
通用数据挖掘系统的结构与设计
2016-12-26 07:35汪峰坤张婷婷
黑龙江工业学院学报(综合版) 2016年11期
汪峰坤,张婷婷
(安徽机电职业技术学院,安徽 芜湖 241000)
通用数据挖掘系统的结构与设计
汪峰坤,张婷婷
(安徽机电职业技术学院,安徽 芜湖 241000)
数据挖掘是当前应用系统有效的功能扩展,通过数据挖掘模块可以提升应用系统的价值,发现数据的深层次知识。但是数据挖掘算法的多样性,以及开发的高难度,限制了数据挖掘功能的广泛应用。为了提高数据挖掘模块的通用性及扩展性,减少与特定领域的耦合性,设计出一个结构松散、扩展性强、领域无关、支持动态配置的通用数据挖掘系统是非常必要的。利用高级语言支持的反射功能,设计了简单的插件模型和数据挖掘过程中各功能模块的统一接口,通过系统内核动态加载并运行插件,有效地增加了数据挖掘模块的通用性和扩展性,具有一定的实用价值。
数据挖掘;框架;低耦合;反射;插件
一 引言
随着网络的快速发展以及信息技术的深入应用,人们产生、收集和存储数据的能力大幅增加。对这些具有海量、结构非良好、模糊、随机等特征的数据进行有效的处理分析,提取出隐藏在数据内部的潜在知识,是数据挖掘技术所研究的目标。数据挖掘是一门跨学科、跨领域的研究课题。在数据挖掘技术中,融合了统计学、概率论、面向对象技术、数据库技术、机器学习、人工智能、信息检索、数据可视化以及知识工程等研究领域。[1][2][3]
当前大部分的网络应用系统中,为了综合有效地利用已有数据,都会开发相应的数据挖掘模块。商用的数据挖掘系统一般都是闭源收费,如:IBM 公司的 Intelligent Miner、SGI 公司的 SetMiner、SPSS 公司的 Clementine、 SAS 公 司 的 Enterprise Miner等。一些开源的数据挖掘系统如Weka等,具有功能较弱,与应用系统集成困难等缺点。
本文介绍了一种适用于数据挖掘系统的软件体系结构,此种体系结构具有多数据源支持、挖掘算法增加方便、参数配置简单、挖掘算法之间耦合性低、平台无关性等优点。
1 数据挖掘算法特点
数据挖掘算法主要分成:关联规则挖掘算法、分类挖掘算法、聚类挖掘算法三大类型。对于每种类型又存在着多种基本算法,以及增强算法。关联规则挖掘算法常见的有:Apriori算法簇、FP_Growth算法簇、Two-Phase算法簇等。分类挖掘算法常见的有:决策树、 Bayes分类、神经网络、支持向量机等。聚类挖掘算法常见的有:基于划分聚类算法簇、基于层次聚类算法簇、基于密度聚类算法簇等。[4][5][6][7]
通过对上述各类型挖掘算法进行分析,可发现数据挖掘挖掘算法有以下几个特点。
(1) 各挖掘算法对数据特征要求不一样。例如:关联规则挖掘算法只需要指定数据所在列,而分类挖掘算法既要指定数据所在列,又要指定分类结果列。
(2) 各挖掘算法参数配置不同。例如:对于基于划分聚类挖掘算法要设置类的个数,对于基于密度聚类挖掘算法簇要指定密度大小。
(3) 各挖掘算法运算后输出结果的格式是不同的。例如:聚类挖掘算法输出结果是多个集合,每个集合就是求解的一个簇。关联规则挖掘算法求解的结果是一组蕴含式和相应的概率。
由上可以得出数据挖掘挖掘算法在输入、参数配置和输出结果上差距很大,即使在同种类型的挖掘算法簇中,不同挖掘算法的参数个数和类型也有区别。
开发通用的数据挖掘系统应该满足如下条件。
(1) 支持多种输入的数据类型。在当前的数据挖掘系统中,不同的软件支持的数据源类型是不同的。常见的数据源类型有:关系型数据库、网络数据、文本数据、电子表格数据等。系统要支持结构良好、半结构化和无结构化的数据。
(2) 支持挖掘算法多种开式的输出结果。系统中要考虑输出结果的多样性,支持控制台直接输出、操作系统事件日志输出、系统日志文件输出、Excel表格输出、XML文件输出及JSON数据格式输出等。
(3) 挖掘算法增加删除方便。对于通用数据挖掘系统,要非常重视系统的可扩展性。系统要做到对于新增加的挖掘算法,通过简单的参数配置就可以在系统中直接使用,无需重新编译整个系统。
