
面向计算机基础教学的Hadoop实验设计
2016-12-27 08:19:15徐岩,周围
实验室研究与探索 2016年1期
徐 岩, 周 围
(北京交通大学 计算机与信息技术学院, 北京 100044)
面向计算机基础教学的Hadoop实验设计
徐 岩, 周 围
(北京交通大学 计算机与信息技术学院, 北京 100044)

随着互联网和Web技术的飞速发展,现代社会的信息量迅速增长,中国已经步入“大数据”时代。Hadoop作为Apache基金会的开源项目,是一个分布式计算框架,主要处理大量数据,在业界和应用行业尤其是互联网行业得到了广泛应用。因此,研究它非常必要。本文对Hadoop的特点及其子项目进行深入探讨,以Hadoop1.1.0为基础,设计面向计算机基础教学的系列实验,从环境搭建、并行编程到数据迁移等七个方面,它涉及到Hadoop的多个子项目,形成一定的深度和广度。使学生能够更加深入了解和学习Hadoop,为今后的学习奠定扎实的基础,以便培养更好的Hadoop人才。
Hadoop; 计算机基础教学; 实验设计
0 引 言
随着互联网和Web技术的飞速发展,现代社会的信息量迅速增长,中国已经步入了“大数据”时代。根据摩尔定律,约每隔18个月,CPU性能会提高一倍。然而,由于晶体管电路已经逐渐接近其物理上的性能极限,摩尔定律在 2005 年左右开始失效。CPU的速度不可能再大幅度提升了,人们开始设计分布式系统,把众多的计算机通过集群方式并行同时运行,来提高处理的速度。Hadoop作为一个分布式计算框架,主要处理大量数据,因此,研究它非常必要[1-2]。
实验教学可以使学生更形象生动地掌握了原来枯燥无味的理论知识,又锻炼了学生的动手能力和创造能力,从而最大限度地激发了学生的学习兴趣。因此,重视和加强实验教学,是激发学生学习兴趣的关键。Hadoop作为Apache基金会的开源项目,模仿Google的核心技术,是一个分布式系统的基础,是最典型和最常见的云计算平台[3-4]。本文针对Hadoop的特点及其子项目进行深入探讨,设计系列实验,使同学们能够更加深入了解和学习Hadoop。为今后的学习奠定扎实的基础,以便培养更好的Hadoop人才。
1 实验总体设计
1.1 Hadoop框架
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算。但是在Hadoop下的Common、HBase、Zookeeper、Avro等子项目也是不可或缺的,它们在提供了互补性服务或在核心层上提供了更高层的服务[5]。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。Hadoop家族由以下几个子项目组成(见图1)。

图1 Hadoop家族图
Hadoop Common:支持其他模块的常用工具集,主要包括系统配置工具、序列化机制、远程过程调用、数据压缩与解压缩、Hadoop抽象文件系统,为在通用硬件上搭建云计算环境提供基础服务,并为运行在该平台上的软件开发提供了所需的API。
HDFS:一个高扩展、高容错、高可靠、高吞吐量,运行在低成本的通用计算机上的分布式文件系统。
MapReduce:一种编程模型,用于大规模数据集的并行运算。
HBase:一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用这项技术可在廉价服务器上搭建起大规模结构化存储集群。
