
Onboard:以数据驱动的敏捷软件开发协同工具
2016-12-22 04:15张世琨
计算机研究与发展 2016年12期
陈 龙 叶 蔚 张世琨
(软件工程国家工程研究中心(北京大学) 北京 100871)(chenlongpku@163.com)
Onboard:以数据驱动的敏捷软件开发协同工具
陈 龙 叶 蔚 张世琨
(软件工程国家工程研究中心(北京大学) 北京 100871)(chenlongpku@163.com)
Scrum是一种兼顾计划性与灵活性的敏捷开发过程,能让软件开发团队具有快速工作和响应变化的能力.软件开发生命周期中每一个环节都会产生大量的数据,如果能记录下这些数据进行分析,并通过可视化等手段展示和反馈,则能进一步促进团队管理、项目管理,提高开发效率.现有的软件开发管理工具中,项目管理和代码管理往往是相互独立的,这导致了数据的分散和未充分利用.为推广以Scrum为核心、以数据为驱动的敏捷软件开发过程,开发了一款基于云服务的Onboard敏捷软件开发协同工具, 利用代码提交和任务的关联,创造性地将敏捷过程管理、源代码管理和项目管理有机地整合到一起,支持端到端的软件全生命周期管理,从而能记录下软件开发过程中产生的所有数据并提取有价值的信息,为中小软件开发团提供一站式的敏捷开发管理与协同服务.1)介绍了Onboard的设计理念;2)围绕着“如何利用软件开发过程中产生的数据更好地支持敏捷开发过程”和“如何评估团队成员贡献度”两大课题,全面介绍了数据可视化和数据分析在Onboard敏捷软件开发协同工具中的应用,并针对一系列相关问题提出了解决方案;3)对值得进一步研究的问题进行了展望.
数据驱动;敏捷软件开发;Scrum;软件生命周期;数据可视化;代码提交与任务关联;贡献度评估;代码影响行数
20世纪60年代中期“软件危机”的出现,使得人们不得不重新认识软件开发的标准、方法和技术.2001年,17位软件专家聚集在一起概括出了让软件开发团队能够快速工作、响应变化的价值观和原则,进而产生了我们现在所熟知的《敏捷软件开发宣言》[1].研究表明,由于软件是迭代发布的,在一个迭代过程中变化容易得到控制,因此敏捷软件开发过程能有效地减少需求变化产生的成本[2].
遵循敏捷价值观和原则设计出来的软件开发过程模型都是敏捷开发过程模型,其中近年来业界比较流行的是Scrum,一种兼顾计划性与灵活性的敏捷开发过程.Scrum一词的含义源自橄榄球[3],在19世纪90年代由Sutherland及他的开发团队提出,并在21世纪后由Schwaber和Beedle做了进一步的改进[4].Scrum开发过程从一开始就假定了混乱的存在[5],因而使得使用它的敏捷开发团队在必然存在的不确定性面前得以顺利工作.Scrum团队以短小的迭代(sprint)为单位进行工作,关于团队中的角色和典型的迭代流程的介绍可参见附录A.
然而Scrum方法并不是万灵药.国内第一位看板教练吴穹在《精益开发与看板方法》[6]一书的推荐序中指出,在他多年敏捷咨询的过程中,经常需要进场拯救那些将Scrum实施成小瀑布的项目.Scrum方法中的看板和燃尽图为项目负责人把握项目进度提供了最基本的工具,但仅仅有这些工具是不够的,比如项目负责人无法利用看板和燃尽图监控软件的质量.软件开发团队需要利用更多更先进的工具促使开发过程达到敏捷的状态.
经常困扰项目负责人的另一个问题是:如何公平、高效地对团队成员的贡献进行评估.如果需要手动去统计每个成员完成了几个任务、提交了多少行代码等,是非常琐碎的.此外,一个软件团队往往还分成若干小团队开发相关但相对独立的子项目,尤其是在移动互联网快速发展的背景下,一个团队很可能同时开发Web端和多个移动端的产品,这无疑使手动的评估过程变得更加繁琐.
事实上,软件开发生命周期的每一个环节都会产生大量的数据,如果能记录下这些数据并对这些数据进行分析,提取有价值的信息,并通过可视化等技术进行信息的展示和反馈,则能够为开发团队的建设、项目进度和质量的控制、工作流程的完善等提供有力的支持,也为自动化评估团队成员的贡献提供了可能.
团队成员间合作和沟通的传统媒介往往是非常朴素的,比如面对面的沟通、白板、海报板、索引卡和便签等[7].这些手段无法将软件开发过程中产生的数据积累起来并加以利用.近些年来,很多软件开发管理工具被开发出来,但这些工具往往功能比较专一,比如缺陷管理、源代码管理、任务管理等,导致软件开发过程中产生的数据过于分散,未能被充分整合利用.
国内项目管理工具的领跑者Tower从去年(2015-07-09)在标准项目之外开始支持敏捷项目[8],但其并没有融入Scrum的流程即迭代.该产品也提供了团队成员贡献度的统计,但仅仅是计算了完成任务数量的百分比.此外,由于定位于一般的团队项目管理,Tower并不支持源代码管理.
Github是基于Git的代码托管、版本管理和协同开发的云平台,集成了issue(类似于缺陷)管理、持续集成等功能,是开源软件社区协作开发的首选.Github本身不支持以任务为核心的项目管理,这点和开源软件的开发特点比较吻合,但无法满足敏捷软件开发团队的需求.
还有一些工具,试图整合项目管理和代码管理.国内比较知名的有Coding.Net,但它并不支持敏捷开发,并且项目管理和代码管理是相对独立的模块,没有能有效整合并利用软件开发过程中产生的数据.
我们认为,对于软件开发团队来说,项目管理和代码管理是不可分割的整体.为推广以Scrum为核心、以数据为驱动的敏捷软件开发过程,我们开发了一款基于云服务的Onboard敏捷软件开发协同工具,利用代码提交和任务的关联,创造性地将敏捷过程管理、源代码管理和项目管理有机地整合到一起,支持端到端的软件全生命周期管理,从而能记录下软件开发过程中产生的所有数据并提取有价值的信息,为中小软件开发团提供一站式的敏捷开发管理与协同服务.
本文结构如下:1)介绍了Onboard敏捷软件开发协同工具的设计理念、功能及架构,并和市面上主流的几款相关的项目管理软件进行了对比;2)围绕着如何利用软件开发生命周期中各个环节产生的大量数据更好地支持敏捷开发过程、评估团队成员的贡献度,介绍了Onboard开发团队在数据可视化和数据分析的实践,着重讨论了任务和代码的关联、代码仓库的可视化、团队成员贡献度自动化评估、缺陷预警和责任人推荐等问题;3)总结全文,列举主要贡献,并展望进一步的工作.
1 Onboard介绍
Onboard致力于做最专业的敏捷软件开发协同工具.Onboard是注册即用的云服务*http://onboard.cn,能够通过Web,iOS和Android多种平台使用,支持无处不在的开发协同.
Onboard核心价值观是推广以Scrum为核心的敏捷软件开发过程.Onboard将产品设计、编码、测试、持续集成、发布和运维等各阶段进行有机地连接和集成,支持端到端的软件全生命周期管理,提高软件开发人员之间的协作效率,从而加速软件开发,为中小软件开发团打造一站式的敏捷开发管理与协同服务.
Onboard提供的各项功能从逻辑上可以分为3个类别,彼此紧密联系.
1) 敏捷过程管理
① 通过看板来规划敏捷软件开发中的每一次的迭代,完美支持Scrum;
② 通过看板来追踪需求、任务和缺陷的状态;
③ 展示每一次迭代的燃尽图,以及代码行数和代码提交等丰富的统计信息.
2) 源代码管理
② 专业化的Code Review功能,对每一个代码合并请求、每一次代码提交、每一行代码都能讨论;
③ 需求、任务和缺陷与代码有机关联,可以看到所有相关的代码提交;
④ 后台整合了Sonarqueb代码质量分析工具,网站通过访问后台的api展示分析的报告,其中包含技术债务等信息,便于团队对代码质量进行把关;
⑤ 后台整合了Jenkins服务器,用户可以在网站上撰写自己的脚本,执行代码的构建和测试,并可查看所有的历史任务和执行结果,实现持续集成;
⑥ 利用Docker容器技术为用户部署Web应用.
3) 项目管理
① 通过Git客户端与系统进行交互,如关联任务、完成任务等.
② 具备话题讨论、任务分配、团队日历、在线文档、文件共享、团队管理这些通用的项目管理功能;
③ 项目所有相关活动都能够清晰地自动记录,并同过大量数据可视化,细粒度地展现项目的全貌;
④ 通过邮件和客户端将团队动态第一时间推送给团队成员;
⑤ 为项目的所有关键信息建立了全文索引,提供了搜索功能.
此外Onboard还实现了功能的插件化,能让用户打造适合自己团队项目的工具集.Onboard现已开源,其开源版本的源代码可以在Github*https://github.com/sercxtyf/onboard上找到.
Onboard的整体架构如图1所示.
