
通过距离匹配法对224团骏枣与10团骏枣聚类分析的研究
2016-12-29 05:04:43李伟伟孔维楠罗雪宁代希君罗华平
塔里木大学学报 2016年4期
李伟伟 孔维楠 罗雪宁 代希君 罗华平,2,3*
(1 塔里木大学机械电气化工程学院, 新疆 阿拉尔 843300)(2 新疆维吾尔自治区普通高等学校现代农业工程重点实验室, 新疆 阿拉尔 843300)(3 南疆农业农机化研究中心, 新疆 阿拉尔 843300)
通过距离匹配法对224团骏枣与10团骏枣聚类分析的研究
李伟伟1孔维楠1罗雪宁1代希君1罗华平1,2,3*
(1 塔里木大学机械电气化工程学院, 新疆 阿拉尔 843300)(2 新疆维吾尔自治区普通高等学校现代农业工程重点实验室, 新疆 阿拉尔 843300)(3 南疆农业农机化研究中心, 新疆 阿拉尔 843300)
和田224团骏枣与阿克苏10团骏枣在价格上有明显的差别,快速准确的识别二者有很大的实际意义。应用距离匹配法对和田224团骏枣与阿克苏10团骏枣进行聚类分析,预处理方法采用归一化,基线校正和Savitzky-Golay卷积求导法(13点平滑,3点差分宽度),并利用马氏距离剔除异常样本。研究结果表明:和田224团骏枣与阿克苏10团骏枣在水分含量、总糖含量和总酸含量上有明显区别。预测效果最好的是总酸波段的聚类分析模型,其次是水分波段的聚类分析模型,最后是总糖波段的聚类分析模型。在分类效果上,聚类分析模型更适用阿克苏10团骏枣,所以阿克苏10团骏枣比和田224团骏枣效果好。结论:利用距离匹配法对和田骏枣与阿克苏骏枣进行产地的鉴别是可行的,该法对考察南疆红枣的产地鉴别有一定的参考价值。
距离匹配法; 聚类分析; Savitzky-Golay卷积求导法; 马氏距离
红枣营养丰富,具有药用和食用价值。不同地区的红枣在水分、总糖、总酸的含量上有区别,在价格方面也有明显的差别。和田骏枣在价格上比阿克苏骏枣高出许多,有些不良商贩会用阿克苏骏枣冒充和田骏枣,进而在价格上谋利。因此,快速准确的分辨和田骏枣和阿克苏骏枣对于经销商十分重要。
和田地区的地理坐标位于东经79°50′至79°56’,北纬36°59’至37°14’。南越昆仑山抵藏北高原,北部深入塔克拉玛干腹地。阿克苏地区的地理坐标位于东经78°03’至84°07’,北纬39°30’至42°41’。位于新疆维吾尔自治区天山南麓,塔里木盆地北缘[1]。根据新疆统计局的统计年鉴近7年的数据分析:和田地区的年平均气温比阿克苏地区高2. 56 ℃,和田地区的日照时数比阿克苏地区少133. 6小时,但在从红枣生长到成熟日照时数基本相差无几。和田地区的昼夜温差与阿克苏地区相差不大。和田地区的有效积温为4 200 ℃,阿克苏地区的有效积温为3 800 ℃~4 200 ℃。地理位置、平均气温、日照时数、昼夜温差、有效积温对于红枣的生长与糖分积累起着至关重要的作用。
