
一种基于可达标识的过程模型修复方法
2017-01-13 05:38:06祁宏达杜玉越
山东科技大学学报(自然科学版) 2017年1期
祁宏达,杜玉越,刘 伟
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
一种基于可达标识的过程模型修复方法
祁宏达,杜玉越,刘 伟
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
模型修复是一种基于模型增强的过程挖掘的应用技术,现有的模型修复方法大多是以拟合度为主要指标,对于其他维度,诸如精确度,考虑较少。基于此,本文试图综合考虑多个维度,来对过程模型进行修复。校准能够对事件日志进行重演,发现各类偏差,即日志动作和模型动作,却无法确定偏差在Petri网中出现的位置。因此,基于Petri网的可达标识,提出了扩展校准的概念,这样便能确定偏差的位置。进一步地,针对扩展校准中出现的日志动作提出了RMR(Reachable Marking Repaining)算法进行修复。最后,通过实验证明修复算法在拟合度和精确度上均有较好的表现。
校准;模型修复;扩展校准;修复算法
过程挖掘是从实际执行集合中提取出结构化过程描述的方法[1]。过程挖掘技术一共有三类应用:过程发现(process discovery)、一致性检测(conformance checking)和过程增强(process enhancement)。
评价过程模型 “好坏”的标准有拟合度(fitness)、精确度(precision)、简化度(simplicity)和泛化度(generalization)[2],其中拟合度是评价过程模型最为重要的指标。模型的拟合度意味着日志中的迹(trace)在模型中重演的能力。高精确度代表着模型只会重演事件日志中的迹。
在一致性检测和过程增强技术方面,目前最大的挑战是在过程模型上进行重演,发现事件日志中观察到的行为的最优路径。文献[3]提出了基于事件日志的校准方法,为模型修复奠定了基础。
作为一种新的过程挖掘的应用技术,模型修复技术属于过程增强这一范畴[4]。模型修复以事件日志和过程模型作为输入,如果存在事件日志中的迹不能够在过程模型中重演,则需要对过程模型进行修改。修改后的模型要尽量与原始模式相似,即不改变原始模型的基本结构。
目前,已有一些运用编辑距离矩阵(edit distance matrices)来发现改进模型的[5-7]方法,虽与修复模型的目标一致,但并不属于模型修复技术。基于模型和日志的偏差来进行模型修复的方法并不多,文献[4]提出了一种模型修复方法,利用校准发现模型和日志的偏差,进而对模型进行修复。但是,这种方法主要关注拟合度这一维度,对于其他维度(如精确度)未考虑。在这一背景下,本文综合考虑多个维度指标来修复过程模型。
1 基本概念
这一节中对事件日志、Petri网[8-9]和校准[3]等基本概念进行了描述。首先介绍迹和事件日志这一概念。
定义1(迹,事件日志) 设A∈A是活动集,迹σ∈A*是活动队列。而事件日志L则是迹的多重集合,即L∈IB(A*)。
Petri网是一个包含库所(place)和变迁(transition)的有向二分图。