Onboard在设计之初就考虑了数据的积累.从一句评论到一次代码提交,凡是用户在Onboard上进行的操作都会生成活动的日志.这为进一步做数据挖掘提供了数据来源,进而可以从数据中提取有价值的信息.
Onboard将敏捷过程管理、源代码管理和项目管理有机地整合在一起,从而支持软件全生命周期的管理,并对软件开发过程中产生的数据进行收集和分析,在软件工程业界是独树一帜的.表1把Onboard和其他一些业界主流的基于云服务的项目源代码管理工具从功能上进行了对比.

Fig. 1 The system architecture of Onboard, an agile software development collaboration tool.图1 Onboard敏捷软件开发协同工具的系统架构图
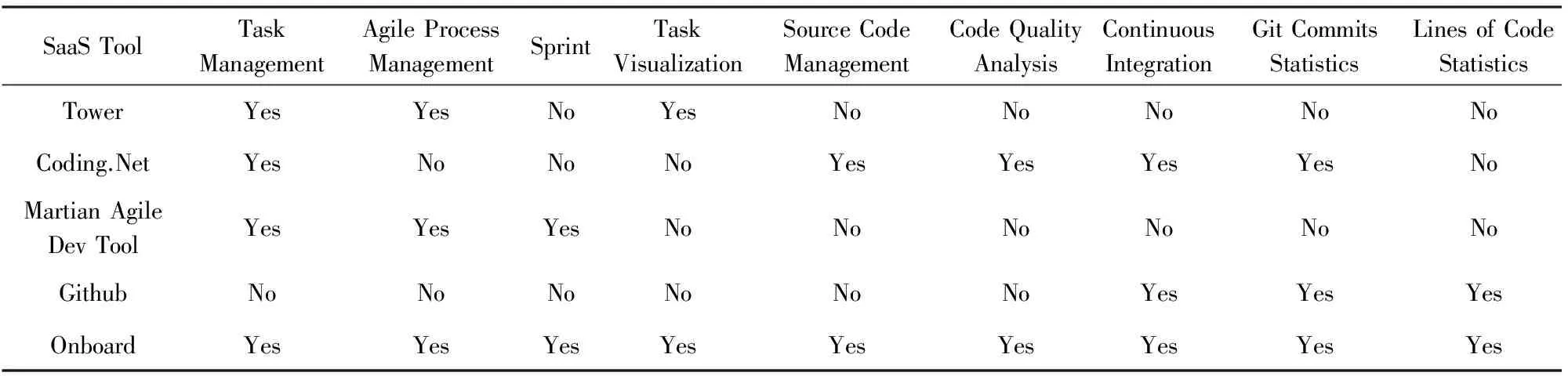
SaaSToolTaskManagementAgileProcessManagementSprintTaskVisualizationSourceCodeManagementCodeQualityAnalysisContinuousIntegrationGitCommitsStatisticsLinesofCodeStatisticsTowerYesYesNoYesNoNoNoNoNoCoding.NetYesNoNoNoYesYesYesYesNoMartianAgileDevToolYesYesYesNoNoNoNoNoNoGithubNoNoNoNoNoNoYesYesYesOnboardYesYesYesYesYesYesYesYesYes
2 代码提交与任务关联
敏捷开发强调的是对变化的快速响应,而实际开发过程中,Scrum敏捷开发团队最容易进入的一个误区就是把“敏捷”等同于“快速”,把“增量式地产出可工作的产品”等同于“尽可能按期完成迭代中的所有任务”——当对照燃尽图发现进度落后时,团队的第一反应是要加快开发速度、甚至加班加点赶进度,而不是去查找影响进度的因素.如此一味追求进度,导致对软件质量的忽视,也就无怪乎劣质代码入库、产品“裸奔”上线等情况会频频发生.
软件质量保障是软件开发生命周期中不可缺少的一个环节,而软件的质量主要体现在代码的质量.Scrum方法所描述的软件开发过程,以及常用的看板、燃尽图等工具,都是着眼于进度管理的,无法辅助软件质量的管理.因此,敏捷软件开发团队,需要这样一款工具,能把敏捷过程管理和源代码管理结合起来.
但是,仅仅把简单敏捷过程管理工具和源代码管理工具的功能加在一起是不够的.一个需求是否被满足、一项任务是否完成,取决于相关的代码是否实现以及相关代码的质量,两者是密不可分的.因此需要有一种机制能把敏捷过程管理和源代码管理有机地联系在一起,发挥“1+1>2”的作用.敏捷过程管理是对需求和任务的管理,源代码管理是对代码的管理,鉴于此,我们提出了代码提交与任务进行关联的机制.这里的任务是广义的,既包含满足产品需求所要实现的具体步骤,也包含待修复的缺陷.
有2种途径实现代码和任务的关联:1)将合并请求(pull-request)和任务关联;2)将代码提交(commit)和任务关联.
代码提交是指本地开发时增量保存当前新修改的代码,同时在代码提交注释(commit message)中注明这些代码的作用.一般建议是及时提交修改,以便发生错误时能快速复原代码,故一个任务往往对应多次代码提交.Github支持在commit message里面填写#{issueId},当代码提交推送至Github时,系统自动识别#{issueId},将代码提交和相应的issue关联.如果在#{issueId}之前添加关键词close或fix,还可以自动关闭该issue.Github中的issue类似于缺陷,但不完全等同,因为issue还可以是讨论或建议等.
相比之下,在敏捷开发过程中,将代码提交和任务相关联是更合适的选择.迭代中的任务主要是需求分解成的具体实现步骤,Scrum方法提倡任务粒度细化,以小时为单位估计任务的工作量,故一次合并请求中可能包含多次代码提交,并且对应着多个相关的任务.因此,无论在多个任务中关联一个合并请求,或是在一个合并请求的描述中添加多个任务,都比较繁琐.相反,一次代码提交通常只对应一个任务,若借鉴Github的做法,利用代码提交的commit message实现代码和任务的自动关联,则操作十分简便.
我们在Onboard中采用了第2种途径实现代码和任务的关联,并做了如下改进:
1) 迭代中的看板由“未开始”、“正在做”和“已完成”3个基本栏目构成,团队可根据自身需要在“正在做”和“已完成”之间添加新的栏目,比如“等待测试”、“等待验收”等.当commit message中的任务编号前添加了fix或close等关键字后,默认将该任务从当前栏目移动到下一个栏目,而非完成任务.
2) 若发生漏操作或误操作,在仓库所有代码提交的列表页面中,可以添加或解除任务关联,亦可在某个任务的相关联的代码提交列表中解除关联.
3) 创建合并请求时,默认将本次合并请求所包含的所有代码提交的commit message合并为合并请求的描述,代码审核者可点击描述中的任务编号,便捷地打开相应的任务进行查看.这也间接地实现了合并请求和任务的关联.
将代码提交和任务关联,从功能上打通了敏捷项目管理和源代码管理,具有7点好处:
1) 团队成员在提交代码的同时就能改变任务的状态;
2) 便于产品负责人跟踪任务的进度和具体实现;
3) 提供关于任务更有价值的信息,便于项目负责人了解任务的工作量和质量;
4) 对于缺陷,能通过关联的代码提交准确定位到产生缺陷的代码文件及具体位置;
5) 便于团队知识的积累、分享和传承.需求分解成了任务,任务关联了代码,如果有新的团队成员加入,或者团队成员之间互相学习等,希望了解一项功能是具体如何实现的,可以顺着“需求→任务→代码”这条线索,定位和功能相关的代码,从代码级别深入了解;
6) 能从任务和代码2个维度共同刻画出“开发者画像”;
7) 可以更准确地判断出有代码关联的任务的结束时间,从而更准确地描述任务尤其是缺陷的生存期.
3 敏捷开发过程的可视化分析
数据可视化主要是借助于图形化手段,清晰有效地传达与沟通信息.和计算机相比,人脑更善于理解视觉图像并从视觉图像中提取有价值的信息,因此,数据可视化技术能更有效地帮助人们理解数据.软件开发生命周期的每一个环节都会产生大量的数据,可视化分析的方法是从这些大量的数据中提取有价值的信息的有效手段.
Onboard收集了用户在开发过程中产生的所有数据,并通过可视化的技术进行信息的提取和展示,从而为开发团队的建设、项目进度的控制、工作流程的完善、团队成员贡献的自动化评估提供有力的支持.
在可视化实践的过程中,我们强调图表的可交互性.可交互的图表具有更好的用户体验,也能丰富图表的语义,展现复杂、多维度的数据.比如,在Onboard提供的统计图中,可以通过选择不同的项目成员,对展示的数据进行筛选;也可以选择查看不同时间区间的数据;响应用户操作时,多张统计图可以联动地变化等.
在可视化的机制上,我们采用了先用Web Api从后台获取相关数据、后用Javascript在前端处理数据并绘图展示的方式.我们在开发过程中使用了D3.js等第三方开源的Javascript库.