近红外光谱技术作为一种无损、快速的检测方法,已被广泛用于分析复杂的化合物,如石油、农产品和中药材等[2-4]。聚类分析是一种无管理模式识别方法,常用于目标观测对象的分类,即利用表征观测对象的一组变量对目标进行分类[5]。本文采用距离匹配法对二者进行聚类分析,从而能够快速高效的区别和田224团骏枣与阿克苏10团骏枣。距离匹配法是计算光谱到每个类别中心点的距离,用来判别一个未知材料到两个或更多已知材料类别的匹配程度。在区别含有相同成分但含量不同的材料时,距离匹配算法十分适合。在这种分析中,每个类别的标准光谱都非常相似。主要的不同仅仅出现在少数几个关键波段的峰强度上。距离匹配方法的原理,建模过程中,软件为每个类别计算出一条平均光谱和一条标准偏差光谱。用此法给一个未知样品的光谱进行类别划分时,针对每个类别,软件将未知样品的光谱减去该类别的平均光谱得到一条残差光谱,再除以相应的标准偏差光谱,得到一条新光谱(相减的步骤得到了两条光谱间在各个波长点的差异,除的步骤得到每个差异点所占的权重)然后计算残差光谱中超过距离匹配限值的波长点所占的百分比。
1 材料与方法
1.1 材料
和田224团白熟期骏枣和阿克苏10团白熟期骏枣,样品数为和田骏枣与阿克苏骏枣各60颗。样品的采集方式采用隔行隔排采集,保证样品的相对独立性。红枣置于自封袋内,防止水分的散失,及时带回实验室放入冷库。
1.2 仪器
美国赛默飞世尔科技生产的Antaris Ⅱ FT-NIR型光谱仪。
1.3 方法
1.3.1 工作流程
1.3.1.1 采集和田224团白熟期骏枣与阿克苏10团白熟期骏枣的正反面近红外光谱图;
1.3.1.2 采用TQ分析软件对谱图进行预处理;
1.3.1.3 建立相应的水分、总糖和总酸波段的聚类分析模型;
1.3.1.4 对未知(待测)样品进行检测。
1.3.2 近红外光谱采集及预处理过程
1.3.2.1 仪器设备以及参数设置
美国赛默飞世尔科技生产的Antaris Ⅱ FT-NIR型光谱仪,以仪器内部空气为背景,测量范围4 000~10 000 cm-1,采样点数为1 557点,每张光谱扫描次数32次,分辨率为8 cm-1,仪器使用InGaAs检测器,化学计量学分析软件为仪器自带的TQ软件。近红外数据处理和统计分析软件用的是MATLAB7.11(美国Mathworks)[6]。
1.3.2.2 样品的选择
选择和田224团白熟期骏枣与阿克苏10团白熟期骏枣, 大小均匀分布和颜色深浅不一的有代表性的样品各60颗。其中90颗作为校正集(和田224团骏枣45颗、阿克苏10团骏枣45颗),30颗作为验证集(和田骏枣15颗、阿克苏骏枣15颗)。
1.3.2.3 近红外光谱的采集
光谱采集前,先将红枣从冷库中取出放入室内12个小时,室内温度在23 ℃~26 ℃之间,相对湿度25%~30%。其次将所测样品置于Antaris Ⅱ FT-NIR型光谱仪测试点处,红枣的赤道部位A、B面各测定光谱一次,保证实验的准确性。原始光谱如图1。
1.3.2.4 预处理过程
主要进行归一化处理(图2),基线校正(图3)和 Savitzky-Golay卷积求导法(图4)的预处理。
归一化处理:用来校正由微小光程差异引起的光谱变化;
基线校正:可以消除基线漂移,进而减小对后续计算工作的影响;
导数:可以有效的消除基线和其他背景的干扰,分辨重叠峰,提高分辨率和灵敏度;
Savitzky-Golay卷积:用来分辨率高、波长采样点多或稀疏波长采样点的光谱[7]。

