侧重。将主题T下级联Ci的源点记为Si,寻找真正发起者的人物是要减少集合S中的元素。主要从两个方面着手:1)把相似度高的级联归为一个新闻版本,只保留其中时间戳最早的源点;2)排除修改后发表的源点,结合用户关系排除晚于好友发布相似度较高信息的源点。由于每条微博最长为140个字且相似的博文大部分字词并不会改变,因此采用简单字词重复比率来衡量文本相似度。
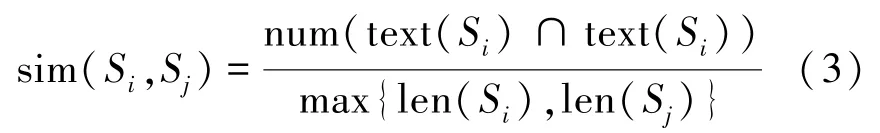
式中:len(Si)表示源点Si博文的字符数,num(text(Si)∩text(Sj))为源点Si与Sj中重复字符总数,sim越大表示相似度越高,直接复制转发的博文相似度为1。实验中sim(Si,Sj)大于阈值0.71则认为级联Ci与Cj为同一博文。表3中给出了10个热点事件按相似度归类后的新闻版本数。
当然,微博信息传播中的一种现象不容忽视,即信息被高影响力节点转发后形成的二次爆发,因此,微博信息溯源仅找到信息发起者还不够。

表2 事件及主要指标Table 2 Events and main index

表3 不同事件级联集合变化情况表Table 3 Cascade set of issues
4.3 早期重要参与者
微博信息传播过程中时间因素很重要,社会网络中每个节点平均新增的边数随时间变化不大,而级联边的产生呈指数下降的[16]。具体而言,早期重要参与者应具有以下特性:1)参与转发级联时间早;2)具有高影响力指数和低从众指数。
4.3.1 综合影响力评估
情感标注采用情感词表匹配法[18],包含30组否定词和30组肯定词,否定词权重在0.5~1,越大表示否定情感越强烈;肯定词的权重在0~0.5,越小表示越肯定。无评论的直接转发行为认定为正向情感E+,评论部分按常用情感词表进行匹配计算情感倾向。如果评论中含有多个情感词,则综合情感程度为其算数平均值,当其大于0.5时记为正向情感E+,否则记为否定情感E-。对∀v Î ci⊂GT,初始化Φ(v)=Ω(v)=1,迭代计算并归一化处理影响力指数Φ(v)和从众指数Ω(v)。为了衡量用户话题中用户的综合影响力定义τ=Φ(v)/Ω(v),图3展示了不同话题中用户τ的分布情况。
4.3.2 参与者提取
微博溯源时间因素尤为重要,早期重要参与者是指较早参与话题的高综合影响力指数τ的用户。定义GT的发布时间为TT=Earliest{Ti|ci⊂GT},T∗= Latest{Ti|ci⊂GT},而∀v Î ci⊂GT参与级联的时间Tv,则Δt=Tv-TT。为了区分出Δt小且τ大的早期重要参与者,因为不同主题事件的规模不同,持续时间各异,采取分级量化的方法进行对比,Δt等级为总时间T∗-TT均匀分为10段,再将τ>2的高影响力节点按参与级联的时间投影到不同的Δt等级中去。如虚假信息1有14%的节点被涉及,图4给出了其投影分布结果。

图3 不同主题综合用户影响力分布Fig.3 Comprehensive influence distribution in various topics
从图4中可以看出,事件的中早期高影响力的用户节点分布较多,这里不排除一些为虚假信息造势而注册的活跃马甲账户。虚假信息1中第一区间用户占比为0.43%,这一较小的数字有利于进行后期虚假信息控制。左侧第一区间为影响力最高且参与时间最早的人,这部分在所有10个虚假信息中最大值为114,即有效分离出了早期重要参与者。
4.4 溯源结果评估与确认
早期参与者中可能包含部分发起者,因此两者应取并集。虚假信息溯源结果见表4,其中“√”表示达到指标,“×”表示不满足该指标。可见,事件源头基本锁定在129个ID以内,达到了挖掘效果。为了对结果的准确性进行评价,需要从以下几个方面进行考量:(a)是否包含了信息的最早发布者;(b)节点之间是否存在好友关系;(c)人工分析源头节点所发微博与事件是否相关;(d)分析节点的微博数、粉丝数属性等活跃程度,分析源头节点是否都是相对较活跃的节点。
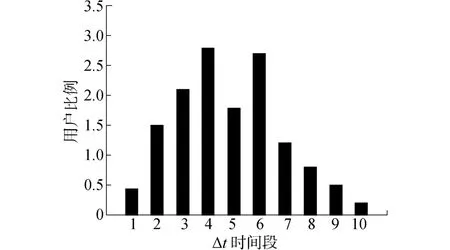
图4 虚假信息1中τ>2的用户节点参与时间分布图Fig.4 The participate time distribution of the τ>2 users