由于可交互性的需求,在获取一组数据时,先拿到了所有成员的数据,存储在图表对应的Javascript对象中,再根据用户的操作筛选数据.这样可以避免在切换成员时频繁向后台发送ajax请求,前端处理数据、绘图的速度相对较快,用户体验较好;此外可以同时展示全体成员和个体的2张图,进行对比.
下面将介绍在Onboard中,如何利用可视化分析支持敏捷开发过程.
3.1 活动记录的Punch Card图
Punch Card中文意思是穿孔卡,最早运用在IBM计算机上,通过在纸片上不同的位置上穿孔代表不同的数据.而在数据可视化领域,Punch Card又被赋予了新的含义.以活动记录的Punch Card图为例,纵轴刻度表示周一至周日,横轴刻度表示0点至23点,于是平面上就由坐标轴形成了多个交点.每个交点上的一个圆代表数据点,数值为对应的一个小时内的活动记录数量,圆的大小或颜色的深浅代表数值的大小.如图2所示:
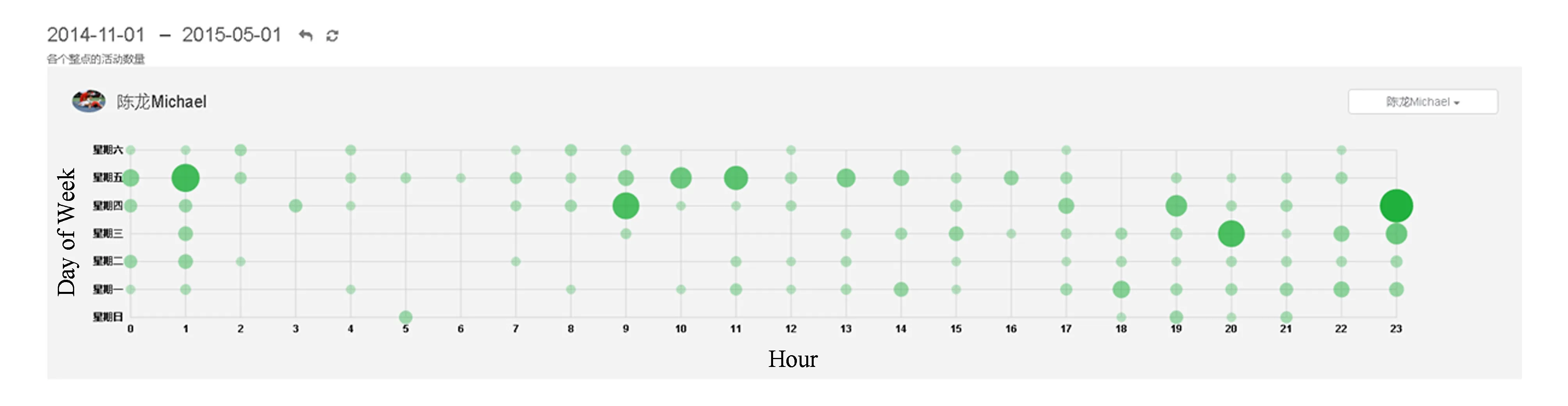
Fig. 2 User’s Punch Card of number of activities on Onboard.图2 用户在Onboard上活动数目的Punch Card图
用户在使用Onboard时,任何的操作都会生成一条活动记录.获取一段时间内用户活动记录的数目并绘制成Punch Card图,可以发现一些有趣的信息,从而帮助项目负责人了解团队成员的工作状态.比如:
1) 假设每周五是开迭代评审会和反思会的时间,如果发现团队成员的活动记录突出集中在周五的前两天,说明团队中存在赶deadline的现象,平常可能有消极怠工,需要及时干预;
2) 可以了解团队成员的偏好,如喜欢白天工作还是夜里工作;
3) 通过成员之间的对比,判断整个团队工作的步调是否一致,是否有良好的协作.
3.2 缺陷统计图
缺陷的及时发现和修复是软件开发过程中不可缺少的一个环节.一个成员发现缺陷数目和修复缺陷数目的多少,可以反映出该成员是否具有产品的主人翁精神.在缺陷管理模块中,Onboard提供了对比团队成员之间发现缺陷数目和修复缺陷数目的2张饼图.
3.3 代码提交数据可视化
代码提交次数和行数是软件开发团队衡量工作量最重要的指标之一.Github为托管在上面的代码仓库提供了丰富的统计图,非常值得参考,特别是Contributors,Commits和Punch Card.
如图3所示,在Contributors统计图中,可以在右上角切换3个统计量:增加的代码行数、删除的代码行数、代码提交的数目.左上方注明了仓库存在的时间,时间下方是一句说明,意思是“只统计对master分支的贡献,并且不包含合并请求时产生的代码提交”.位于中间的第1张图在时间轴上呈现了master分支上统计量随时间的变化,时间轴的下方枚举了不同贡献者的数据.在第1张图中可以用鼠标拉取时间窗,下方的不同贡献者的统计图会随之变化,只展示时间窗内的数据.
在敏捷开发过程中,也需要统计团队成员的代码贡献量.我们在Onboard中同样做了代码提交的可视化,和Github有相似之处,但也有创新.
最大的一点不同是,我们采用了多分支的统计而不是基于master单一分支的统计.这是考虑到了团队项目和开源项目固有的区别.对于Github上的开源项目,任何人都可以创建新的分支,在上面修改或添加代码并提交,这些代码可能是重复的、不必要的甚至错误的.因此,判断开发者是否对开源项目产生贡献,比较合理的是看他提交的代码有没有被合并进master分支.而在敏捷开发团队中,一般不会出现“无用功”的代码,因此,凡是同步到Onboard上托管的中央仓库的分支所包含的代码提交都应计入工作量的统计之中.
