
面向有效错误定位的偶然正确性识别方法
2017-01-10 07:17曹鹤玲姜淑娟王兴亚钱俊彦
电子学报 2016年12期
曹鹤玲,姜淑娟,王兴亚,薛 猛,钱俊彦
(1.中国矿业大学计算机科学与技术学院,江苏徐州 221116; 2.河南工业大学信息科学与工程学院,河南郑州 450001;3.桂林电子科技大学广西可信软件重点实验室,广西桂林 541004)
面向有效错误定位的偶然正确性识别方法
曹鹤玲1,2,3,姜淑娟1,王兴亚1,薛 猛1,钱俊彦3
(1.中国矿业大学计算机科学与技术学院,江苏徐州 221116; 2.河南工业大学信息科学与工程学院,河南郑州 450001;3.桂林电子科技大学广西可信软件重点实验室,广西桂林 541004)
错误定位是软件调试中耗时费力的活动之一.针对偶然正确性影响错误定位效率的问题,提出面向错误定位的偶然正确性识别方法.该方法首先识别偶然正确性元素;然后,挑选“偶然正确性特征元素”,使用该特征元素约简程序执行轨迹;在此基础上,建立基于模糊c均值聚类的偶然正确性识别模型,将其结果应用于错误定位.为验证该方法的有效性,基于3组测试程序开展偶然正确性识别,并将其结果应用于Tarantula等4种错误定位方法.实验结果表明,与基于k-means聚类的偶然正确性识别方法相比,该方法在偶然正确性识别方面具有较低的误报率和漏报率,并且更能提高错误定位的效率.
软件调试;错误定位;偶然正确性;聚类分析
1 引言
基于覆盖信息的错误定位方法深受工业界和学术界广泛关注.偶然正确性指软件中存在缺陷但是仍然通过测试的现象,它通常对基于覆盖信息的错误定位方法的效率产生负面的影响.并且,Hierons和Masri等人[1,2]研究了偶然正确性在软件系统中存在的普遍性.Masri等人[3]研究表明程序大部分程序依赖不能传递任何可度量的信息,这意味着很多感染的程序状态不能传播到输出,从而导致偶然正确性的发生.
针对偶然性正确问题,Wang等人[4]假设调试人员能预先知道程序缺陷类型,对错误触发前后的控制流和数据流信息与特定模式匹配,提纯代码覆盖信息,从而移除偶然正确性对错误定位效率的不利影响.Bandyopadhyay[5]根据成功测试用例和失败测试用例的相似度来识别偶然正确性,并赋予偶然正确性测试用例较低的权重,进而根据测试用例的权重而不是测试用例数量来计算程序语句的怀疑度,减少偶然正确性对错误定位效率的影响.陈振宇等人[6]对程序覆盖信息进行聚类分析,将和失败测试用例在同一簇中的成功测试用例视为可能的偶然正确性测试用例,通过移除偶然正确性测试用例来减少其影响.上述研究可以显著提高错误定位的效率,这促使我们去研究更有效率的偶然正确性识别方法.
文献[7]采用k-means聚类分析来识别偶然正确性测试用例,而k-means聚类属于硬分类方法,每个程序执行轨迹信息只能属于所有类别中的某一类,非此即彼.这样带来的问题是:所有程序执行轨迹信息对计算聚类中心贡献度相同.而模糊理论允许数据对象属于任何一类(簇),不同的是它们属于某类(簇)的可能性大小不同.为此,我们引入模糊c均值聚类(Fuzzy C-Means,FCM)来识别偶然正确性测试用例.将去除偶然正确性测试用例后的测试用例集应用于错误定位,则可以提高错误定位方法的效率.
本文贡献在于:
(1)提出了偶然正确性特征元素挑选策略,使用该特征元素对程序执行轨迹信息进行维度约简.
(2)提出面向错误定位的偶然正确性识别方法,该方法使用基于Fuzzyc-means聚类来识别偶然正确性测试用例,从而提高错误定位效率.
