
一种改进高斯核度量的HEC算法在变压器故障诊断中的应用
2017-01-10 01:31:18李中胜刘林
广东电力 2016年12期
李中胜,刘林
(1. 福建水利电力职业技术学院 电气工程系,福建 永安 366000;2. 广东电网有限责任公司佛山供电局,广东 佛山 528000)
一种改进高斯核度量的HEC算法在变压器故障诊断中的应用
李中胜1,刘林2
(1. 福建水利电力职业技术学院 电气工程系,福建 永安 366000;2. 广东电网有限责任公司佛山供电局,广东 佛山 528000)
针对传统超球型聚类算法难以解决变压器故障诊断问题的特性,使用一种改进的高斯核的超椭球聚类 (hyper-ellipsoidal clustering,HEC)算法,并将其解释为寻找体积和密度都紧凑的椭球分簇,该算法能够有效地处理形状为椭球、大小不同和密度不同的分簇。在模拟数据集上的仿真实验表明所提算法在聚类结果和性能上优于K-Means算法、模糊C-Means算法和混合高斯模型期望最大化算法,从而验证了该提算法在处理椭球形或复杂形状数据集聚类时的可行性和有效性;同时将该算法应用在基于变压器油中溶解气体(dissolved gas-in-oil analysis,DGA)的变压器故障诊断中,验证了该方法更高的故障诊断准确度。
数据聚类;超椭球聚类;高斯核度量;变压器;油中溶解气体;故障诊断
聚类算法在设备故障诊断等领域都有广泛的应用,但目前仍没有一种能够处理所有聚类问题的最优算法。传统的聚类算法如K-Means、混合高斯模型期望最大化(gaussian mixture model-expectation maximization,GMM-EM)、模糊C-Means等[1],都是基于最小化簇内样本点的欧氏距离和的通用聚类准则。欧氏距离只考虑各类别样本均值特征,得到的是超球型聚类结果,即在不同的方向上相似性尺度一致。而大多数情况下,同类样本的分布是凸的,且为超椭球型分布[2]。若使用超球型的聚类往往不得不增加类别数来获得更好的训练结果,但如此就会对学习的整体效果产生影响。为解决上述问题,学者提出了各种超椭球聚类(hyper-ellipsoidal clustering,HEC)[3-14]算法,这些算法通常使用马氏距离作为距离度量来建立椭球分簇。
现有的HEC算法主要存在以下问题:过高的计算复杂度;当分簇包含少量样本点时,协方差矩阵可能是奇异的。为了解决上述问题,文献[3-5]提出基于改进马氏距离和伪协方差矩阵的HEC算法,但是这些算法的计算复杂度仍然很高。另一方面,文献 [8-10] 通过近似分簇体积,即找到最小体积椭球(minimum-volume ellipsoids,MVE),取代了协方差矩阵的计算,部分克服了以上的不足。
本文根据一般数据聚类问题特性,将之描述为寻找体积和密度都紧凑的椭球分簇,据此提出的基于改进高斯核度量的HEC算法,旨在解决既有HEC算法的时间、空间复杂度过高,以及寻找MVE过程复杂的问题。改进算法通过Khachiyan的快速近似算法来寻找MVE,在聚类精度与算法的时间、空间复杂度上取得了良好折中,并对不同尺寸和密度的椭球有效处理。基于油中溶解气体(dissolved gas-in-oil analysis,DGA)的变压器故障诊断技术一直是研究的热点,主流的故障诊断方法包括模糊聚类算法[15]、最小二乘法[16]、支持向量机法[17]等。其中,聚类算法受本身特性的限制,存在一定的误分类的可能,为解决该问题,从改良算法入手,本文提出了一类基于改进高斯核度量的HEC数据聚类方法,并用于解决变压器DGA故障诊断问题。
1 椭球和复杂形状聚类

P=arg(P)minEC(P).