另外,我们把代码的增加行数(最上方的折线)和删除行数(最下方的折线)并排显示在折线图中,同时显示一条虚线(中间的折线)表示仓库代码总量的变化,并在图的下方添加了团队成员对比的饼图,如图4所示.
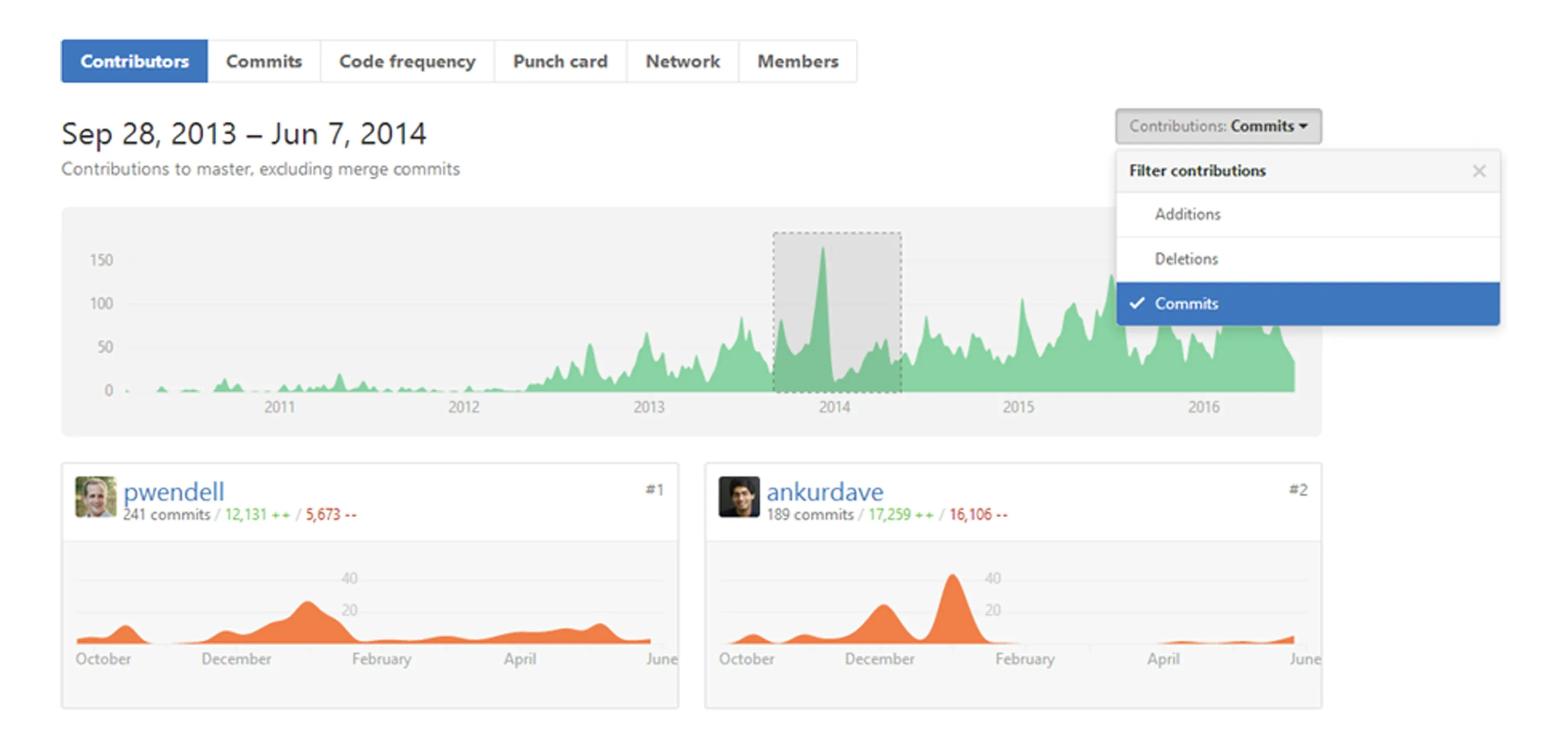
Fig. 3 Contributors graphs on Github (based on Apache Spark project).图3 Github贡献者统计图(以Apache Spark项目为例)
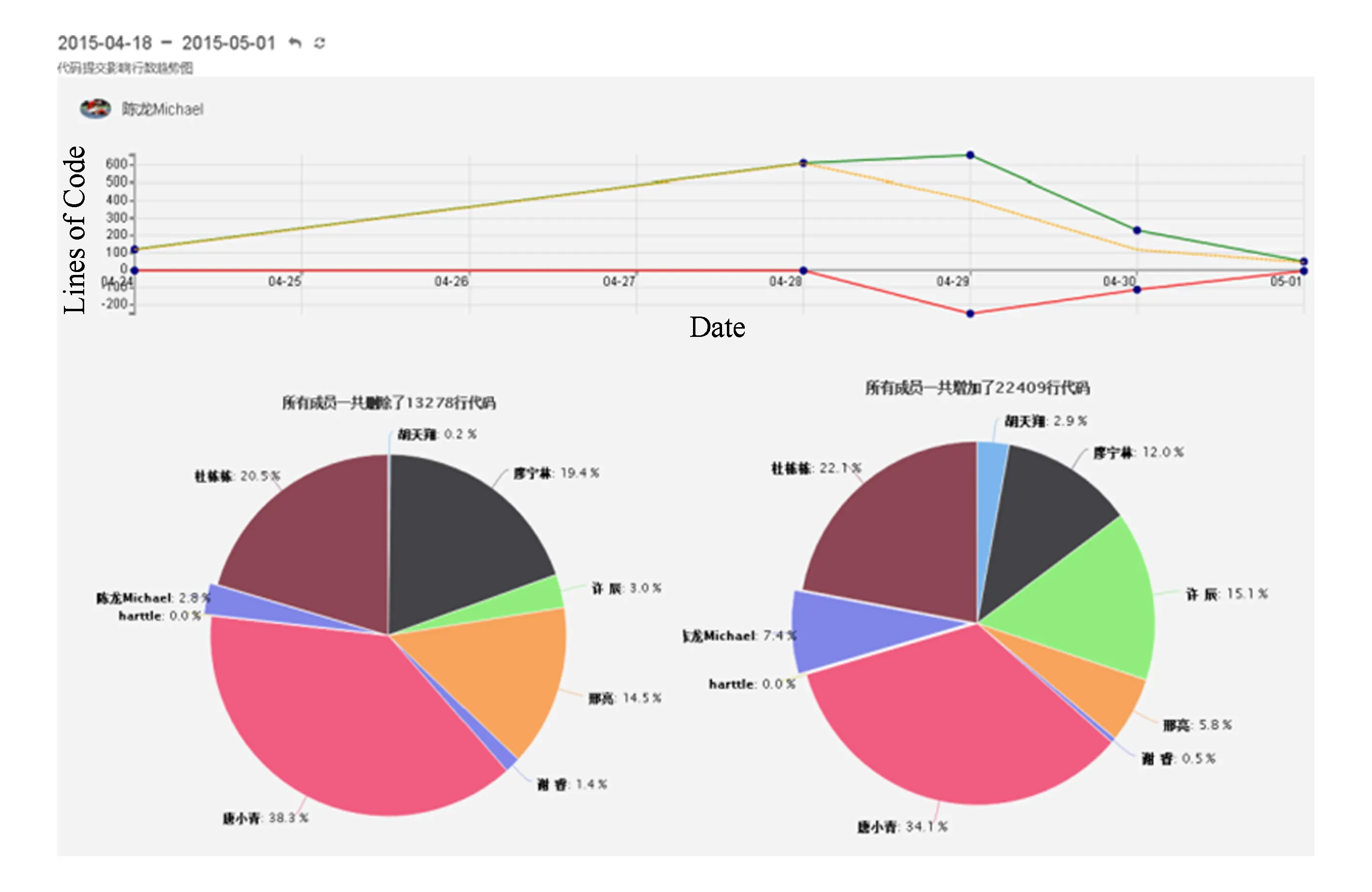
Fig. 4 Code contribution graph on Onboard.图4 Onboard中代码行数统计图
值得一提的是图4中3个图是联动的:点击任意饼图中的切片,2张饼图相应的切片都会突出,在上方的折线图中则会相应显示切片对应的用户的统计数据.
代码提交的次数则单独制作了一张统计图,与图4类似.此外还绘制了代码提交次数的Punch Card.
另一个创新的地方是在数据点的tooltip中显示了数据点包含的代码提交列表,而不仅仅是代码总行数或总次数.点击代码提交的ID,会打开一个浮动的窗口,显示这次代码提交影响的代码.这大大增加了统计图的可交互性.如图5所示.
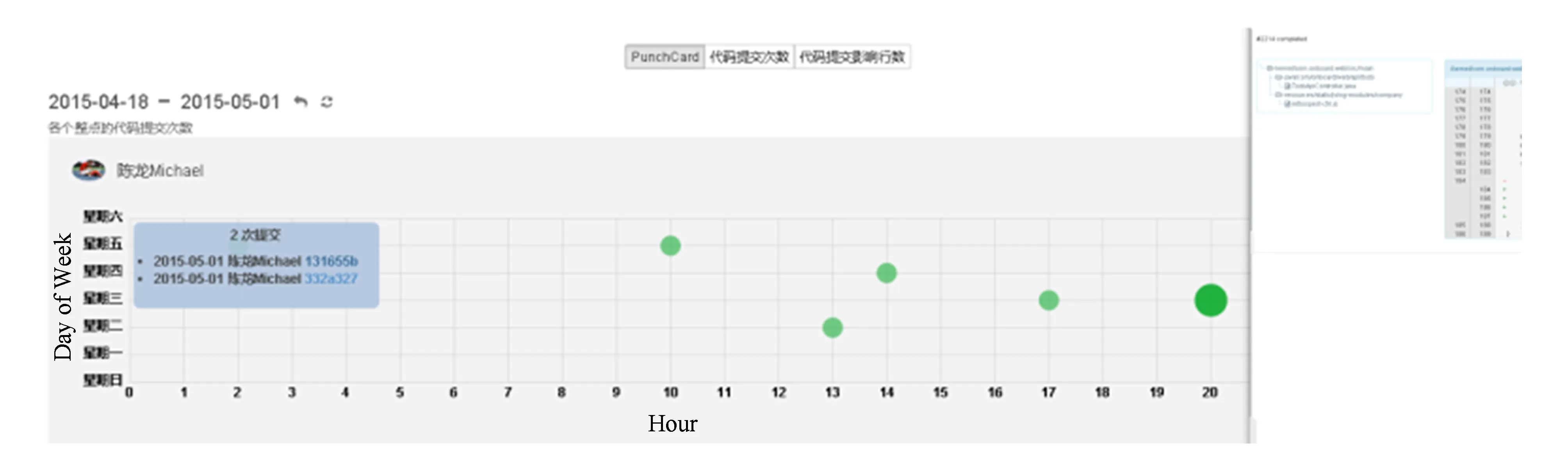
Fig. 5 Punch Card of number of commits with enhanced tooltips.图5 带列表和导航的代码提交次数Punch Card图
我们额外维护了一张Git_email和Onboard_user的关联表,目的是将代码提交准确地和团队成员对应,避免用户在Git中设置的email和用户在Onboard中设置的email不一致而产生的问题.
3.4 迭代总结报告
除了Scrum方法中常见的燃尽图之外,我们在Onboard中还设计了一份详实的迭代总结报告.报告中除了列举本次迭代中已满足的需求、完成的任务之外,还整合了燃尽图、任务统计、代码提交统计等统计图.利用报告,在召开迭代总结会时能够做到3点.
1) 确认迭代完成的质量;
2) 了解各个团队成员的工作量和工作状态;
3) 发现迭代中存在的问题,在下次迭代中进行改进.
有2点特别值得注意:1)这些统计图是联动的,可以同时切换显示某个成员的统计数据;2)在后台加入了snapshot(快照)的机制,一旦结束当前迭代之后,这份报告将永远保存下来,里面的数据和统计图都不会发生变化,以供日后回顾时查看.
4 团队成员贡献度评估
4.1 代码影响行数(affected lines of code, ALOC)
代码量是软件开发团队中衡量成员工作量的最重要的指标之一.在用Git进行版本管理的代码仓库中统计代码量时,通常会计算2个指标:1)增加的代码行数;2)删除的代码行数,对每次代码提交分别计算再累加而成.Github和Onboard中的代码统计都是这样做的.那么,问题出现了:给出了增加的代码行数和删除的代码行数,如何衡量代码量呢?
