
基于Spark的大电网广域时空序列分析平台构建
2017-01-10 02:15袁宝超刘道伟刘丽平王泽忠
电力建设 2016年11期
袁宝超,刘道伟,刘丽平,王泽忠
(1.华北电力大学电气与电子工程学院,北京市 102206;2.中国电力科学研究院,北京市 100192)
基于Spark的大电网广域时空序列分析平台构建
袁宝超1,刘道伟2,刘丽平2,王泽忠1
(1.华北电力大学电气与电子工程学院,北京市 102206;2.中国电力科学研究院,北京市 100192)
为了适应能源互联网发展趋势及日益复杂的运行环境,亟需依托大数据技术,提升能源互联网多源大数据的挖掘深度及应用效率。首先,针对大电网广域时空序列数据,阐述了Spark在分布式计算中的优势,阐明大数据平台建设目标,设计了基于Spark的电力大数据平台架构,并对平台各个层次进行详细的论述。其次,描述了Spark针对电网时空序列数据的处理过程。最后,在搭建的Spark和Hadoop实验环境基础上,对典型聚类算法进行性能对比测试,验证了Spark相对于Hadoop的MapReduce计算模型数据处理的优势,为下一步研究工作奠定了基础。
能源互联网;Spark;时空序列;流计算;聚类
0 引 言
伴随着能源互联网建设进程的稳步推进,互联网、新能源和可再生能源技术深度融合,电网将逐渐演变成具有广泛互联、高度智能、开放互动和自主行为的复杂能源网络[1-3]。传统的电力系统运行模式将发生巨大改变,在信息流、能量流2种载荷交错运行的情况下,多源数据规模呈现出爆发式增长趋势,致使电网在海量数据获取、管理与分析,安全稳定运行等方面面临严峻的挑战[4-6]。
近年来,国内外大停电事故时有发生,暴露了传统的离线预决策方式已经不能满足大电网稳定控制技术要求[7-10]。新一代智能电网调度技术支持系统(D5000)实现了大电网运行状态的广域测量,为实现信息驱动的大电网在线安全评估与防控提供了数据平台基础。电力大数据服务应用作为能源领域的国家战略,为加强广域时空序列数据在大电网安全防控中的应用,提升对广域信息的综合分析、处理能力,满足海量数据存储、管理需求,提供了重要的技术支撑手段[11-14]。
在大数据技术领域中,Spark是继Hadoop之后的新一代大数据分布式处理平台。目前,已经有部分专家学者针对Spark平台在电力系统中的应用展开了研究。文献[15]基于Spark平台和多变量L2-Boosting回归模型建立了分布式能源系统短期负荷预测方法;文献[16]提出了在Spark环境下电力变压器监测数据并行诊断方法;文献[17]在Spark环境下通过粒子群优化算法对最小二乘支持向量机的参数进行调优,提出短期分布式电力负荷预测方法;文献[18]提出了基于Spark和聚类分析的电力系统不良数据辨识新方法。以上文献所述方法取得了不错的效果,但均未指明Spark平台在电力系统中应用的具体设计方案以及相较于同类大数据平台的数据处理优势。
