
决策森林研究综述
2016-12-22 05:35黄海新
电子技术应用 2016年12期
黄海新,吴 迪,文 峰
(1.沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159;2.沈阳理工大学 自动化与电气工程学院,辽宁 沈阳 110159)
决策森林研究综述
黄海新1,吴 迪2,文 峰1
(1.沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159;2.沈阳理工大学 自动化与电气工程学院,辽宁 沈阳 110159)
随着经济与社会的发展,数据挖掘技术广泛应用到各个领域,其中分类算法中的决策森林(Decision Forest)成为一个研究热点。决策森林算法是一种包含多个决策树分类器的统计学习理论,能较好地处理噪声且避免发生过拟合。针对几种典型的决策森林算法,阐述了其原理和算法的特点,并从决策森林的构建过程出发,系统地分析和总结了国内外现有的决策森林算法。在此基础上,详细说明了在面对大数据时应用决策森林进行分布式计算的处理过程。通过比较,总结出了各种决策森林算法的适用范围。
数据挖掘;抽样;决策森林;分类;分布式计算;决策树
0 引言
随着日常生活和诸多领域中人们对数据处理需求的提高,海量数据分类已经成为现实生活中一个常见的问题。分类算法作为机器学习的主要算法之一,是通过对已知类别的训练集进行分析,得到分类规则并用此规则来判断新数据的类别,现已被医疗生物学、统计学和机器学习等方面的学者提出。同时,近几年大数据时代的到来,传统的分类算法如 SVM、贝叶斯算法、神经网络、决策树等,在实际应用中难以解决高维数据和数量级别的数据。而决策森林在处理类似问题时会有较高的正确率及面对高维数据分类问题时的可扩展性和并行性。Fernandez-Delgado[1]等人通过在 121种数据集上比较了14种决策森林归纳算法的预测效果,8种改进随机森林算法,20种改进更新权重抽样算法,24种改进无更新权重抽样算法和11种其他的集成算法,得出结论:随机森林中的决策树比其他的学习算法效果好很多。目前,决策森林已在人工智能如 AlphaGo、推荐系统、图像和视频检索中使用。
本文基于的随机森林算法分析其他几种典型决策森林的特性及不同,进而说明了不同决策森林算法的适用范围。通过比较算法,根据使用者选取能解决问题的最适合的决策森林算法。介绍了面向大数据时,基于决策森林的并行处理数据的方法。
1 决策树
决策树算法是一种基于实例的算法,常应用于分类和预测。决策树的构建是一种自上而下的归纳过程,用样本的属性作为节点,属性的取值作为分支的树形结构。因此,每棵决策树对应着从根节点到叶节点的一组规则。决策树的基本思想如图1所示。
决策树的可视结构是一棵倒置的树状,它利用树的结构将数据进行二分类。其中树的结构中包含三种节点,分别为:叶子节点、中间结点、根节点。
对决策树而言问题主要集中在剪枝和训练样本的处理。相对而言,决策森林在提高了分类精度的同时解决了决策树面临的问题。决策森林由几种决策树的预测组合成一个最终的预测,其原理为应用集成思想提高决策树准确率。通过构建森林,一棵决策树的错误可以由森林中的其他决策树弥补。
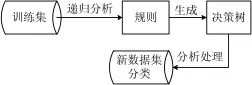
图1 决策树的基本思想
2 决策森林构建方法
2.1 Bootstrap aggregating
Bagging(bootstrap aggregating)无权重抽样通常用于产生全体模型,尤其是在决策森林中,是一种简单而有效的方法。森林中的每一棵决策树从原始训练集中筛选出的数据作为训练集。所有的树都使用相同的学习算法进行训练,最后的预测结果由每棵树的预测结果投票决定。由于有放回抽样被使用,一些原始数据可能出现不止一次而有些数据没有被抽到。为了确保在每个训练实例中有足够数量的训练样本,通常会设置每个样本的原始训练集的大小。无权重抽样的一个最主要的优点是在并行模式下容易执行通过训练不同的处理程序的集成分类器。
通常情况下,bagging无权重抽样产生一个组合模型,这个模型比使用单一原始数据的模型效果好很多。Breiman[2]指出无权重抽样决策树作为随机森林算法中的特定实例,而随机森林算法将会在下一节介绍。
