
基于本地敏感信息过滤的大数据查询优化算法研究
2017-01-10 04:08郭玲
广东技术师范大学学报 2016年11期
郭玲
(珠海城市职业技术学院,广东珠海 519090)
基于本地敏感信息过滤的大数据查询优化算法研究
郭玲
(珠海城市职业技术学院,广东珠海 519090)
在数据快速访问和网络数据快速访问领域,信息过滤的效率高低直接影响访问速度,因而信息过滤的性能倍受瞩目.通过信息过滤,可以在相对较短时间内完成信息检索并经常能够提供出相应的统计分析结果,并进一步实现了大数据检索的成本降低.因此,如果将信息过滤器技术在大数据中应用,将极大提高大数据信息检索的效率.本文基于本地信息的内容特征,提出一种基于本地敏感信息过滤的大数据查询优化算法,该算法可以有效改善单纯依靠精确比对法的检索性能,从而明显提高数据快速访问和网络数据快速访问的速度.
大数据;信息过滤;本地敏感信息
1 引言
随着电子化的快速发展,人们的日常生活越来越离不开信息化数据的帮助.数据体积越来越大,不得不消耗更多的内存容量进行读取和访问,需要研发更先进的技术来处理这些大量数据.对如此庞大规模数据的检索就是其中非常严峻的挑战之一.相比之下,如果想用精确的成员比对查询(q∈S)还不如使用近似成员比对查询(q→S),但这样一来就需要证明近似成员查询成员q有多么“接近”集合S才算精确.对查询内容进行精确比对,当数据量非常大的时候输出就很难控制.因此暴力查询精确对象一般会消耗太多的资源,这时近似成员比对查询就显得更为实际.同时,使用近似查询还有助于我们校正错误或者不精确的查询输入值.实际上这个问题并不是只在大量数据查询领域中存在,对于通过传统查询方法无法完全解决的查询提速问题早已受到关注[1].对近似成员对比查询的研究为节约用户时间和提升软件性能提供了一个可能的方向[2][3].近似成员对比查询有助于我们确定数据集合S中近似存在成员q的问题,这里的近似成员也会被认为成精确成员.
布隆过滤器在业务查询中处理信息错误波动概率较低的紧凑集表达方面非常有效[4].布隆过滤器使用简单的哈希查询(如设置并测试0和1的值)时,求解精确比对查询的运算复杂度是O(1).该过滤器的距离隔离结构也因此被很多领域采用,比如重负载数据流识别[5]、最优替换[6]、文本总结[7]、最长前缀匹配[8]、路径查询[9]及数据包分类[10]都有这种过滤器的应用.但是,标准的布隆过滤器并不支持近似成员比对查询,而且经常会忽略掉可能的近似成员查询项,这主要是受限于使用统一的独立哈希函数(比如MD5、SHA-1等)计算答案是布尔数据类型的问题.本地敏感哈希算法对大数据中近似成员比对查询有所帮助,该算法通过将相似项合并,在局部数据中避免了布隆过滤器忽略相似项的问题[11].目前,已有开始尝试在近似成员合并中引入经过优化改造的布隆过滤器的研究[12].本文的研究主要目标是优化大数据查询效率,同时避免无效的查询结果.
本文首先将哈希过程进行优化以提高效率,随后改进布隆过滤器以进一步提升检索和
查询的性能.改进的哈希过程和布隆过滤器共同组成了基于本地敏感信息过滤的大数据查询优化算法(Local Sensitive Information Filtering based Big Data Inquiry,LSIFBDI).
2 信息过滤
2.1 引入布隆过滤的重要性
布隆过滤器最早于1970年由Burton H. Bloom发明.本文以对n个对象组成的数据集合S={a1,a2,…,an}形成的m比特向量对应的布隆过滤为例介绍其原理.初始化将过滤器中全部置0.布隆过滤器采用长度为k的独立哈希函数{h1,h2,…,hn}实现集合S向比特向量的映射.每个哈希函数hi基于相同的随机分布生成集合元素ai到m比特向量任意位置的映射.如果每一hi(ai)个的值都是1,那说明确实是集合S的一个成员.对每一个集合成员的判定实质上就是一个正误识别判定过程.布隆过滤器在组网方面应用非常广泛.
