
基于Gist特征与CNN的场景分类方法
2016-12-21 02:04:24梁雪琦
电视技术 2016年11期
梁雪琦
(太原理工大学 信息工程学院,山西 晋中 030600)
基于Gist特征与CNN的场景分类方法
梁雪琦
(太原理工大学 信息工程学院,山西 晋中 030600)
针对大多数场景分类方法只能学习浅层特征,忽略图像之间的相关结构信息,提出一种基于Gist特征与卷积神经网络结合的场景图像分类方法。其中Gist特征用于提取场景图像的全局特征,并将其作为深度学习模型的输入,通过逐层训练卷积神经网络,提取更高层次的特征,并用训练好的卷积神经网络进行分类。实验在O&T室外场景图像数据集和MNIST手写体数据集上考察了batchsize、卷积核对分类结果的影响,并与DBN,NN,SVM和CART作为分类器的分类结果进行比较,充分说明了本文方法的有效性。
Gist特征;特征提取;卷积神经网络;场景分类
场景分类在计算机视觉领域有广泛的应用,2006年召开的首次场景理解研讨会上明确提出“场景分类是图像理解的一个新的有前途的研究方向”[1]。Ulrich和Nourbakhsh[2]利用颜色直方图进行场景分类。Shen[3]等人采用多种特征融合的方法表征图像特征进行场景分类。Lazebnik[4]等人提出金字塔匹配模型(Spatial Pyramid Matching, SPM),利用视觉词汇的空间布局信息实现场景的有效分类。杨昭[5]在Gist特征中引入空间信息和RGB颜色信息,并基于词汇包(BOW)模型设计了一种高效匹配核来度量局部特征间的相似性,核化特征匹配过程。以上算法均为利用各种特征提取方法解决场景分类问题,但特征提取过程有过多主动因素介入,有很大的盲目性。
深度学习是近年发展起来的多层神经网络学习算法,可通过学习一种深层非线性网络结构,实现复杂函数逼近[6-7]。其中,卷积神经网络(Convolutional Neural Network, CNN)[8-11]是一个典型的深度学习模型。它是一个深层的神经网络,采用上一层的输出是这一层的输入的逐层学习的贪婪模型,使其能够学习更高级、更有效的特征。CNN已成功应用于语音识别、手写字符识别等领域。但是,CNN对输入数据是局部敏感的,以像素级的特征作为CNN的输入,提取不到图像的全局信息。Gist特征提取算法[12]是Oliva和Torralba等提出的一种有效的全局特征描述子,提取图像的自然度、开放度、粗糙度、膨胀度和险峻度描述描述图像的全局特征。以Gist特征作为CNN的输入,可有效避免深度学习中遇到的难题。二者相结合,能为场景分类提供一种新的思路。
本文通过Gist特征提取场景图像的全局特征,用CNN进一步学习更深层次的特征,并在CNN最高层进行场景分类。全局特征反映了图像的空间布局,过滤了很多不必要的信息,比原始图像像素具有更强表达能力。同时,通过CNN的逐层贪婪学习,并在最高层实现特征识别,提高了场景图像的学习性能。在O&T室外场景图像数据集上的实验表明,本文提出的算法与DBN、NN、SVM、CART相比,具有更强的判别性,能够更有效地表征室外场景图像的特征,并得到较高的分辨率。
1 相关理论
1.1 Gist特征[12-13]
Oliva等提出的Gist特征是一种生物启发式特征,该特征模拟人的视觉,形成对外部世界的一种空间表示,捕获图像中的上下文信息。Gist特征通过多尺度多方向Gabor滤波器组对场景图像进行滤波,将滤波后的图像划分为4×4的网格,然后各个网格采用离散傅里叶变换和窗口傅里叶变换提取图像的全局特征信息。Gabor滤波器组的表达式为
exp[2πj(u0xrθi+v0yrθi)]