2.2 Adaptive boosting
更新权重抽样是一种提高弱学习机性能的方法,这种算法通过反复地迭代不同分布的训练数据中的决策树归纳算法。这些决策树组合成为强集成森林。该算法将预测精度较低的弱学习器提升为预测精度较高的强学习器。与自举法(bootstrapping)相同的是,更新权重抽样方法同样利用重采样原理,然而在每次迭代时却不是随机的选取样本,更新权重抽样修改了样本目的是想在每个连续的迭代中提高最有用的样本。
AdaBoost[3](Adaptive Boosting)是最受欢迎的更新权值抽样算法。AdaBoost是Boosting算法的一种,它能够自适应地调节训练样本权重分布,这个算法的主要思想是给在上一次迭代中错分的树有较高的权值。特别地,这些错分的树的权值越来越大而正确分类的那些树的权值越来越小,这个迭代过程生成了一连串相互补充的决策树。
3 国内外研究现状
3.1 随机森林(Random forest)
随机森林是最普通的决策森林,这个算法在二十世纪90年代中期被提出,后来被 Breiman[2]完善和推广。文献[2]截至2016年4月的谷歌学术已经被引用超过 20 800次,而这篇论文的受欢迎程度每年都增加的主要原因一方面是因为随机森林算法的简单,另一方面是因为它的预测能力强。
随机森林算法中有大量的没有修剪的随机决策树,而这些决策树的输出是使用的一种无权重的多数投票。为了保证随机森林的准确性,在决策树归纳算法的建立过程中有2个随机的过程:
(1)从训练集中无放回的挑选样本。虽然样本都是从原始数据集中产生,但每棵树的训练数据集是不同的。
(2)不是从所有的特征中选取最佳分裂点,而是随机地从特征子集中取样,从中选取最佳分裂点。子集大小n是根据式(1)得出:

其中N是特征的数量,近似得到。
最初随机森林算法仅由决策树组成。随机森林是在树的每个节点从不同属性的子集中选择一个特征,其主要思想是替换更广泛的“随机子空间方法”[4],此方法可以应用于许多其他的算法例如支持向量机。尽管最近对于决策树的随机森林和随机子空间的比较已经表明在精确度方面前者要优于后者[1]。
尤其涉及到数字特征时,也存在将随机性添加到决策树归纳算法中的其他方法。例如代替使用所有的实例去决定为每个数字特性和使用实例的子样本[5]的最佳分裂点,这些子样本的特征是各不相同的。使用这些特征和分裂点评价最优化的分裂标准,而评价标准是每个节点决策选择的。由于在每个节点分裂的样本选取是不同的,这项技术结果是由不同的树组合成的集合体。另一种决策树的随机化方法是使用直方图[6]。使用直方图一直被认为是使特征离散化的方法,然而这样对处理非常大的数据时能够减少很多时间。作为代表性的是,为每个特征创建直方图,每个直方图的边界被看作可能的分裂点。在这个过程中,随机化是在直方图的边界的一个区间内随机选取分裂点。
由于随机森林的流行,随机森林能被多种软件语言实现,例如:Python、R语言、Matlab和C语言。
3.2 极端随机森林(Extremely randomized forest)
随机森林选取最佳分裂属性,而极端随机森林[7]的最佳切割点是在随机的特征子集中。比较起来,极端随机森林的随机性既在分裂的特征中又在它相应的切割点中。为了选取分裂特征,该算法随机性表现为在被判断为最好的特征中选取确定数目的特征。除了数字特征以外,该算法还在特征值域中统一地绘制随机切点,即切点选取那些完全随机独立的目标属性。在极端情况下,此算法在每个节点上随机选取单属性点和切割点,因此一棵完全随机化树建立完成。
Geurts等人[7]指出独立极端随机树往往有高偏差和方差的元素,然而这些高方差元素能通过组合森林中大量的树来相互抵消。
3.3 概率校正随机森林
一般地,决策树中的每个节点的分裂标准是使用熵或者基尼指数进行判断,这些判断标准描述了相应的节点分裂而没有考虑节点的特性。概率校正随机森林(Calibrated probabilities for random forest)[8]算法通过引入一个考虑分裂可能性的第二条件,来提出一个提高随机森林分类算法的分裂标准。提出的方法被直接应用到离线学习的过程,因此分类阶段保留了快速计算决策树特征属性取值的算法特征。算法的改进是直接在生成决策树的过程中,它没有增加分类的计算时间。