本文以大电网采集的广域时空序列数据为基础,设计基于Spark的广域时空序列大数据分析平台。在此基础上,搭建Spark实验室环境,为研究基于Spark的电力大数据平台的有效性,分别采用Spark和Hadoop的MapReduce分布式计算框架对典型K-Means算法进行性能对比测试,由此验证Spark在时空序列处理速度上相较于同类平台的高效性。
1 Spark分布式平台优势
1.1 计算优势
Spark分布式计算性能相比于Hadoop的MapReduce模型在性能上有很大的提升,表1展示了2014年在Daytona GraySort测试中Spark与Hadoop的对比结果[19]。
表1 Spark和Hadoop对比
Table 1 Comparison between Spark and Hadoop
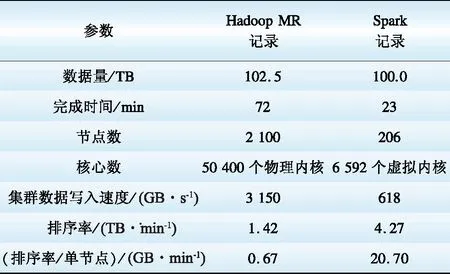
从表1中可以看出排序100 TB的数据(1万亿条数据),Spark只用了Hadoop十分之一的计算资源,但耗时只有其三分之一。由于Spark内部优秀的容错和调度机制,使其具有强大的分布式计算能力。
1.2 集成优势
Spark为批处理(Spark Core)、交互式查询引擎(Spark SQL)、流式数据处理引擎(Spark Streaming)、机器学习库(MLlib)、图计算(GraphX)提供了统一的数据处理平台。并且各个组件间输入输出数据可以无缝共享,无须格式转换。因此,Spark在数据分析处理过程中,效率更高,相较于同类平台具有很大优势。
(1)MLlib:机器学习是实现人工智能的核心思想和方法,为有效提升电网智能化实时感知及广域协调控制水平,自然离不开机器学习算法的支撑。
(2)Spark SQL:高度优化的SQL查询引擎,可针对电网离线或实时数据查询请求进行高速处理,为电网海量数据查询与处理提供了强有力的保障。
(3)Spark Streaming:基于微批量方式的计算和处理的流计算引擎,可用于处理实时流数据。针对广域测量系统采集的实时数据,只需设置合理的批处理间隔,即可完成对数据的实时分析与处理。
(4)GraphX:电网是一个典型的复杂网络系统,应用复杂网络理论和图计算方法,可加深对电网拓扑结构以及网络特性间关联关系的深入研究。
由此可见,Spark中集成的各个组件在电力大数据中均可得到应用,而同类平台则需要相互协调互为补充才能实现Spark所具备的功能。这样可避免不同平台间数据传输带来的数据格式转换、数据共享等弊端。
2 基于Spark的电力大数据平台架构
2.1 平台目标
电力系统传统安全防控模式下,依靠“建模+仿真”模型,智能化水平不高,并且受到参数、模型等制约,对广域测量信息的挖掘深度不足,时效性也很难得到保证。
建立基于大数据技术的信息驱动模式主要目标为满足对大电网海量时空序列数据的高效分析与处理,动态跟踪电网时空序列演变过程。同时,更好地结合机器学习、复杂网络等理论,对大电网多维度时空动力学行为进行量化评估、自适应广域协同控制等。