(1)
其中
(2)
式中:l为滤波器的尺度;K为正常数;σ为高斯函数的标准差;θi=π(i-1)/θl,i=1,2,…,θl,θl为l尺度下的方向总数。滤波后的图像为

(3)
1.2 卷积神经网络
卷积神经网络是当前语音分析和图像识别领域的研究热点,它融合了3种结构性的方法来实现平移、缩放和扭曲不变形,即局部感受眼、权值共享和空间域或时间域上的采样。CNN是一种多层神经网络,由多个卷积层和子采样层交替组成,每一层由多个特征图组成,每个特征图由多个神经单元组成,同一个特征图的所有神经单元共用一个卷积核(即权重),卷积核代表一个特征。
1.2.1 卷积层
卷积层[14]有如下几个参数:特征图的个数N,特征图的大小(Nx,Ny),卷积核(kx,ky)和步长(Sx,Sy)。一个大小为(kx,ky)的卷积核必须在输入图像的有效区域内移动,即卷积核必须在输入图像内。步长Sx和Sy定义了卷积时卷积核在x轴和y轴跳多少的像素。输出特征图大小的定义为
(4)
式中:参数n表示层数。在Ln层的每个特征图最多可连接在Ln-1层的Nn-1个特征图。
1.2.2 采样层
采样层是对上一层的卷积层进行采样工作,实现局部平均和子抽样,使特征映射的输出对平移等变换的敏感度下降[15]。采样层并不改变特征图的个数,但输出的特征图会变小。对卷积层进行采样有很多方式,包括均值采样、随机采样、最大值采样、重叠采样、均方采样、归一化采样等。均值采样是对上一层特征图的相邻小区域进行聚合统计,区域大小为scale×scale,并取均值。随机采样是对特征图中的元素按照其概率的大小进行选择,即元素值大的被选中的概率也大。
2 基于Gist特征与卷积神经网络的图像分类方法
本文提出一种基于Gist特征与卷积神经网络的场景图像分类方法。该方法不是将原始图像的像素作为卷积神经网络的输入,而是采用图像的Gist特征作为它的输入。
本文所用图像大小为256×256,若图像的像素直接作为CNN的输入,其维数就是图像的大小,即256×256。而CNN的输入采用Gist特征时,用Oliva模型提取Gist特征,每幅图像的Gist特征维数为512×1,重新调整它的行数、列数,即将512×1维转化为16×32维。比起前一种方法,第二种使得CNN的输入维数大大缩小,减少了可训练参数,从而减小了网络复杂度,节省了计算时间。
本文构建的卷积神经网络基本结构如图1所示。它由一层输入层、两层卷积层、两层采样层和一层输出层组成。网络中C层为卷积层,卷积层的特征图都由不同的卷积核与前一层的特征图卷积得到。S层为采样层,它对卷积层的特征图进行子采样,本实验选择的采样方式是均值采样,输出是指最终的分类结果,输出层与输出层前一层之间全连接。
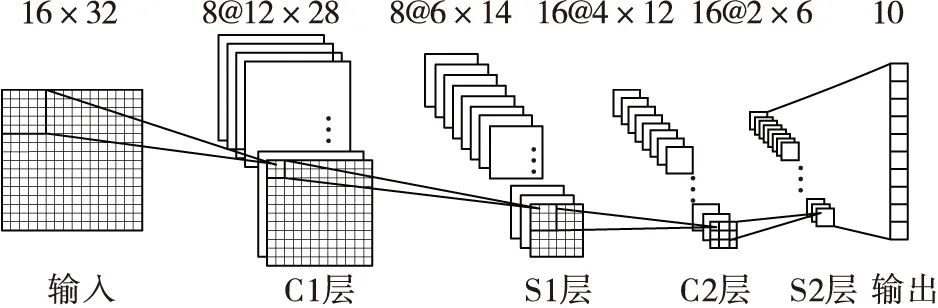
图1 基于Gist特征与卷积神经网络结合的模型
本文提出的方法步骤(伪代码)如下:
方法:基于Gist特征与卷积神经网络结合的场景图像分类方法
输入:图像数据集
输出:分类误差
Step1:用Oliva模型提取Gist特征;
Step2:每类抽取150幅图像的Gist特征作为训练数据,其余用于测试;
Step3:处理Gist特征,将数据归一化,并调整Gist特征的行数、列数;
Step4:参数初始化,包括CNN结构、学习率、batchsize和迭代次数;
Step5:CNN网络初始化,即对卷积核和权重进行随机初始化,而对偏置进行全0初始化;
Step6:CNN网络训练
fori=1:迭代次数
forj=1:numbatches
随机抽取batchsize个训练数据,前向传输计算在当前网络权值和输入下网络的输出;
