
火力电厂优化配煤系统构建及算法研究
2017-01-09 07:11张威
淮南职业技术学院学报 2016年6期
张 威
(安徽理工大学, 安徽淮南232001)
火力电厂优化配煤系统构建及算法研究
张 威
(安徽理工大学, 安徽淮南232001)
随着我国社会经济的快速发展,能源问题日益突出,在我国各种能源资源中,煤炭资源最为丰富,我国的一次能源消费结构中,煤炭占主导地位,因此,在煤炭资源的利用问题上,发展以提高煤炭利用率和减少污染为宗旨的洁净煤技术是我们在通往未来能源的过渡时期内的切实有效地现实选择;动力配煤作为我国电力行业普遍采用的一种高效净煤技术,可以将不同类别、品质的煤经过筛选、破碎和按比例混合等过程,改变其物理、化学和燃煤特性,使之达到煤质互补、优化产品结构 ,从而达到了减少污染物排放以及提高煤炭资源利用率的目的;主要研究目的在于以优化配煤系统为框架,利用火力电厂优化配煤算法对煤炭资源的使用进行最优选择,分析优化算法的优越性。
算法研究; 动力配煤; 神经网络
1 引言
1.1 课题研究的意义
人类社会经历了近二个世纪的高速发展,主要是依靠了以煤炭等为主的化石燃料为基础的能源利用。随着人口爆炸、资源枯竭等问题日益严重,人们越来越意识到我们不仅需要一种更为高效、清洁的能源利用方式来使用不可再生能源,以保证在找寻到新型、稳定、高效的可再生能源之前人类社会的能源平衡。
煤炭资源种类繁多,品质参差不齐。将优质煤炭作为火力电厂的燃料全部燃烧是一种极大的浪费,在满足电厂锅炉燃烧要求的前提下,把十数甚至是数十种不同的煤炭资源以合适的比例混配再进行燃烧,是对资源的合理化、最大化利用,符合当前社会对能源开发利用的宗旨。而对混配的煤种、数量、比例等因素考虑,不仅决定了配煤的优劣,更关系到火力电厂的安全运行。动力配煤技术作为解决上述问题的技术措施,受到了国家的广泛重视。
1.2 课题研究的主要内容
本文主要目的在于通过查阅资料等方式了解火力电厂优化配煤系统构建及配煤算法,对优化配煤算法的提出、种类、实现方法等进行描述,然后选择一种优化配煤算法进行实例分析,说明优化配煤算法的优越性。
2 火力电厂优化配煤系统构建及配煤算法概述