为了得到一个有识别力的可靠的分裂指标,通过使用普拉特缩放(Platt Scaling)方法将 Sigmoid函数引入特征空间。因此,选取最佳分裂点不再只根据单一的标准,而是一种可靠的必须满足更新最好分裂点的指标。此外,这个指标可以把随机森林分类器更好地应用到不同阈值的任务和数据集中。
该算法是用交通标志识别的GTSRB数据集、手写数字识别的MNIST数据集和著名机器学习数据集(美国邮政总局数据集、信件数据集和 g50c数据集)进行评估。研究结果表明,本文提出的方法优于标准随机森林分类器,尤其适用少量数目的树。概率校正随机森林基本流程图如2所示。

图2 概率校正随机森林基本流程
3.4 梯度提升决策树
梯度提升决策树(Gradient boosted decision trees,GBDT)[9]是更新权重抽样算法的一种,最初用来解决回归任务。与其他更新权重算法相同的是该算法计算一系列的回归树,但却以阶段式方法构建森林。特别地,该算法计算一系列的回归树,而回归树中的每一棵后续树的主要目的是使预测伪残差表现好的树有任意可微的损失函数。树中的每一片叶子在相应区间最小化损失函数。通过使用适当的损失函数,传统的更新权重抽样的决策树可也进行分类任务。
为了避免过拟合,在梯度更新权重抽样森林中选择适当数量的树(也就是迭代的次数)是非常重要的。迭代次数设置过高会导致过拟合,而设置过低会导致欠拟合。选取最佳值的方法是尝试在不同的数据集中比较不同森林大小的效果。
通过使用随机梯度更新权重抽样方法可以避免过拟合。大体的思路是分别从训练集中选取随机样本并连续地训练树。由于森林中的每棵树是使用不同的样本子集所建立的,所以造成过拟合的概率将会降低。
3.5 旋转森林
旋转森林(Rotating forest)[10]是在 3.1的基础上进行改进,添加了数据轴的一种算法。旋转森林中树的多样性是通过训练整个数据集中旋转特征空间的每棵树得到。在运行树归纳算法之前旋转数据轴将会建立完全不同的分类树。除此之外在确保树的多样性同时,被旋转的树能降低对单变量树的约束,这些单变量树能够分解输入空间到平行于原始特征轴的超平面。
更具体的说,是为森林中的每一棵树使用特征提取的方法建立完整特征集。首先随机分离特征集到K个相互独立的区间,之后分别在每个特征区间使用主成分分析法[11](Principal Component Analysis,PCA)。PCA算法的思想是正交变换任何可能相关的特征到一个线性无关的特征集中。每个元素是原始数据线性组合。且要保证第一主要元素具有最大方差。其他的元素与原来的元素正交的条件下也具有较高方差。
原始的数据集被线性转变为新的训练集,这些主要元素构建一个新的特征集。新的训练集是由新的特征空间所构建的,被应用到训练分类树的树归纳算法中。值得注意的是,不同的特征区间将会导致不同的变换特征集,因此建立了不同的分类树。这个旋转森林算法已经被应用到MATLAB编码的Weka工具。
通过对旋转森林的实验研究发现旋转森林要比普通的随机森林算法精度高。然而旋转森林有两个缺点。第一,由于使用PCA算法旋转随机森林比普通随机森林计算复杂度高。另一个缺点是在新建立的树中节点是变换后的特征而不是原始特征。这令用户更难理解树,因为树中的每个节点不是审查单一特征,用户需要审查的是树中每个节点上特征的一个线性组合。
3.6 Safe-BayesianRandom Forest
Novi Quadrianto和 Zoubin Ghahramani[12]提议利用从训练集中随机选取的几个树的平均值进行预测。从一个先验分布中随机选取决策树,对这些选取的树进行加权产生一个加权集合。与其他的基于贝叶斯模型的决策树不一样的是,需要用马尔可夫链蒙特卡罗算法对数据集进行预处理。这个算法的框架利用数据中相互独立的树的先验性促进线下决策树的生成。该算法的先验性在查看整体的数据之前从决策树的集合中抽样。此外对于使用幂的可能性,这种算法通过集合的决策树能够计算距离间隔。在无限大的数据的限制下给每一棵独立的决策树赋予一个权值,这与基于贝叶斯的决策树形成对比。
3.7 Switching classes