Zookeeper: 一个为分布式应用所设计的分布的、开源的协调服务,主要用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
Avro:一个数据序列化系统,用于支持数据密集型,大批量数据交换的应用[6]。
1.2 面向计算机基础教学的系列实验设计
计算机基础教学实验的特点有:①与时俱进,发展迅速,内容更新快;②实践性强,需要动手操作;③要求有一定的教学条件[7]。计算机是一门实践性很强的课程,如果实验课没有安排好,是不能有效掌握计算机的。而选取或设计一系列的实验,是至关重要的[8]。为了使学生能够更加深入了解和学习Hadoop,本文针对Hadoop的特点,以Hadoop1.1.0为基础,设计了一系列的实验(见表1),它涉及到Hadoop的多个子项目,形成一定的深度和广度。通过学习这些实验,可以使学生有效地掌握理论知识,在实践中获得巩固和提高。实验环境集群拓扑图如图2所示,实验所需软件环境如表2所示。

表1 面向计算机基础教学的系列实验

图2 实验环境集群拓扑图
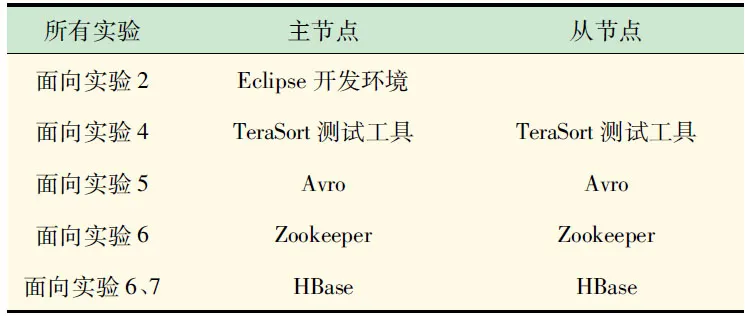
表2 实验软件环境
2 实验内容设计及实现
2.1 实验1:Hadoop集群环境搭建实验
本实验帮助学生掌握Hadoop所需软硬件环境。首先给主从节点机器配置网络,安装SSH、JDK,配置环境变量,安装Hadoop,分别设置主从节点的配置文件。启动前先格式化名字节点,最后通过查看各节点进程状态,确认进程正常启动,至此Hadoop集群环境搭建完毕。通过搭建实验,使学生学习Hadoop和Linux常用命令、熟悉Hadoop管理方式[9]。
2.2 实验2:分布式并行编程实验
本实验帮助学生理解MapeReduce的分布式并行计算工作原理。在此通过一个应用实例(单词计数)的运行过程来实现。单词计数程序的完整代码可以在Hadoop安装包的相应目录下找到,主要完成的功能是:统计一系列文本文件中每个单词出现的次数[10-11]。通过分析源代码帮助学生理解程序基本结构和执行过程,如图3所示。通过此实验,帮助学生学习Hadoop分布式文件系统、MapReduce编程模型,理解MapReduce的思想。

图3 MapReduce处理大数据集的过程
2.3 实验3:破坏试验可靠性验证实验
本实验模拟Hadoop集群中其中一台数据节点宕机故障,验证是否影响HDFS的使用?①设置副本数为3,本地上传一个大小为30 MB的文件到集群文件系统。②查看哪三台机器上面有Block块的新增。③在其中一台有数据块的数据节点执行关机操作。④观察集群的状态,宕机的节点已经被自动从集群中踢除了。⑤名字节点会检查每个正常工作数据节点的文件块是否都为3份,如果不是则会备份成3份放到正常工作的数据节点中。⑥验证能否从文件系统下载此文件?结果表明Hadoop集群中任何一台数据节点意外宕机,不会影响文件系统。通过此实验,使学生了解HDFS的工作原理及其高容错性的优点。
2.4 实验4:性能分析实验
本实验测试Map和Reduce任务数量对Hadoop性能的影响。通过Hadoop自带的Terasort排序程序,测试不同的Map任务和Reduce任务数量,对Hadoop性能的影响。实验数据由程序中的teragen程序生成,数据量为1GB和10GB。通过更改配置文件,从而调节Map任务和Reduce任务的数量;副本数设为3,其它参数默认[12]。结果表明:当数据量为1GB和10GB时,把输入分片设置为128MB(此时,1GB数据Map任务=8, 10GB数据Map任务=76),系统性能最佳(见图4、图5);Reduce任务的数量应该设置为接近从节点数量,或者适当大于节点数,不宜设置为比节点数量小太多。 通过此实验,使学生学习如何调整参数来提高Hadoop的性能,对Hadoop有更加深入的了解。