2.1 数字化煤场系统功能概述
2.1.1 系统构建意义
目前电厂普遍存在实际用煤与设计煤点脱节的现象,有的电厂来煤的煤点多达十几种以上。这一方面导致了煤场煤点多、煤堆摆放混乱、自燃损耗大、管理低效等状况,另一方面由于不同燃煤来源的煤质特性差别较明显,这必然对锅炉安全运行产生一定影响。为了解决以往煤场管理中不直观、存煤数据不准确、报表滞后、参烧配煤不科学等问题,采用数字化煤场管理系统可以针对煤场自燃损耗大、煤堆摆放混乱、管理低效等状况进行信息化、规范化处理,对煤场实行分区堆放,并且配合企业内部的输煤系统,对煤场实现数字化管理。系统实时采集煤场相关数据,对煤场的煤质特性和存煤分布通过立体图形具体的体现出来,通过该系统不仅可以直观详细的掌握煤场状况,有效的调度各种煤质的存煤,最大限度的降低存煤的挥发浪费、起到节能降耗的作用。而且在对实际来煤进行混合配比掺烧时,使锅炉燃烧时更加稳定,且降低燃煤成本。在确定配煤比例时,如果仅用人工进行计算量太大,很难达到使配煤成本价最低的优化配方,而采用系统行进配煤方案的优化能够充分发挥计算速度快的优点,在短时间内找到能使电厂配煤成本最低,经济效益最好的优化配方。通过配煤参烧更可以大幅降低发电成本。
2.1.2 系统框架
数字化煤场系统总体框架如图1所示,数字化煤场功能体系如图2所示。
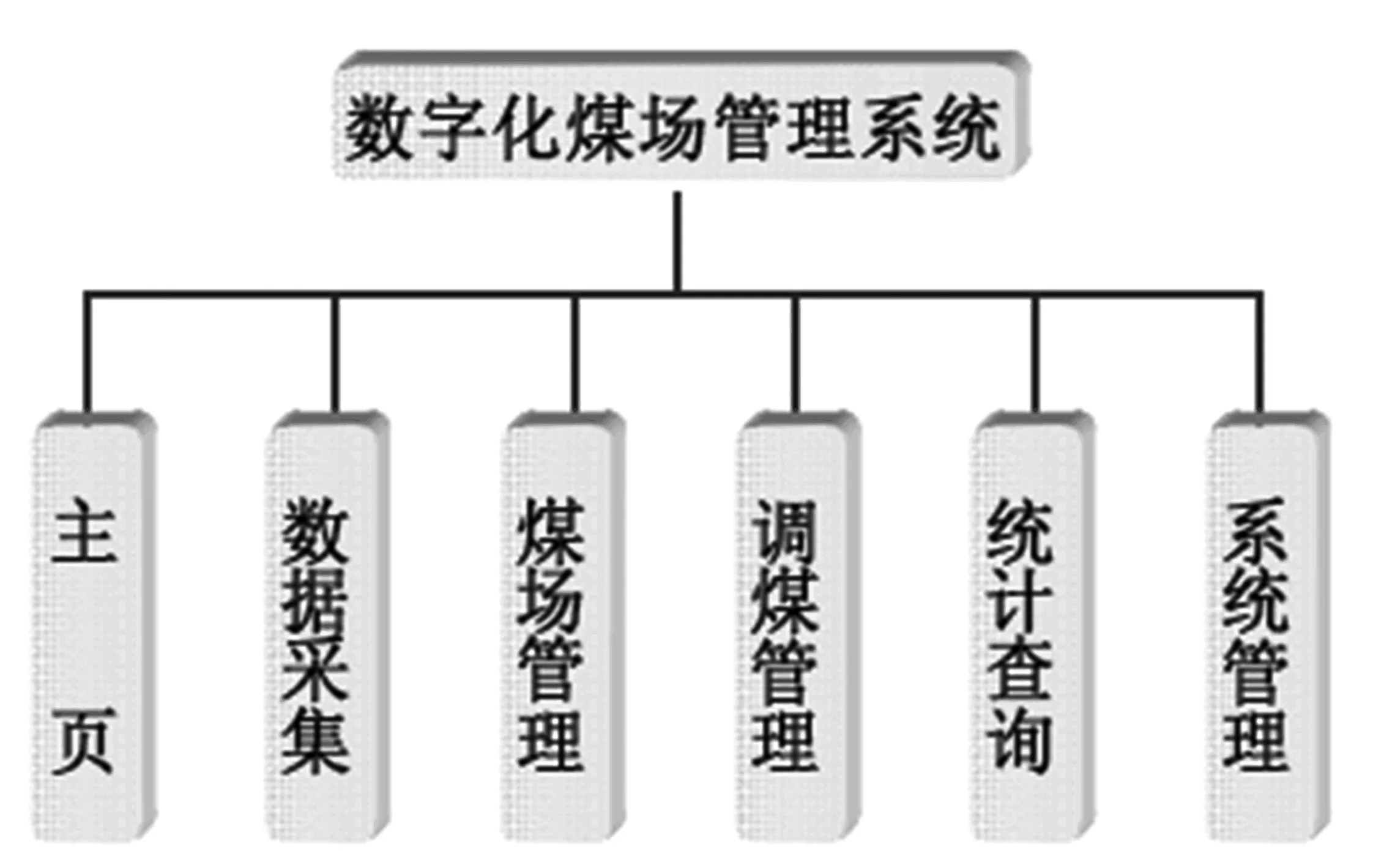
图1 数字化煤场系统
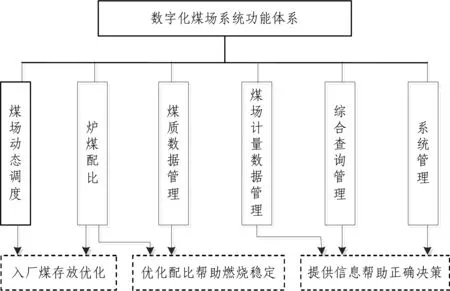
图2 数字化煤场系统功能体系
2.1.3 系统实现功能
煤场动态调度。煤场采用分区管理的方式对不同来煤进行管理。遵循煤的分区堆放原则,即煤的组堆应最大限度地减少燃煤在存储过程中的损耗。 不同品种的煤要分别组堆; 指标相近的煤尽量组堆,进厂煤将根据历史来煤预测当日来煤的煤质情况,分别存放到相应的煤区或直接上仓,等煤质分析报告;对高挥发份,高含硫煤的组堆,由于这类煤最易自燃,建议堆放在单独的煤场一角; 对高灰,高硫,低灰熔融性的特殊煤,由于无法单独燃用,会选在煤场某一特定区域单独堆放,等待掺烧。