定义2(Petri网[8-9]) 四元组PN=(P,T;F,M)称为一个Petri网PN,当且仅当
1)N=(P,T;F)为一个网,其中P是一个有限库所集,T是一个有限变迁集,F⊂(P×T)∪(T×P)是一个有限弧集;
2)M:P→N称为网PN的一个标识,其中mi为初始标识,mf为终止标识;
3)PN具有下面的变迁发生规则:
①对于变迁t∈T,如果∀p∈·t:M(p)≥1,则称变迁t在标识M下使能,记为M[t>;
②若M[t>,则在标识M下,变迁t可以发生,从标识M引发变迁t得到一个新的标识M′,记为M[t>M′,且对∀p∈P,
在定义2中,·t表示t的输入集,t·表示t的输出集。
以一个过程模型作为参考,活动在执行过程没有偏离模型,意味着在当前状态下活动是被模型所允许的。也就是说,给定一个无任何偏差的事件日志,活动是完全按照模型的顺序来执行的。文献[3]提出了校准这一概念,用以比较事件日志中的活动与模型上的活动。对于校准来说,每一个实例都要对应一个校准。
定义3(校准[3]) 设A∈A,σ∈A*,PN=(P,T;F,M)。二元组(a,t)∈A≫XT≫{(≫,≫)}是一个移动。校准γ是迹σ和模型PN之间的移动队列(a,t)*,且满足:
1) π1(γ)↓A=σ,即校准中所有的第一元素对应一条迹;

Γσ,PN是迹σ和模型PN之间所有校准的集合。其中π1(γ)↓A代表校准中第一个元素,π2(γ)↓T代表校准中第二个元素。
对于一个移动(a,t),可能是一个:①同步动作iffa≠≫ andt≠≫,② 模型动作iffa=≫ andt≠≫,③日志动作iffa≠≫ andt=≫。
给定一个迹和一个Petri网,可能会存在多个校准。在实际过程中,偏差的可能性会随着活动的不同和人为制定的不同而产生不同的影响。为了能够产生最有可能的校准,需要对每一个移动赋予一个可能性代价函数lc(a,t)。在本文中,对于日志动作和模型动作,lc(a,t) = 1,对于同步动作,lc(a,t) = 0。根据制定的可能性代价函数,能够找到可能性代价值最低的校准,这种校准被称为最优校准。

校准和最优校准能够将事件日志和过程模型关联起来,并且最优校准能够处理过程模型中的不可见变迁、复杂的控制流和循环等。当偏差出现时,校准能够展示出偏差所在的位置,并且为进一步的研究提供诊断信息。
2 扩展校准
过程模型修复属于过程增强的具体应用,其思想是利用实际过程中产生的事件日志扩展和改进一个已经存在的过程模型。校准能够对事件日志进行重演,发现各类偏差,即日志动作和模型动作,却无法确定偏差在Petri网中出现的位置。因此,本文引入了可达标识对校准进行扩展,来确定偏差出现的位置,其定义如下。
定义5(扩展校准) 设A∈A,σ∈A*,PN=(P,T;F,M),γ是一个迹σ和模型PN之间的校准。β∈(γ×M)*是迹σ和模型PN之间的扩展校准,当且仅当:
1)γ是一个迹σ和模型PN之间的校准;
2)mi[π2(π1(β)↓γ) ↓T>mf,即扩展移动队列在模型中的移动发生后,最终会到达终止标识;
Bσ,PN是迹σ和模型PN之间所有扩展校准的集合。需要指出的是,当前动作的可达标识与前一动作的可达标识相同,为iffπ2(π1(β)↓γ)↓T= ≫。
以图1所示的Petri网PN1为例,假设存在一条迹σ1=