如图1所示,将二者相互结合,互为补充,可进一步深度挖掘时空序列信息的关联关系与电网时空演变特性。
2.2 平台架构
基于电网广域时空序列数据,构建以Spark为核心的数据分析平台,如图2所示,主要包括以下几个层次。
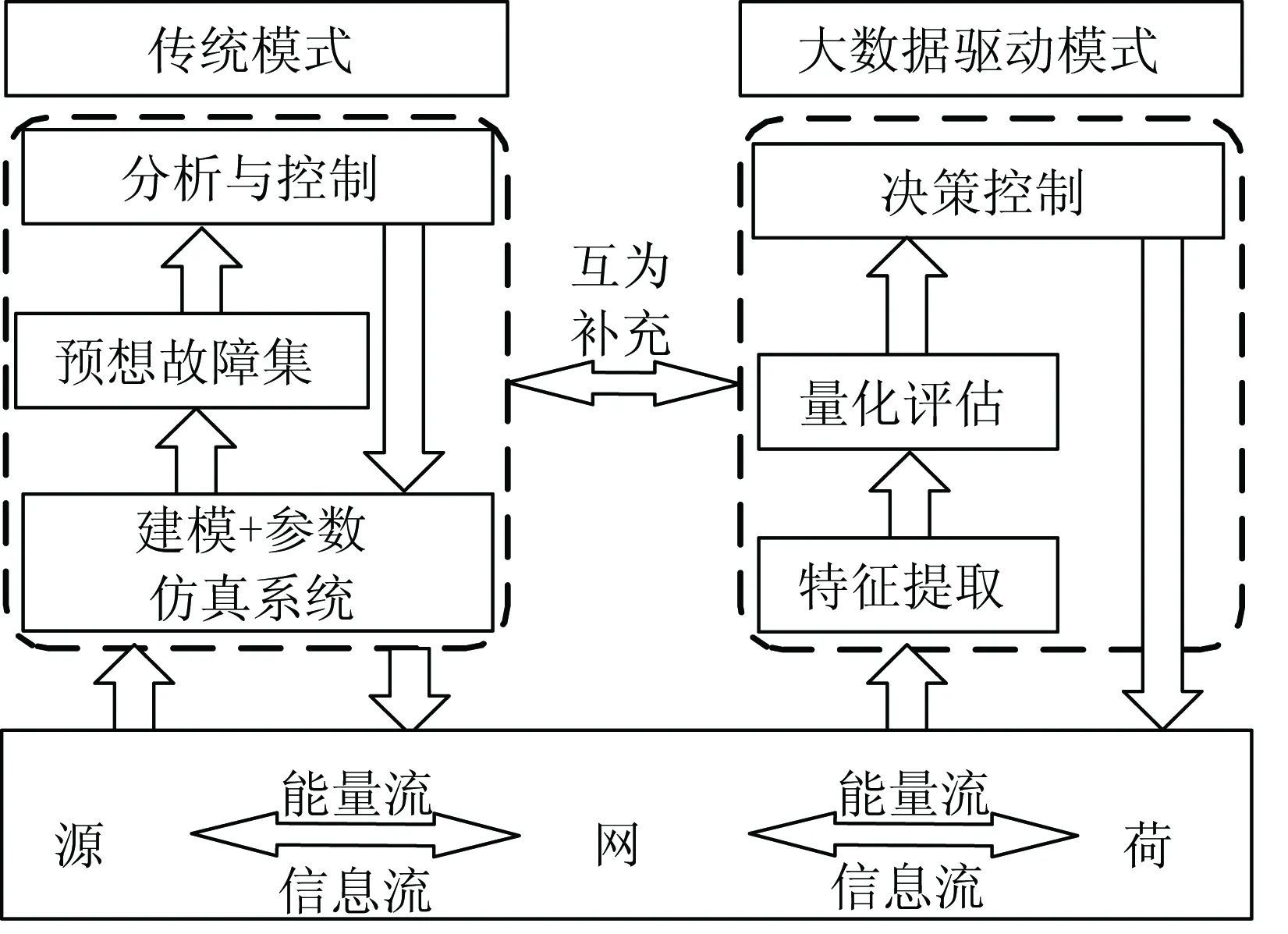
图1 电力大数据平台建设目标
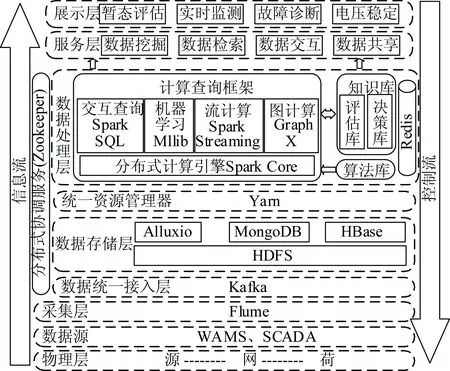
图2 电网时空序列数据分析大数据平台
该平台旨在构建以信息驱动为主的电网信息-物理耦合系统,从复杂的信息网络中提取主导电网运行状态的关键特征,通过计算、通信、控制等技术,利用信息-物理间的相互作用及反馈,提升电网的智能化实时感知和广域协调控制能力,保障电网的安全稳定运行。
2.2.1 采集层
Flume是一个分布式、高可靠、高可用的海量日志采集、聚合、传输系统,负责实时数据的采集。
2.2.2 数据统一接入层
由于电网数据采集、存储、处理速度不一定同步,使用分布式消息队列Kafka[20]作为数据中心管道。同时,为数据流环节的数据规范,传输给Kafka的数据按规定格式输出,避免后端多种接入方式的数据处理问题。
2.2.3 数据存储层
为满足电网时空序列信息高质量获取与整合、流式数据高速索引及存储、错误自动检测等功能,该平台以分布式文件系统(Hadoop distributed file system,HDFS)作为底层分布式存储系统,配合多种NoSQL数据库,为大规模海量数据存储提供了强大的底层支撑[21]。Alluxio作为分布式内存文件系统,可将多次使用的数据存储在共享内存中,避免大量的磁盘I/O操作,提升数据处理效率[22]。
2.2.4 数据处理层
数据处理层为该平台的核心部分,计算及查询框架主要使用了Spark Core,以及在其基础上运行的四大组件:MLlib、Spark SQL、Spark Streaming、GraphX。计算框架采用统一的编程模式,各组件间输入输出数据可以实现无缝共享,无须格式转换,充分发挥了Spark的优势。Redis内存数据库用作数据缓冲池,减轻数据库负载。算法库用于存储常用的高性能并行算法,知识库存储经机器学习训练得到的认知模型。
2.2.5 服务层
服务层可借助从数据处理层获取的业务洞察,用于电网异常事件监测、实时制定决策等功能,以便对电网物理层进行实时控制。其还可以对数据进行封装、解耦,实现数据共享,解决数据使用不灵活问题。
2.2.6 展示层
对计算结果进行图形化展示,可供调度人员直观辨识电网实时运行状态。为便于前端展示,分别将历史、实时数据的分析结果写入不同数据库。图3简要介绍了业务展示流程。
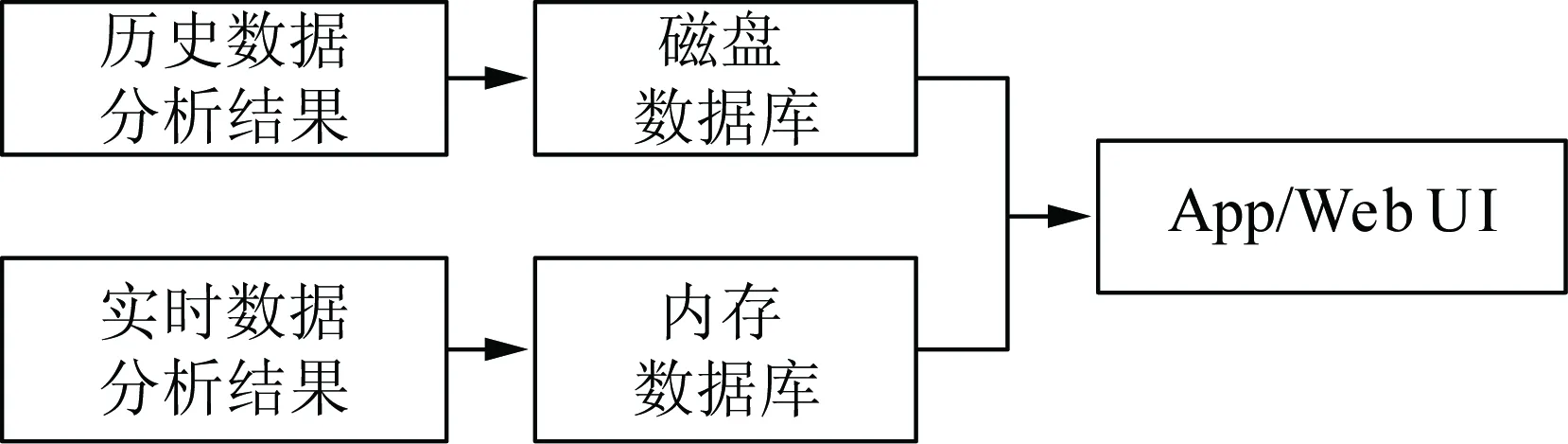
图3 数据结果展示
使用Spark计算平台,计算结果数据可存储在内存中,作为后续操作共享数据,减少结果展示过程中读写磁盘I/O操作带来的延时。针对历史数据分析结果,将数据写入磁盘数据库进行持久化。对于实时数据分析结果,将计算结果数据写入内存数据库,以满足实时更新的需求。