(4) 所有挖掘算法所需要的参数设置配置化。即挖掘算法中用到的参数个数、类型、值等都是通过配置文件完成,由通用数据挖掘系统统一读写,无需在系统中写死。方便参数管理,减少挖掘算法参数配置部分的代码量。
(5) 为了保证挖掘算法性能,系统提供多线程机制、提供同步锁、提供挖掘算法中止功能等。
所以在设计通用数据挖掘系统时,要符合软件设计原则,尽可能的屏蔽各挖掘算法不同之处,高度抽象出挖掘算法的共同接口,以低耦合的方式联接各种挖掘算法。通用数据挖掘系统应使用插件结构,通过良好的体系结构设计分离出数据挖掘的各部分,每个部分屏蔽了数据、算法等的差异性,以插件的方式来动态加载和运行各部分模块。[8][9][10]
2 通用数据挖掘系统体系结构
通用数据挖掘系统体系如下图(图1),由系统内核、算法接口、算法插件、数据源读取接口、数据源读取插件、数据结果输出接口、数据结果输出插件等部分组成。
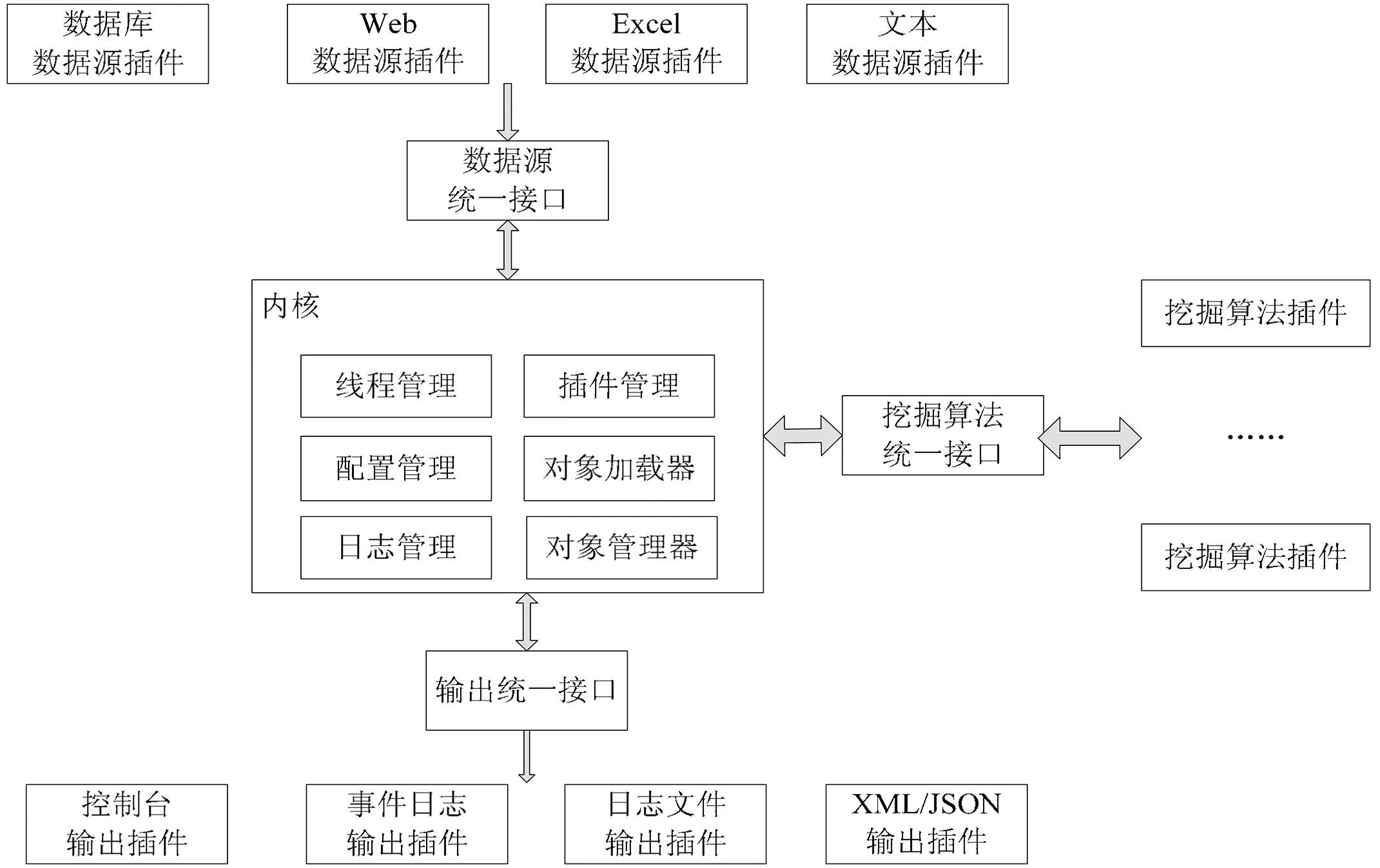
图1 通用数据挖掘系统体系结构图
2.1 内核。
数据挖掘系统的内核部分是整个系统最基础的部分,通过反射机制实现了动态数据源插件配置读取与加载、挖掘算法插件配置读取与加载、输出插件配置读取与加载、异常处理等。内核主要包括线程管理、插件管理、配置管理、对象管理器、日志管理、对象管理器等功能模块。
线程管理是用来启动、暂停、终止挖掘算法的线程,提供了简单的线程同步锁。如果挖掘算法需要多线程操作,则可以通过线程管理模块中提供的线程同步锁进行线程同步。
为了能够使本系统具有良好的可扩展性,系统中的数据读取、挖掘算法和结果输出三个主要的部分的功能都是通过插件方式提供。内核中的插件管理模块是对数据读取等三部分功能进行动态管理,不需要重新启动本系统就可以动态的增加、修改或删除数据源读取插件、挖掘算法插件和挖掘结果输出插件,即支持热插拨技术。
当要运行某个插件时,首先插件管理器通过反射功能得到此插件的元数据,配置管理器读取插件的配置信息,然后将插件元数据和配置信息传递给对象加载器。对象加载器到对象管理器中查找是否已经实例化此插件的对象,如果已经实例化,则直接返回此对象。如果未实例化,则由对象加载器生成此插件的唯一实例。动态删除一个插件时,由插件管理器以事件方式通知对象加载器,对象加载器到对象管理器中查找,如果找到则将插件实例对象设置为空。
对象管理器是管理系统中通过反射自动实例化的插件实例对象的容器。每一个实例化后的对象在对象管理器中会自动赋给一个唯一编号,方便查找。在对象管理器中,至少有三类对象,即数据源插件对象、挖掘算法插件对象和运算结果输出插件对象。如果系统以单线程方式运行,则对象管理器中只要三个对象就可以了。如果系统以多线程方式运行,则每一类可以有多个对象,对象管理器中有多个(超过3个)对象。
为了方便插件参数设置,本系统所有插件参数都是放到配置文件中。因为XML格式文件具有跨平台、扩展方便、易理解和验证,以及支持的语言和工具很多等优点,所有本系统所有的配置文件都使用的是XML格式文件。内核中的配置管理模块对插件的配置文件进行统一的验证和读写。配置管理模块的主要功能有:XML读取功能、XML Schema配置文件正确性验证、XML配置内容解析等。
系统内核中还包括了其它的一些通用服务功能,如:日志管理器可以记录程序的运行情况。日志管理器集成了开源的Log4Net组件,利用Log4Net强大的记录功能,通过配置可将日志在控制台显示,可保存到文本文件、数据库和事件管理器中。错误处理模块可以捕获系统中出现的异常信息,并通过日志模块将异常信息进行保存。
2.2 数据挖掘算法统一接口。
数据挖掘算法的统一接口是通用数据挖掘系统和数据挖掘算法插件唯一联系的地方。通过此接口,系统内核无需了解算法的内部实现,屏蔽不同挖掘算法在参数、实现等方面的不同之处。
其主要内容如下。
interface IAlgorithm
{void Build(Instance instance, Parameter para,Log log);
void Run();
string GetAlgorithmName();}
