
基于改进支持向量机的视频摘要技术
2016-12-27 08:18:44刘长征张荣华
实验室研究与探索 2016年1期
刘长征, 张荣华
(石河子大学 信息科学与技术学院,新疆 石河子 832003)
基于改进支持向量机的视频摘要技术
刘长征, 张荣华
(石河子大学 信息科学与技术学院,新疆 石河子 832003)

鉴于视频监控系统获取到的视频数据十分庞大且其中存在大量冗余信息,通过视频摘要技术将这些视频数据浓缩成简短的摘要视频,让用户快速、准确地获得视频中的重要信息, 提高视频数据的管理效率。采用二进制化的支持向量机和滑动窗口结合的方法,利用图像在HSV颜色域中的梯度信息,提取原始视频中具有重要信息的关键帧,然后把提取到的关键帧融合得到摘要视频。实验结果表明,该方法不但能够快速、准确地提取关键帧并形成摘要视频,而且能够取得较好的效果。
视频摘要技术; 关键帧提取; 支持向量机; 绝对梯度
0 引 言
视频摘要技术主要分为两大类:基于静态的视频摘要技术和基于动态的视频摘要技术。前者是把原始视频看作一个连续图像集合,通过筛选出具有重要视频信息的图像集合代替原始视频。该方法原理简单,容易扩展。而后者则是对原视频流进行再编码,把视频中的重要内容进行编码压缩,包括音频和运动内容,通过减少视频中的时间-空间冗余,将原始视频内容压缩成浓缩的视频。对于上述的两类技术,基本思路是通过分析视频中的内容,筛选发生重大的变化的视频片段,最后将筛选出来的视频片段融合成摘要视频。通常情况下将发生重大变化的视频片段取为关键帧。经过不断地发展,基于提取关键帧的视频摘要技术越来越先进,例如:Guan等[4]通过设定关键点,分析关键点在全局图像和局部图像的对应关系,进而判断关键帧。Chun-Rong等[5]利用颜色模型追踪目标,从而提取关键帧。Naveed Ejaz等[6]提出通过计算相邻两帧图像的直方图和运动模型,然后利用聚类的方法提取关键帧。Xin Zhao等[7]利用结合平均灰度累积直方图和边缘方直方图提取关键帧。上述各种基于提取关键帧的视频摘要方法的效果不错,但计算过程消耗的时间都比较多,实时性不佳。本文研究分析摄像头静止拍摄获取的视频数据,将其分成两种不同的图像集合:一种是只有场景的图像集合,这类图像没有感兴趣的信息,属于被去除的视频帧;另一种是具有运动目标的图像集合,这类图像往往受到用户的高度重视,因为视频的重要信息几乎集中在这个集合中。根据上述分析,本文采用一种支持向量机和滑动窗口的方法提取具有运动目标的视频图像。
1 方法介绍
对一个视频数据内容进行摘要表达,假设从这个原始视频的第t帧开始,而这个原始视频总共有Nf帧,可以表达为
(1)
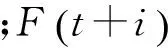
(2)
根据式(1)、(2),本文利用滑动窗口在图像上滑动,计算窗口中的绝对梯度值,再利用SVM分类器将进行训练学习并分析视频中内容的变化程度,从而判读并提取关键帧,具体步骤如下所述。