现在对快速得到精确结果的要求越来越强烈.因为数据在网络中越来越多,那么以便于查找的方式存储就越来越重要.传统的数据存储格式看起来能够应付这种需求,但数据描述对象的属性的差异严重限制了传统存储格式在解决这类问题方面的能力.大数据处理中,输入数据量大到必须进行分割成更小的文件进一步处理,这就需要引入借助哈希函数的布隆过滤器.
2.2 大数据信息过滤建模
仍旧以n个对象组成的数据集合S={a1,a2,…,an}为例,假设要进行的查询是类似“y是否在S中?”的要求,其输出的答案并非S集合的成员或者子集本身,而是是否存在的一个判定结果.另外,布隆过滤器也是存在容差的.本例中,布隆过滤器先将全部序列值初始化为0再根据哈希函数进行映射运算.那么在回答本例中类似问题过程中,并不需要逐一检测完全部的向量元素值是否为1,只要表征存在y在S中即可.但这样就有可能出现虚报y存在于S的错误.
传统意义上讲,应用布隆过滤器解决一般的查询问题的优势包括如下几方面:
(1)运算空间利用率更高:布隆过滤器的长度与被处理数据的量之间是线性关系,且与被查询数据具体存储位置无关.
(2)快速构建:构建布隆过滤器的过程非常快速,耗时极少,只要扫描一次数据集合就可以完成.
(3)测试归属类查询效率很高:所占用的查询序列长度通常是常数,且与被查询集合的大小相比微乎其微.
(4)设置布隆过滤器长度可节约查询时间:但同时需要注意长度过短可能增大上文提到的虚报问题.
2.3 映射与化简
映射与化简是并行处理数据量在TB以上级别数据时应以的一种编程模型.
正如其名,映射与化简函数包含映射功能和化简功能.映射过程选取一组数据将其映射为另外的数据,比如将各项物品的数据拆分并重新以特定的符号进行简化替代用于后续数据处理的过程就是典型的映射过程.化简过程以映射的输出作为其输入,将映射的结果压缩为更小的集合.程序框架自动排序映射过程的结果,将最近似的一组结果向化简函数输出.输入和输出存储在文件系统中.框架则负责任务的调度、构建、进度监控和结束错误进程.化简过程的输出结果最终作为整体输出.映射与化简框架与Hadoop分布式文件系统同时并行在存储文件系统中同一个节点上运行.这种方式有效降低了可能引发的在节点之间传输大量过程量的风险. Hadoop平台中设置一个独立运行的总控进程,每一个节点上存在一个本节点的从属进程.从属进程接受总控进程对数据处理的调度,总控进程则需控制全部从属进程运行和衔接管理.
2.4 布隆过滤器中的哈希过程
哈希过程实质上是将通常以字符串格式存储的数据转化为一个长度更小、大小几乎固定的数值,这个数值在哈希函数内部可以识别其所代表的字符串.正是由于这一点,哈希函数所存储的仅仅是m比特的哈希值而非字符串本身,因此在索引和取值操作中大量应用哈希过程加快程序相应速度、提高执行效率.布隆过滤器也是应用哈希函数将原始数值转换为哈希值存储在过滤器中的.
3 本地敏感信息哈希过程
定义哈希函数为:

其表达域可以表示为(R,cR,P1,P2),该函数对距离敏感,可表述为:
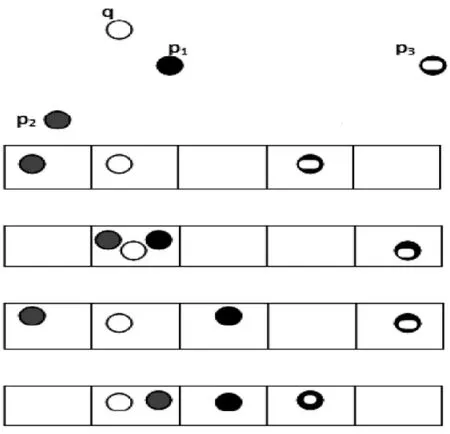
图1 哈希过程的数据表示意图
对于相似搜索,假设c>l且P1>P2,那么每个哈希函数ha,b可以映射一个d长度的向量v到一系列整数上去.哈希函数IH可以通过下式计算:

其中,a是根据一个有s个稳态的分布函数生成的d长度的随机向量,b是从区间[0,w)中选取的任意实数,w为常数.