所有的事件都达到了指标(a)溯源得到的节点中都包含了信息的最早发布者。指标(b)分为发起者(b1)和重要参与者(b2)两部分:(b1)针对溯源结果中发起者之间的关系,如果有好友关系的两个节点存在于同一级联树中,那么晚于好友发布同一消息的节点已经被剔除,所以大部分事件的源头节点都是已经不存在好友关系孤立节点。指标(b2)主要衡量早期重要参与者是否与其他节点具有好友关系,而重要节点是通过拓扑结构分析得到的高影响力节点,因此理论上都应该存在好友关系。但事件2和6不满足指标(b2)是由于存在某重要节点,其所在级联的发起者由于晚于好友发布同一消息已经被剔除。指标(c)经人工识别后发现所有保留节点的博文都是与事件相关的,这一点也是由算法特性决定的,因为经关键词锁定主题和转发形成级联后,主题漂移的可能性不大。指标(d)衡量源节点是否都为活跃节点,这里对活跃节点没有具体定义,仅认为被关注数较高并发微博数较大的用户为活跃节点。综上所述,本文算法的溯源结果包含了最早的信息发布者且都相对活跃,同时剔除了好友关系使得源头更准确,并且控制了主题漂移。

表4 发起者和重要参与者统计Table 4 The initiator and important participants
4.5 虚假信息控制效果评估
对于同一虚假信息传播的级联集合,应用不同的控制策略以进行效果比较,如虚假信息1,经过溯源得到发起者59个和早期重要参与者78个,溯源结果集合取两者并集共104个。则具体策略为:
(A)删除时间戳较早的发起者30个;
(B)删除所有的发起者59个;
(C)删除综合影响力较高的早期重要参与者39个;
(D)删除所有的早期重要参与者78个;
(E)删除所有溯源集合内的节点104个;
(F)删除PR值最高的节点104个;
(G)删除策略(A)和(C)的69个节点,全局综合影响力指数τ最大的35个节点,共104个。
(H)删除全局综合影响力指数τ最大的节点104个。
为了对比,设置策略(F)对同一虚假信息的级联集合应用PageRank得到影响力最大的104个节点,溯源结合综合影响力的控制策略(G),以及全局综合影响力策略(策略H)。策略(A)和策略(C)主要为策略(G)提供优质源头节点,可见,优质源头节点主要由溯源节点集合中时间戳较早的发起者和综合影响力较高的早期重要参与者组成。图5展示虚假信息在不同的控制策略下的传播覆盖率。
可见,所有的控制策略都不同程度地降低了虚假信息的覆盖率。10个虚假信息的控制效果都在策略(G)时最佳,其次为策略(E),策略(E)删除了所有溯源得到的节点集合,而策略(G)选择了溯源节点中较优质的一部分,同时,为了更好的控制效果,将综合影响力扩展到信息传播的全过程。为了对比,共选取(KPT-ITT/2-EAT/2)个全局综合影响力指数τ最大的节点,使得策略的删除节点数相等。可见,单纯删除溯源节点的策略(E)对个别虚假信息的控制效果不如策略(F),如虚假信息7和8,这是因为虚假信息的传播态势不同,信息传播过程中晚期高影响力节点多,导致信息二次爆发,此时仅仅删除溯源节点控制力不足。通过对比发现,基于溯源的虚假信息传播控制策略能够在删除少量节点的情况下更好地控制信息传播的规模。而实际虚假信息控制经常是找到发表信息时间戳最早的一个用户并删除,所删除节点仅仅是策略(A)的一个子集,该方法在复杂微博传播机制下不能很好地控制信息规模。

图5 不同策略下虚假信息传播覆盖率Fig.5 False information transmission coverage under different strategies
5 结论
虚假信息的传播一般为人为恶意操作,且针对特定人群,所以传播的速度比一般信息还要快。文章针对虚假信息控制问题展开建模分析得到以下结论:
1)基于溯源的虚假信息传播控制策略能够及时准确地锁定信息的源头;
2)用户节点的综合影响力由影响能力和从众程度共同决定;
3)基于虚假信息的关键节点挖掘与仅考虑拓扑关系的关键节点意义不同。综上所述,本文算法在同等条件下虚假信息控制效果最佳。虚假信息是网络舆情分析与预警的重要对象,虚假信息传播演化规律的研究将进一步揭示网络舆情演化机制,这将是下一步主要研究内容。
[1]丁兆云,贾焰,周斌.微博数据挖掘研究综述[J].计算机研究与发展,2014,51(4):691-706.DING Zhaoyun,JIA Yan,ZHOU Bin.Survey of data mining for Weibos[J].Journal of computer research and development,2014,51(4):691-706.