Step1:训练支持向量机(Support Vector Machine,SVM)分类器。在适量监控视频中,大部分用户对视频中的人和车辆感兴趣,所以选取仅只有人、车辆的图像作为分类器的正样本,而且尺寸、光照和遮挡等各不相同。而分类器的负样本就选取仅包含监控场景的图像,例如路口、街道和室内大厅等。
Step3:提取关键帧。对输入的视频数据利用滑动的窗口,然后计算窗口内HSV绝对梯度差,最后利用SVM分类器分类分析视频图像中发生重大变化的视频帧,然后将它提取保存,最后融合成摘要视频。根据上述步骤,设计的算法流程如图1所示。
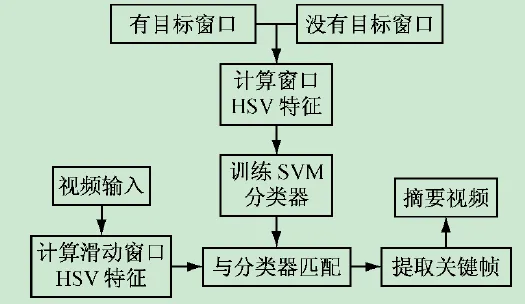
图1 视频摘要算法流程图
2 算法实现
2.1 参数定义
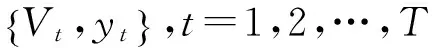
(3)
根据式(3),利用大量样本计算分类器w,然后利用w对待处理的视频帧序列进行关键帧提取。
根据文献[1]提出根据图像RGB颜色域上的绝对梯度特征对目标进行检测的方法,本文利用SVM学习原始视频中关键帧的绝对梯度信息,然后根据下面式(4)提取视频中的关键帧。为了更加准确地提取关键帧,结合滑动窗口进行局部搜索,只要发现图像局部地方发生重大变化,就可以判断为关键帧。因为需要不同大小的窗口进行滑动寻找目标,将每个滑动的窗口进行量化,表达分别为:
Sl=〈W,Hl〉
(4)
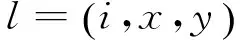
(5)

2.2 改进的SVM分类器
要得到一个准确率高的SVM分类器,就需要大量样本,这些样本不仅数量要多,而且要具有代表性。例如在视频监控领域中,主要针对的视频信息基本是行人和车辆。因此我们根据视频中行人和车辆的变化判断当前帧是否为原始视频中的关键帧。为了使得算法具有更好的鲁棒性,在选择训练样本的时候,选择规模大小、光照强度、遮挡程度和旋转角度等各不相同的样本若干个。我们把VOC2007里面的行人图像和车辆图像进行裁剪,裁剪出大小不同、姿态不同和颜色不同等具有丰富特点的样本,并建立实验需要的行人库和车辆库。
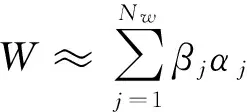
我悄悄跟着溜了出去,不过刚才我一句话也懒得说,所以也没人发现我。我本身也是不喜欢拓展社交圈的人,不知道为何,我就是很想认识这位小哥。
(6)
然后结合式(3)、(5),要计算滑动窗口的分数Sl,只要将特征值Hl也转化为二进制形式表达,Sl计算过程就变成了二进制数的运算,既简单又快速。
按照算法1:
输入:W,Nw
初始化:ε=W,j=1
当j≤Nw
ε=ε-βjαj,j=j+1
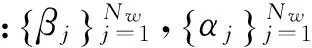
2.3 HSV绝对梯度值
在视频监控领域中,主要研究对象是人、车辆以及其他运动物体。因此根据视频中是否出现行人或者车辆作为提取关键帧的条件。行人具有非刚性特征,而且行人图像容易受到身材、姿态、以及衣着等因素影响。车辆则具有刚性特征,受到干扰因素比较少。因为颜色特征与其他图像特征相比,前者对图像本身尺寸、方向、视角的依赖性较弱,更具有鲁棒性。因此本文选择利用HSV颜色域上的绝对梯度值作为图像特征。首先根据文献[8-9,13-16]将输入的视频数据从RGB颜色空间转换成HSV颜色空间,转换公式为:
