
基于HANA的高校教务大数据多维度分析
2016-12-27 19:10张红
中国教育技术装备 2016年19期
关键词:大数据
张红
10.3969/j.issn.1671-489X.2016.19.027
摘 要 基于HANA平台,对东华大学近10年的教务数据进行多维分析,对学生信息表和学生成绩表分别创建分析视图和计算视图,挖掘学生成绩、生源地、专业、星座之间的关系,并对其关系进行图形展示,为高校学生的管理和研究提供信息支持。
关键词 HANA;教务数据;大数据
中图分类号:G642 文献标识码:B
文章编号:1671-489X(2016)19-0027-02
1 引言
近年来随着“大数据”技术的发展,数据的价值逐渐被大家认识并发掘,行业内出现了各种关于大数据的应用,本文的立足点是高校教务数据。高校教务数据包括学生的基本信息、学生的选课信息及学习成绩信息等,这些信息比较全面地反映了学生的整体情况,而且彼此之间存在紧密联系,同时也隐含了一些重要信息。通过对该数据的挖掘分析,可以把一些重要的信息从数据库中抽取出来,为人们提供具有价值的信息,更好地支持人们的决策,同时为学生管理人员提供有力的信息支持和工作指导。本文以东华大学近10年的教务数据为样本进行研究分析,挖掘学生成绩、生源地、专业和星座之间的系。
2 相关技术
内存计算 数据库奠基人Jim Gray曾于2006年预言:“磁带已经死了,磁盘已经落伍,闪存成为新存储,内存局部性才是王道。”随着硬件成本的不断降低,如今这一预言已经成为现实[1]。内存计算在软硬件系统协同配置的环境下,高效地将数据库以及数据仓库全部放在内存中进行计算,这样有效地减少了磁盘的I/O。内存计算采用高效的并行计算技术以及基于内存的数据的读取、处理以及压缩技术,同时支持数据的行式存储以及列式存储。在内存计算方法中拥有系统内容的计算引擎,使用内存计算法运行大量的数据系统是用虚拟数据建模,计算引擎直接采用虚拟数据进行有效计算,这样的计算方式直接在内存中进行,减少了因为大量的数据的存在造成的数据冗余,优化了数据层与应用之间的数据交互,极大地提升了系统的运行效率。内存计算的计算方式让数据的计算速度飞快地增长,也让海量的数据快速计算成为可能。
HANA数据库 HANA是一种数据库管理系统[2],其研发者是SAP公司。HANA数据库不同于一般的数据库,它是一种集软件与硬件为一体的工作平台,是列式存储与内存计算技术上的结合体。HANA数据库的运行方式相较于传统的数据库的运行方式,极大地提高了数据的压缩效率以及存储的性能,减少了可能造成的数据冗余。HANA数据库的使用者可以自由使用内置的分析工具对各种模型进行分析,如建立数据仓库、报表等,能够对平台上的大量数据及时处理并实时获得分析结果,完成对大量数据的分析。
HANA[3]的内存数据库是内存计算中最主要的组成部分,主要包括的内容有数据库服务器、客户端工具、建模工具。在HANA数据中,计算引擎是核心,主要负责对大量数据的CRUDQ操作,操作形式支持MDX、SQL语句[4-5]等。HANA数据库不一般的计算能力以及强大可扩展性,让原来需要很长时间很大工程的运算成为可能,并且其计算引擎也不对其他的用户操作造成影响,这很大程度上提高了企业的工作效率,促进了劳动生产力的提高。
3 数据处理过程
数据加载 从东华大学得到的教务数据是csv文件格式的,包括学生基本信息、选课信息、选课情况信息、成绩信息等。该格式的文件是一种比较轻量级的用半角逗号作分割值的数据文件,无法创建索引,每次查询都需要遍历文件,很难适应复杂多变的查询需求。因此,首先将数据从csv文件导入到HANA数据库,HANA数据库可以帮助系统完成大规模的数据查询与提取。
安装HANA客户端工具和建模工具后,需要将数据加载到HANA实例中,以便开始执行示例应用程序。数据加载可能非常复杂,SAP为不同的数据加载业务情景提供了多个解决方案。打开HANA建模工具,单击“文件”(File)菜单并选择“导入”项(Import)即可实现数据的导入。