3 基于Spark的电网时空序列数据处理
广域时空序列信息能反映电网实时运行状态,在信息流不断演变的过程中进行实时遥测分析,捕捉电网异常行为,触发相关处理逻辑。
3.1 数据预处理
图4展示了基于Spark的时空序列数据预处理过程。
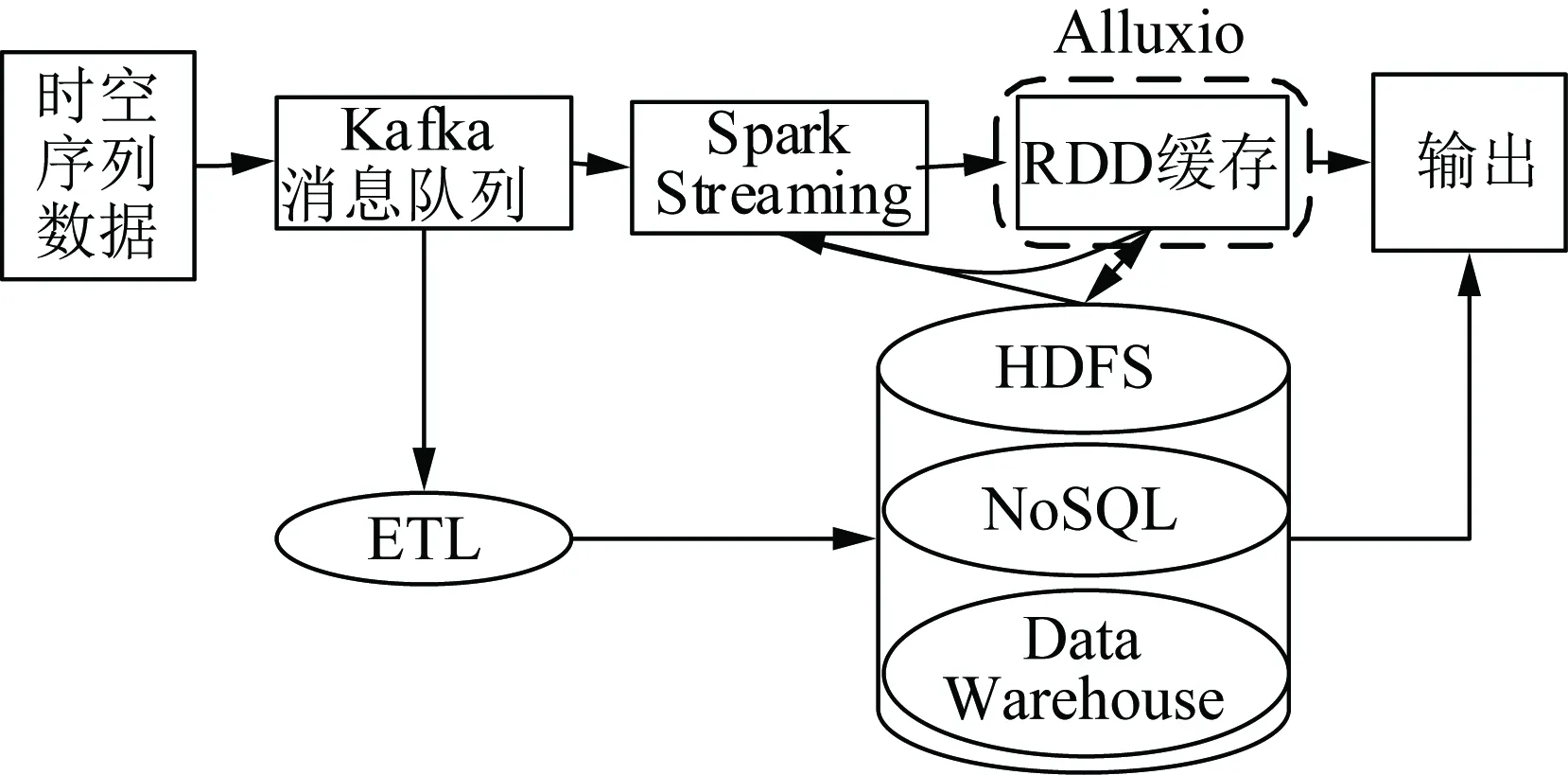
图4 数据预处理
电网原始采集数据中会存在不完整、不一致等情况,为提高数据挖掘的质量,需对实时接收数据进行清洗、转换、归约等预处理操作。Kafka作为数据中心管道,可以对集群中数据进行初步审计验证服务,检测数据延迟、丢失情况,持续监控数据的完整性。
在电力大数据环境下,直接对复杂的数据分析和挖掘效率比较低,可通过Spark Streaming对广域时空序列数据进行特征提取、降维等操作,抓住影响电网稳定的关键因素进行快速分析。由于Spark可以满足复杂的批量数据处理、历史数据的交互式查询、实时数据流的处理3种情景,并且3种情景的输入输出数据可以无缝共享,无须格式转换。因此,极大地方便了使用Spark SQL、MLlib对数据进行实时查询与分析。整个流程根据业务需求可以对中间的结果进行叠加,或写入磁盘进行持久化存储。为了便于前端展示和页面请求,处理及查询得到的结果需写入到数据库中。
3.2 时空序列数据分析
图5展示了基于Spark的电网时空序列数据处理过程。
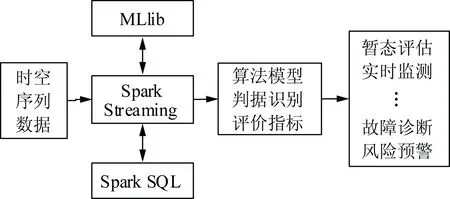
图5 时空序列数据评估
图5描述了在算法模型、判据识别、评价指标等基础上,对Spark Streaming数据预处理结果进行更深一步的量化评估,从而完成对电网运行态势的实时监测。同时,可以通过MLlib离线训练模型,在Spark Streaming中使用该模型对在线数据进行实时分析。例如,将使用训练好的预想故障集实时地对每一批处理间隔内的数据进行检测,实现周期性地对电网进行动态安全约束校核。此外,流数据源中的数据可以与Spark SQL访问的静态数据源进行联合,将实时、静态数据浓缩得更为精炼,用于实时分析,其编程模型的高度一致保证了业务逻辑在流处理、批处理和交互式处理中的共享和复用。
综上所述,在机器学习、流计算等大数据技术应用下,站在电网运行状态全局可观的角度。为了深度挖掘和高效利用广域时空序列信息,需针对电网具体运行场景以及稳定防控问题,抓住影响电网稳定的主导因素,建立一系列依托于电力大数据的时空关联约束模型。构建电网异常事件行为知识库,为电网异常事件的主动预警、实时决策提供可靠的知识保障体系,提升对电网时空序列信息智能化分析水平。
4 Spark、Hadoop算法对比测试
聚类算法可以对电网采集数据进行初步去噪预处理操作,将落在集合之外的数值视为噪声。此外,聚类算法在电网中还有其他一些应用[23-24]。因此本文选择典型的聚类算法K-Means,针对相同的数据集,分别对Spark、Hadoop单机环境和集群环境进行测试并做对比。