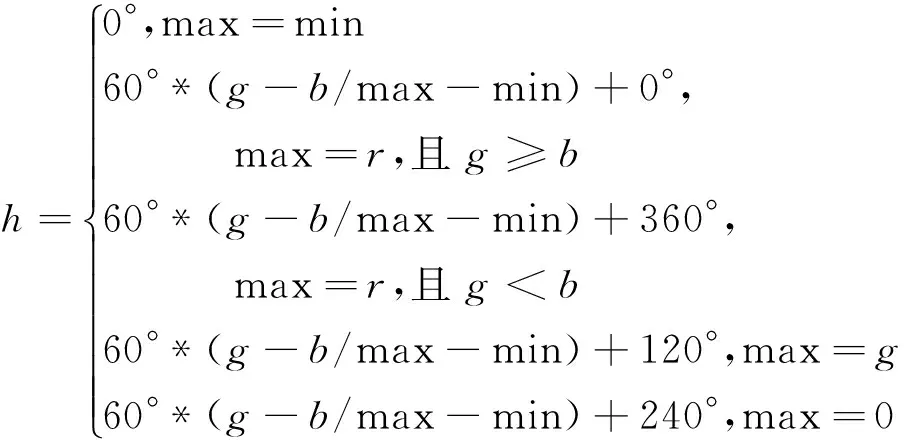
(7)

(8)
v=max
(9)
其中:max为图像像素中的最大值;min为图像中的最小值。然后,当滑动窗口滑过的时候,计算窗口内的HSV绝对梯度差值Hl,最后为了简化式(6),将Hl量化为一个8 b的二进制数。所以Hl特征值可以表示为:
(10)
式中:Nh为控制Hl长度,当Nh=8时,Hl=8,而当Nh=1,Hl=1。通过调节Nh,减少计算过程中的按位操作的次数,从而减少计算的时间损失,提高运算性能。与此同时,根据式(4)、(6)、(10)进一步得到:
(11)
根据式(11)计算得到的Sl分析视频图像中内容变化程度,进而提取关键帧,生成摘要视频。
3 实验结果
首先要对VOC2007图像库里面的图像进行筛选,选出适合作为SVM训练样本的图像,并对其进行适当裁剪,建立一个简单实用的行人库和车辆库。VOC2007这个数据库中一共有4 952张图片包含20类对象,每一类对象都具有不同的视角、大小、位置、遮挡和光照,这就保证了样本的多样性,同时确保建立的行人库和车辆库具有鲁棒性。图2表示行人库和车辆库中的部分图像。同时为了方便扩展,可以根据不同需要选不同的对象建立不同的数据库。
建立行人库和车辆库后,就可以利用这两个数据库里面的样本训练SVM分类器。首先将行人库和车辆库中的样本大小按照一定比例缩小,如图3(a)所示。通过该方法得到了更多的训练样本,而且图像的绝对梯度值具有尺度不变性,在增加样本的同时不影响SVM训练的结果。然后将每一个样本图像的绝对梯度差值用8位的二进制数表示,得到如图3(b)的二进制矩阵图。最后利用训练样本的二进制的绝对梯度值矩阵图来训练SVM分类器。

图3 训练样本处理
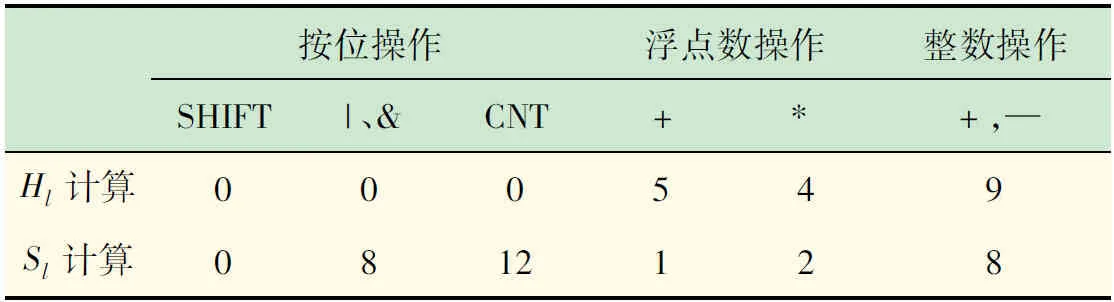
表1 各步骤原子操作次数表
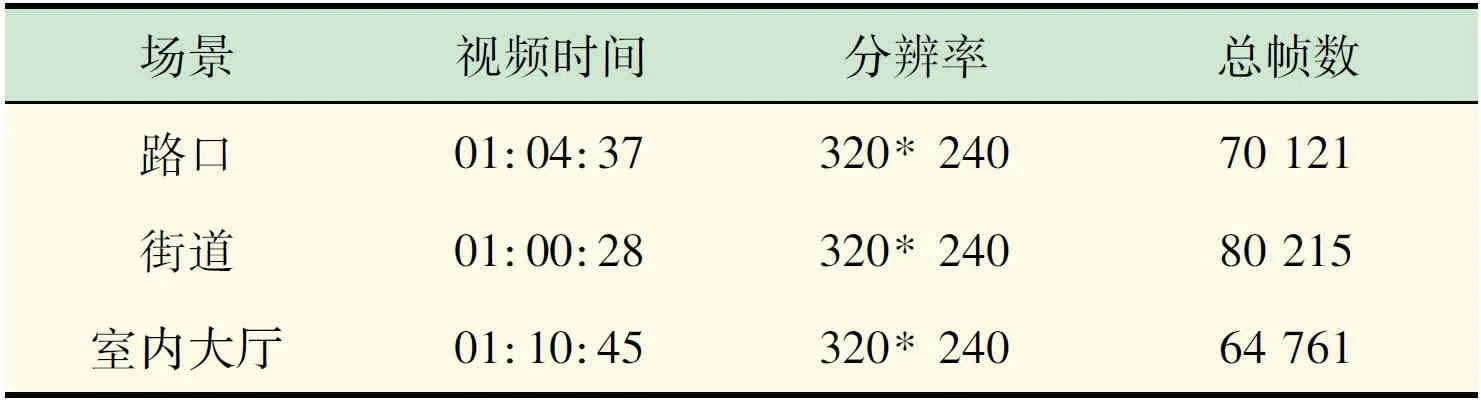
表2 测试视频的数据

表3 实验数据对比
4 结 语
通过实验表明:本文改进支持向量机的视频摘要方法能够快速地提取关键帧并生成效果良好的摘要视频,但是提取关键帧没有达到较高的准确率,这会影响摘要视频内容的真实程度和冗余程度,尤其在环境复杂的情况,准确率更加低。所以今后要开展的工作是如何更快、更准确地提取关键帧,例如在训练分类器的时候选择更多具有代表性的训练样本,另外就是选择其他的图像特征,例如纹理、形状等进行试验对比分析,希望通过实验对比,得出更适合提取关键帧的图像特征,生成效果更好的摘要视频。
[1] Ming-Ming Cheng, Ziming Zhang, Wen-Yan Lin,etal. BING:Binarized Normed Gradients for Objectness Estimation at 300fps[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition,2014:3286-3293.