煤场数据计量管理。本模块通过燃运部门录入的煤炭到达信息、以及系统获取的入厂煤翻车机衡数据和入炉煤皮带秤数据,以图形和表格的形式动态反映煤场进出煤和存煤的实际情况,并对煤场存煤数据进行校核。系统包含以下功能:煤炭到达数据录入:由燃运部门将来煤的车次、煤点等相关数据录入系统;入厂煤翻车机衡数据导入: 系统自动调用翻车机衡工作站中入厂翻车机衡数据,经转换后导入本系统数据库中;入炉煤皮带秤数据导入: 系统自动调用皮带秤工作站中入炉煤皮带秤数据,经转换后倒入本系统数据库中;煤场存煤量数据校核:根据入厂煤、入炉煤实际数据间接校核煤场存煤量;煤场存煤预警:通过实时计算煤场存煤的煤质和煤量,实时进行煤场存煤预警。
综合管理。入厂煤综合查询:以图表形式综合显示入厂煤的煤点、存量、存放天数、煤质等数据;入炉煤综合查询:以图表形式综合显示入炉煤的煤点、使用量、使用时间、煤质、与入厂煤关联数据等数据;报表数据查询和报表生成:根据用户要求查询制作报表所需相关数据,并自动生成报表;煤场管理经济数据查询:根据用户要求,制作查询报表,显示煤场存煤价值、盈吨情况、月度亏吨亏卡情况等数据;盘点报告:根据实测比重、实测体积,以及月底的暂存煤量,损耗煤量,水分差调整煤量,计算自动生成月末煤场盘点报告。
3 火力电厂优化配煤算法实例分析
在火力电厂优化配煤系统构建的过程中,最重要的是火力电厂优化配煤算法的使用,灵活运用优化算法以实现整个系统的最优化是每个火力电厂优化系统的主要任务,下面本文将对火力电厂优化配煤算法进行研究分析。通过阅读资料易知,研究优化配煤算法之前必须了解算法的因子,即煤种的性质。
3.1 混煤煤质特性介绍
首先需要对15种实验单煤做发热量测定和工业分析,所得数据见表1。
然后对15种煤种进行混合实验,在单煤种中取3种单煤,按不同的比例混合配成45种混煤,并对45种混煤进行编号,混配方案见表2。
由表2、表3易知, Mad、 Oad、Sad、Cad等参数通过线性加权获得的误差均较大,Cad的线性加权误差较小而Mad、Vad的线性加权的平均误差最大。与混煤的实际参数相比误差过大。若火力电厂的混煤方案采用该线性加权法进行,有可能对电厂的热力生产产生较大的扰动,影响其安全稳定。故而我们需要采用其他的数学方法决定混煤方案。