Breiman[13]提出的一种决策森林,该算法中的每棵决策树使用带有随机分类标签的原始训练集,每个训练样本的类标签是根据过渡矩阵改变的。过渡矩阵确定了类被类替代的概率,被选择的改变概率是为了保持原始训练集的类分布。
Martínez-Mun~oz和 Suárez[14]指出当森林是非常大的时候改变类的方法能使结果特别精确,而使用多类转变建立的森林是不需要保持原始类的分布的。在不平衡数据集中,原始类分布松弛约束对于使用转变类方法是非常重要的。每次迭代中原始数据集中随机选取一个固定的部分,这些选定实例的类是随机切换的。决策森林算法改进过程如图3所示。
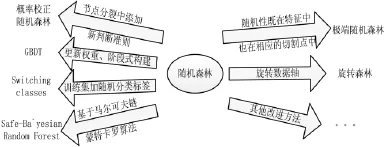
图3 决策森林算法改进过程
4 决策森林算法比较
中尝试了比较几种不同的决策森林算法。Dietterich[15]针对构建 C4.5决策森林比较了 3种算法,分别是随机抽样、无权重抽样和更新权重抽样。实验表明当数据中有少量噪声时,更新权重抽样预测效果最好,无权重抽样和随机抽样有相同的效果。
另一个文献比较了以更新权重抽样为基础的决策树和以无更新权重为基础的决策树[16]。研究表明无更新权重抽样减少了非稳态法样本的方差,而更新权重抽样方法减小了非稳态法样本的方差和偏差但增加了稳态法样本的方差。
Villalba Santiago等人[17]为决策森林中建立决策树的根节点对比了7种不同的更新权值抽样算法。他们得出结论,对于二项分类任务来说,大家众所周知的AdaBoost算法(通过迭代弱分类器而产生最终的强分类器的算法)的效果更好。然而对于多分类任务来说如GentleAdaBoost算法效果更好。
Banfield[18]等人用实验评估无更新权重抽样和其他 7种以随机化为基础的决策森林的算法。根据统计测试从57个公开的数据集获得实验结果。统计显著性用交叉验证进行对比,得出57个数据集中只有8个比无更新权重抽样精确,或在整组数据集上检查算法的平均等级。Banfield等人总结出在更新权重抽样算法的随机森林中,树的数量是1 000棵时效果最好。
除了预测效果也有其他的标准。根据使用者选取能解决问题的、最适合的决策森林算法:
(1)处理数据时适当地对算法进行设置:在处理具体的学习情况时,不同的决策森林方法有不同的适用范围,例如不平衡的高维的多元的分类情况和噪声数据集。使用者首先需要的是描述学习任务的特征并相应地选择算法。
(2)计算复杂度:生成决策森林的复杂成本以及实时性,并且对新数据预测的时间要求。通常梯度更新权重抽样的迭代法会有较高的计算效率。
(3)可扩展性:决策森林算法对大数据有缩放的能力。因此,随机森林和梯度更新权值抽样树有较好的可扩展性。
(4)软件的有效性:现成的软件数据包的数量。这些数据包能提供决策森林的实现方法,高度的有效性意味着使用者可以从一个软件移动到另一个软件,不需要更换决策森林算法。
(5)可用性:提供一组控制参数,这些参数是广泛性且易调节的。
5 决策森林应用
随着通信信息系统收集到的数据数量的增长,这些大规模数据集使得决策森林算法要提高其预测标准。然而对于任何数据学家,这些大规模数据的有效性是至关重要的,因为这对学习算法的时间和存储器提出了挑战。大数据是近几年被创造的专业术语,指的是使用现有算法难以处理的巨量资料集。
对于中小型数据集,决策树归纳算法计算复杂度是相对较低的。然而在大数据上训练密集森林仍有困难。可扩展性指的是算法训练大数量数据能力的效率。
近几年来,可扩展性主要集中在像 MapReduce和MPI的并行技术中。MapReduce是数据挖掘技术中最普遍的并行编程框架算法之一,由谷歌开创并推广的开源Apache Hadoop项目。Map把一组键值对映射成一组新的键值对,处理键值对来生成过度键值对。指定并行Reduce函数,确保所有映射的键值对有相同的键组。对于其他的并行编程架构(例如CUDA和MPI),MapReduce已经成为产业标准。已经应用于云计算服务,如亚马逊的EC2和各类型公司的 Cloudera服务,它所提供的服务能缓解Hadoop压力。
SMRF[19]是一种基于随机森林算法改进的、可伸缩的、减少模型映射的算法。这种算法使得数据在计算机集群或云计算的环境下,能优化多个参与计算数据的子集节点。SMRF算法是在基于MapReduce的随机森林算法模型基础上进行改进。SMRF在传统的随机森林相同准确率的基础上,能处理分布计算环境来设置树规模的大小。因此MRF比传统的随机森林算法更适合处理大规模数据。