4.1 K-Means聚类算法
K-Means算法是最为经典的基于划分的聚类方法,其基本思想是:首先从N个数据中随机取k个元素,作为k个簇的各自的中心;分别计算剩下的元素到k个簇中心的距离,将这些元素分别划归到距离最近的簇;重新计算k个簇各自的中心,即取簇中所有元素各自维度的算术平均数;重复以上步骤,直到满足收敛条件为止。
4.2 实验环境
基于图2所描述的电力大数据平台架构,搭建了以Spark为核心的实验环境,该平台以Yarn作为资源管理器,HDFS作为分布式文件存储系统,Spark为分布式计算框架。同时,为对比Spark和Hadoop的MapReduce这2个计算框架对相同数据的处理能力,二者运行在相同的机器上,并均以HDFS作为底层文件存储系统。集群和单机配置情况如表2、表3所示(注:表中内存指Spark可用内存大小,并非主机实际物理内存):集群内存为14 GB,CPU核数为16;单机内存为2 GB,CPU核数为2。
表2 集群配置
Table 2 Cluster configuration

表3 单机配置

4.3 测试数据
以某区域电网暂态时域仿真结果作为测试数据,该区域电网有7 332个节点,10 928条支路。以中国电力科学研究院PSD-BPA仿真程序进行仿真。由于K-Means聚类时间和数据量大小有一定的关系,数据量越大,迭代一次所用时间越长。为更好地显示对比效果,设置不同的仿真时间,生成5组测试数据,如表4所示。
表4 测试数据
Table 4 Test data

4.4 单机环境对比
使用Hadoop的MapReduce和Spark这2种计算框架,在单机环境下对表4中数据进行K-Means测试,其对比结果如图6所示。
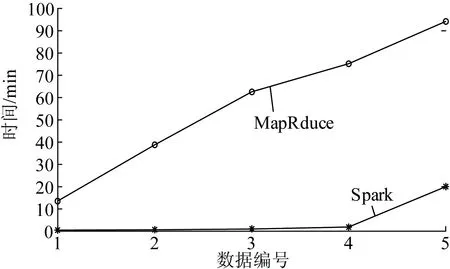
图6 单机环境测试对比结果
由图6可以看出,在相同的硬件设施环境下,且在Spark与MapReduce上K-Means的迭代次数同为为25次,Spark的计算速度要明显优于Hadoop的MapReduce模型。图7展示了随着数据量逐渐增加,Spark和MapReduce运行K-Means处理相同数据的时间对比,曲线代表MapReduce运行时间与Spark运行时间的比值。
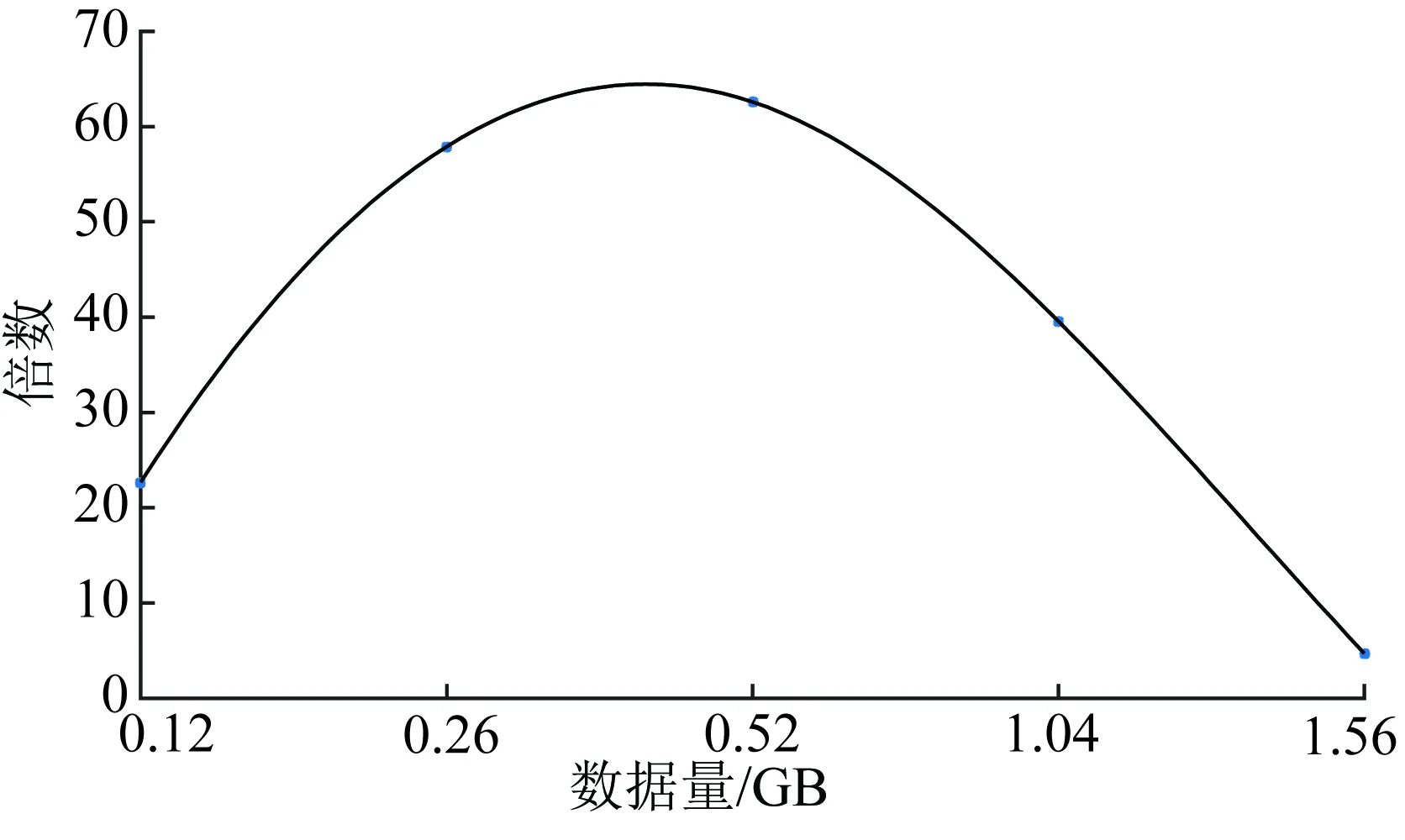
图7 MapReduce与Spark数据处理时间比值
由图7可以看出,数据量在500 MB左右时,Spark的处理数据的优势最为明显。数据量比较小时,MapReduce模型每次迭代计算时磁盘读写时间比较短,系统性能并没有明显受到影响。当数据量增大时,致使数据不能完全保存在内存中,Spark运行程序会在磁盘上进行,导致大量磁盘I/O操作,使系统性能下降。
4.5 集群环境对比
MapReduce和Spark这2种计算框架,在集群环境下对表4中数据进行K-Means测试,其对比结果如图8所示。