图1 原始光谱

图2 归一化处理

图3 基线校正
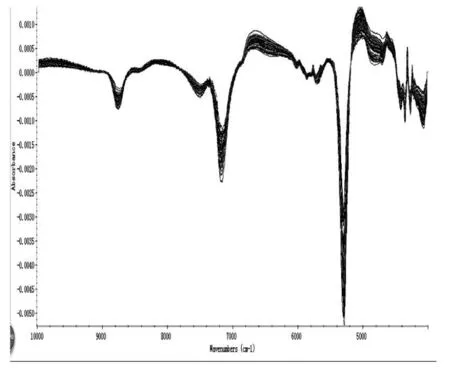
图4 Savitzky-Golay卷积求导法
1.3.2.5 异常样本的剔除
应用马氏距离法对异常样本的剔除(主成分数为5),剔除效果如图5。
马氏距离用来界外样本的识别,其公式为
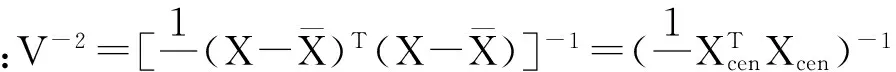
马氏距离考虑了同一类中相同特征变量的变化(方差),以及不同特征变量间的变化(协方差)。它考虑了样本的分布,在识别模型界外样品等方面发挥着重要的作用[7]。
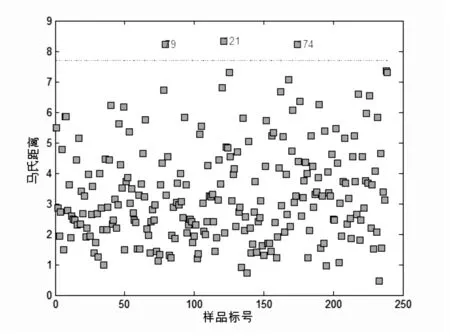
图5 马氏距离剔除
2 结果分析
依次经过归一化处理、基线校正、Savitzky-Golay卷积求导法预处理及马氏距离异常样本剔除法后,运用TQ软件的距离匹配法进行聚类分析。模型识别性能的评价用正确分类率来表示。
在实践中,大量数据分析费时耗力,选择适当的光谱区间可以获得满意的结果。最近,理论和实践证明光谱区间选择能显著提高模型的性能[8]。所以合适的波长变量选择对于提高模型预测至关重要。
聚类分析模型主要是针对和田224团白熟期骏枣与阿克苏10团白熟期骏枣建立的混合模型,其中两类红枣的分类标准是计算两类红枣的马氏距离,以距离较近的进行归类。两地红枣在水分、总糖、总酸含量上的差异造就二者近红外光谱和马氏距离的差异,聚类分析模型计算二者的马氏距离,通过马氏距离进行归类,从而可以反映红枣水分、总糖、总酸的成分差异。
2.1 建立水分波段的聚类分析模型
液态水由于氢键的缔合,其吸收峰都为宽谱带。O-H伸缩振动的一级倍频和二级倍频吸收分别出现在6 944 cm-1(1 440 nm)和10 420 cm-1(960 nm)附近。其合频吸收谱带主要有两个,较强的在5 155 cm-1(1 940 nm),较弱的在8 197 cm-1(1 220 nm)附近。这些特征吸收十分有用,例如农产品、食品和药品中的水分含量都可以通过这些特征吸收来测定[7]。
因此,根据Antaris Ⅱ FT-NIR型光谱仪的测试范围的界定,水分波段的聚类分析模型波长变量的选择是5 155 cm-1(1 940 nm),6 944 cm-1(1 440 nm),8 197 cm-1(1 220 nm)。通过TQ软件建立的水分模型如图6所示。

图6 水分波段的聚类分析模型
2.2 建立总糖波段的聚类分析模型
美国农业部通过分析得出的常见的农产品各成分近红外光谱吸收特征波长,根据这些特征波长可以大致判断含有该基团的化合物相关的波长区域。其中糖类的吸收特征波长为838 nm,888 nm,913 nm,978 nm,1 005 nm,1 380 nm,1 437 nm,1 687 nm,2 080 nm,2 202 nm,2 275 nm,2 320 nm。其中978 nm,1 380 nm,2 275 nm和2 320 nm为一阶微分光谱,2 080 nm为二阶微分光谱,其他的为原始光谱[6]。
因此,根据Antaris Ⅱ FT-NIR型光谱仪的测试范围和之前的预处理方法采用的Savitzky-Golay卷积求导法(一阶微分求导)。总糖波段的聚类分析模型波长变量的选择为4 310 cm-1(2 320 nm),4 396 cm-1(2 275 nm),7 246 cm-1(1 380 nm)。通过TQ软件建立的总糖模型如图7所示。

图7 总糖波段的聚类分析模型
2.3 建立总酸波段的聚类分析模型
通过相关系数法,SPA,UVE,SiPLS,SiPLS+GA这几种不同的波长选择方法对骏枣样品的建模精度和预测能力的影响。研究发现采用无信息变量消除法(UVE)选择波长的效果最佳,所以对于红枣总酸的波长采用无信息变量消除法(UVE)来筛选波长。由此选出的360个波长对应的区间分别是:1 000 nm~1 113 nm、1 381 nm~1 523 nm、1 567 nm~1 672 nm[6]。
因此,总酸模型波长变量的选择为5 981 cm-1~6 382 cm-1(1 567 nm~1 672 nm),6 566 cm-1~7 241 cm-1(1 381 nm~1 523 nm),8 985 cm-1~10 000 cm-1(1 000 nm~1 113 nm)。通过TQ软件建立的总酸模型如图8所示。