2 预备知识
2.1 偶然正确性
定义1 偶然正确性元素cce[7].给定一个程序元素e,P(TF,e)为失败测试用例TF执行e的概率,P(TP,e)为成功测试用例TP执行e的概率,e出现在所有失败测试中,即P(TF,e)=1,而出现在成功测试中的概率为0 cce={e|P(TF,e)=1∧0 (1) 定义2 偶然正确性特征元素fcce.使用某怀疑度计算式计算偶然正确性元素的怀疑度,并对其按怀疑度从大到小排序得到序列rank(cce),取序列的前θ(0<θ<1)部分为偶然正确性特征元素. fcce={e|e∈cce∧θ*rank(cce)} (2) 定义3 偶然正确性测试用例TCC[7].一个测试用例T执行了偶然正确性元素cce,而没有导致程序执行结果失败,则该测试用例为偶然正确性测试用例TCC. 定义4 偶然正确性(Coincidental Correctness,CC)[7].指的是程序执行了缺陷语句,而缺陷语句的错误状态并没有传播到程序输出结果,而使程序执行成功或没有抛出异常. 下面以函数foo()为例说明偶然正确性存在.函数foo()中的错误在语句s5,正确语句为:ret=x+y.我们设计了以下6个测试用例:t1(6,3,9),t2(2,4,6),t3(4,0,3),t4(5,2,0),t5(5,4,2)和t6(5,0,2)来测试程序.获取6个测试用例执行的覆盖信息及执行结果如表1所示,其中,“·”和“∘”分别表示语句被覆盖和未被覆盖,T和F分别表示程序执行成功和失败.由定义4可知,测试用例t3和t6执行了错误语句s5而程序没有报错,则说明在程序的执行过程中存在偶然正确性.根据定义3可知,测试用例t3、t6为偶然正确性测试用例. 表1 偶然正确性示例 2.2 模糊c均值聚类 软件错误定位场景中的聚类分析从数学模型角度刻画如下:X=(x1,x2,…,xj,…,xn)表示聚类分析的数据对象(程序执行轨迹信息),即测试用例(t1,t2,…,tj,…,tn)执行程序的轨迹信息,其中xj表示第tj个测试用例的执行轨迹信息.对给定数据对象X进行聚类分析就是将其划分成c簇,对于识别偶然性正确测试用例来说就是将成功测试用例集TP划分成偶然正确性测试用例集和真正成功测试用例集.我们采用欧几里德距离dij如式(3)所示,来度量两个程序执行轨迹的相似度. (3) FCM聚类就是通过找到使用的最佳组对(U,V)来求解目标函数J(U,V)的过程,从而将聚类问题转换成一个带约束的非线性规划问题,通过不断迭代求解得到数据集的最优划分,其中,U表示隶属度矩阵,V表示聚类中心点.FCM聚类将数据对象X分为c个模糊簇,并求每簇的聚类中心点vi,i=1,2,…,c,使得目标函数J(U,V)达到最小值.目标函数定义如下: J(U,V) =J(U,v1,v2,…,vc;X) (4) 且满足下列等式: (5) 对于所有输入的参数求导数,使得J(U,V)达到最小值且满足等式(5)的必要条件为式(6)和(7).其中,式(6)是最佳聚类中心点,式(7)是最佳隶属度函数. (6) (7) 3.1 方法概述 针对偶然正确性影响错误定位效率的问题,提出面向有效错误定位的偶然正确性识别方法,并建立基于模糊c均值聚类的偶然正确性测试用例识别模型CC-FCM(cleansing Coincidental Correctness test cases based on Fuzzy C-Means)如图1所示.该模型的目标是识别测试用例集中的偶然正确性测试用例,移除后应用于错误定位,能提高其效率. 该模型主要步骤如下: (1)获取执行轨迹信息.通过插桩程序获取程序执行轨迹信息,根据测试谕言将其分为成功和失败测试用例的执行轨迹信息. (2)根据定义1识别偶然正确性元素cce. (3)特征元素挑选.采用Tarantula方法对cce进行怀疑度计算,将怀疑度的大小作为偶然正确性元素的权重,对偶然正确性元素进行排序,设置参数θ作为选择偶然正确性元素的比例,挑选出特征元素. (4)维度约简.根据挑选的特性元素对步骤(1)中获得的程序执行轨迹信息进行维度约简. (5)识别偶然正确性.对降维后的程序执行轨迹信息采用Fuzzyc-means聚类算法将其分为两簇,一般认为偶然正确性测试用例的执行轨迹和失败测试用例的执行轨迹最相似[7],因此,将包含失败测试用例较多的那个簇中的成功测试用例视为偶然正确性测试用例,另外一个簇中的成功测试用例为真正成功测试用例. (6)将移除偶然正确性测试用例后的测试用例集应用于错误定位,从而提高其效率. 3.2 算法 算法1描述了基于Fuzzyc-means聚类的偶然正确性测试用例识别算法,主要实现3.1节偶然正确性识别模型中的步骤2~5.第1~5行识别偶然正确性元素cce,其中第1行初始化偶然正确性元素为φ.第2、3行根据计算偶然正确性元素,其中L(t)表示程序执行轨迹中所有元素.第4行计算偶然正确性元素集合.