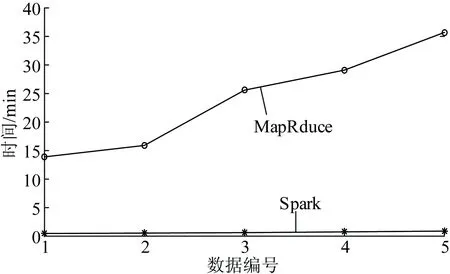
图8 集群环境测试对比结果
由图8可以看出,Spark集群数据处理时间并没有明显变化。在同样硬件设施、迭代次数环境下,K-Means在MapReduce模型上运行时间与Spark上运行时间比值基本维持在三十几倍左右。
(1)单机和集群在相同的程序参数下,数据量比较小的时,集群与单机K-Means测试时间相差不多,有时单机处理甚至会更快一些。因为,集群启动初始化需要一定的时间,并需要考虑分布式系统间通信和集群启动带来的延迟,所以处理时间相差不多。
(2)当数据量超过1 GB时,Spark单机处理时间倍增,特别是当数据量达到1.5 GB时。由于程序在运行、资源调度过程中需要占用一定的内存,单机环境剩余的内存已经不够缓存该数据,从而导致大量的磁盘I/O操作,致使处理时间骤增。说明当数据量达到一定程度时,单机已经不能满足数据处理高效性的要求,并且其计算性能显著降低。
(3)数据量增加时,Hadoop和Spark集群处理时间与单机环境相比并没有增加太多,集群的优势在于可以利用多个计算机进行并行计算从而获得很高的计算速度。当数据量达到单机处理能力的瓶颈时,集群的优势才会明显体现出来,该优势远大于考虑到分布式系统间通信带来的劣势。
(4)无论是在单机还是集群环境下,Hadoop的MapReduce计算模型数据处理速度都要比Spark慢很多。因为MapReduce作业执行过程map阶段和reduce阶段的结果均要写磁盘,会明显降低系统性能,而Spark将数据和计算所得的中间结果直接缓存在内存中,做不落地的运算,数据处理速度会显著提升。
(5)在大数据实际数据处理过程中,数据量往往会达到TB,甚至PB数量级。此时,单台计算机的存储以及计算能力已经远远不能满足数据海量化、高效化处理的需求。因此,海量数据的处理需要大数据技术的支撑。
5 结 论
本文针对大电网广域时空序列在线快速分析与处理需求,综合考虑Spark在高性能数据处理、组件集成中的优势,设计了以Spark为核心的大电网广域时空序列大数据分析平台,为实现电网海量数据可靠存储、高效处理提供了一套可行的解决方案。
通过对大电网时域仿真结果实际对比测试,验证了本平台相对于同类大数据平台,对电网广域时空序列快速、高效的处理能力的优势,满足大电网在线安全分析与控制的需求,为实现能源互联网形势下的新一代安全防御系统提供重要的平台支撑。
[1]孙宏斌, 郭庆来, 潘昭光, 等. 能源互联网:驱动力、评述与展望[J]. 电网技术, 2015, 39(11): 3005-3013. SUN Hong, GUO Qinglai, PAN Shaoguang, et al. Energy internet: driving force, review and outlook[J]. Power System Technology, 2015, 39(11): 3005-3013.