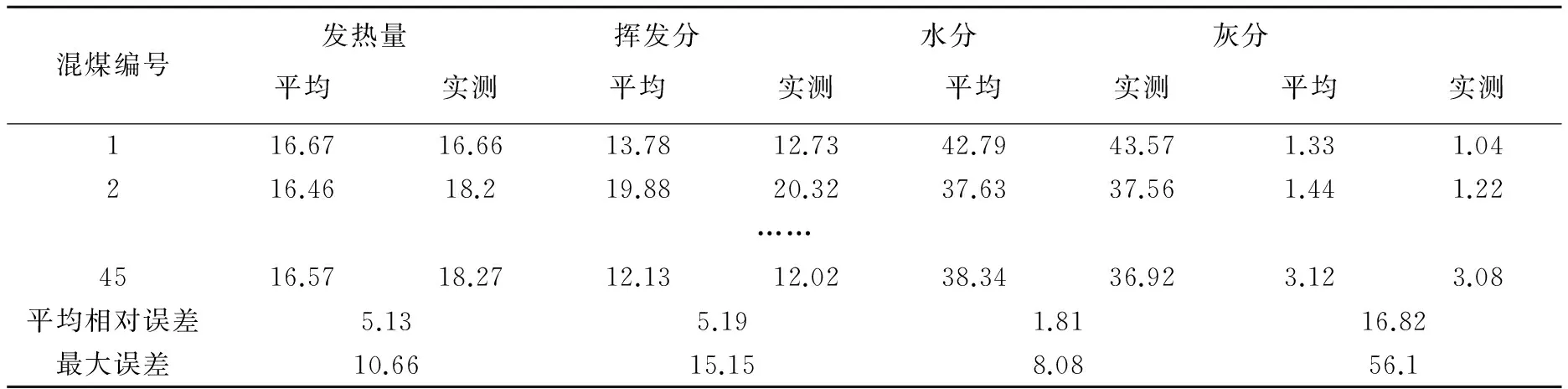
表2 混煤煤样的发热量、挥发分、水分、灰分预测与实测简表
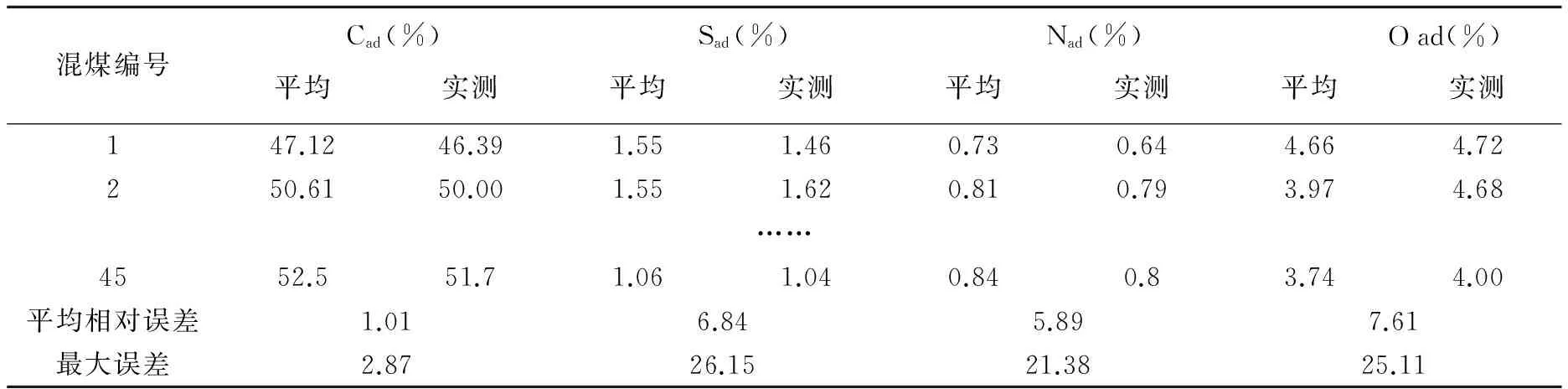
表3 混煤煤样的Cad、Sad、Nad、Oad预测与实测简表
3.2 GRNN及其预测算法在煤质预测中的应用
3.2.1 基于GRNN的混煤煤质预测模型描述
混煤煤质预测模型是一个包括四层神经元(模式层、输入层、输出层与求和层)的GRNN网络模型,如下图所示。为简单介绍以输入输出均是单维列的向量来说明模型的作用。令网络的输入变量为X=[x1,…,xm]T,则输出变量为Y=[y1,…ym]T。
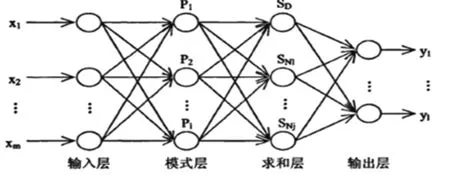
图3
其中:m为输入层的维数,n为模式层神经元数,传递函数:
式中X为输出变量,Xi为样本,神经元i的输出为X预期对应的样本Xi之间的Euclid距离平方的指数形式:
进行计算求和时,在求和层中任一神经元对模式层输出进行求和时的连接权值为1,传递函数为
进行加权求和时,求和层的第j个神经元与模式层的第i个神经元的连接权值为Yi中的第j个元素 yij,传递函数为:(L是输出向量维数)。
每个输出层的神经元讲求和层的输出相除,可得:
利用GRNN理论知识,建立了混煤的煤质预测模型,本文研究的模型以上述45种单煤的任意3种单煤及其2种单煤的对应比例为输入,模型可预测该混煤的煤质特性(化学参数等)。
3.3 混煤煤质预测结果
3.3.1 混煤煤质预测模型性能分析及发热量预测结果
诸多因素都可以影响我们根据GRNN网络原理建立的混煤煤质预测模型的最终预测性能,针对上述情况,我们以低位发热量为例子说明预测模型的性能。
参考数据的影响。预测模型可以选取多种参考数据,能量函数越高模型的预测偏差越大。GRNN预测的能量函数E取平均相对误差,即:
其中yi为实验值,n为训练样本数,outi为网络预测值。模型参考数据不同时混煤Q.net.ar预测结果见表4。

表4 不同输入时混煤的低位发热量预测结果
由表4易知,采用GRNN预测所得的能量函数均很低,性能较好。