在开发过程中,对代码的改动无外乎3种情况:增加代码、删除代码、重构代码.在重构代码时,既有代码的增加,也有代码的删除,因而不能把增加的代码行数和删除的代码行数简单加在一起来衡量代码量.若仅考虑代码的增加量,有这样一个缺陷:代码重构时,常常会通过设计模式或更好的算法,用更精炼的代码替换原有代码,在这种情况下,用较少的新增的代码行数,无法衡量减少了更大篇幅代码所做工作的价值.
另一个需要考虑的问题是:删除的代码行数是否计算在工作量之内?我们认为,单纯地删除代码不考虑在内.
此外,还有2种特殊情况需要区别对待:引入第三方库,往往会增加大量的代码行数;挪动一个代码文件的位置会产生一对数值很大且相同的增加的代码行数和删除的代码行数.
综合以上考虑,我们提出了代码影响行数ALOC的概念来衡量代码量.把一次代码提交的ALOC记为commitALOC,把一处代码增量差异(diff)的ALOC记为diffALOC.我们是这样计算commitALOC的:
若本次代码提交是分支合并产生的合并结点,忽略不计;
对代码提交中的每一处diff: 若只有代码的增加,则diffALOC=增加的代码行数;
若只有代码的减少,则diffALOC=0;
若既有代码的增加也有代码的减少,则diffALOC=max(增加的代码行数,删除的代码行数);
若diffALOC超过了限制(如300行),则diffALOC=0;
累计所有diffALOC,得到一次代码提交的commitALOC;
若commitALOC超过了限制(如3 000行),则commitALOC=0.
在实际使用Onboard的过程中,验证了ALOC是衡量代码量的有效指标.
4.2 跨项目的团队统计
Onboard允许一个团队建立多个项目,一名团队成员可以加入一个或多个项目.每个项目相对独立,有自己的代码仓库和迭代等.第3节所介绍的数据可视化分析都是基于单个项目的.
实际调研后发现,一个开发团队往往同时并行若干个子项目,特别是创业型的团队,而项目负责人只有一个.例如Onboard团队曾在某一段时间内,同时开发Web应用、安卓应用和苹果应用.手动统计每个成员的工作量,比如提交的代码行数等是一件非常繁琐的事情.有了数据可视化工具的辅助,这项工作就大大简化了,通常只要查看统计图、在统计图中进行一些交互操作即可.但在多项目并行的情况下,项目负责人若想比较团队各个成员的工作量、了解团队整体的动态,仍需要分别查看各个项目的统计数据再进一步汇总.因此,跨项目的团队统计能够进一步解决项目负责人的痛点.
在Onboard上的团队统计页面,我们提供了这样一个可视化的统计工具,如图6所示:
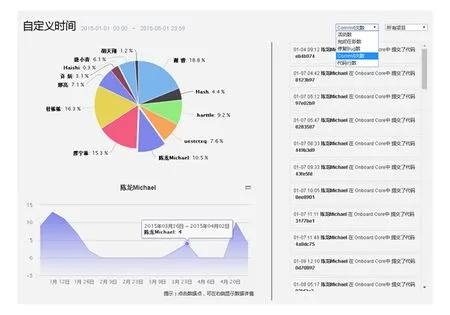
Fig. 6 Visualization tool of team statistics across projects.图6 跨项目的团队统计工具
该工具包含7项功能:
1) 有5个统计量供用户选择:活动记录数量、完成的任务数量(狭义,指从需求分解出的任务)、修复的缺陷数量、代码影响行数、代码提交次数;
2) 可以自定义统计的日期范围;
3) 可以选择团队所有项目汇总后的统计数据,也可以单独查看某一个项目;
4) 提供了团队成员之间数据对比的饼图;
5) 点击饼图中的切片,可以选择性地查看某一个成员的数据;
6) 提供了时间变化趋势图和Punch Card图,可以进行切换;
7) 点击数据点,右侧显示该数据点包含的具体内容.
4.3 团队成员贡献度的自动评估模型
软件开发生命周期的每一个环节都会产生大量的数据,而Onboard支持软件开发全生命周期的管理,并记录了用户所有的操作,这些数据的积累为建立团队成员贡献度的自动评估模型提供了可能.
我们做了这样的实验:选取若干次迭代为研究对象,获取了迭代起止时间范围内团队成员的各类数据,分别计算出每个成员的5个统计量——活动记录数量、完成的任务数量、修复的缺陷数量、代码影响行数、代码提交次数,作为自变量;从项目负责人那获取了每个迭代中各个成员的评分(百分制,团队成员互评+负责人打分)作为应变量,然后通过统计学的方法计算一个模型,能够利用5个自变量预测评分.
为了让模型有更好的解释性,我们从线性回归模型开始入手.
方案1.
Y评分~β0+β1X活动数+β2X任务数+β3X缺陷数+
β4X代码影响行数+β5X代码提交次数,β1~β5>0.
拟合后得到的结果并不是很理想.首先通过探索性分析发现,代码影响行数和代码提交次数存在很强的共线性,因此代码影响行数和代码提交次数在线性模型里面只能保留一个.保留代码影响行数后,凡是出现系数β值为负数时,就把相应的变量从模型中剔除,如此反复计算,最后得到的模型中,系数β显著不为0的变量仅仅只有代码影响行数!显然这个模型过于简略,无法投入到实际应用中去,比如它无法评价没有代码提交却有完成任务的成员的贡献量.
由于我们要求模型要有好的解释性,从而限制了β1~β5>0.其实β的含义是非常明确的,表示某一项指标在综合考核指标中所占的比例.若再加上一条所有β之和为1的限制,可以把这个问题转化为带有约束的优化问题.
方案2.
定义变量P=

损失函数为
∑|Y评分-(β1P活动数+β2P任务数+β3P缺陷数+
β4P代码影响行数)|;
约束条件为β1~β4>0,β1+β2+β3+β4=1.
编程求解过程中,可设系数β的最小步长为0.05,遍历所有β1~β4的可能取值(3重循环),返回使损失函数取值最小时β1~β4的取值.最后得到的结果是β1=0.55,β2=0.15,β3=0.15,β4=0.15.
将输出的模型应用到评估团队成员贡献度,如图7所示.图7中用p1~p19表示团队成员的姓名,同时存在不活跃的团队成员.
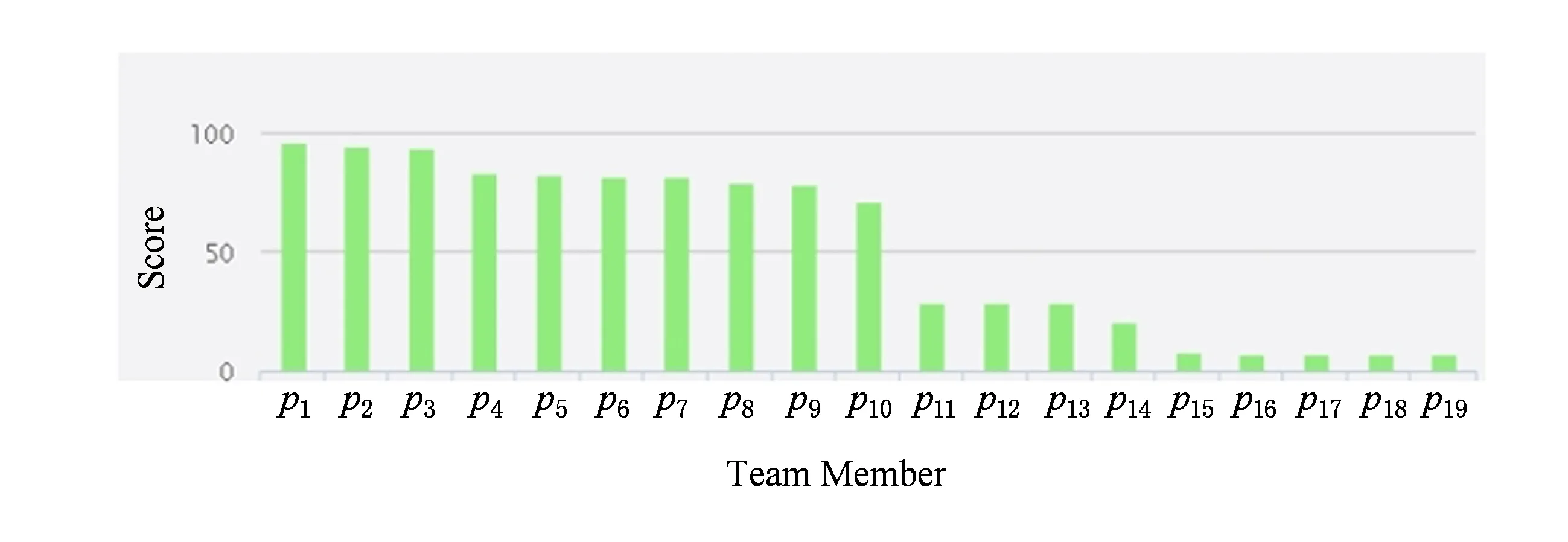
Fig. 7 Demo of team member contribution evaluation.图7 团队成员贡献评估示例
5 数据可视化和数据分析的更多应用
5.1 团队成员关键词词云
词云(word cloud)是一种有趣的、有独特视觉效果的文本信息可视化工具,最早起源于标签云,在20世纪末由Flickr等网站的大量使用而普及开来[9].词云是在一定区域内不重叠地摆放一组不同字体大小的单词形成的,字体的大小通常表示单词的权重,如词频.单词的颜色通常只是为了视觉效果的美观,没有其他含义.