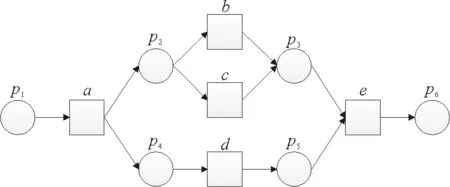
图1 Petri网PN1

图2 迹σ1的扩展校准
对于(d,d,m2),可达标识m2:m2(p2) =m2(p5)=1,m2(p1)=m2(p3)=m2(p4)=m2(p6)=0。
类似于最优校准,最优扩展校准定义如下:
定义6(最优扩展校准) 设A∈A,σ∈A*,PN=(P,T;F,M),γ是一个迹σ和模型PN之间的校准。扩展校准β∈(γ×M)*是一个最优扩展校准当且仅当γ是一个最优校准。
对于图2中的两个扩展校准β1和β2,可能性代价值lc(β1)=2,lc(β2)=2,显然,β1,β2均是是迹σ1的最优扩展校准。
3 偏差修复方法
实际上,现有过程模型往往是通过过程挖掘算法或者手动建立的。存在着这样一种情形:一开始的事件日志与过程模型完全符合,但随着一些原过程模型中无法重演的迹出现在事件日志中,导致原模型不再符合真实情况。因此,需要对过程模型进行修复。
对于最优扩展校准来说,存在两类基本的偏差类型:日志动作和模型动作。本文主要针对日志动作修复方法进行改进。日志动作的出现,说明事件日志中出现了过程模型中不存在的活动。Fahland的方法利用校准发现模型和日志之间的偏差,收集出不拟合的子日志,利用现有挖掘算法对不拟合的子日志进行挖掘,将挖掘出的子过程作为自环,添加到原模型的合适位置。自环的出现,使得这一子过程可以多次重复发生,即模型中允许无限序列的出现。然而在实际过程中,这种情况基本不会出现,导致了修复后过程模型的精确度不高。
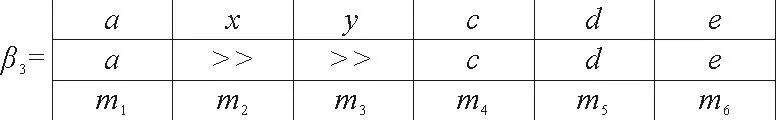
图3 迹σ2的扩展校准

图4 Fahland的方法修复后的模型
以Petri网PN1为例,假设存在变迁σ2=〈a,x,y,c,d,e〉,最优扩展校准如图3所示。
β3存在两个连续的日志动作(x,≫,m2)和(y,≫,m3)。其中两个动作可达标识完全相同,即m2=m3且m3(p2) =m3(p4) = 1。根据其可达标识,Petri网PN1在库所p2和p4处有托肯。Fahland的方法对于添加子环的位置并未做出约束,位置可以是p2和p4任意一个,在此选取p2位置,修复后的模型如图4所示。
由于在p2处添加了一个自环,修复后的模型允许这一自环无限重复发生,即存在一个无限序列σ3=〈a,x,y,…〉。在实际的事件日志中,σ3显然不会出现。这就导致模型允许的可能的发生序列多于实际的事件日志,因而模型的精确度不高。
为了避免自环的出现,本文提出了RMR修复方法,将这一子过程插入到原模型中。由于是插入到原模型中,导致这一子过程必然会发生,而实际的日志中这一子过程可以不发生。因此,需要对子过程添加一个不可见变迁,分别与初始库所和终止库所相连。同样以σ2为例,选取p2位置,修复后的模型如图5所示。

图5 RMR方法修复后的模型
算法1实现了对指定库所处的日志动作的收集。其思想是依次对每一条扩展校准进行遍历,当发现指定库所是日志动作时,进行保存。遍历完所有的最优扩展校准后将会得到一个变迁序列集合。
算法1指定库所处日志动作收集
输出:变迁序列集合TS
步骤:
2. {While(j<βi,length)do
3. {if(mj(p)=1 and π2(π1(βi[j]))↓γ↓T=≫)then