第6、7行,特征元素选择,使用Tarantula计算怀疑度,对偶然正确性元素cce按怀疑度从大到小排序,设置挑选高可疑偶然正确性元素比例θ,来挑选特征元素.第8行执行轨迹维度约简,按挑选出的特征元素对所有程序执行轨迹进行维度约简,约简后程序执行轨迹信息作为Fuzzyc-means聚类的输入.第9~15行为Fuzzyc-means聚类过程,第9行为初始化隶属度矩阵U0且矩阵满足式(5).第10~12行为聚类迭代求解过程,根据式(6)和式(7)迭代求解最优(Uf,Vf),其中Uf表示最优隶属度矩阵,Vf表示最优聚类中心点,第14、15行根据最优(Uf,Vf)生成最终簇Cluster1,Cluster2,其中一个簇中包含偶然正确性测试用例. 算法1 基于Fuzzyc-means聚类的偶然正确性测试用例识别算法 输入:k; //聚类的簇数k=2 T; //所有程序执行轨迹信息 m; //聚类迭代次数最大值 θ; //偶然正确性元素挑选阈值 ε; //聚类分析终止阈值,ε>0 输出:Cluster1,Cluster2 begin 1. cce←φ; 2. for eachein∪t∈Trace(L(t)) 3. if (P(TF,e)=1∧0 4. cce←cce∪{e}; 5. end for 6. calculate the suspiciousness of ccewith Tarantula; 7. pick the most suspicious ccewith suspiciousness sorted by Tarantula setting parameterθ; 8. reduce traceTusing ccebeing picked; 9. randomly generate membership matricU0and makeuijsatisfy formula(5); 11. calcalate the center of clusterVtwithUtand formula(6); 12. calcalate membership matricUtwithVt-1and formula(7); 13.end while 14. produce optimal (Uf,Vf)=(Ut,Vt); 15. generate Cluster1 and Cluster2 according to (Uf,Vf); end 为评估偶然正确性对错误定位效率的影响,选取Tarantula[8]、Ochiai[9]、Naish2[10]和Russel&Rao[10]共4种错误定位方法进行对比实验.运行环境:Ubuntu 64位操作系统,版本12.04,2核CPU 3.07GHz Intel(R),内存16GB. 4.1 实验对象 实验采用西门子套件C版本中的3个程序print_tokens2,schedule2和tcas作为代码较小规模的程序代表;西门子套件目前使用广泛,但程序规模较小,为保障实验结论更具一般性,选取了代码中等规模的Nanoxml程序中版本v1、v2和v5;另外选取了Unix工具程序(gzip、grep、sed、flex).实验对象详细信息见表2,从SIR(Subject Infrastructure Repository)(SIR网址:http://sir.unl.edu/portal /index.html)下载. 表2 实验对象 4.2 评测指标 (1)漏报率(False Negatives,FN).主要用于评估某种方法未准确识别偶然正确性测试用例的比率[7],见式(8),其中,true CC NO.表示的是真实的偶然正确测试用例数,CC identifed NO.表示的是通过聚类分析技术判别出来的偶然正确性测试用例数. (8) (2) 误报率(False Positives,FP).主要用于评估某种方法将非偶然正确性测试用例判别为偶然正确性测试用例的比率,见式(9),其中,Tp表示成功测试用例数. (9) (3)错误定位代价(cost).为找到缺陷时需要检查的语句数与程序的总语句数的比率[11],见式(10). (10) (4)检查得分(EXAM)[11].为错误检出率(% of faults located)与代码检查率(% of code examined)的比率. (11) 4.3 实验评估 为评估方法有效性,进行以下3个方面的实验. (1)偶然正确性存在的普遍性 通过程序插桩来检测成功测试用例的执行过程中缺陷语句是否被执行到,若被执行到,则为偶然正确性测试用例;否则为真正成功测试用例.图2展示了测试的136个程序错误版本(见表1)中普遍存在偶然正确性现象.其中,横坐标为成功测试用例中包含偶然正确性百分比;纵坐标为包含一定比例偶然正确性测试用例的错误版本数比率. (2)识别偶然正确性的误报率(FN)和漏报率(FP) 由表3可见,CC-FCM模型的误报率和漏报率都稍低于对比方法Tech-I.