将每个团队成员的关键词按一定权重制作成词云,可以一目了然地展示该成员所关注的问题、曾参与开发的功能等信息,起到类似用户画像的作用.
如何提取团队成员的关键词并计算权重呢?如果把用户看成一篇文章,把软件开发过程中积累下来的和该用户相关的文本信息的总和看成是文章的内容,那么就可以用文章关键词自动提取的技术,实现用户关键词的自动提取.
从很长的文章中提取关键词,涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但有一个简明、有效的经典算法——TF-IDF算法:
TF-IDF=词频(TF)×逆文档频率(IDF);
词频(TF)=

逆文档频率(IDF)=

可以看到,TF-IDF与一个词在文章中出现的次数成正比,与这个词在整个语料库中出现的次数成反比.
引申到提取团队成员的关键词,则:
词频(TF)=

引申后的TF-IDF可以表示对一个单词对某一用户而言的权重.
计算一个用户所有相关单词的TF-IDF并按降序排列,取前N个,就是该用户的关键词.
在代码实现过程中,我们是这样设计流程并优化的:
1) 在数据库建立一张用户-单词关联表,记录用户不同单词的词频(单词出现的次数),当用户在Onboard上操作时,就提取相关的文本(包括但不仅限于发起的讨论、评论、完成任务的内容及相关联的需求、修复的缺陷描述、代码提交中的commit message、上传文件的文件名等),进行中英文分词操作,并更新该用户这些词的词频以及所有团队成员的这些词的TF-IDF.
2) 向后台请求用户的关键词列表时,后台返回的是根据TF-IDF排序的、有数量上限的(如100个)关键词列表.
3) 绘图算法中,根据该用户的关键词数目,优化最小字体号,为了在关键词数目较少时绘制的词云不至于太过稀疏.
4) 点击词云中的关键词,跳转到搜索页面,自动显示和该用户相关的这个关键词的搜索结果.
我们用d3-cloud*https://github.com/jasondavies/d3-cloud第三方Javascript插件绘制关键词词云,展示在团队成员的个人页面,如图8所示:

Fig. 8 Demonstration of keyword cloud of a team member.图8 团队成员关键词词云示例
5.2 缺陷生存期预警
缺陷是软件开发团队不愿意遇见的,但却永远无法避免的.缺陷一旦出现,最理想的状态当然是越快修复越好,但这种“变化”很容易打乱团队的开发计划.实际开发中,严重、紧急的缺陷一般要尽快修复,而不是那么紧急的缺陷,有的团队会指定专人负责修复缺陷;有的团队习惯把缺陷搁置一旁,等累积到一定数目再集中时间修复;也有的团队在计划任务时会预留出修复缺陷的时间,将缺陷修复和新功能的开发交替进行.
Scrum方法中没有具体说明如何管理缺陷,一般而言,可以把缺陷看作一类需求,在开迭代计划会时和其他需求一并安排进入下一次迭代[3].我们建议,紧急程度较高的缺陷可以添加进当前迭代,在计划会时可以根据经验预留一定的工作量.
一个缺陷的重要程度是会随时间发生变化的,如果存在的时间越长,就越应该引起团队的重视.Onboard中设计了这样一种机制:若一个缺陷存在的时间超过了历史平均期限,就会高亮这个缺陷条目,以提醒开发团队及时处理.
首先定义随机变量T,表示缺陷的生存期,即缺陷从创建到修复的持续时间.如果缺陷有代码提交与之关联,则修复的时间点设置为最后一次提交的时间;否则,修复的时间点设置为缺陷状态更改为“已修复”的时间.
其次,选择合适的统计量描述随机变量T分布的中间值.在统计学中有3个统计量可以描述一组随机变量取值的中间值:平均数、中位数和众数.众数适用于随机变量取值有限的情况,不适用于时间变量T.假设当前已有n个已经修复完成的缺陷,下面分别就采用平均数的和采用中位数的2种方案分别展开讨论.
1) 采用均值和标准差
假设T服从正态分布N(μ,σ),则当ti>μ,提醒用户该缺陷存在的时间超过了历史平均时长;当ti>μ+σ时,提醒用户该缺陷存在的时间过长.其中μ和σ分别表示均值和标准差,由已修复的n个缺陷的t计算得到.
方案1的问题在于:1)均值容易受到异常值的影响;2)正态分布的假设不一定成立.
但方案1的优点在于均值和方差计算简单,时间复杂度是O(N),并且,均值和方差可以通过递归计算得到,证明如下:
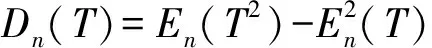
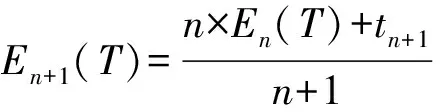
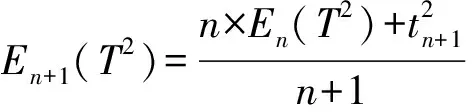
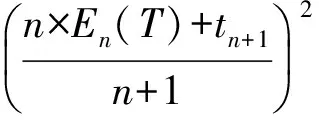
对于正态分布,方差Dn(T)=σ2,期望En(T)=μ,因此,只需保存当前的En(T)和En(T2),当有一个新的缺陷修复完成时,利用上面的公式就计算出En+1(T)和En+1(T2),从而快速计算得到新的μ和σ,时间复杂度是O(1)的.
2) 采用分位数
利用基于快速排序的Top-K算法(在快速排序的过程中可得到第K大或第K小的数,不需要全部排序完成后就能得到结果),计算出T的50%分位数t0.5(即中位数)和75%分位数t0.75,当ti>t0.5时,提醒用户该缺陷存在的时间超过了历史平均时长;当ti>t0.75时,提醒用户该缺陷存在的时间过长.
和均值相比,分位数受异常值的影响很小,因而方案2更健壮.
平均情况下Top-K算法的时间复杂度是O(N)的.但是分位数需要排序才能找到,无法用公式表达,无法得到递推关系式,因而在需要更新时不得不每次重新计算分位数,无法达到方案1的O(1)时间复杂度.
是否能设计一种算法,把上述2种方案的优点结合在一起呢?