反向传输调整权值;
更新权值;
endfor
endfor
Step7:CNN网络测试,用测试样本和训练好的CNN网络进行测试;
Step8:输出误差。
3 实验分析
为了验证本文方法的有效性,选用O&T室外场景数据集进行实验。关于CNN的结构选取目前尚未有完善的理论依据,本实验用上述模型在Oliva&Torralba(O&T)室外场景图像数据集和MNIST手写体数据集上的结果讨论了CNN的结构(batchsize、卷积核)对分类结果的影响,找到各个参数影响分类结果的内在原因。并通过本文结果与DBN,NN,SVM,CART作为分类器在O&T场景图像集上的分类结果进行比较,来验证本文方法的有效性。
3.1 数据集
本实验选用两个数据集,即MIT的Oliva&Torralba(O&T)室外场景图像数据集和MNIST手写体数据集。
Oliva&Torralba(O&T)室外场景图像数据集用于验证基于Gist特征与卷积神经网络的场景图像分类方法的有效性。该数据集包含海滨、森林、高速公路、城市、高山、乡村、街道和高楼8个类别,每幅大小为256×256,共2 688幅。数据集如图2所示。MNIST手写体数据集用于在进行参数讨论时的对比实验。本实验直接用CNN对MNIST手写体数据集进行分类。数据集包含0~9的10个类别,每个样本被规范化,将数字置于图像中心,并下采样成28×28的灰度图像,共70 000个样本。

图2 Oliva&Torralba(O&T)室外场景图像数据集
3.2 场景分类及相关参数讨论
在进行实验时,卷积神经网络选取的卷积核(kx,ky)和步长Sx,Sy在x轴与y轴的数值一样,故用kn表示第n层的卷积核,Sn表示第n层的步长。本实验中,设步长为固定值1。
3.2.1 batchsize的影响
对于O&T室外场景图像数据集,每类随机抽取150张图像用于训练,其余用于测试。MNIST手写体数据集包含60 000个训练样本和10 000个测试样本。保持其他参数不变,改变batchsize,结果如表1、表2所示。
从表中可以看出,对于同一个数据集,随着batchsize的减小,误差也在减小。程序中,每次挑出batchsize个样本进行训练,即每次用batchsize个训练样本一起计算梯度,更新模型参数。本实验数据集数量没有那么大,如果选取较大的batchsize,很容易收敛到不好的局部最优点,而减小batchsize的数值,引入更多的随机性,会跳出局部最优。
3.2.2 卷积核参数的影响
卷积核是连接两层神经元互联的重要工具,其大小决定提取局部特征的大小,设置适当的卷积核,对于提高CNN的性能至关重要。
在此实验中,对于O&T室外场景图像数据集,其实验结果如表3所示。其中,误差1和误差2是指C1、C2层特征图个数分别为7、14,8、16时实验的分类误差。
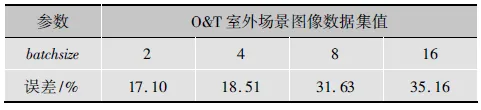
表1 batchsize对O&T室外场景图像数据集的影响
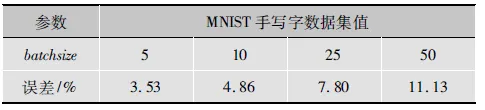
表2 batchsize对MNIST手写字数据集的影响
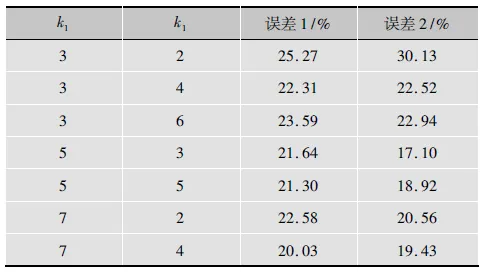
表3 O&T室外场景图像数据集上卷积核参数的影响
对于MNIST手写体数据集,调整卷积核参数,其实验结果如表4所示。其中,误差3、误差4和误差5是指C1、C2层特征图个数分别为6、12,7、14和8、16时实验的分类误差。