由于真正成功和偶然正确性测试用例较难区分,且聚类分析对数据对象的识别存在一定的偏差,导致这两种方法都有一定程度的误报和漏报. 表3 平均误报率和漏报率 (3)去除偶然正确性前后错误定位效率的对比 本文主要采用4种错误定位方法Tarantula,Ochiai,Naish2和Russel&Rao进行对比实验.在下面3种情况下比较其错误定位的效率:①不考虑偶然正确性,在原始测试用例集上进行错误定位,记为Orig.②在文献[7]中Tech-I方法去除偶然正确性的测试用例集上进行错误定位,记为Tech-I.③在CC-FCM模型识别并移除偶然正确性的测试用例集上进行错误定位,记为CC-FCM. 对于某方法来说,错误定位代价越小说明其效率越高.实验结果如表4中所示,在CC-FCM和Tech-I移除偶然正确性的基础上,4种方法的错误定位代价均低于在原始测试用例集上(Orig.)的错误定位代价.大多数情况下,在CC-FCM识别偶然正确性的基础上的错误定位代价低于在Tech-I识别偶然正确性基础上的错误定位代价;但在个别情况下,在CC-FCM基础上的错误定位代价稍高于或等于在Tech-I基础上的错误定位代价,如表4中阴影所示.例如,对于schedule2程序,Russel&Rao方法在CC-FCM基础上的错误定位代价18.32%稍高于在Tech-I基础上的错误定位代价18.23%.其原因在于:这些测试程序不尽相同,程序特征及错误分布可能不同,这使得本文方法的效果可能受到一定程度的影响,在个别情况下,效率提升不明显. 接下来比较在CC-FCM与Tech-I、Orig.基础上错误定位的检查得分.图3分别展现了在3种情况下4种错误定位方法的检查得分.其中,横坐标代表代码检查率,纵坐标代表在一定代码检查率下的错误检出率.相同代码检查率下,某方法定位出的错误比例越高则该方法越有效.从图3可以看出,4种错误定位方法在CC-FCM识别偶然正确性情况下检查得分高于在Tech-I识别偶然正确性情况下的检查得分;并且CC-FCM和Tech-I识别并移除偶然正确性后,错误定位方法的检查得分都高于不考虑偶然正确性测试用例Orig.情况下的检查得分. 表4 去除偶然正确性前后各错误定位方法的错误定位代价 本文方法与Tech-I方法相比的优势在于:①引入Fuzzyc-means聚类分析,该聚类允许数据对象属于任何一簇,只是它们属于某簇的可能性大小不同;而Tech-I方法使用的k-means聚类属于硬分类,使得每个程序执行轨迹只能属于所有类别中的某一类,对聚类中心点的贡献度相同.②设计了偶然正确性特征元素挑选策略,这些特征元素更能反映程序执行轨迹信息的偶然正确性特征. 针对偶然正确性问题,提出一种面向有效错误定位的偶然正确性识别方法.首先,识别出偶然正确性元素;其次,对偶然正确性元素排序,挑选出高可疑偶然正确性元素作为特征元素,利用其对程序执行轨迹进行维度约简;最后,使用模糊c均值聚类对维度约简后程序执行轨迹进行聚类,识别出偶然正确性测试用例,将其移除偶然正确性后的结果应用于错误定位.实验表明:与Tech-I方法相比,CC-FCM识别偶然正确性的误报率和漏报率有所下降;移除偶然正确性测试用例后,错误定位方法的定位效率有一定程度的提升. [1]Hierons R M.Avoiding coincidental correctness in boundary value analysis[J].ACM Transactions on Software Engineering and Methodology,2006,15(3):227-241. [2]Masri W,Assi R A.Cleansing test suites from coincidental correctness to enhance fault-localization[A].Proceedings of the 3rd International Conference on Software Testing,Verification and Validation[C].Paris,France:IEEE,2010.165-174. [3]Masri W,Podgurski A.Measuring the strength of information flows in programs[J].ACM Transactions on Software Engineering and Methodology,2009,19(2):5-37. [4]Wang X,Cheung S C,et al.Taming coincidental correctness:coverage refinement with context patterns to improve fault localization[A].Proceedings of the 31th International Conference on Software Engineering[C].Los