所有的挖掘算法插件都要实现此接口。此接口中Build方法是内核向挖掘算法提供挖掘的数据内容和算法自身的配置信息。instance对象是内核实例化后的数据源插件对象读取的待挖掘的数据,para对象是由内核中的配置管理器实例化后的算法的配置信息。log对象是内核中日志对象,挖掘算法中通过日志对象可以记录算法运行的中间状态和数据。
接口中的Run方法是由内核反射后调用的算法运行的主方法。
GetAlgorithmName方法由挖掘算法实现,提供挖掘算法的名称,此名称也是挖掘算法配置文件的名称。内核反射调用挖掘算法名称进行算法配置对象的读取和装配。
对于通用数据挖掘系统的主调方法非常简单,所有算法插件调用方法都是一样的,如下所示。
IAlgorithm algorithm= GetInstance(algorithmName);
algorithm.Build(instance, para,log);
algorithm.Run();
其中GetInstance方法就是根据用户选择的算法名称得到实例化后的对象,代码如下:
static IAlgorithm GetInstance(string algorithmName)
{Type tp = Type.GetType(algorithmName);
object obj =
Assembly.LoadFile(dllPath).CreateInstance(algorithmName);
IAlgorithm ia = (IAlgorithm)obj;
return ia; }
GetInstance方法利用C#提供的反射功能,根据算法的名称,动态实例化相应算法的内存对象,并且将此对象强制转换成算法接口。因为所有挖掘算法实现了同一个接口,所以从通用数据挖掘系统的角度上屏蔽了所有挖掘算法内部实现的差异性。
2.3 通用数据挖掘系统工作流程。
通用数据挖掘系统内核启动过程:内核启动时首先由配置管理器读取并验证默认的主配置文件,然后根据主配置文件由插件管理器按顺序检查并获取插件元数据信息,最后由对象加载器加载并实例化内核插件。内核启动成功后,显示主界面,等待用户操作。
数据挖掘主流程是用户选择并配置数据源插件、算法插件和输出插件,确定选择后,由通用数据挖掘系统内核依次验证、加载并运行相应插件。
结束语
数据挖掘模块是在当前的很多应用系统中重要组成部分,通过数据挖掘模块可以有效的深入发现已获取数据的深层次的知识。通过挖掘的知识可用于决策支持、信息管理、过程控制,以及对应用系统自身的数据优化。
本文提出并实践了一个通用的数据挖掘系统,此系统通过良好的系统架构、统一的操作接口、简单的插件模型,降低了各子模块之间的耦合性,提高了系统的扩展能力。使用本系统,开发者只需把精力用于挖掘算法的研发,通过简单的插件配置,使应用系统支持各种挖掘处理算法。
[1]Pang-Ning, Tan;Michael, Steinbach. 数据挖掘导论[M]. 北京:人民邮电出版社,2011:1-8.
[2]Ian H Witten,Eibe Frank,Mark A Hall. 数据挖掘实用机器学习工具与技术[M]. 北京:机械工业出版社, 2014:14-20.
[3]Jiawei Han,Micheline Kamber,Jian Pei. 数据挖掘概念与技术[M]. 北京:机械工业出版社, 2014:1-26.
[4]刘红岩,陈剑,陈国青. 数据挖掘中的数据分类算法综述[J]. 清华大学学报(自然科学版), 2002(6):727-730.
[5]王光宏, 蒋平. 数据挖掘综述[J]. 同济大学学报,2004(2):246-251.
[6]贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J]. 计算机应用研究, 2007(1):10-13.
[7]钟晓,等. 数据挖掘综述[J]. 模式识别与人工智能,2001(1):48-55.
[8]王孝明,胡健,等. 基于.NET平台可复用软件框架的设计与实现[J]. 计算机工程,2004(22):76-78.
[9]崔冬华,刘吉林. 基于反射的低耦合软件框架的研究[J]. 计算机信息,2007(10):232-234.