从表3和表4可以看出,对于同一个数据集,C1层的特征图个数和C2层的特征图个数变化时,误差最小时对应的C1层的卷积核大小不变。对于不同的数据集,误差最小时对应的C1层和C2层的卷积核大小虽然不一样,但C1层的卷积核大小应选择最大值,C2层应选择与C1一样大或大小相邻的卷积核。

表4 MNIST手写体数据集上卷积核参数的影响
根据卷积神经网络通过局部感受眼提取网络内部各层特征的特点,卷积核越大,网络可表示的特征空间越大,学习能力越强。卷积核在一定程度上越大越好,但如果太大,提取的特征的复杂度远远超过卷积核的表示能力,而训练数据没有增加,容易出现过拟合现象,故应适当选择。
3.3 与其他方法比较
为探讨本文算法的有效性,本实验还与其他分类器进行了比较。CNN,DBN,NN,SVM,CART的输入均为O&T室外场景图像数据集的灰度图像。其中,CNN与本文方法参数一致、DBN隐含层节点为100-100-100,NN的节点为512-100-8。SVM采用常用的LIBSVM,其核函数采用径向基函数(RadialBasisFunction,RBF),CART算法选择10折交叉实验。
对比实验结果如表5所示。实验结果表明,本文算法识别率最高,说明本文算法具有较好的识别能力。基于Gist特征的CNN分类精度高于输入为像素级的分类精度。将Gist特征作为网络的输入,有助于过滤不必要的信息,学习到图像的局部特征更有利于图像的识别。
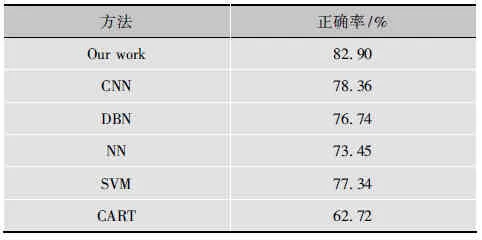
表5 分类性能比较
4 小结
本文在对CNN深入研究的基础上,提出了一种基于Gist特征与卷积神经网络的场景图像分类方法,在O&T室外场景图像数据集上的实验表明,本文方法能够很好地对场景图像进行分类。引入深度学习结构,一定程度上克服了传统浅层结构算法的局部最优。将Gist特征与CNN相结合,使得在逐层提取特征之前,提前过滤了一部分不必要的特征,减小了网络复杂度,节省了计算时间。实验深入研究了batchsize与卷积核对分类结果的影响,并在不同的数据集上得到了一致的结果。实验还与其他分类方法进行了比较,结果证明本文方法正确率较高。本实验在最经典的Oliva模型上进行实验,在其他的模型上是否也有同样的效果,是继续研究的方向。
[1]金泰松, 李玲玲, 李翠华. 基于全局优化策略的场景分类算法[J]. 模式识别与人工智能, 2013, 26(5): 440-446.
[2]ULRICHI,NOURBAKHSHI.Appearance-basedplacerecognitionfortopologicallocalization[C]//Proc.IEEEInternationalConferenceonRoboticsandAutomation, 2000. [S.l.]:IEEE, 2000: 1023-1029.
[3]SHENJ,SHEPHERDJ,NGUAHH.Semantic-sensitiveclassificationforlargeimagelibraries[C]//Proc.Proceedingsofthe11thInternationalMultimediaModellingConference, 2005. [S.l.]:IEEE, 2005: 340-345.
[4]GRAUMANK,DARRELLT.Thepyramidmatchkernel:Discriminativeclassificationwithsetsofimagefeatures[C]//Proc.TenthIEEEInternationalConferenceonComputerVision, 2005. [S.l.]:IEEE, 2005: 1458-1465.