训练样本数量的影响。由表5可知,增大GRNN模型输入的训练样本数量对模型的预测性能改变不是单纯的线性关系。它既导致了训练样本能量函数的增加,又导致了检验样本能量函数的下降。根据GRNN预测理论,训练样本数据的增多可以改善模型的预测性能。根据本文采集的混煤数据,该模型采用的训练样本数量可定为40。

表5 训练样本数量不同时混煤低位发热量的预测结果
σ的影响。对网络的影响是多方面的,它既影响网络预测与实际值得偏差夹逼速度,又影响整个模型的物理预测误差。在不同的训练样本及检验样本数的情况下,平滑因子的逼近能力与物理减少误差的能力存在完全不同的变化方式,如下图4、图5所示。

图4 GRNN网络的逼近误差图
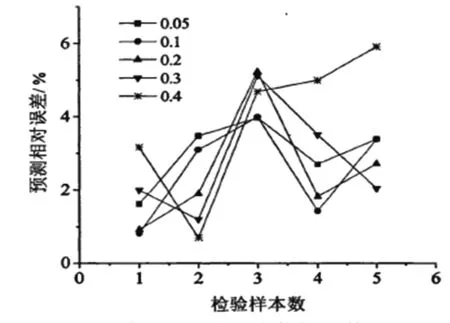
图5 GRNN网络的预测误差图
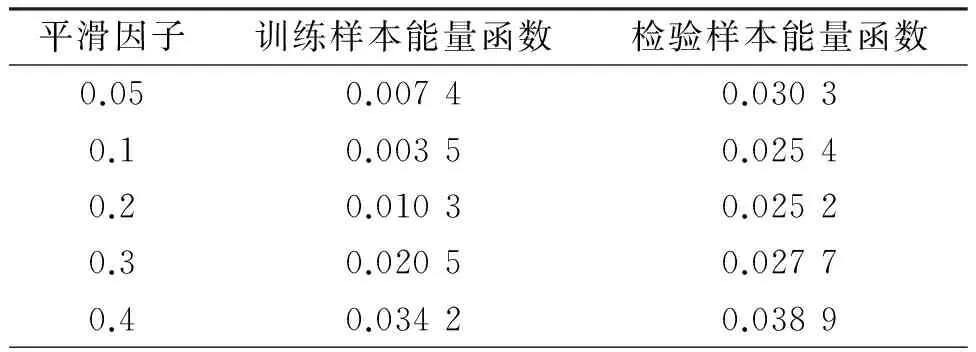
σ取不同的值时样本的能量函数存在一定的线性变化规律见表5。根据神经网络理论综合考虑模型的平滑性与逼近性能,本文确定模型中的平滑因子为0.2。
表5 网络选用不同的平滑因子时混煤的Q.net.ar预测结果
平滑因子训练样本能量函数检验样本能量函数0.050.00740.03030.10.00350.02540.20.01030.02520.30.02050.02770.40.03420.0389
在确定了模型的平滑因子与输入参数后进行的低位发热量预测值如见表6。
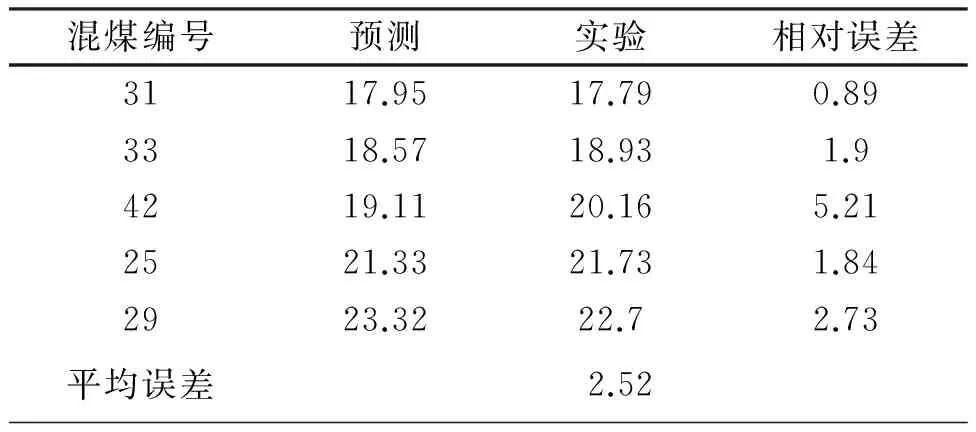
表6 Q.net.ar的检验样本预测
混煤的低位发热量由GRNN模型预测的平均相对误差仅为2.52 %,而线型加权方法获得的数据平均相对误差与之相较偏大了2.61 %,两者相较,GRNN的预测准确度得到了很大的改善。
4 结论与建议
当今社会,环境问题愈发严苛,低碳生产、清洁能源的开发利用是我国能源高效利用、保证社会可持续发展的重要手段。煤炭一直是我国乃至人类社会发展进步的重要能源,作为洁净煤技术重要分支的动力配煤技术,既满足中国当前的国情需要,又为环保交出了一份社会满意的答卷。