[2]马钊, 周孝信, 尚宇炜, 等. 能源互联网概念、关键技术及发展模式探索[J]. 电网技术, 2015, 39(11): 3014-3022. MA Zhao, ZHOU Xiaoxin, SHANG Yuwei, et al. Exploring the concept, key technologies and development model of energy internet[J]. Power System Technology, 2015, 39(11): 3014-3022.
[3]魏向向, 杨德昌, 叶斌. 能源互联网中虚拟电厂的运行模式及启示[J]. 电力建设, 2016, 37(4): 1-9. WEI Xiangxiang, YANG Dechang, YE Bin. Development path exploration of energy internet[J]. Electric Power Construction, 2016, 37(4): 1-9.
[4]王玮, 刘荫, 于展鹏, 等. 电力大数据环境下大数据中心架构体系设计[J]. 电力信息与通信技术, 2016,14(1):1-6. WANG Wei, LIU Yin, YU Zhanpeng, et al. System design of the big data center architecture in electric power big data environment[J]. Electric Power Information Technology, 2016,14(1):1-6.
[5]朱朝阳, 王继业, 邓春宇. 电力大数据平台研究与设计[J]. 电力信息与通信技术, 2015, 13(6): 1-7. ZHU Chaoyang, WANG Jiye, DENG Chunyu. Research and design of electric power big data platform[J]. Electric Power Information Technology, 2015, 13(6): 1-7.
[6]李亚楼, 张星, 李勇杰, 等. 交直流混联大电网仿真技术现状及面临挑战[J]. 电力建设, 2015, 36(12): 1-8. LI Yalou, ZHANG Xing, LI Yongjie, et al. Present situation and challenges of AC /DC hybrid large-scale power grid simulation technology[J]. Electric Power Construction, 2015, 36(12): 1-8.
[7]印永华, 郭剑波, 赵建军, 等. 美加“8. 14”大停电事故初步分析以及应吸取的教训[J]. 电网技术, 2003, 27(10): 8-11. YIN Yonghua, GUO Jianbo, ZHAO Jianjun, et al. Preliminary analysis of large scale blackout in interconnected north America power grid on august 14 and lessons to be drawn[J]. Power System Technology, 2003, 27(10): 8-11.
[8]薛禹胜. 时空协调的大停电防御框架(一)从孤立防线到综合防御[J]. 电力系统自动化, 2006, 30(1):8-16. XUE Yusheng. Space-time cooperative framework for defending blackouts, part I: from isolated defense lines to coordinated defending[J]. Automation of Electric Power Systems, 2006, 30(1): 8-16.
[9]薛禹胜. 时空协调的大停电防御框架(二)广域信息、在线量化分析和自适应优化控制[J]. 电力系统自动化, 2006, 30(2):1-10. XUE Yusheng. Space-time cooperative framework for defending blackouts, part II : reliable information, quantitative analyses and adaptive controls[J]. Automation of Electric Power Systems, 2006, 30(2): 1-10.
[10]刘道伟, 张东霞, 孙华东, 等. 时空大数据环境下的大电网稳定态势量化评估与自适应防控体系构建[J]. 中国电机工程学报, 2015, 35(2):268-276. LIU Daowei, ZHANG Dongxia, SUN Huadong, et al. Construction of stability situation quantitative assessment and adaptive control system for large-scale power grid in the spatio-temporal big data environment[J]. Proceedings of the CSEE, 2015, 35(2): 268-276.
[11]胡学浩. 智能电网——未来电网的发展态势[J]. 电网技术, 2009, 33(14):1-5. HU Xuehao. Smart grid—A development trend of future power grid[J]. Power System Technology, 2009, 33(14): 1-5.
[12]宋亚奇, 周国亮, 朱永利. 智能电网大数据处理技术现状与挑战[J]. 电网技术, 2013,37(4): 927-935. SONG Yaqi, ZHOU Guoliang, ZHU Yongli. Present status and challenges of big data processing in smart grid[J]. Power System Technology, 2013, 37(4): 927-935.
[13]彭小圣, 邓迪元, 程时杰, 等. 面向智能电网应用的电力大数据关键技术[J]. 中国电机工程学报, 2015,35(3): 503-511. PENG Xiaosheng, DENG Diyuan, CHENG Shijie, et al. Key technologies of electric power big data and its application prospects in smart grid[J]. Proceedings of the CSEE, 2015,35(3): 503-511.
[14]赵春晖, 吴志力, 姜欣, 等. 跨平台电网规划数据融合与存储模式[J].电力建设, 2015, 36(3): 119-122. ZHAO Chunhui, WU Zhili, JIANG Xin, et al. Cross-Platform data fusion and storage pattern of power grid planning[J]. Electric Power Construction, 2015, 36(3): 119-122.