图8 总酸波段的聚类分析模型
2.4 未知(待测)的检测
应用以上模型对未知(待测)样本进行检测,分析结果如表1。

表1 各模型聚类分析的结果
3 结语
3.1 和田224团白熟期骏枣与阿克苏10团白熟期骏枣在水分含量、总糖含量和总酸含量上有明显的差别。预测效果最好的是总酸波段的聚类分析模型,其次是水分波段的聚类分析模型,最后是总糖波段的聚类分析模型。在正确分类率上,聚类分析模型更适用阿克苏10团骏枣,所以阿克苏10团骏枣比和田224团骏枣分类效果好。
3.2 利用距离匹配法对和田骏枣与阿克苏骏枣进行产地的鉴别是可行的,但由于不同时期(脆熟期和完熟期)不同品种(灰枣、冬枣等)的红枣在水分、总糖和总酸上含量差别很大,所以需要建立不同时期不同品种的聚类分析模型,才能全面考察南疆红枣的鉴别。
[1] 王星.新疆红枣成“黑马”[N].阿克苏日报,2014-9-11(24).
[2] 武斌,武小红,贾红雯.苹果近红外光谱的聚类分析[J].食品科技,2014,39(09):280-281.
[3] 刘卉,郭文川,岳绒.猕猴桃硬度近红外漫反射光谱无损检测[J].农业机械学报,2011,42(3):145-149.
[4] Burns D A ,Ciurczak E W .Handbook of Near-Infrared Analysis.Third Edition.Marcel DekkerInc, New York,2007.
[5] 石杰,李长滨,吴拥军.不同厂家冬凌草片的近红外光谱主成分聚类分析[J].郑州大学学报,2011,43(4):69-69.
[6] 彭云发.近红外光谱技术在南疆红枣品质快速无损检测中的应用研究[D].塔里木大学,2015.
[7] 褚小立.化学计量学方法与分子光谱分析技术[M].北京:化学工业出版社,2011:42-269.
[8] 李晓云,王加华,黄亚伟,等.便携式近红外仪检测牛奶中脂肪、蛋白质及干物质含量[J].光谱学与光谱分析,2011,03:665-668.
Research of Cluster Analysis of Jun-jujube in 224 Group and 10 Group by the Distance Matching Method
Li Weiwei1Kong Weinan1Luo Xuening1Dai Xijun1Luo Huaping1,2,3*
(1 College of Mechanic and Electrical Engineering, Trim University, Alar, Xinjiang 843300) (2 Xinjiang Uygur Autonomous Region General Institutes of Higher Education Key of Modern Agriculture Engineering, Alar, Xinjiang 843300) (3 Southern Xinjiang Agricultural Mechanization Research Center, Alar, Xinjiang 843300)
There is great price difference between the No. 224 Group jun-jujube in Hetian and No. 10 Group in Aksu, and it is practical significance to identify quickly and accurately. The Jun-jujube in No. 224 Group Hetian and No. 10 Group Aksu were clustering analyzed by the distance matching method, and were pretreated with normalized method, baseline correction, Savitzky-Golay convolution derivation method (13 points smooth, 3 points differential width), and abnormal samples were excluded using the Mahalanobis distance. The results showed there were great differences in the moisture content, total sugar content and total acid content between the No. 224 Group Hetian and No. 10 Group Aksu Jun-jujube. The most precise method was the clustering analysis model of total acid band, followed by the cluster analysis model of water wave and the clustering analysis model of total sugar band. The cluster analysis model is more suitable for the Jun-jujube in 10 Group Aksu, because of the more efficiency classification. Conclusion: It is feasible to identify the locality of Hetian and Aksu Jun-jujube using the distance matching method, and this can provide some reference value in identification the producing area of Southern Xinjiang jujube.
distance matching method; cluster analysis; Savitzky-Golay convolution derivation method; mahalanobis distance
1009-0568(2016)04-0070-06
2015-11-04
国家自然科学基金(11164023,11464039)。
李伟伟(1985-),男,硕士研究生,研究方向为农产品无损检测。 E-mail:liweiwei8503@163.com
*为通讯作者 E-mail:luohuaping739@163.com
TP391.4
A
10.3969/j.issn.1009-0568.2016.04.011
文章编号:1009-0568(2016)04-0070-06
猜你喜欢
种子科技(2024年3期)2024-03-07 10:52:54
上海建材(2020年4期)2020-12-15 00:31:54
中国外汇(2020年17期)2020-11-21 08:24:12
上海建材(2020年12期)2020-04-13 05:57:58
山西林业科技(2020年4期)2020-03-09 08:17:06
电子制作(2017年22期)2017-02-02 07:10:24
语言与翻译(2015年2期)2015-07-18 11:09:56
新疆农垦科技(2014年8期)2014-02-28 19:20:41
新疆农垦科技(2014年7期)2014-02-28 19:20:29
双语教育研究(2014年4期)2014-02-27 06:44:44