4.TI←TI∪π1(π1(βi[j]))↓γ↓A;}
5. if((TI≠Ø)then
6.TS←TS∪TI;
7.TI←Ø;}
8.returnTS;
在收集到所有指定库所处的日志动作后,可以通过现有挖掘算法来挖掘过程模型,之后将这一子过程添加到指定的库所处。目前,国内外的很多学者都致力于研究过程挖掘算法。比如,基于活动顺序关系产生的α算法[10]以及其衍生算法[11-12],基于语义技术提出的区域挖掘[13]和ILP挖掘[14]等等。本文所使用的过程挖掘算法是归纳挖掘[15]。算法2主要思想是通过挖掘算法挖掘出变迁序列集合对应的子过程,这一子过程需要添加一个不可见变迁,并将这一子过程插入到指定的库所处。
算法2利用子日志修复过程模型
输入:原过程模型PN,子日志SL,指定库所p
输出:修复后的过程模型PN′
步骤:
1.PN1←InductiveMiner(SL)
2.T1←T1∪{τ}
3.F1←F1({(m1i,τ),(τ,m1f)}
4.PN′←PN
5. for ∀t∈·pdo
6. {F′ ←F′∪{(t,m1i)}{(t,p)};
7. for ∀t∈p·do
8. {F′←F′∪{(m1f,t)}{(p/t)};
9.P′←P′ {p}
10.P′←P′∪P1,T′←T′∪T1,F′←F′∪F1
11. returnPN′
通过这两个算法,能够收集指定库所处出现的日志动作,实现在指定库所处对过程模型进行修复。
4 实验
本文中所有的仿真实验均在ProM 6.0中进行,所有的数据均来自于青岛某医院胸外科。
4.1 修复过程模型
以某医院胸外科的业务流程为例,通过在原有事件日志的基础上进行挖掘建模,得到图6的Petri网模型。主要活动过程描述如下:首先,病人通过两种方式预约:分诊台预约(reserve at triage station)和电话预约(reserve by phone)。随后,进行预约登记(booking)和取得预约号(get reservation number)。病人也可以不进行预约直接就诊(consult without reservation),但需要进行挂号(registration)。对于预约的病人和挂号的病人,医院进行排号(arranging)和顺序叫号(call number by order),病人依照顺序找医生问诊(inquiry)。医生通过问诊来确定是否进行影像检查和临床检验。影像检查一共有三种类型:普通CT(common ct)、PET-CT和胸部增强(chest enhanced scan)。临床检验有4种类型:血沉(ESR)、生化全套(Biochemical full set)、血气分析(blood gas analysis)和血常规(blood routine)。之后,医生根据检查结果进行诊断(diagnosis)。若病人病情无碍,则可离开医院(leave)。若病人病情严重,则需要住院治疗(hospitalization)。
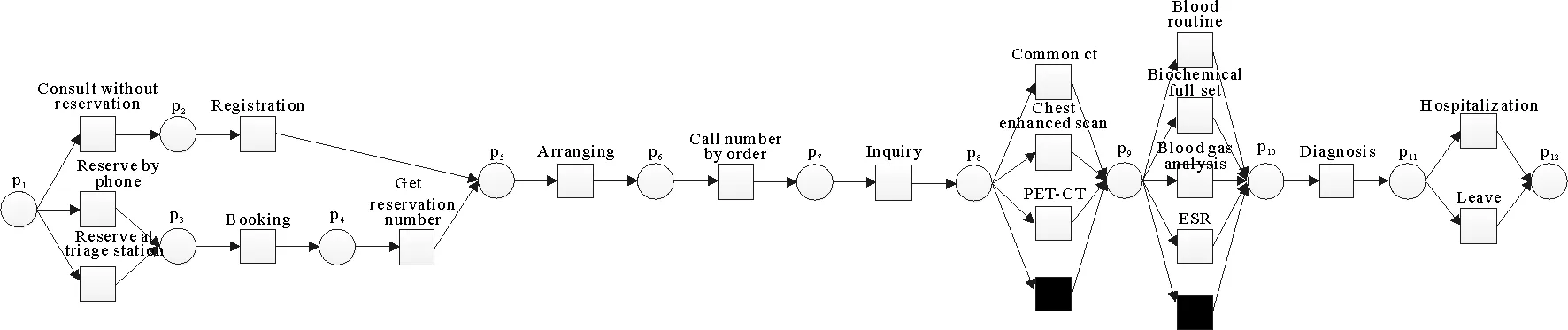
图6 某医院胸外科的Petri网模型
选取了3组事件日志用以修复过程模型。表1展示了3组事件日志中迹的总数与长度、事件总数、活动总数和迹中出现的偏差总数。