考虑到距离现在越久远数据对现在的指导价值越小,因此在计算分位数时可以只考虑最新的k个数据点构成的数组.当一个新的数据点插入数组时,把最老的数据点从数组中删除,数组维持长度为k不变.以计算中位数为例,假设当前k个数据点的中位数为X0.5,最老的数据点值为Xold,插入的数据点为Xnew.若Xold
基于这样的想法,可以提出方案2的改进版:
保存当前n个缺陷的T的50%分位数t0.5和75%分位数t0.75;
当第n+1个缺陷完成修复时,
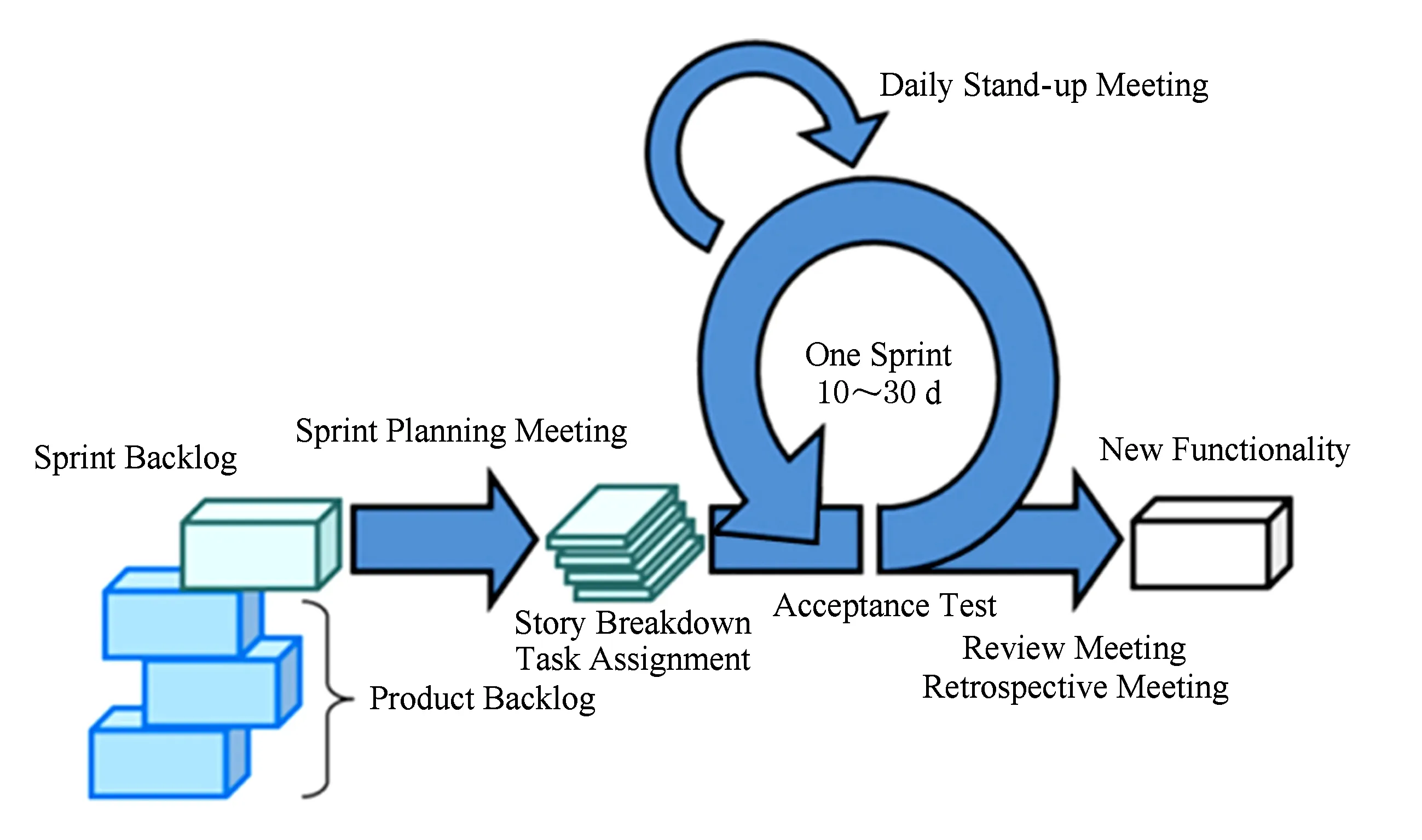
若n 若n≥k,记最新的k个缺陷的T为tn-k+1~tn,比较tn-k+1,tn+1,t0.5,t0.75的大小: 若tn-k+1,tn+1同小于或同大于t0.5,则t0.5不变,不需要重新计算; 否则,遍历tn-k+2~tn+1, 若tn+1 若tn+1>t0.5,找到比t0.5大的最小值, 记为新的t0.5; 类似地,可保留或更新t0.75的值. 在Onboard中采用了上述方案2的改进版,k=51,实现缺陷生存期的2级预警. 5.3 缺陷责任人推荐 一个缺陷生存期的长短取决于能否及时地将缺陷分配给一名合适的开发者.若将缺陷分配给了不合适的开发者,比如该名开发者不具备相关能力或没有空余时间,则会延长缺陷的存在时间.传统的缺陷跟踪系统中,缺陷的责任人大多都是人工分配的.人工缺陷责任人分配是一项耗时耗力且琐碎的工作,因而利用计算机进行缺陷责任人的自动分配成为了一个有意义的研究课题. 随着SVN,Git等源代码管理软件的流行,建立缺陷和源代码之间的联系变得可行.如果说缺陷报告描述了一个缺陷是什么,那么源代码中则包含了缺陷在哪里发生、什么时候被引入的信息.Shokripour等人[13]就另辟蹊径,把预测谁来修复缺陷的问题转化为了预测缺陷和哪些源代码文件相关的问题:首先利用一个源代码文件中的标识名称(如类名、函数名等)、代码提交的注释、代码中的注释以及和这个源代码文件相关联的历史缺陷报告这4类信息建立源代码文件的词频矩阵,当有新的缺陷产生时,通过计算相似性来预测该缺陷和哪些源代码文件相关,最后从源代码管理软件中获得最近修改这些源代码文件的开发者,作为该缺陷责任人的推荐名单. 缺陷责任人的自动分配问题还可以被看作是推荐系统问题——从大量的开发者中推荐若干开发者作为备选名单,再进行人工分配.不少文献中均使用了Top-K召回率作为算法的评价指标之一,即算法针对输入的一个缺陷给出K个可能的缺陷负责人,判断这个缺陷实际的负责人是否在这份名单里面. 综上,解决缺陷责任人的自动分配问题大致3种思路:判断缺陷和缺陷之间的相似性(缺陷分类)、判断缺陷和源代码文件的相关性、判断缺陷和开发者的相关性. 在Onboard敏捷软件开发协同工具中引入缺陷责任人推荐的功能,需要针对应用场景的特殊性设计一套解决方案.1)和专门的缺陷跟踪系统软件相比,Onboard中提供的缺陷管理模块对缺陷报告要求的字段比较单一,只需要缺陷的描述和复现步骤;2)和大型的开源项目相比,在使用Onboard的中小型开发团队的项目中,需要创建缺陷报告的缺陷数目往往比较有限.也就是说,从缺陷报告中提取出来的词频矩阵比较稀疏,用于训练的数据量也比较有限,因而不太适宜采用缺陷分类的思路,把问题转化为文本分类的机器学习问题.但反过来,Onboard的优势在于其记录了软件开发全生命周期的数据,这些数据远远比缺陷数据丰富得多,解决方案应当充分利用这些数据中所包含的信息.此外,还要求解决方案中的算法能够增量迭代,即当新创建的缺陷的责任人被分配之后,算法应当同时利用这一信息以及之前的信息,给之后发现的缺陷推荐责任人.再者,在实现5.1节“团队成员关键词词云”这一功能时已经得到了用户的词频矩阵.综合以上几点考虑,我们采用了判断缺陷和开发者的相关性的思路: 从新创建的缺陷报告中提取关键词的词频向量; 对每一个当前处于活跃状态的团队成员: 从用户的词频矩阵中得到这些关键词的TF-IDF构成用户的关键词向量,计算和缺陷关键词词频向量的余弦相似度; 将所有成员按余弦相似度从高到底排列, 若一个成员的余弦相似度明显高于其他成员, 则推荐该成员作为该缺陷的责任人; 若有若干成员的余弦相似度比较接近, 则根据当前任务数目的多少、当前正在修复的缺陷的数目等推荐最可能有时间修复缺陷的成员. 我们还考虑过给任务也添加推荐责任人的功能.但是Scrum流程中有每日立会,并且敏捷价值观第1条“个体与交互胜过过程和工具”讲的就是团队成员之间应当充分交流.一个敏捷开发团队应当是自组织的,由成员互相讨论分配任务,因而从方法论的角度看,这样一个功能是没有价值的. 我们利用代码提交和任务的关联,将项目管理和源代码管理有机整合,继而以Scrum方法为指导,开发了支持敏捷软件开发全生命周期管理的Onboard敏捷软件开发协同工具.此外,我们还提出要收集软件开发过程中每一个环节产生的大量数据,并对这些数据进行分析,提取有价值的信息,进一步促进敏捷软件开发过程的管理,并在Onboard项目中付诸实践.这是本文描述的工作的两大主要贡献.此外,我们还提出了代码影响行数ALOC的概念来衡量团队成员贡献的代码量. 本文围绕着“如何利用软件开发过程中产生的数据更好地支持敏捷开发过程”和“如何评估团队成员的贡献度”两大课题,全面介绍了数据可视化和数据分析在Onboard中的应用——丰富的、可交互的、具有洞察性的统计图表,覆盖了敏捷软件开发的各个环节;为团队成员贡献度评估、缺陷责任人分配等问题设计了解决方案. 我们对敏捷软件开发过程中产生的大量数据的分析还是比较初步的,还有更多有价值的信息值得深入挖掘.此外,还有5方面的工作正在或计划进行: 1) 遍历并统计Git代码仓库不同分支的所有代码提交的算法优化 一个分支的代码提交构成了一棵二叉树,对二叉树进行遍历是高效的,加上缓存的使用,直接遍历Git代码仓库中的代码提交的时间成本在一定统计时间范围内是可以接受的.然而,由于要统计所有分支上的代码提交,在使用过程中我们发现,当统计的时间区间超过半年时,数据就返回得比较慢了.一种可行的替代方案是:在每次上传代码提交时,将新的代码提交的信息及统计所需要的计算结果存进SQL数据表中,以空间换时间.但实际上计算效率是否提升、能提升多少,还有待进一步实验验证. 2) 一个项目不同迭代之间的对比 若选取一些指标,如延误的任务数目比例、增加的代码行数等,绘制横轴为时间的折线图,展现同一项目在不同迭代间的变化趋势,可以进一步洞察开发团队在Scrum敏捷开发过程中是否存在问题、是否有改进的地方等. 3) 自适应的团队成员贡献度评估机制 我们提出的贡献度评估模型中,各个自变量的权重是根据我们团队的实际情况计算出来的.然而各个团队之间是有差异的,这种差异性很可能导致我们提出的评估模型并不是通用的.能否设计一种带反馈的评估机制,使得团队成员贡献度评估模型能自我调整,适应使用Onboard的各个开发团队的实际情况. 4) 代码质量分析的进一步整合 Onboard中整合了Sonarqueb代码质量分析工具,为用户展示了初步的分析结果,特别是“技术债务”的分析为代码质量的控制提供了有力的支持.目前代码质量分析是相对独立的功能,如何将其整合进敏捷开发过程中,还有待进一步研究和实践.一种思路是:从包含技术债务的文件可以找到相应的代码提交,从而找到关联的任务和开发者,给予提醒. 5) 开发者画像 如第2节所述,任务和代码之间的关联,使得可以从任务和代码2个维度描绘一名团队成员.每一行代码都可以追本溯源到一个或多个团队成员.根据一个团队成员所修改过的代码文件的文件名,可以判断出代码的类型,进而判断出开发者擅长的技术;根据任务完成的时长和关联的代码,可以判断出开发者的效率;根据代码质量分析的结果以及代码是否引入了缺陷,可以判断出开发者的水平等,这些和个人关键词词云一起,能共同刻画出“开发者画像”. [1]Beck K, Grenning J, Martin R C, et al. Manifesto for agile software development[EB/OL].[2016-08-15]. http://www.agilemanifesto.org [2]Cockburn A, Highsmith J. Agile software development: The people factor[J]. IEEE Computer, 2001, 34(11): 131-133 [3]Chen Yong. Martian agile development manual[OL]. (2012-12-25)[2016-08-15]. http://blog.csdn.net/cheny_com/article/details/6616794 (in Chinese)(陈勇. 火星人敏捷开发手册[OL]. (2012-12-25)[2016-08-15]. http://blog.csdn.net/cheny_com/article/details/6616794) [4]Schwaber K, Beedle M. Agile Software Development with SCRUM[M]. Upper Saddle River, NJ: Prentice Hall, 2001 [5]Pressman R S, Maxim B R. Software Engineering: A Practitioner’s Approach[M]. 8th ed. Beijing: China Machine Press, 2015: 79 [6]Li Zhihua. Lean Software Development: Understanding Kanban Method[M]. 1st ed. Beijing: Tsinghua University Press, 2016 (in Chinese)(李智桦. 精益开发与看板方法[M]. 1版. 北京: 清华大学出版社, 2016) [7]Cockburn A. What the agile toolbox contains[EB/OL].[2016-08-15]. http://alistair.cockburn.us/What%20the%20agile%20toolbox%20contains [8]Tower. Feature log of Tower[EB/OL].[2016-08-15]. https://tower.im/roadmap (in Chinese)(Tower. Tower功能日志[EB/OL].