(1)

(2)
式中:mk为第k个分簇的均值向量;D(xi,mk)为输入模式与mk之间的距离度量。
为了构造椭球分簇,HEC算法通常采用马氏距离。但在该条件下划分聚类的代价函数是常量[7],为了实现在实际聚类过程中,通用性较好的椭球聚类,使用式(3)改进高斯核作为距离度量:
(3)
式中:Qk为第k个分簇的协方差矩阵;变量α∈[0,1]控制式(3)的第1项和第2项的权重,其中第1项表示马氏距离,第2项与Qk表示的第k个椭圆分簇的容积成正比。则聚类代价函数改写为
(4)
代价函数EC(P)达到最优的必要条件为∂EC(P)/∂mkT=0,通过最小化式(4)得到划分的分簇中心
(5)

(6)
定义:如果改进高斯核式(3)作为式(2)的聚类代价函数的距离度量,则有
(7)
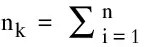
2 改进高斯核度量的HEC算法
2.1 算法原理
改进高斯核度量的HEC算法开始于一个初始的聚类,最终将初始的聚类划分为C个分簇,在此过程中算法迭代查找改进的划分矩阵的分配,分簇体积的权重和不断缩小,直到分簇结果没有进一步可能的改进为止。
计算最小体积椭球(minimumvolumeellipsoid,MVE)(记作dMVE)法所包含样本可以定义为求最大特征向量问题[9-11],以上问题难以通过直接求以下优化问题解决:
(8)
式中:Q为所在椭球分簇的协方差矩阵;i=1,2,…,mk;xc为选择的椭球样本中心向量。
本文通过以下2个步骤来寻找MVE:
a) 通过式(9)近似计算包含矩阵Q特征向量和的目标函数来求解式(8)所示凸优化问题[8,11]:
(9)
b) 使用Khachiyan的快速近似算法[12]寻找dMVE:
(10)
2.2 改进高斯核度量的HEC算法步骤
步骤1:确定分簇数C,从样本集中随机选择C个样本,设定为分簇的中心,记作mk;
步骤2:使用样本与分簇中心mk欧氏距离来确定划分矩阵的初始分配
(11)
式中DEuc(xi,mk)为椭球中样本xi与其他分簇中心mk的欧氏距离。
步骤3:计算新的分簇中心和属于该分簇的样本的数量,即
(12)
式中nk为以mk为中心的新分簇样本数量。
步骤4:使用MVE法近似算法计算伪协方差矩阵Qk。
步骤5:使用式(3)的改进高斯核度量、mk和Qk确定划分矩阵P的一个新的分配
(13)
式中DMGK为最小高斯核度量距离(minimal Gauss kernel,MGK)。
步骤6:如果划分矩阵P没有变化,则算法停止。否则重复步骤3至步骤5。
3 仿真实验
3.1 数值实验描述
为验证本文提出算法的有效性,在模拟数据集和基准评测数据集上进行了仿真实验。在性能评估时,使用误分类率(misclassificationrate,MCR)(记作eMCR)和归一化互信息度(normalizedmutualinformation,NMI)(记作eNMI)作为评价指标,分别定义如下
(14)
(15)
式(14)-(15)中:QE、QA分别为误分类样本数和总样本数;X、Y为两个随机变量;I(X,Y)为互信息;H(X)和H(Y)为X和Y的熵。
3.2 数值实验结果与分析
3.2.1 模拟数据集
为了说明本文所提算法的有效性,在实验中使用了2个模拟数据集。其中,模拟数据集1样本维度2,初始分簇数2,包含一个球型与一椭球型分簇,样本数分别为4、10个,用以验证基于改进高斯核的HEC算法对于不同大小、不同密度和椭圆形分簇的聚类能力,该数据集包含一个圆形的分簇和一个细长椭圆形的分簇。在模拟数据集1上使用式(9)-(10)的2种不同的MVE近似方法所提到的聚类结果是一样的,因此忽略式(9),而使用式(10)的HEC算法在数据集1上的聚类结果如图1所示。
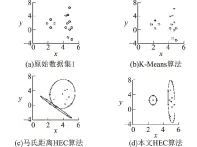
图1 不同算法在模拟数据集1上的聚类结果