[2] Zheng S, Sturgess P, Torr P H S. Approximate structured output learning for constrained local models with application to real-time facial feature detection and tracking on low-power devices[J]. Automatic Face and Gesture Recoginition(FG), 2013:1-8.
[3] Alexe B, Deselaers T, Ferrari V. Measuring the objectness of image windows[J]. IEEE TPAMI, 2012,34(11):2189-2202.
[4] Guan G, Wang Z, Yu K,etal. Video summarization with global and local features[C]//Multimedia and Expo Workshops (ICMEW),2012 IEEE International Conference on,2012:570-575.
[5] Chun-Rong Huang, Hsing-Cheng Chen,Pau-Choo Chung. Online Surveillance Video Synopsis[J]. IEEE,2012: 1843-1846.
[6] Naveed Ejaz, Tayyab Bin Tariq, Sung Wook Baik. Adaptive key frame extraction for video summarization using an aggregation mechanism. J. Vis. Commun[J]. Image R. 2012: 1031-1040.
[7] Xin Zhao, JiWei Liu, Lan Zhang. Adaptive key-frame selection based on image features in Distributed Video Coding[J]. IEEE, 2013: 245-248.
[8] 张 磊,傅志中,周岳平.基于HSV颜色空间和Vibe算法的运动目标检测[J].计算机工程与应用,2014,50(4):181-185.
[9] 岳求生,周书仁,李 峰,等.HSV与LBP特征融合的行人检测方法研究[J].计算机工程与科学,201436(10):1997-2001.
[10] Avila S E D, Lopes A B P, Antonio L J,etal. VSUMM: a mechanism designed to produce static video summaries and a novel evaluation method[J]. Pattern Recognition Letters. 2011,32(1):56-68.
[11] Everingham M, Van Gool L, Winn J,etal. The PASCAL Visual Object Classes Challenge 2007(VOC2007) Results[EB/OL]. http://www.pascalnetwork.org/challenges/VOC/voc2007/workshop/index.html
[12] 丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2014,40(1):2-10.
[13] Tosic I, Frossard P. Dictionary learning[J]. Signal Processing Magazine, IEEE, 2011, 28(2): 27-38.
[14] Bruckstein A M, Donoho D L, MICHAEL Elad. From sparse solutions of systems of equations to sparse modeling of signals and images[J]. SIAM Review, 2009, 51(1): 34-81.
[15] Mairal J, Bach F, Ponce J. Task-driven dictionary learning[J]. Transactions on Pattern Analysis and Machine Intelligence, IEEE, 2012, 34(4): 791-804.
[16] Mairal J, Ponce J, Sapiro G,etal. Supervised dictionary learning[C]//Advances in neural information processing systems. 2009: 1033-1040.
Video Summarization Technology Based on Improved Support Vector Machine
LIUChang-zheng,ZHANGRong-hua
(College of Information Science and Technology, Shihezi University, Shihezi 832003, China)
Aimed at the problem that video surveillance system obtained a huge amount of video data which exit a large number of redundant information, the paper proposed to condense these video data into a brief summary video by the video synopsis technology. The summary video can allow the user to get the important information in video quickly and accurately, so that the management efficiency of video data is improved. Using the means of combining the binarized support vector machine and the sliding window, we use the gradient information in the image in HSV color field, and extract the key frames which contain the important information in original video, then the summary video is gotten by fusing these key frames. Experimental results show that the method can not only extract the key frames quickly and accuracy from original video and get a summary video, but can also get good effect.
video synopsis technology; key frame extracted; SVM; absolute gradient
2015-08-24
兵团青年科技创新资金专项(2014CB004);兵团社会科学基金项目(13QN11);兵团科技攻关与成果转化项目(2015AD018);石河子大学重大科技攻关计划项目(gxjs2012-zdgg03)
刘长征(1979-),男,山东惠民人,硕士,高级工程师,主要从事计算机应用等方面的研究。
Tel.:18999335349;E-mail: liucz@sina.cn
TP 39
A
1006-7167(2016)01-0085-04
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
扬子江(2019年1期)2019-03-08 02:52:34
电子测试(2018年1期)2018-04-18 11:52:35
大连理工大学学报(2017年4期)2017-08-07 07:03:20
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