[10]孙玉钰. 基于.NET组件技术的插件式框架的研究[J]. 计算机应用与软件,2009(6):143-145.
Class No.:TP31 Document Mark:A
(责任编辑:蔡雪岚)
On Structure and Design of General Data Mining System
Wang Fengkun,Zhang Tingting
(Anhui Technical College of Mechanical and Electrical Engineering, Wuhu, Anhui 241000,China)
Data mining is the effective function of the current application system expansion, with the data mining module, we can enhance the value of the application system and found the deep knowledge of the data. But the diversity of data mining algorithms and the development of high difficulty limit the wide range of data mining applications. In order to improve the data mining module versatility and scalability, reducing the coupling with a particular field, people has designed a loose, expanded, field independent, support dynamic configuration of the general data mining system. We provided a general data mining system with high-level language support function of the reflex, uniform interface simple plug-in model and the data mining process of each function module. Through the kernel dynamic load and run the plug-in, the system can effectively increase the commonality and expansibility of the data mining module.
data mining; framework; low coupling; reflection; plug-in
汪峰坤,硕士,讲师,安徽机电职业技术学院。研究方向:数据挖掘,大数据处理。 张婷婷,硕士,讲师,安徽机电职业技术学院。研究方向:数据挖掘,无线网络协议分析。
2016年安徽省高校省级自然科学研究重点项目“基于云平台的健康体检项智能推荐系统研究”(KJ2016A136);2014年安徽省高校省级自然科学研究重点项目“基于移动客户端的教职工健康体检数据智能分析管理系统的研发”(KJ2014A038);安徽省质量工程项目(2014mooc093)。
TP31
A
1672-6758(2016)11-0060-4
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
现代装饰(2021年1期)2021-03-29
计算机与网络(2021年22期)2021-01-13
电脑爱好者(2020年10期)2020-07-28
信息安全研究(2018年12期)2018-12-29
数码世界(2018年2期)2018-12-21
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
浙江大学学报(工学版)(2015年2期)2015-05-30