图2 对两元素的哈希检索示意图
研究通过多个哈希函数实现的相似检索,只对两个元素(P1和P2)检索,且两元素的存储距离足够大(c>l),如图2所示.本地敏感信息检索过程测量元素的存储距离来计算亮点之间近似位置.如果将q看做是以R为半径的圆,点P1处于圆内,那么这个点处于q的近点,本地敏感哈希过程将继续扩大其半径至cR,此时P2进入了圆的范围,但是P3仍不在圆内.
对应到基于本地敏感信息的哈希检索过程,图2的含义为由多张哈希表决定的P1和P2均被检索到,但相对来讲P1的敏感度更高.而P3则不是该哈希过程的检索结果.
4 本地敏感信息布隆过滤器设计
为了进一步提高上节设计的哈希查询的准确性,同时更好地克服虚报的问题,布隆过滤器也需要进一步改进.本文在应用改进的哈希查询的基础上,在布隆过滤器设计中引入了逐比特验证算法来减轻虚报问题的影响,同时也可降低误判的概率.改进的滤波器由L个本地敏感哈希函数gi(q)(1≤i≤L)将数据分类至哈希缓存表.基于哈希查询,通过检查对象的本地位置信息可以将之映射至哈希表中相应位置,这个过程中哈希表的值可能被多次修改,但是仅第一次修改值有效,这样保证了修改效果的误操作.集合S的所有成员将分散到一个m比特的向量中.这样设计的滤波器在执行对q的查询或者基于哈希查询插入一个成员值的时候,实际上是执行对L比特的哈希距离gi(q)(1≤i≤L)的计算.如果全部L个比特的值均为1,则判定q确实在集合S中.图3给出了这一设计的示意图.
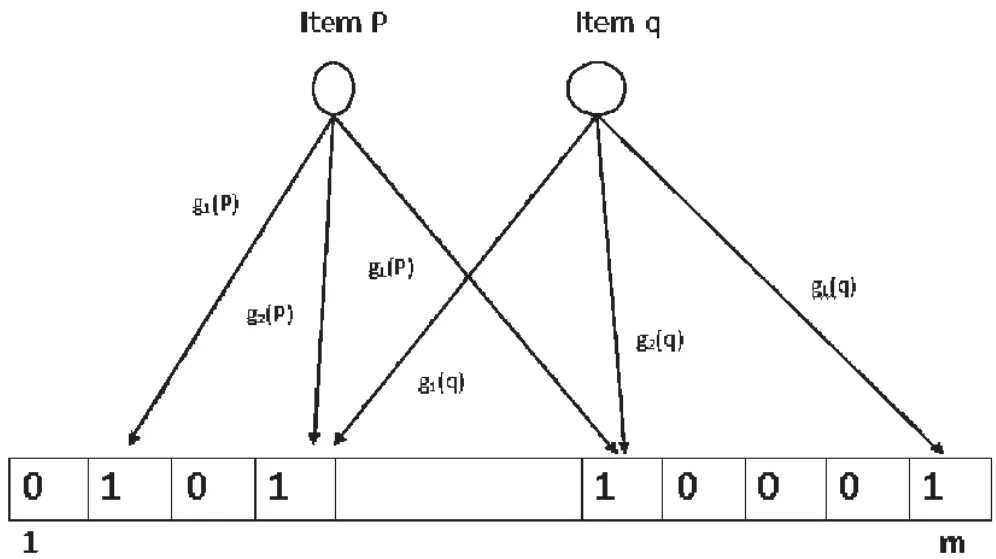
图3 本地敏感信息布隆过滤器示意图
为了便于检查哈希结果,每一比特计算的输出如果为1代表所查询的成员在集合S中,如果全部比特均显示为1代表所查询的对象是集合S的近似成员,也即完成了本次查询.
5 本地敏感信息查询优化算法实现
布隆过滤器通过哈希查询将对象进行标记来存储数据,那么这一算法就可以用于大数据的信息检索了.大数据的内容可能包含多种格式,比如.doc、.jpg、.mpeg、.xls,还可能存在其他格式的视频、音频等等,但是在内存中这些均存储成了不同的0或1.那么在公共存储区存储不同类型的数据时,数据格式就显得非常重要了.好的数据格式选择将大幅降低检索耗时,相似格式的数据也便于存储在邻近的位置.因为大数据的查询过程是先进行映射,映射的结果再合并成最终的检索结果,所以应采取本文提出的改进算法进行数据的存储和检索.