本文采用了15个单煤种和45种混煤的低位发热量数据,在基本数据获取的基础上建立了混煤煤质预测模型,利用了GRNN理论对模型进行设计、求解、优化,对混煤的煤质进行了较为准确的预测。本文的研究结论如下:
通过采集的单煤煤质数据与混煤煤质数据可知,单煤掺混燃用时化学性质的改变不是简单的线性关系,需要建立更精密的模型进行预测。
建立了混煤预测模型,并对混煤的低位发热量进行了相关的预测,其预测结果的误差与线性加权比较有了明显降低,成功的解决了混煤煤质特性采用线性加权方法预测结果偏差大的问题。
本文所涉及到的混煤煤质特性的预测模型建立、预测等研究只是动力配煤研究的一小方面,想要在实际生产中灵活运用动力配煤技术,我们还需要进行更多的理论研究与实地实践。结合本文得出的部分结论,对今后开展有关动力配煤技术的研究提出以下建议:
单煤的数量限制了本文基于GRNN建立的配煤模型预测的精度,建议在实验条件允许的前提下,尽量增加单煤的数量,以期得到更为准确的预测模型,同样更有力的证明神经网络等优化算法的优越性。
在根据所采集单煤以及混煤数据获得优化后的混煤配比模型后,可以根据该模型在电厂进行实际混烧,实践证明优化算法确实提高了入炉煤炭的热效率,有效的提高了火力电厂的资源利用率。
[1] 桂祥友,马云东.非线性优化理论在动力配煤中的应用[J].中国矿业, 2005, 14 (6): 49-51.
[2] Jhih Shyang Shih,H.Christopher Frey.Coal blending optimization under uncertainty [J].European Journal of Operational Research,1995(83): 452-465.
[3] M Chakraborty,M K Chandra. Multicriteria decision making for optimal blending for beneficiation of coal:a fuzzy programming approach[J].The international Journal of Management Science,2005(33):413-418.