[2]王永刚,蔡飞志,LUA E K,等.一种社交网络虚假信息传播控制方法[J].计算机研究与发展,2012,49(S1):131-137.WANG Yonggang,CAI Feizhi,LUA E K,et al.A diffusion control method of fake information in social networks[J].Journal of computer research and development,2012,49(S1):131-137.
[3]DALEY D J,KENDAL D G.Stochastic rumours[J].IMA journal of applied mathematics,1965,1(1):42-55.
[4]ZANETTE D H.Dynamics of rumor propagation on small-world networks[J].Physical review E,2002,65(4 Pt 1):041908.
[5]ZHOU Jie,LIU Zonghua,LI Baowen.Influence of network structure on rumor propagation[J].Physics letters a,2007,368(6):458-463.
[6]LESKOVEC J,MCGLOHON M,FALOUTSOS C,et al.Patterns of cascading behavior in large blog graphs[C]//Proceedings of the 2007 SIAM International Conference on Data Mining.Minneapolis,Minnesota,USA:SIAM,2007,7:551-556.
[7]LI Hui,BHOWMICK S S,SUN Aixin,et al.Affinity-driven blog cascade analysis and prediction[J].Data mining and knowledge discovery,2014,28(2):442-474.
[8]DABEER O,MEHENDALE P,KARNIK A,et al.Timing tweets to increase effectiveness of information campaigns[C]//Proceedings of the 5th ICWSM.Barcelona,Spain: AAAI,2011:105-112.
[9]LEHMANN J,GONÇALVES B,RAMASCO J J,et al.Dynamical classes of collective attention in twitter[C]//Proceedings of the 21st International Conference on World Wide Web.Lyon,France:ACM,2012:251-260.
[10]YANG J,COUNTS S.Predicting the speed,scale,and range of information diffusion in twitter[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media.Washington:AAAI,2010,10:355-358.
[11]TSUR O,RAPPOPORT A.What's in a hashtag?:content based prediction of the spread of ideas in Weiboging communities[C]//Proceedings of the 5th ACM International Conference on Web Search and Data Mining.Seattle,Washington,USA:ACM,2012:643-652.
[12]王佰玲,曲芸,张永铮,等.基于数据流的网页内容分析技术研究[J].电子学报,2013,41(4):751-756.WANG Bailing,QU Yun,ZHANG Yongzheng,et al.Research on network-traffic based web traffic computing technology[J].Acta electronica sinica,2013,41(4):751-756.