本文所提出的算法,以类程序结构表述如下:

6 算法性能评估
为检验LSIFBDI的性能,本文提取了某在线教学课程网站的后台数据作为数据处理的基础.分别应用LSIFBDI和传统的精确查询(Traditional Exact Inquiry,TEI),对给定的课程或学习信息进行查询操作.分别检查两种算法在查询准确率(查询到的记录与实际存储的记录之间的比例)、查询占用内存比例(为方便对比,以精确查询占用内存为基础系数1,换算LSIFBDI的占用内存比例)、LSIFBDI算法在设置不同的过滤器位数时误报和漏报的比例.
首先,我们对比LSIFBDI与TEI在查准率方面的性能.当数据量较小的时候,两者的查准率相差很小.但是随着数据量的增大,LSIFBDI的查准率能够仍然维持在相对稳定的水平上,但是TEI的查准率则出现了不规则的抖动,如图4所示.
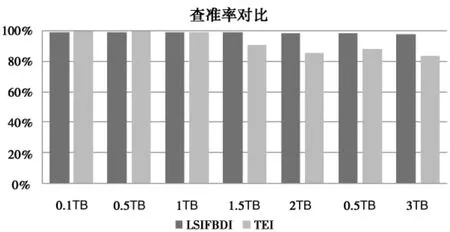
图4 查准率对比图
随后,本文研究了两算法查询占用内存比例关系,为方便对比,以TEI占用内存量为基础,以LSIFBDI占用内存是TEI占用内存的倍数进行数据呈现,如图5所示.可见,随着数据量的增大,LSIFBDI占用内存相对于TEI出现非常明显的降低.
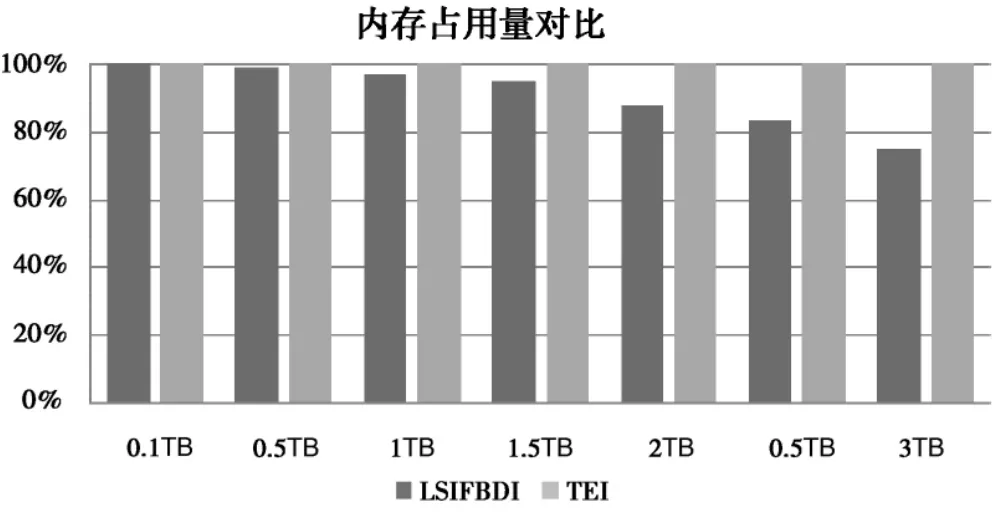
图5 内存占用量比较
最后,本文对比了LSIFBDI算法在设置不同的过滤器位数时误报和漏报的比例.随着过滤器位数的上升,错报和漏报比例均出现了明显的下降.但当过滤器位数达到一定长度后,错报和漏报比例几乎不变,如图6所示.可见,在设置LSIFBDI算法过滤器长度时,不必一味追求精度而增加滤波器长度.

图6 LSIFBDI算法漏报与错报比例
7 结语
提升信息的快速访问和检索的性能是大数据应用的重要技术难点.基于本地信息特征,本文提出了一种基于本地敏感信息过滤的大数据查询优化算法(Local Sensitive Information Filtering based Big Data Inquiry,LSIFBDI),该算法可以在大数据查询中替代传统的精确查询算法,用以提高查询的精度和消耗的时间同时达到降低内存占用的效果.本文将所提算法与传统算法进行对比,在查准率、内存占用量、漏报与错报方面所提算法均有较好表现.通过查询项之间存储距离的计算,本文提出的算法可以更好地处理相似项的检索问题.数据验证可证明本文所提算法在查询精度和资源消耗方面的性能提升.