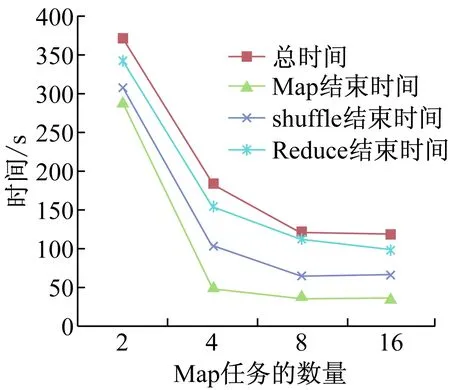
图4 1GB数据性能对比
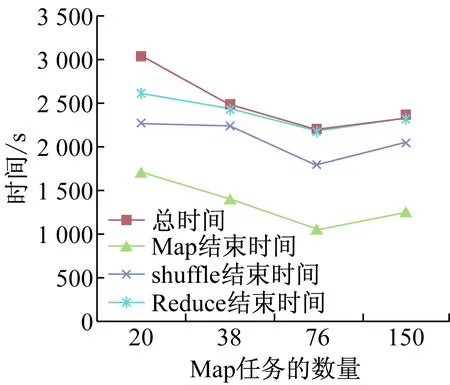
图5 10GB数据性能对比
2.5 实验5:大量小文件处理实验
本实验通过学习Avro工作过程理解大量小文件处理方式。如果采用MapReduce进行小文件的处理,那么Mapper的个数就会跟小文件的个数成线性相关。如果小文件特别多,MapReduce就会在消耗大量的时间进行Map进程的创建和销毁。为了解决大量小文件带来的问题,可以将HDFS中的小文件打包到一个大的文件容器中。将本地磁盘中所有的目标文件存储到HDFS中的一个单独的Avro文件,然后在MapReduce中处理Avro文件和其中的小文件。通过此实验,使学生学习如何处理大量小文件。
2.6 实验6:数据库编程实验
本实验针对HBase进行相关操作,了解数据库管理知识。过程如下:①插入数据:创建一个Put对象,在这个Put对象里可以指定要给哪个列增加数据,以及当前的时间戳等值,然后通过调用HTable.put(PUT)来提交操作。注意:在创建Put对象的时候,必须指定一个行(Row)值,在构造Put对象的时候作为参数传入。②获取数据:获取数据,使用Get对象,Get对象同Put对象一样有好几个构造函数,通常在构造的时候传入行值,表示取第几行的数据,通过HTable.get(Get)来调用。③删除:使用Delete来删除记录,通过调用HTable.delete(Delete)来执行删除操作[13]。通过此实验,使学生了解对HBase中表的管理、数据的操作等。
2.7 实验7:数据迁移实验
本实验实现Hadoop向HBase的数据迁移。通过使用MapReduce的方法,使用Hadoop的标准Map方法读取并分析HDFS文件,然后使用HBase提供TableReducer来实现Reduce,在TableReducer中调用Put对象,并构建行数据,直接插入到HBase中。所有的数据维护动作均由HBase自己来完成,数据插入的过程是追加过程,不会对已经存在的数据造成影响[14-15]。在测试时,需要输入一个HDFS文件的路径。通过此实验,使学生了解如何从Hadoop向HBase进行数据迁移。
3 结 语
Hadoop因其在大数据处理领域具有广泛的实用性以及良好的易用性,自2007年推出后,很快在工业界得到普及应用,同时得到了学术界的广泛关注和研究,Hadoop必将成为研发和应用大数据的理想选择。本文对Hadoop的特点及其子项目进行深入探讨,设计系列实验,能满足学生从事大数据应用和研发的现实需要,使用实例搭建并经实证的云平台,能实现海量数据的分布式计算和处理,可为计算机基础相关课程提供实验技能训练,如“大学计算基础”、“Linux操作系统基础”等,具有一定的理论及实用价值。本实验设计会随着系统升级、大数据主流开源产品的发展而不断改进。
[1] 中国电子科学研究院学报编辑部.大数据时代[J].中国电子科学研究院学报,2013(1):27-31.