[5]杨昭,高隽,谢昭,等. 局部Gist特征匹配核的场景分类[J]. 中国图象图形学报, 2013, 18(3): 264-270.
[6]孙志军,薛磊,许阳明,等. 深度学习研究综述[J]. 计算机应用研究, 2012, 29(8): 2806-2810.
[7]BENGIOY,DELALLEAUO.Ontheexpressivepowerofdeeparchitectures[C] //Proc.AlgorithmicLearningTheory.BerlinHeidelberg:Springer, 2011: 18-36.
[8]ZHENGZ,LIZ,NAGARA,etal.Compactdeepneuralnetworksfordevicebasedimageclassification[C]//Proc. 2015IEEEInternationalConferenceonMultimedia&ExpoWorkshops.Turin,Italy:IEEE, 2015: 1-6.
[9]HEK,ZHANGX,RENS,etal.Spatialpyramidpoolingindeepconvolutionalnetworksforvisualrecognition[J].IEEEtransactionsonpatternanalysis&machineintelligence, 2015,37(9): 1904-1916.
[10]DONGZ,WUY,PEIM,etal.Vehicletypeclassificationusingasemisupervisedconvolutionalneuralnetwork[J].IEEEtransactionsonintelligenttransportationsystems, 2015(29): 2247-2256.
[11]SANTANAE,DOCKENDORFK,PRINCIPEJC.LearningjointfeaturesforcoloranddepthimageswithConvolutionalNeuralNetworksforobjectclassification[C]//Proc. 2015IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing, 2015. [S.l.]:IEEE, 2015: 1320-1323.
[12]OLIVAA,TORRALBAA.Modelingtheshapeofthescene:aholisticrepresentationofthespatialenvelope[J].Internationaljournalofcomputervision, 2001, 42(3): 145-175.
[13]陈三风, 梁永生, 柳伟, 等. 基于全局特征信息的快速场景识别与分类研究[J]. 微计算机信息, 2010, 26(25): 41-42.
[14]CIRESAND,MEIERU,MASCIJ,etal.Acommitteeofneuralnetworksfortrafficsignclassification[C]//The2011InternationalJointConferenceonNeuralNetworks, 2011. [S.l.]:IEEE, 2011: 1918-1921.
[15]刘建伟,刘媛,罗雄麟. 深度学习研究进展[J]. 计算机应用研究, 2014, 31(7): 1921-1930.
Method of scene image classification based on Gist descriptor and CNN
LIANG Xueqi
(CollegeofInformationEngineering,TaiyuanUniversityofTechnology,ShanxiJinzhong030600,China)
Most of the scene classification methods have a problem which ignoring the structural information related between images leads to they only can learn shallow representations for scene recognition. A method of scene image classification based on Gist descriptor and Convolutional Neural Network(CNN) is proposed. Firstly, Gist descriptor, for global scene image feature extraction, is used as the input of deep learning net. Secondly, convolutional neural network is trained by layer-by-layer to extract a higher level of features. Then, the trained convolutional neural network is used as a classification. Finally, experiments on Oliva&Torralba(O&T) outdoor scene image data set and MNIST handwritten data set investigates the influence to classification accuracy with batchsize and kernelsize, and the comparison with the classification results of the classifiers, Deep Belief Network(DBN), Neural Network (NN), Support Vector Machine(SVM) and Classification And Regression Tree(CART) on the O&T scene image sets indicates the effectiveness of the method are put forward.
Gist descriptor; feature extraction; convolutional neural network; scene classification
梁雪琦.基于Gist特征与CNN的场景分类方法[J]. 电视技术,2016,40(11):7-11. LIANG X Q. Method of scene image classification based on Gist descriptor and CNN[J]. Video engineering,2016,40(11):7-11.
TP18
A
10.16280/j.videoe.2016.11.002
国家自然科学基金项目(61450011);山西省自然科学基金项目(2014011018-2);山西省回国留学人员科研资助项目(2013-033;2015-45)
2016-04-06
梁雪琦(1990— ),女,硕士生,主研深度学习、人工智能、大数据等。
责任编辑:薛 京
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