[1]L.Carter,R.Floyd,J.Gill,Markowsky and Wegman, Exact and Approximate Membership Testers[C],Proc. 10th Ann.ACM Symp.Theory of Computing,1978:59-65.
[2]孙炯宁.基于混合式子树算法的大数据匿名化[J].南京理工大学学报,2015(5):950-961.
[3]覃雄派,王会举,杜小勇,王珊.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012(1): 6-13.
[4]Y.Zhu and H.Jiang,False Rate Analysis of Bloom Filter Replicas in Distributed Systems[C],Proc.Int’1 Conf.Parallel Processing,2006:255-262.
[5]W.ChangFeng,Kandlur,SahaandK.G.Shin, Stochastic Fair Blue:A Queue Management Algorithm forEnforcingFairness[C],Proc.IEEEINFOCOM, 2001.
[6]李建中,刘显敏,大数据的一个重要方面:数据可用性[J],计算机研究与发展,2013(6):7-11.
[7]余祖坤,许景楠,郑小林,陈德人,基于信任的真实数据判定方法[J].2013(9):11-18.
[8]CVitolo,YElkhatib,DReusser,CJAMacleod,W Buytaert,Web technologies for environmental Big Data[J],Environmental Modelling&Software,2015(63): 185-198.
[9]A.BroderandMitzenmacher,Usingmul tipleHash Functions to Improve IP Lookups[C],Proc.IEEE INFOCOM,2001:1454-1463
[10]F.Baboescu and Varghese,Scalable Packet Classification[J],IEEE/ACM Trans.Networking,2006,13(1): 2-14.
[11]X Jin,BW Wah,X Cheng,Y Wang,Significance and Challenges of Big Data Research[J],Big Data Research,2015,2(2):59-64.
[12]A.KirschandMitzenmacher,Distance-Sensitive Bloom filters[C],Proc.Eighth Workshop Algorithm Eng and Experiments(ALENEX),2006.
[13]MMNajafabadi,FVillanustre,TMKhoshgoftaar,N Seliya,RWald,Deeplearningapplicationsandchallenges in big data analytics[J],Journal of Big Data》, 2015,2(1):1-21
[14]ATVu,FMGDe,JGama,ABifet,Distributed AdaptiveModelRulesforminingbigdatastreams[C],IEEEInternationalConferenceonBigData, 2015:345-353
[15]Zhijian Chen;Dan Wu;Wenyan Xie;Jiazhi Zeng; Jian He;di Wu,A Bloom Filter-Based Approach for EfficientMapreduceQueryProcessingonOrdered Datasets[C],Advanced cloud and Big Data,2013 International Conference on,2013:93-98.
[16]Mayank Bhushan&Sumit Yadav,Cost based Model for Big Data Processing with Hadoop Architecture[M], 2014.
[责任编辑:王晓军]
A Local Sensitive Information Filtering based on Big Data Inquiry Algorithm
GUOLing
(ZhuHai City PolytechZhuhaiGuangdong519090,China)
Information filter affects the accessing efficiency in the areas of data fast access and network information fast access.This attracts attentions from the researchers.Via information filtering,it becomes possible to finish information searching within a relatively short time period and provides statistic analyses.Moreover, information filter reduces the cost of information fast access.By applying this advance,the big data inquiry efficiency will be greatly increased if information filtering technique is utilized.A Local Sensitive Information Filtering based Big Data Inquiry is proposed in this paper,based on the features of local information.The proposed algorithm could improve the performance of exacting matching inquiring method and enhance the performance of data fast access and network information fast access.
Big data;Information filtering;Local sensitive information
TP 399
A
1672-402X(2016)11-0047-06
2016-08-10
郭玲(1970-),女,湖南长沙人,珠海城市职业技术学院讲师.研究方向:计算机应用、教育技术.
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
文萃报·周二版(2020年32期)2020-09-02
西北园艺(果树)(2019年2期)2019-02-20
趣味(语文)(2018年2期)2018-05-26
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
自动化博览(2014年6期)2014-02-28
中国氯碱(2014年11期)2014-02-28