从图1(b)可以看出,K-Means算法在模拟数据集1上不能得到正确的聚类;从图1(c)可以看出,马氏HEC算法虽然将样本划分为不同大小的两个椭圆分簇,但当两个分簇距离较近时聚类结果也不准确;图1(d)表明本文提出的HEC算法通过调整α的值来控制改进高斯核的第1项和第2项的权重,从而最小化分簇体积权重和,使得聚类后分簇的紧凑性和密度达到最大。
模拟数据集2样本维度2,初始分簇数2,包含一个高斯分布分簇和一个香蕉形分簇,高斯与香蕉型数据分别为100、28个,用于验证提出的HEC算法的有效性,该算法专门设计用于复杂几何形状样本集的聚类。K-Means算法、马氏距离HEC算法、基于高斯核的HEC算法模拟数据集2上的聚类结果分别如图2的(b)、(c)、(d)所示。

图2 不同算法在模拟数据集2上的聚类结果
从图2可以看出,K-Means算法、马氏HEC算法以及本文提出的HEC算法有相似的聚类结果。可以注意到,虽然聚类结果相似,但是由每个算法所确定的聚类的决策边界仍有很大的不同。与其他算法相比,马氏HEC算法和本文提出的HEC算法有重叠的决策边界。
3.2.2 基准评测数据集
为了评估本文提出算法的性能,在来自UCI的3个基准评测数据集(见表1)上与K-Means算法、模糊C-Means算法、GMM-EM算法和马氏距离MVE-HEC算法进行了比较实验。5种算法在eMCR和eNMI2个评判准则上的比较结果如图3所示,可以看出提出的HEC算法在eMCR和eNMI2个指标上均优于K-Means、模糊C-Means、GMM-EM和马氏距离HEC算法。
表1 来自UCI的基准评测数据集

数据集属性数类别数记录数IRIS43150WINE133178GLASS117214
注:IRIS、WINE、GLASS是来自UCI的基本评测数据集合。

图3 基准评测数据集上的聚类性能比较
3.3 变压器故障诊断实例
本文收集了某省区域内,来自不同厂家,具有不同电压等级与容量的运行变压器DGA数据,剔除明显异常样本与数据后,进行数据归一化预处理,进一步减少数据自身因素对聚类的影响。根据IEC标准,定义变压器运行于正常状态、低能放电、高能放电、低温/中温故障以及高温故障等运行状态,选取了156组变压器的不同故障类型数据,并与K-Means,模糊C-Means,GMM-EM以及马氏HEC算法进行对比,统计结果见表2。
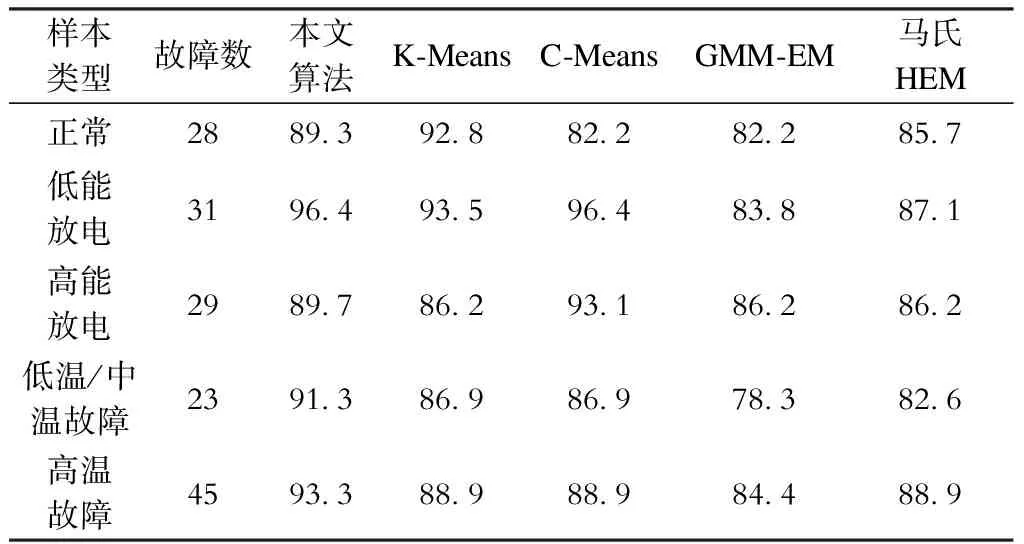
表2 不同算法故障诊断率 %
由于上述数据均经过了归一化处理,算法对数据敏感因素被排除。本文所提出算法在低能放电、低温/中温热故障与高温热故障3个状态诊断中,效果明显好于其他算法。分析样本数据集的聚类过程可以发现,按照MVE进行聚类,算法相对更为合理。但在正常状态聚类中,与K-Means算法相比,聚类错误数增加了3.1%,以及在高能放电样本中,诊断数据比C-Means算法错误率增加了3.4%,反查动态过程中,样本被分类的情况可以发现,本文所提算法的高斯核函数的设定,恰好将部分样本排除在聚类外,表明高斯核函数的相关参数调整,可以提高聚类的相关精度。
由此可见,本文所提出的改进高斯核度量的HEC数据聚类方法,相比传统的K-Means、模糊C-Means、GMM-EM以及马氏HEC算法在较大范围具有良好的适应性,能较好的判断变压器运行状态,并给出具有较高可信度的诊断结果。
4 结束语
本文将基于MVE的HEC算法与改进的高斯核相结合,提出了基于改进的高斯核变量的HEC算法。该算法能够处理不同大小、不同密度和椭球形状的分簇。在模拟数据集和UCI基准评测数据集上的仿真实验,以及基于变压器DGA数据的实例试验表明,提出的算法能够通过建立紧凑的分类边界有效地分离各分簇,无论在聚类能力和性能方面均优于K-Means、模糊C-Means、GMM-EM和马氏距离HEC算法,说明本文所提出算法正确,且具有可行性和有效性。
[1] 金建国. 聚类方法综述[J]. 计算机科学,2014,41(增刊2): 288-293.
JIN Jianguo. Suvey on Clustering Methods [J]. Computer Science,2014,41(S2):288-293.