[2016-08-15]. https://tower.im/roadmap) [9]Feinberg J. Beautiful Visualization[M]. San Francisco, CA: O’Reilly Media, 2010: 37-41 [11]Ahsan S N, Ferzund J, Wotawa F. Automatic software bug triage system (BTS) based on latent semantic indexing and support vector machine[C] //Proc of IEEE ICSEA’09. Piscataway, NJ: IEEE, 2009: 216-221 [12]Xuan Jifeng, Jiang He, Hu Yan, et al. Towards effective bug triage with software data reduction techniques[J]. IEEE Trans on Knowledge and Data Engineering, 2015, 27(1): 264-280 [13]Shokripour R, Anvik J, Kasirun Z M. Why so complicated? Simple term filtering and weighting for location-based bug report assignment recommendation[C] //Proc of the 10th IEEE Working Conf on Mining Software Repositories. Piscataway, NJ: IEEE, 2013: 2-11 Chen Long, born in 1988. Currently PhD candidate in the School of Software & Microelectronics, Peking University. Student member of China Computer Federation. His main research interests include software engineering and machine learning. Ye Wei, born in 1985. Received his PhD degree from School of Electronics Engineering and Computer Science, Peking University. Currently associate research fellow in National Engineering Research Center for Software Engineering, Peking University. His main research interests include Web-based software engineering, software architecture and application integration. Zhang Shikun, born in 1969. Received his PhD degree from Department of Computer Science and Technology, Peking University. Professor and PhD supervisor in National Engineering Research Center for Software Engineering, Peking University. His main research interests include software engineering and cyber security. 附录A Scrum团队中的主要角色包括: Scrum Master——Scrum教练和团队负责人,确保团队合理地运作Scrum并帮助团队移除实施中的障碍; Product Owner——产品负责人,确定产品的方向和愿景,定义产品发布的内容、优先级及交付时间; Team——开发团队,通常为3~9人的小型团队,团队拥有交付可用软件需要的各种技能. Scrum团队以短小的迭代(sprint)为单位进行工作,一个典型的Scrum迭代通常持续2~4周. 在日常工作时,产品负责人须维护一个按优先级排序的“产品需求列表”(product backlog),即从客户价值理解和描述中凝练成的产品功能条目.在每次迭代开始之前,产品负责人组织召开迭代计划会(sprint planning meeting),从优先级最高的需求进行讲解,团队成员就需求细节、完成标准等展开讨论,并估算工时,直至该迭代期间内团队工作量饱和,从而形成迭代需求列表(sprint backlog).一旦迭代开始,原则上迭代需求列表不再发生大的变化,可以使团队能在短期内相对稳定地、高效地开展工作.然后,要把本次迭代的需求细分为以小时为单位的任务,在迭代期内,团队成员将自主决定任务分配等,逐一完成任务.每天由团队负责人组织进行一个简短的站立会议(daily stand-up meeting),一般不超过15 min,团队成员相互沟通,主要回答3个问题——自上次站立会议以来完成了什么任务、遇到了什么困难、下一次站立会议之前计划完成什么任务——以便更早地发现潜在的问题,促进团队自我组织协调. 团队以故事板(也称作看板)的形式展示团队的进度,比如将看板划分为“未开始”、“开发中”和“待审核”3个并排的栏目,计划会结束后所有任务都排列在“未开始”一栏下.随着迭代的进行,一项任务处于哪种状态,就将任务移动到相应的栏目下.关于看板的一条简单规则,就是处于“开发中”的任务永远不要太多,避免在迭代结束时出现大量“半成品”.团队还维护一张“燃烧图”(burn down chart),即所有任务的累积剩余时间随开发进程与日递减的图形,以观察和预测所有任务是否会按期完成.如果有紧急的缺陷(bug)被发现,可以作为任务临时添加进迭代. 在每个迭代的最后一天,团队召开评审会(review meeting),邀请产品负责人等参加,对已经完成的产品功能条目进行评审,产品负责人做出判断并给出改进意见.当天还会召开反思会(retros-pective meeting),总结本次迭代中的不足之处,并在之后的迭代中加以改进. Scrum整个流程如图A1所示: Onboard: A Data-Driven Agile Software Development Collaboration Tool Chen Long, Ye Wei, and Zhang Shikun (National Engineering Research Center for Software Engineering (Peking University), Beijing 100871) Scrum is an agile software development process with a balance between schedule and flexibility, which empowers software development teams with the ability to work efficiently and respond to changes quickly at the same time. Each step in the software development process can generate tons of data, which can further facilitate team and project management and improve development efficiency if these data are captured, analyzed, displayed and fed back. However, these data are commonly scattered and under-utilized because project management and source code management are separated in existing software development management toolbox. To promote data-driven agile software development process with Scrum at its core, we create Onboard, an agile software development collaboration tool based on cloud service, which, by associating Git commits with tasks, creatively incorporates agile process management, source code management and project management into one integrated service for software development teams. Onboard supports end-to-end management of the whole software life cycle, thus it can collect all the data generated throughout the development process and extract valuable information. This paper first introduces the design principle and structure of Onboard, and then gives a comprehensive survey of data visualization and analysis applied in Onboard. In the survey, we propose solutions to a series of related problems on two topics: how to fully utilize the data generated to improve agile development process and how to evaluate the contribution of a team member. In the final analysis, the paper provides topics that need further research. data-driven; agile software development; Scrum; software life cycle; data visualization; associating commit with task; contribution evaluation; affected lines of code (ALOC) Fig. A1 Demonstration of Scrum software development process.图A1 Scrum软件开发流程示例 2016-08-16; 2016-10-24 叶蔚(wye@pku.edu.cn) TP311.5
6 总结及进一步的工作



 猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22师道·教研(2022年1期)2022-03-12现代信息科技(2021年21期)2021-05-07海洋信息技术与应用(2020年1期)2020-06-11传媒评论(2019年4期)2019-07-13动漫星空(2018年11期)2018-10-26动漫星空(2018年2期)2018-10-26动漫星空(2018年9期)2018-10-26动漫星空(2018年5期)2018-10-26中国司法鉴定(2018年4期)2018-07-30
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22师道·教研(2022年1期)2022-03-12现代信息科技(2021年21期)2021-05-07海洋信息技术与应用(2020年1期)2020-06-11传媒评论(2019年4期)2019-07-13动漫星空(2018年11期)2018-10-26动漫星空(2018年2期)2018-10-26动漫星空(2018年9期)2018-10-26动漫星空(2018年5期)2018-10-26中国司法鉴定(2018年4期)2018-07-30