Alamitos,CA:IEEE Computer Society,2009.45-55. [5]Bandyopadhyay A.Mitigating the effect of coincidental correctness in spectrum based fault localization[A].Proceedings of the 5th International Conference on Software Testing,Verification and Validation[C].Montreal,QC:IEEE,2012.479-482. [6]Miao Y,Chen Z,Li S,et al.A Clustering-based strategy to identify coincidental correctness in fault localization[J].International Journal of Software Engineering and Knowledge Engineering,2013,23(05):721-741. [7]Masri W,Assi R A.Prevalence of coincidental correctness and mitigation of its impact on fault localization[J].ACM Transactions on Software Engineering and Methodology,2014,23(1):1-28. [8]Jones J A,Harrold M J,Stasko J.Visualization of test information to assist fault localization[A].Proceedings of the 24th International Conference on Software Engineering[C].Los Alamitos,CA:IEEE Computer Society,2002.467-477. [9]Rui A,Peter Z,et al.An evaluation of similarity coefficients for software fault localization[A].Proceedings of the 12th Pacific Rim International Symposium on Dependable Computing[C].Riverside,CA:IEEE,2006.39-46. [10]Naish L,Lee H J,et al.A model for spectra-based software diagnosis[J].ACM Transactions on Software Engineering and Methodology,2011,20(3):11-43. [11]Renieris M,Reiss S P.Fault localization with nearest neighbor queries[A].Proceedings of the 18th IEEE International Conference on Automated Software Engineering[C].New York,USA:ACM,2003.30-39. 曹鹤玲 女,1980年5月出生于河南南阳.中国矿业大学博士生,CCF会员.主要研究领域为软件分析与测试、数据挖掘. E-mail:caohl410@cumt.edu.cn 姜淑娟(通信作者) 女,1966年12月出生于山东莱阳.现为中国矿业大学计算机科学与技术学院教授、博士生导师,CCF会员.主要研究领域为编译技术、软件工程等. E-mail:shjjiang@cumt.edu.cn Identifying Coincidental Correctness for Effective Fault Localization CAO He-ling1,2,3,JIANG Shu-juan1,WANG Xing-ya1,XUE Meng1,QIAN Jun-yan3 (1.SchoolofComputerScienceandTechnology,ChinaUniversityofMiningandTechnology,Xuzhou,Jiangshu221116,China; 2.CollegeofInformationScienceandEngineering,HenanUniversityofTechnology,Zhengzhou,Henan450001,China; 3.GuangxiKeyLaboratoryofTrustedSoftware,GuilinUniversityofElectronicTechnology,Guilin,Guangxi541004,China) Fault