[2] 王 珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011(10):1741-1752.
[3] Tom White. Hadoop 权威指南[M].北京:清华大学出版社,2013(11):391-426.
[4] 刘 刚,候 宾,翟周伟.Hadoop开源云计算平台[M].北京:北京邮电大学出版社,2011:10-13.
[5] Hadoop官方网站,http://hadoop.apache.org/.
[6] Hadoop中国网站,http://www.hadooper.cn/dct/page/1.
[7] 何怡璇. 论高校计算机基础教学的思路和方法[J]. 计算机学报,2011(12):106-106.
[8] 崔 成.《计算机基础》教学及改革思考[J]. 福建电脑,2011(1):209-210.
[9] (美)拉姆.Hadoop实战[M].韩冀中译,北京:人民邮电出版社,2011:3-4.
[10] 董西城.Hadoop 技术内幕:深入解析 MapReduce 架构设计与实现原理[M].北京:机械工业出版社,2011:13-18.
[11] 许舟平.云深不知处——大规模分布式云计算方案详解[J].程序员,2008(11):58-61.
[12] 栾亚建,黄翀民,龚高晟,赵铁柱.Hadoop平台的性能优化研究[J].计算机工程,2010(14):263.
[13] George L.HBase权威指南(影印版)[M].南京:东南大学出版社,2012.
[14] http://www.itpub.net/thread-1588509-1-1.html.
[15] Konstantin Shvachko, Hairing Kuang, Sanyjy Radia,etal. The Hadoop Distributed File System [C]//Proceedings of the 2010 IEEE 26thSymposium on Mass Storage Systems and Technologies(MSST),May 03-07,2010:1-10.
Design of Hadoop Experiment for Computer Fundamental Teaching
XUYan,ZHOUWei
(School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China)
With the rapid development of the Internet and Web technology, the information is growing rapidly in modern society, China has entered the era of "big data". As the Apache foundation's open source project, Hadoop is a distributed computing framework, processes large amounts of data mainly, and it is widely used in industry and application industry especially the Internet industry. Therefore, it is very necessary to research it. In this paper, we study Hadoop in-depth according to the characteristics of it and its subprojects, and base on Hadoop 1.1.0 to design series of experiments oriented computer fundamental teaching. The contents include the environment to build, Parallel programming, and data migration among seven aspects. It involves multiple subprojects of Hadoop, holds a certain depth and breadth, enables students to understand and study Hadoop further, and provides them a solid foundation for the future development, and cultivates them to be Hadoop talents.
Hadoop; computer fundamental teaching; experiment design
2015-01-13
北京市哲学社会科学规划项目(12JYB010)
徐 岩(1991-),女,山东济宁人,在读硕士,研究方向计算机科学与技术。
Tel.:18813099341;E-mail: haprnxu@163.com
周 围(1973-),女,河北石家庄人,博士,高级工程师,硕士生导师,研究方向计算机科学与技术。
Tel.:15201319577;E-mail: wzhou@bjtu.edu.cn
TP 39
A
1006-7167(2016)01-0169-04
猜你喜欢
华南理工大学学报(社会科学版)(2022年4期)2022-08-11 06:31:40
中学生数理化·七年级数学人教版(2022年6期)2022-06-05 06:50:56
中学生数理化·七年级数学人教版(2021年10期)2021-11-22 07:53:08
山西化工(2021年4期)2021-01-25 14:15:18
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
劳动保护(2018年5期)2018-06-05 02:12:02
科技创新导报(2017年6期)2017-06-19 21:55:19
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