[4] Huang G H,Baetz B W,Patry G G,et al.A grey dynamic programming for waste management planning under uncertainty [J].Journal of Urban Planning and Development,1994(9):132-156.
[5] 董平,陈彦杰,王鹏.基于Elman网络的动力配煤煤质预测模型的研究[J].洁净煤技术, 2006, 12(4) : 55-58.
[6] 范杜平,薛永飞,周英彪.动力配煤概况分析及预测[J].电站系统工程, 2006, 22(4) : 13-14.
[7] 许建豪,张忠孝,潘金荣.动力配煤的研究与计算[J].选煤技术, 2005(3):5-8.
[8] 郎小燕,王默玉,刘林,等.基于ORACLE 的入炉配煤优化问题的实现[J].现代电力,2005,22(5):66-69.
[9] 范华挺.电厂配煤技术原则及煤质特性参数的计算[J].煤质技术,2006( 5):15-17.
[10]LIUS1 A Modified Low speed Balancing Method for Flexible Rotors Based on Holospectrum[J].Mechanical Systems and Signal Processing,2007(21):348-364.
[11]曲景魁,何京东,何志强.动力配煤主要煤质指标可加性的研究[J].黑龙江矿业学院学报,2000(3): 17-19.
[12]张增强,谷会东.Delphi 6.0实用开发指南[M].北京:电子工业出版社,2001.
[13]彭树婷.沙角A电厂煤场动态查询系统的开发应用[J].广东电力,2008,21(7):42-46.
[14]胡宏伟,杨建国.电厂燃料管理及煤质优化系统的开发及应用[J].热力发电,2004(4):70-72.
[15]曾畅,余为泽,张振胜,等.沙角C电厂燃料部点检系统的开发与应用[J].中国电力,2009 ,54 (1):85-88.
[16]刘泽常,卢宗华,陈怀珍,等.动力配煤的煤质指标与各单煤配比的结构关系[J].煤炭科学技术,2004,32( 7):62-64.
[17]候静,赵益坤.动力配煤的数学模型及优化解[J].太原理工大学学报,2006,37(4):486-488.
[18]韩力群.人工神经网络教程[M].北京:北京邮电大学出版社,2006.
[19]周开利,康耀红.神经网络模型及其MATLAB仿真程序设计[M].北京:清华大学出版社,2005.
[20]阮伟,张伟宁,周俊虎,等.电厂优化配煤多目标机会约束数学模型的建立[J].动力工程,2001,21 (1):1090-1092.
[21]曾琴琴.火电厂配煤优化方法研究[M].哈尔滨:哈尔滨工业大学,2006.
Construction and Algorithm of Coal Blending Optimization System in Coal-fired Power Plant
ZHANG Wei
(Anhui University of Science & Technology, HuainanAnhui 232001)
With the rapid development of China's economy, energy issues have become increasingly prominent. Coal is the most abundant resource in our country and plays the primary role in our energy consumption structure. Thus, the development of clean coal technology which aims at increasing utilization of coal resources and reducing pollution is an effective and practical choice in the transitional period to the future energy.The main purpose of this paper is to optimize coal blending system, choose the coal resource optimally by using coal blending optimization algorithm of the coal-fired power plant, and analyze the advantages of optimization algorithm.
System Construction; Algorithm; Power Coal Blending; Simulated Annealing; Neural network
2016-11-01
张威(1990-),男,安徽淮南人,硕士研究生,研究方向为计算机应用技术,电话:18755465353。
TM621.6;TD94
A
1671-4733(2016)06-0014-06
10.3969/j.issn.1671-4733.2016.06.005
猜你喜欢
选煤技术(2022年3期)2022-08-20
燃烧科学与技术(2022年1期)2022-03-02
价值工程(2018年36期)2018-01-25
动漫星空(兴趣百科)(2017年3期)2017-11-07
科技创新导报(2017年19期)2017-09-13
电站辅机(2016年4期)2016-05-17
中国煤层气(2015年6期)2015-08-22
现代企业(2015年7期)2015-02-28
现代企业(2015年3期)2015-02-28
中国工程咨询(2015年6期)2015-02-16