数据建模 在HANA数据库中,用于对各种数据建模的模型称为信息视图(Information views)。这类视图通过对内容数据(属性数据、度量数据)的各种组合来建立业务实例的模型。数据仓库中一般常用的数据类型有两种:一种是属性数据(attribute),通常是一些描述性的数据,如学生学号、班级、生源地等;一种是度量数据(measure),通常是数字型的数据,如学生家庭收入、学生成绩等。这两种数据类型都可以称为内容数据。
信息视图的一般用途是分析性的用例,如患者地域分布表、多维度分析的检验报告等场景。HANA提供的信息视图有三种,分别是属性视图(attribute view)、分析视图(analytic view)、计算视图(calculation view)。其中,属性视图是基于不同数据库的源表中具有一定关系的属性数据而建立起来的实体模型;分析视图主要用于建立包含度量数据的模型;计算视图可以简单地实现和属性视图、分析视图同样的功能,也可以针对数据库中定义进行更高级的计算,用来满足业务应用上的一些复杂逻辑。
本文对课程信息表创建了分析视图,设置输出列为课程编号和课程名称,并在语义层定义维度和度量,通过查询课程名相同、课程代码不同的课程,可以看出排名前10位的课程主要是每个学院都开设的实习类课程。
对学生信息表创建了计算视图,利用学生出生日期建立计算列,从而获得每个学生的星座。选择“星座”这个维度,度量选择按照“学号”计算,通过分析可以看出,学生人数排名前5位的星座分别是天秤座、天蝎座、狮子座、处女座和水瓶座。
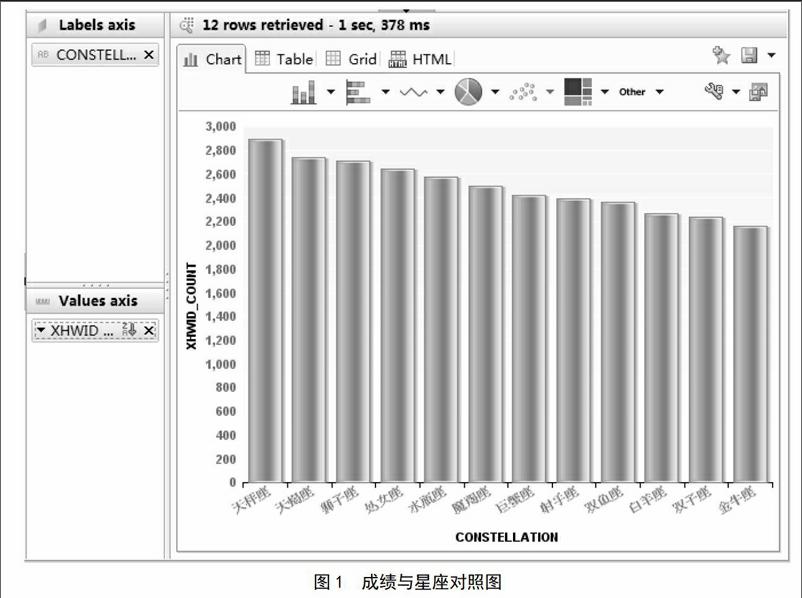
对学生成绩表创建了计算视图,利用成绩建立计算列,选择“生源地”这个维度,度量选择按照“平均成绩”计算,通过分析可以看出,学生人数排名前5位的生源地分别是浙江、河北、河南、福建和山东;选择“星座”这个维度,度量选择按照“平均成绩”计算,通过分析可以看出,成绩排名前5位的星座是天秤座、天蝎座、狮子座、处女座和水瓶座,如图1所示。
4 实验
实验环境 本实验所用服务器的配置为戴尔Power Edge R910,CPU为4颗Xeon核E7520,内存为256 G,操作系统为SUSE Linux Enterprise Server 11 SP1,内存计算数据库引擎采用HANA SERVER 1.006。实验数据采用东华大学近10年的教务数据。
结果与分析 对学生成绩表创建了计算视图,利用成绩建立计算列,选择“生源地”这个维度,度量选择安装“平均成绩”计算,对查询结果进行了筛选,查看成绩相对较差的学生的生源地分布数据,排名后5位的是北京、河南、广东、陕西、云南。
对学生成绩表创建计算视图,利用成绩建立计算列,选择“星座”这个维度,度量选择按照“平均成绩”计算,查看优秀学生的星座分布数据,排名前5位的是天秤座、天蝎座、狮子座、处女座、水瓶座。
5 结束语
本文基于HANA平台,对东华大学近10年的教务数据进行了多维分析,对学生信息表和学生成绩表分别创建了分析视图和计算视图,分析了学生成绩、生源地、专业、星座之间的关系,并对其关系进行了图形展示,为人们提供具有价值的信息,更好地支持人们的决策,同时也为学生管理人员提供了有力的信息支持和工作指导。基于该数据,还可以利用关联规则进一步挖掘各维度之间更深一层的关系。■
参考文献
[1]朱靖翔,张滨,乐嘉锦.基于内存计算的钢铁价格预测算法研究[J].计算机科学,2014,41(b11):432-435.
[2]李抵非,田地,胡雄伟.基于分布式内存计算的深度学习方法[J].吉林大学学报:工学版,2015,45(3):921-925.
[3]付云.大数据时代内存计算先行[J].互联网周刊,
2012(2):64-65.
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