[15]马天男, 牛东晓, 黄雅莉, 等. 基于Spark平台和多变量L_2-Boosting回归模型的分布式能源系统短期负荷预测[J]. 电网技术, 2016, 40(6): 1642-1649. MA Tiannan, NIU Dongxiao, HUANG Yali, et al. Short-term load forecasting for distributed energy system based on Spark platform and multi-variable L2-boosting regression model[J]. Power System Technology, 2016, 40(6): 1642-1649.
[16]刘成, 牛锐, 范贺明, 等. 基于Spark环境变压器故障并行诊断[J].电力科学与工程, 2016,32(6): 32-37. LIU Cheng, NIU Rui, FAN Heming, et al. Transformer fault diagnosis in parallel based on the Spark platform[J]. Electric Power Science and Engineering, 2016,32(6): 32-37.
[17]王保义, 王冬阳, 张少敏. 基于Spark和IPPSO_LSSVM的短期分布式电力负荷预测算法[J]. 电力自动化设备, 2016, 36(1): 117-122. WANG Baoyi, WANG Dongyang, ZHANG Shaomin. Distributed short-term load forecasting algorithm based on Spark and IPPSO_LSSVM[J]. Electric Power Automation Equipment, 2016, 36(1): 117-122.
[18]孟建良, 刘德超. 一种基于Spark和聚类分析的辨识电力系统不良数据新方法[J]. 电力系统保护与控制, 2016, 44(3): 85-91. MENG Jianliang, LIU Dechao. A new method for identifying bad data of power system based on Spark and clustering analysis[J]. Power System Protection and Control, 2016, 44(3): 85-91.
[19]XIN R. Spark officially sets a new record in large-scale sorting [EB/OL]. (2014-11-05)[2016-07-05].https://databricks. com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html
[20]KREPS J,NARKHEDE N,KAFKA R J: A distributed messaging system for log processing[C]//Proceedings of the NetDB, 2011:1-7.
[21]KALA KARUN A, CHITHARANJAN K. A review on hadoop—HDFS infrastructure extensions[C]// Information & Communication Technologies (ICT), 2013: 132-137.
[22]ZHANG H, CHEN G, OOI B C, et al. In-memory big data management and processing: A survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(7): 1920-1948.
[23]刘兴杰, 岑添云, 郑文书, 等. 基于模糊粗糙集与改进聚类的神经网络风速预测[J]. 中国电机工程学报, 2014, 34(19):3162-3169. LIU Xingjie,CEN Tianyun, ZHENG Wenshu, et al. Neural network wind speed prediction based on fuzzy rough set and improved clustering [J]. Proceedings of the CSEE, 2014, 34(19): 3162-3169.
[24]郭昆亚, 熊雄, 金鹏, 等. 基于模糊聚类-量子粒子群算法的用电特性识别[J]. 电力建设, 2015, 36(8): 84-88. GUO Kunya, XIONG Xiong, JIN Peng, et al. Electricity characteristic recognition study based on fuzzy clustering-quantum particle swarm algorithm[J]. Electric Power Construction, 2015, 36(8): 84-88.
(编辑 张媛媛)
Platform Building for Wide-Area Spatiotemporal Sequences Analysis of Large-Scale Power Grid Based on Spark
YUAN Baochao1, LIU Daowei2, LIU Liping2, WANG Zezhong1
(1. North China Electric Power University, Beijing 102206, China; 2. China Electric Power Research Institute, Beijing 100192, China)
To address the energy internet trends and increasingly complex operating environment, we need to enhance the mining depth and utilization capability of energy internet multi-source data relying on big data technology. First, in the view of the wide-area spatiotemporal sequences data of large power grid, this paper expounds the Spark’s advantages in distributed computing and the goal of big data platform, designs the big data platform architecture of power grid based on Spark, and describes each level of the platform in detail. Secondly, this paper describes the Spark’s advantage in processing the spatiotemporal sequences data. Finally, on the basis of Spark and Hadoop experiment environment, this paper carries out typical clustering algorithm to compare the performance between Spark and Hadoop. The results verifies that Spark has a great advantage in data processing comparing with Hadoop MapReduce, which lays the foundation for the next step research.
energy internet; Spark; spatiotemporal sequences; streaming computing; cluster
国家自然科学基金项目(51207143);国家电网公司科技项目(XT71-15-056)
TM 73;TP 391.9
A
1000-7229(2016)11-0048-07
10.3969/j.issn.1000-7229.2016.11.008
2016-07-05
袁宝超(1990),男,硕士研究生,研究方向为基于广域信息的电网扰动特性及大数据技术;
刘道伟(1977),男,博士,高级工程师,主要研究方向为响应式大电网稳定态势量化评估与自适应控制;
刘丽平(1964),女,硕士研究生,教授级高工,主要研究方向为电力系统自动化;
王泽忠(1960),男,教授,博士生导师,研究方向为电力系统电磁兼容和电磁场数值计算。
Project supported by National Natural Science Foundation of China(51207143)
猜你喜欢
新疆钢铁(2021年1期)2021-10-14
矿产勘查(2021年3期)2021-07-20
北京大学学报(自然科学版)(2021年3期)2021-07-16
军民两用技术与产品(2021年10期)2021-03-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
航天工业管理(2019年11期)2019-04-20
中国交通信息化(2018年12期)2018-03-21
能源(2017年9期)2017-10-18
航天返回与遥感(2014年1期)2014-07-31