[13]YANG J,LESKOVEC J.Modeling information diffusion in implicit networks[C]//Proceedings of the 10th International Conference on Data Mining.Sydney,Australia:IEEE,2010:599-608.
[14]MACSKASSY S A,MICHELSON M.Why do people retweet?anti-homophily wins the day![C]//Proceedings of the 5th International AAAI Conference on Weblogs and Social Media.California:The AAAI Press,2011:209-216.
[15]PAL A,COUNTS S.Identifying topical authorities in Weibos[C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining.Hong Kong,China: ACM,2011:45-54.
[16]BAKSHY E,HOFMAN J M,MASON W A,et al.Everyone's an influencer:quantifying influence on twitter[C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining.Hong Kong,China:ACM,2011:65-74.
[17]VER STEEG G,GALSTYAN A.Information transfer in social media[C]//Proceedings of the 21st International Conference on World Wide Web.Lyon,France:ACM,2012:509-518.
[18]ZHOU Xueyan,YANG Jing.A BBS opinion leader mining algorithm based on topic model[J].Journal of computational information systems,2014,10(6):2571-2578.
False information spread control method based on source tracing
YANG Jing1,ZHOU Xueyan1,2,3,LIN Zehong3,4,ZHANG Jianpei1,YIN Guisheng1
(1.College of Computer Science and Technology,Harbin Engineering University,Harbin 150001,China;2.The National University Science Park,Harbin Engineering University,Harbin 150001,China;3.College of Engineering,Harbin University,Harbin 150086,China;4.College of Mechanical and Electrical Engineering,Harbin Engineering University,Harbin 150001,China)
To study the Weibo transmission mechanism,this paper provides a false information spread control method based on source tracing.The cascade sets were built on the basis of the retweeting of a Weibo and its topical relevance,and real initiators were identified by the user relationship and information cascade networks.The influence and conformity indices of every node were then iteratively calculated according to text sentiment analysis,and the information cascades and important early participants were extracted.The real initiators and early participants were combined to ascertain the information source and then evaluated by an experiment.The source tracing nodes and the global high influence nodes were deleted to control the spread of false information.Experimental results verify that the proposed false information control strategy for all source tracing nodes has an optimal effect in a real Sina Weibo dataset.
Weibo;source tracing;false information;influence index;early participants;spread control
10.11990/jheu.201511076
http://www.cnki.net/kcms/detail/23.1390.u.20160928.0936.022.html
TP393
A
1006-7043(2016)12-1691-07
杨静,周雪妍,林泽鸿,等.基于溯源的虚假信息传播控制方法[J].哈尔滨工程大学学报,2016,37(12):1691-1697.
2015-11-30.
2016-09-28.
国家自然科学基金项目(61672179,61370083,61402126);高等学校博士点专项科研基金项目(20122304110012);黑龙江省社科研究规划项目(16XWB01、16TQD03);黑龙江省艺术科学规划课题(2016C030);黑龙江省青年科学基金项目(QC2016083);黑龙江省博士后基金项目(LBH-Z14071);哈尔滨学院青年博士科研启动基金项目(HUDF2016207).
杨静(1962-),女,教授,博士生导师;
周雪妍(1981-),女,副教授.
周雪妍,E-mail:zhouxueyan_zxy@163.com.
YANG Jing,ZHOU Xueyan,LIN Zehong,et al.False information spread control method based on source tracing[J].Journal of Harbin Engineering University,2016,37(12):1691-1697.
猜你喜欢
核安全(2022年3期)2022-06-29
体育科技文献通报(2022年3期)2022-05-23
管理学报(2022年5期)2022-05-12
华人时刊(2022年21期)2022-02-15
—— “T”级联
同位素(2019年1期)2019-03-14
现代营销(创富信息版)(2018年10期)2018-10-12
环球时报(2016-09-01)2016-09-01
系统工程与电子技术(2016年2期)2016-04-16
华人时刊(2016年13期)2016-04-05
原子能科学技术(2015年12期)2015-07-07