对不同的库所,按照算法1进行变迁序列集合的收集,得到表2。
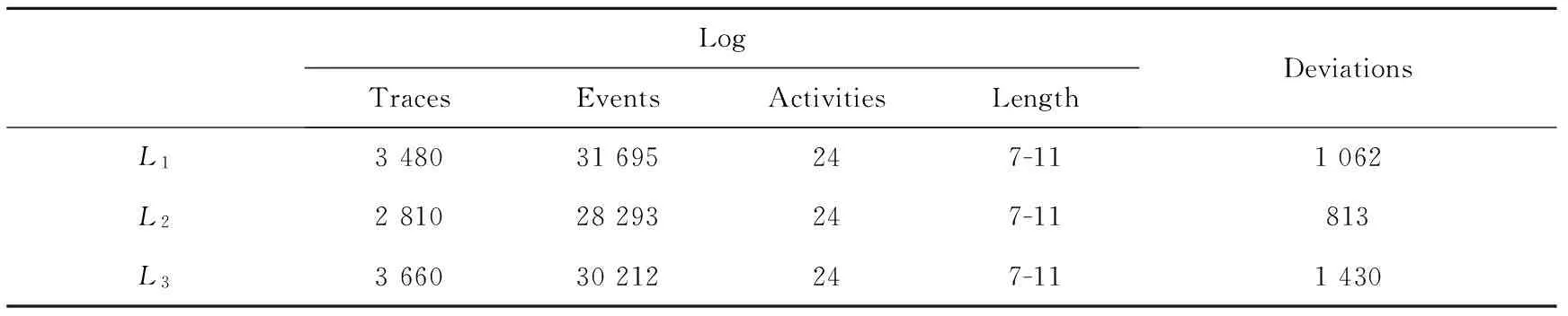
表1 3组事件日志

表2 各个位置处的变迁序列集合
按Fahland的方法对过程模型进行修复,修复后的模型如图7所示。本文中将这一子过程进行修改,插入到原模型中,修复后的模型如图8所示。

图7 Fahland的方法修复后的模型

图8 RMR方法修复后的模型
4.2 模型评估
下面对修复后的过程模型进行评价。针对各个一致性指标,本文分别采用了不同数量级的事件日志,对RMR方法和Fahland方法进行了比较。图9和图10分别展示了不同数量级下拟合度和精确度的变化。
通过图9发现,在不同的数量级下,两种方法均有较高的拟合度,且两种方法并未出现随着数据增加而波动的情形。这说明事件日志中的迹大部分都能够在两个模型中重演。
通过图10发现,对于精确度来说,本文的RMR方法能够保持一个较高的数值,而Fahland方法的精确度较低。对于不同数量级的事件日志,这一情形相似。

图9 拟合度的变化

图10 精确度的变化
5 总结
本文首先在校准中加入了Petri网的可达标识,提出了扩展校准的概念,并通过扩展校准来识别可能出现的各类扩展动作。最优扩展校准则能为各类偏差的修复提供支持。通过对日志动作进行分析,本文提出RMR算法对这类偏差进行修复。通过某医院胸外科的事件日志对这一方法进行仿真实验发现,这一方法相较于Fahland的方法,在拟合度和精确度方面均有着较好的表现。本文仅仅是对基本偏差进行了修复,对于一些高级偏差并未给出相应的修复方法,这也是下一步研究的重点。
[1]曾庆田.流程挖掘的研究现状和问题综述[J].系统仿真学报,2007,19(1):276-278.
[2]VAN DERr AALST W M P.Process Mining:Discovery,Conformance and Enhancement of Business Processes[M].Berlin:Springer-Verlag,2011:9-25.
[3]ADRIANSYAH A,MUNOZ-GAMA J,CARMONA J,et al.Alignment based precision checking[C]//Business Process Management Workshops.Berlin Heidelberg:Springer,2013:137-149.
[4]FAHLAND Dirk,W M P VAN DER AALST. Model repair - aligning process models to reality[J].Information Systems,2015,47:220-243.
[5]GAMBINI M,LA ROSA M,MIGLIORINI S,et al.Automated error correction of business process models[C]//International Conference on Business Process Management.Berlin Heidelberg:Springer,2011:148-165.