PLANET[20]是应用于 MapReduce框架的决策森林算法。PLANET的基本思想是反复地生成决策树,一次一层直到数据区间足够小并能够适合主内存,剩下的子树可以在单个机器上局部地生长。对于较高层次,PLANET的主要思想是分裂方法。在一个不需要整个数据集的特定节点,需要一个紧凑的充分统计数据结构,这些数据结构在大多数情况下可以适合内存。
Palit和 Reddy[32]利用 MapReduce框架开发出两种并行更新权重抽样算法:AdaBoost.PL和 LogitBoost.PL。根据预测结果,这两种算法与它们相应的算法效果差不多。这些算法只需要一次循环 MapReduce算法,在它们自己的数据子集上的每个映射分别运行 AdaBoost算法以产生弱集合模型。之后这些基本的模型随着他们权重的减小被排序和传递,被减小的平均权值推导出整体最后的权值。
Del Río等人[21]提出用 MapReduce来实现各种各样的常规算法。这些算法用随机森林来处理不平衡的分类任务。结果表明,多数情况下映射数量的增加会使执行时间减少,而太多的映射会导致更糟糕的结果。
各种分布的随机森林是可以实现的,尤其在 Mahout中,这只是一个Apache项目。Apache项目是可以提供免费的可扩展的机器学习算法程序包,包括在 Hadoop框架下实现随机森林的包。MLLib一个分布式机器学习框架,提供了在Spark框架下实现随机森林和梯度提升树的包。
6 结论
决策森林主要目的是通过训练多个决策树来改善单一决策树的预测性能。当前决策森林的研究趋势是:解决大数据而实现分布式开发;改进现有的分类和回归的决策森林算法来处理各种各样的任务和数据集。
目前国内对于决策森林的研究很多是针对随机森林的,但却对决策森林的其他算法研究得比较少。
参考文献
[1]Fernández-Delgado M,Cernadas E,Barro S,et al.Do we need hundreds of classifiers to solve real world classification problems?[J].J Mach.Learn.Res.2014,15(1):3133-3181.
[2]BREIMAN L.Random forests[J].Machine Learning,2001,45 (1):5-32.
[3]钱志明,徐丹.一种 Adaboost快速训练算法[J].计算机工程,2009,35(20):187-188.
[4]HO T K.The random subspace method for constructing decision forests[J].IEEE Transactions on Pattern Analysis& Machine Intelligence,1998,20(8):832-844.
[5]KAMATH C,CANTU-PAZ E.Creating ensembles of decision trees through sampling:US,US 6938049 B2[P].2005.
[6]KAMATH C,Cantú-Paz E,LITTAU D.Approximate splitting for ensembles of trees using histograms[C]//Proc.siam Int’l Conf.data Mining,2002.
[7]GEURTS P,ERNST D,WEHENKEL L.Extremely randomized trees[J].Mach.Learn.2006,63(1):3-42.
[8]BAUMANN F,CHEN J,VOGT K,et al.Improved threshold selection by using calibrated probabilities for random forest classifiers[C].Computer and Robot Vision(CRV),2015 12th Conference on.IEEE,2015:155-160.