[2] 刘勇,赵斌,夏绍玮. 模糊超椭球分类算法及其在无约束手写体数字识别中的应用[J]. 清华大学学报(自然科学版),2000,40(9):120-124.
LIU Yong,ZHAO Bin,XIA Shaowei. Self-organizing Network with Fuzzy Hyperellipsoidal Classifying and Its Application in Unconstrained Handwritten Numeral Recognition[J]. Journal of Tsinghua University (Science& Technology),2000,40(9):120-124.
[3] MAO J C,JAIN A K. A Self-organizing Network for Hyper-ellipsoidal Clustering(HEC)[J]. IEEE Transactions on Neural Networks,1996,7(1): 16-29.
[4] 秦玉平,王祎,伦淑娴,等. 基于超椭球支持向量机的兼类文本分类算法[J]. 计算机科学,2013,40(增刊2): 98-100.
QIN Yuping,WANG Yi,LUN Shuxian,et al. Multi-label Text Classification Algorithm Based on Hyper Ellipsoidal SVM[J]. Computer Science,2013,40(S2):98-100.
[5] 梁夷龙,王松,夏绍玮,等. 基于超椭球模糊聚类的人脑磁共振图象分割[J]. 软件学报,1998,9(9):683-689.
LIANG Yilong,WANG Song,XIA Shaowei,et al. Human Brain Magnetic Resonance Image Segmentation Based on Hyperellipsoidal Fuzzy Clustering Algorithm [J]. Journal of Software,1998,9(9): 683-689.
[6] MOSHTAGHI M,RAJASEGARAR S,LECKIE C,et al. An Effient Hyperellipsoidal Clustering Algorithm forResource-constrained Environments[J]. Pattern Recognition,2011,44(9):2197-2209.
[7] 朱峰,宋余庆,陈健美. 基于椭球等高分布混合模型的聚类方法[J]. 江苏大学学报(自然科学版),2011,32(6):701-705.
ZHU Feng,SONG Yuqing,CHEN Jianmei. Clustering Method Based on Elliptical Contoured Mixture Model[J]. Journal of Jiangsu University ( Natural Science Edition),2011,32(6):701-705.
[8] LEE H,PARK J,PARK D. Hyper-ellipsoidal ClusteringAlgorithm Using Linear Matrix Inequality[J]. Journal of Korea Institute Intelligent Systems,2002,12(4):300-305.
[9] MAHESH K O,JAMES B.Scale-invariant Clustering with Minimum Volume Ellipsoids[J]. Computer & Operations Research,2008,35(4): 1017-1029.