[6]LI C,REICHERT M,WOMBACHER A.Discovering reference models by mining process variants using a heuristic approach[C]//International Conference on Business Process Management.Berlin Heidelberg:Springer,2009:344-362.
[7]LOHMANN N.Correcting deadlocking service choreographies using a simulation-based graph edit distance[C]//International Conference on Business Process Management.Berlin Heidelberg:Springer,2008:132-147.
[8]YUYUE D,LIANG Q, MENGCHU.Analysis and application of logical Petri nets to E-commerce systems[J].IEEE Transactions on Systems,Man,and Cybernetics Systems,2014,44(4):468-481.
[9]DU Y Y,LIANG Q,ZHOU M C.A vector matching method for analyzing logic Petri nets[J].Enterprise Information Systems,Sep.2011,5(4):449-468.
[10]VAN DER AALST W,WEIJTERS T,MARUSTER L.Workflow mining:Discovering process models from event logs[J].IEEE Transactions on Knowledge and Data Engineering,2004,16(9):1128-1142.
[11]WEN L,WANG J,SUN J.Mining invisible tasks from event logs[M]//Advances in Data and Web Management.Berlin Heidelberg:Springer,2007:358-365.
[12]WEN L,VAN DER AALST W M P,WANG J,et al.Mining process models with non-free-choice constructs[J].Data Mining and Knowledge Discovery,2007,15(2):145-180.
[13]BERGENTHUM R,DESEL J,MAUSER S.Synthesis of Petri nets from term based representations of infinite partial languages[J].Fundamenta Informaticae,2009,95(1):187-217.
[14]VAN DERWERF J M E M,VAN DONGEN B F,HURKENS C A J,et al.Process discovery using integer linear programming[J].Fundamenta Informaticae,2009,94(3/4):387-412.
[15]LEEMANS S J J,FAHLAND D,VAN DER AALST W M P.Discovering block-structured process models from event logs-a constructive approach[C]//International Conference on Applications and Theory of Petri Nets and Concurrency.Berlin Heidelberg:Springer,2013:311-329.
(责任编辑:傅 游)
Process Model Repairing Method Based on Reachable Markings
QI Hongda,DU Yuyue,LIU Wei
(College of Information Science and Engineering,Shandong University of Science and Technology,Qingdao,Shandong 266590,China)
Model repairing is a new application of process mining based on model enhancement. The existing methods of model repairing concentrate on degree of fitting,and give little consideration to other dimensions such as precision. In this background,this paper attempts to repair the process model by considering the multiple dimensions. Although alignments can replay event logs in process models and find deviations,i.e.,move on log and move on model,they are unable to confirm the locations of deviations in Petri nets. Thus,extended alignments were proposed based on reachable markings in Petri nets to confirm the locations of deviations. A new algorithm were proposed for repairing the move on log in the extended alignments. Finally,experiments were conducted to prove the better performance of the proposed method in fitting,precision and time.
alignment; model repair; Petri Net; repairing algorithm
2016-06-15
国家自然科学基金项目(61170078,61472228); 泰山学者建设工程项目;山东省自然科学基金项目(ZR2014FM0 09);山东省优秀中青年科学家科研奖励基金项目(BS2015DX010)
祁宏达(1993—),男,山东临沂人,硕士研究生,主要从事过程挖掘和Petri网方面的研究. 杜玉越(1960—),男,山东聊城人,教授,博士生导师,CCF高级会员,主要从事软件工程、形式化技术和Petri网方面的研究.E-mail:yydu001@163.com 刘 伟(1977—),男,山东青岛人,副教授,博士,CCF会员,主要从事Petri网、工作流、Web服务的研究.
TP311
A
1672-3767(2017)01-0118-07
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
学生天地(2020年6期)2020-08-25 09:10:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:36
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
系统医学(2016年8期)2016-02-20 02:55:08
少儿科学周刊·少年版(2015年4期)2015-07-07 20:56:37