localization is one of the most time-consuming activities in software debugging.An identifying coincidental correctness approach for effective fault localization is proposed to decrease the effect of coincidental correctness on the effectiveness of fault localization.First,the elements of coincidental correctness are computed.Second,the higher suspicious coincidental correctness elements are selected as feature elements of coincidental correctness,and then program execution traces are reduced in terms of feature elements.Finally,fuzzyc-means based coincidental correctness identification model is created based on the reduced execution traces to locate faults.It was applied to analyze three groups of programs,and test cases removing coincidental correctness were used as input for four popular fault localization approaches,such as Tarantula.The experimental results show that our approach had low false positives and false negatives,and performed well in terms of the effectiveness. software debugging;fault localization;coincidental correctness;clustering 2015-03-19; 2015-08-19;责任编辑:覃怀银 国家自然科学基金(No.61202006,No.61340037,No.61502497,No.61562015,No.61602154);广西可信软件重点实验室研究课题资助(No.kx201616,No.kx201532);河南省高等学校重点科研项目计划资助(No.16A520005) TP311 A 0372-2112 (2016)12-3026-06 ��学报URL:http://www.ejournal.org.cn 10.3969/j.issn.0372-2112.2016.12.030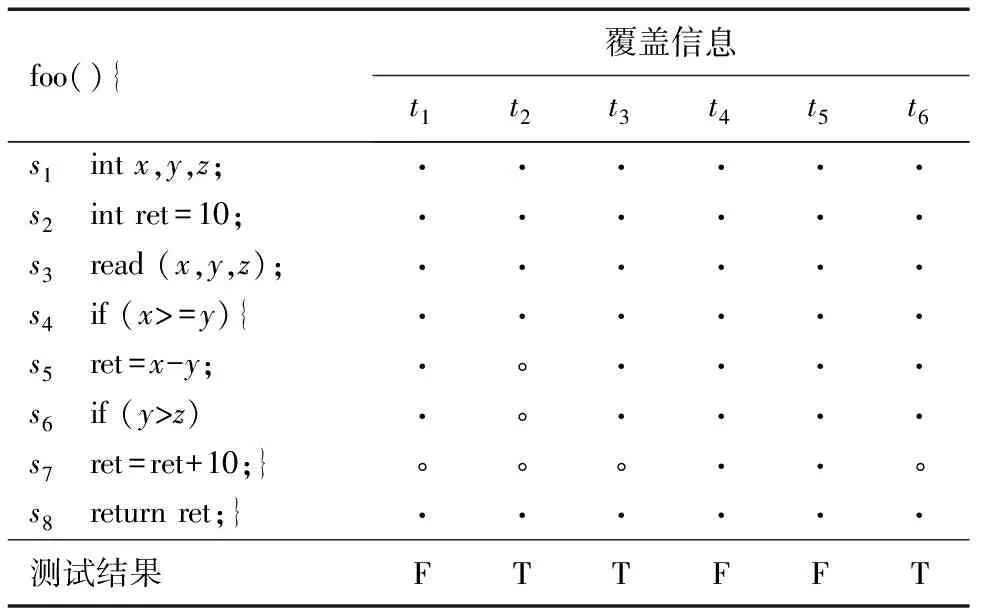


3 本文方法

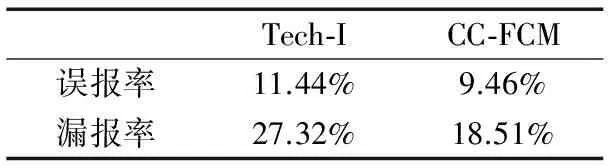
4 实验评估




5 结论

 猜你喜欢
铁道通信信号(2020年6期)2020-09-21读友·少年文学(清雅版)(2020年4期)2020-08-24读友·少年文学(清雅版)(2020年3期)2020-07-24成都信息工程大学学报(2019年2期)2019-08-28现代装饰(2018年5期)2018-05-26中国三峡(2017年2期)2017-06-09科技创新与应用(2017年3期)2017-02-18党史博采·理论版(2016年12期)2016-12-22光学精密工程(2016年5期)2016-11-07浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
猜你喜欢
铁道通信信号(2020年6期)2020-09-21读友·少年文学(清雅版)(2020年4期)2020-08-24读友·少年文学(清雅版)(2020年3期)2020-07-24成都信息工程大学学报(2019年2期)2019-08-28现代装饰(2018年5期)2018-05-26中国三峡(2017年2期)2017-06-09科技创新与应用(2017年3期)2017-02-18党史博采·理论版(2016年12期)2016-12-22光学精密工程(2016年5期)2016-11-07浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