[10] SHIODA R,TUNCEL L. Clustering via Minimum Volume Ellipsoids[J]. Computational Optimization and Applications,2007,37(3):247-295.
[11] STEPHEN B,LIEVEN V. Convex Optimization[M]. Cambridge,UK: Cambridge University Press,2004.
[12] TODD M J,YILDIRIM E A. On Khachiyan’s Algorithm for the Computation of Minimum-volume Enclosing Ellipsoids[J]. Discrete Applied Mathematics,2007,155(13):1731-1744.
[13] CAO J Z,CHEN P,ZHENG Y,et al. A Max-flow-based Similarity Measure for Spectral[J]. Etri Journal,2013,35(2):311-320.
[14] JOHN S T,NELLO C. Kernel Methods for Pattern Analysis[M]. Cambridge,UK: Cambridge University Press,2004.
[15] 张冠军,严璋,张仕君. 电力变压器故障诊断中新方法的应用[J]. 高压电器,1998(4):32-34.
ZHANG Guanjun,YAN Zhang,ZHANG Shijun. Application of New Fault Diagnosis Method on Electric Power Transformers [J]. High Voltage Apparatus,1998(4):32-34.
[16] 郑含博,王伟,李晓纲,等. 基于多分类最小二乘支持向量机和改进粒子群优化算法的电力变压器故障诊断方法[J]. 高电压技术,2014,40(11):3424-3429.
ZHENG Hanbo,WANG Wei,LI Xiaogang,et al. Fault Diagnosis Method of Power Transformers Using Multi-class LS-SVM and Improved PSO[J]. High Voltage Engineering,2014,40(11):3424-3429.
[17] 朱永利,尹金良. 组合核相关向量机在电力变压器故障诊断中的应用研究[J]. 中国电机工程学报,2013,33(22):68-75.
ZHU Yongli,YIN Jinliang. Study on Application of Multi-kernel Learning Relevance Vector Machines in Fault Diagnosis of Power Transformers[J]. Proceedings of the CSEE,2013,33(22):68-75.
(编辑 王朋)
Application of Hyper-ellipsoidal Clustering Algorithm Based on Improved Gaussian Kernel Metric in Transformer Fault Diagnosis
LI Zhongsheng1, LIU Lin2
(1.Department of Electric Power Engineering, Fujian College of Water Conservancy and Electric Power, Yong’an, Fujian 366000, China; 2.Foshan Power Supply Bureau of Guangdong Power Grid Co., Ltd., Foshan, Guangdong 528000, China)
In allusion to the problem of traditional hyper sphere clustering algorithm being unable to solve the problem of transformer fault diagnosis, a kind of hyper-ellipsoidal clustering (HEC) algorithm based on improved Gaussian kernel metric is used. This HEC algorithm is illustrated as searching for ellipsoid clusters with compact volume and density, which is proved to be effectively handle with clusters of ellipsoid shape with different sizes and densities. Experiment on simulating dataset indicates the proposed HEC algorithm is prior to K-Means algorithm, fuzzy C-Means algorithm and GMM-EM algorithm, which verifies feasibility and validity of HEC algorithm in processing problems of ellipsoid dataset or complex-shaped dataset. Application of HEC algorithm in transformer fault diagnosis based on dissolved gas-in-oil also proves higher fault diagnosis accuracy of this method.
data clustering; hyper-ellipsoidal clustering; Gaussian kernel metric; transformer; dissolved gas-in-oil; fault diagnosis
2016-09-02
福建省教育厅科技项目(JA15793)
10.3969/j.issn.1007-290X.2016.12.019
TM41
A
1007-290X(2016)12-0104-06
李中胜(1982),男,福建三明人。实验师,工程师,工学学士,从事电力设备高压试验、状态监测与故障诊断方面的研究。
刘林(1986),女,湖南湘乡人。工程师,工学硕士,主要从事电能计量、智能控制系统等方面研究。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
导航定位学报(2022年2期)2022-04-11 05:12:56
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
智能制造(2021年4期)2021-11-04 08:54:44
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
制造技术与机床(2017年9期)2017-11-27 02:14:14
北京航空航天大学学报(2017年3期)2017-11-23 05:14:36
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