[9]FRIEDMAN J H.Greedy function approximation:a gradient boosting machine[J].Annals of Statistics,2000,29(5):1189-1232.
[10]Rodríguez J J,Kuncheva L I,Alonso C J.Rotation forest:A new classifier ensemble method[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2006,28(10):1619-1630.
[11]王景中,李萌.基于轮廓 PCA的字母手势识别算法研究[J].电子技术应用,2014,40(11):126-128.
[12]NOVI Q,ZOUBIN G.A very simple safe-bayesian random forest[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2015,37(6):1297-1303.
[13]BREIMAN L.Randomizing outputs to increase prediction accuracy[J].Machine Learning,2000,40(3):229-242.
[14]Martínez-Mun~oz G,Suárez A.Switching class labels to generate classification ensembles[J].Pattern Recognition,2005,38(10):1483-1494.
[15]DIETTERICH T G.An experimental comparison of three methods for constructing ensembles of decision trees:Bagging,boosting,and randomization[J].Machine learning,2000,40(2):139-157.
[16]BAUER E,KOHAVI R.An empirical comparison of voting classification algorithms:bagging,boosting,and variants[J].Machine Learning,1999,36(1-2):105-139.
[17]VILLALBA S D,Rodrguez J J,Alonso Carlos J.An empirical comparison of boosting methods via OAIDTB,an extensible java class library[C]//II International Workshop on Practical Applications of Agents and Multiagent Systems-IWPAAMS,2003.
[18]BANFIELD R E,HALL L O,BOWYER K W,et al.A comparison of decision tree ensemble creation techniques[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2007,29(1):173-180.
[19]HAN J,LIU Y,SUN X.A scalable random forest algorithm based on MapReduce[C]//Software Engineering and Service Science(ICSESS),2013 4th IEEE International Conference on.IEEE,2013:849-852.
[20]PANDA B,HERBACH J S,BESU S,et al.PLANET:massively parallel learning of tree ensembles with MapReduce[J].Proceedings of the Vldb Endowment,2009,2(2):1426-1437.
[21]Río S D,López V,Benítez J M,et al.On the use of Map-Reduce for imbalanced big data using Random Forest[J].Information Sciences,2014,285:112-137.
Review of decision forest
Huang Haixin1,Wu Di2,Wen Feng1
(1.Shenyang Ligong University,College of Information Science and Engineering,Shenyang 110159,China;2.Shenyang Ligong University,Automation and Electrical Engineering,Shenyang 110159,China)
With the development of economy and society,the Data Mining Technology runs through all areas widely.In which the forest decision of the classification algorithm has become a hot topic.Decision forest algorithm is statistics theory that combins the set of decision tree classification,can deal with noise and avoid over fitting surpassingly.This article mainly introduced the several classic methods of decision forest algorithm and their characteristics.Researching algorithms in domestic and overseas were analyzed and summarized systematically from the process of the construction of the decision forest.In the face of big data is described in detail application decision forest distributed computing process.By comparison,this article summarizes the applicable scope of various decision forest algorithm.
data mining technology;sampling;decision forest;classification;distributed computing;decision tree
TP301
A
10.16157/j.issn.0258-7998.2016.12.001
黄海新,吴迪,文峰.决策森林研究综述[J].电子技术应用,2016,42(12):5-9.
英文引用格式:Huang Haixin,Wu Di,Wen Feng.Review of decision forest[J].Application of Electronic Technique,2016,42 (12):5-9.
2016-05-16)
黄海新(1972-),通信作者,女,博士,副教授,主要研究方向:机器学习、人工智能、智能电网,E-mail:huanghaixin@sia.cn。
吴迪(1990-),女,硕士研究生,主要研究方向:机器学习。
文峰(1977-),男,博士,副教授,主要研究方向:机器学习、智能交通。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
当代陕西(2020年17期)2020-10-28
成都信息工程大学学报(2019年3期)2019-09-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
电子制作(2018年16期)2018-09-26
人大建设(2018年5期)2018-08-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
应用科技(2015年5期)2015-12-09
郑州大学学报(医学版)(2015年1期)2015-02-27
郑州大学学报(理学版)(2012年4期)2012-03-25
