
基于随机森林的流量多特征提取与分类研究*
2016-12-17 05:19:09韦泽鲲夏靖波张晓燕
传感器与微系统 2016年12期
韦泽鲲, 夏靖波, 张晓燕, 付 凯, 申 健
(1.空军工程大学 信息与导航学院,陕西 西安710077;2.厦门大学 嘉庚学院,福建 厦门 363105)
基于随机森林的流量多特征提取与分类研究*
韦泽鲲1, 夏靖波2, 张晓燕1, 付 凯1, 申 健1
(1.空军工程大学 信息与导航学院,陕西 西安710077;2.厦门大学 嘉庚学院,福建 厦门 363105)
网络流量的多样化和复杂化以及高实时性要求对流量识别技术带来了巨大挑战,而通过基于机器学习的网络流量分类中,流量统计特征选择能够快速准确对流量进行识别,具有重要的研究意义。随机森林(RF)作为近年较热门的灰盒算法,对当前的网络流量具有较好的识别能力。通过随机森林的节点选择算法,对流量特征进行选择,并结合物理意义进行优化,进行多次特征提取。实验结果表明:提出的算法在识别模型构建上性能更加优越,耗费时间大大减小,同时准确度等指标得到提高。
流量统计特征; 随机森林; 灰盒模型; 特征提取
0 引 言
随着网络规模日益增大、5G等更高带宽技术的高速发展、云计算与大数据的应用呈爆发式增长,同时高附加值业务与用户行为的日趋复杂,尤其是移动终端和去中心化、异构网络的普遍性,导致需要更加高效地进行网络管理和数据流量控制。对网络资源的有效分配利用,对用户资源的分析引导,流量入侵检测和网络规划架构,是当今网络监管和互联网服务提供商(Internet service providers,ISPs)亟需处理的关键问题。
流量分类则是对不同应用类型流量进行分类,保证解析出适合用户群的业务模式,保证较高的服务质量(quality of service,QoS),为解决上述问题提供可靠的技术支持。通过采集流量的外部统计特征并应用机器学习算法分类是最常用的流量识别方法[1,2]。因此,机器学习流量分类技术是目前任何形式流量分类的主流技术。
近10年来,流量分类技术几近处于瓶颈阶段。各种机器学习技术准确率皆到达90 %以上,甚至超过99 %,技术的创新遭遇到了前所未有的挑战。Bernaille和Nguyen T提出采用网络子流的统计特征作为流量分类的研究对象,不仅克服网络应用的规避检测技术,大大提高分类的准确性,同时满足实时性的要求。柏骏、夏靖波等人[2]详细综述2006年~2012年国内外实时流量分类识别技术,提出以准确性与实时性作为两大指标,对流量分类方法进行研究的评价指标。Kalaiselvi T和Shanmugaraja P[3]结合机器学习中的有监督和无监督分类算法,提出了一种C4.5与k-means混合算法,且选取了极少量的流统计特征数据,并实验得到了较高的准确率。李平红、王勇等人[4]针对未识别流量,提出了一种基于成对约束扩展的半监督特征选择方法,该算法在较少成对约束条件下得到了更好的分类性能。文献[5]的特征提取实验,法国De Lorraine大学的Jerome Francois分析客户端向服务器发送通信数据的业务节点接口(service node interface,SNI)扩展码,提出多级框架去识别HTTPS服务的流量,必将识别的特征数量大大减少,实时流识别准确率高达93.10 %。
1 流量特征分类技术
在IP网络中,网络流量定义为源和目的计算机之间基于特定端口(如传输控制协议(transmission control protocol,TCP),用户数据报协议(user datagram protocol,UDP),互联网控制报文协议(Internet control message protocol,ICMP)等)的一个或者多个数据包。这些数据包中存在流的五元组信息〈源IP地址,源端口,目的IP,目的端口,传输层协议〉[6],相同流的五元组信息是相同的。
基于机器学习的流量分类方法是近年来热门的研究领域,流量分类模型可表述为:f:X→T,X={X1,X2,…,Xm}为类型未知的网络流集合,T={T1,T2,…,Tn}为已知网络流集合,f为特定的机器学习算法,如何通过特定的算法对普遍或特殊流量问题进行分类,是该领域研究的重点[7]。主要有有监督的机器学习和无监督的机器学习[7,8]构成;有监督的分类方法是将N-分类问题转化为N个二分类问题,即为每种流量类型单独训练一个分类模型,常见的有朴素贝叶斯Naive Bayes,支持向量机(support vector machine,SVM)和决策树算法。无监督的分类方法则无需考虑单独处理每个流量类型,常见的如聚类k-means聚类算法等。结合文献[6~8,10]本文中用于特征选择的物理特征如表1。

表1 常用流量识别特征
2 随机森林算法
随机森林(random forest,RF)[11]是由一系列决策树{h(X,Θk),k=1,2,…,K}所组成,其中{Θk}是服从独立分布的随机向量,k为决策树的个数。训练数据集被随机指派到多种决策树上独立处理,且每一个节点上的优化策略是一致的。这些树得出判决或预测值后停止生长,所有树的结果将归入一个集合,并根据最多数的判决计算出最终结果。RF产生的最终分类决策为
(1)
式中 H(x)为组合模型,hi为单个决策树分类模型,Y为目标变量。
近年来,我国应用型本科院校发展取得了一些成绩。在教育部的指导下,以应用技术大学为办学定位的地方本科院校发起并成立了应用技术大学(学院)联盟。截止到2018年6月,已有172所高校加入了该联盟。
就属性特征而言,特征的选择因树的不同而不同,因而产生的树更具有普遍性,RF因此能够平衡一些属性权重带来的偏差或者误差。当树的数量变得庞大时,带有缺失或者统计错误的属性数据就会聚合,因此,对于噪声,RF具有鲁棒性。
RF模型具有很好的收敛性,通过余量函数(marginfunction)定量地描述
(2)
余量函数表示平均正确分类数超过平均错误分类数的程度,mg(X,Y)越大,分类的准确性就越高。由余量函数可推得泛化误差,公式为
PE*=Px,y,mg(X,Y)<0
(3)
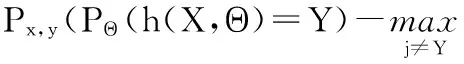
3 实验与验证
3.1 流量特征的选取
特征选择是指从原始特征集中提取出一个特征子集,使得此特征集在特定的分类评价标准下达到最优。目前较多的特征选择方法为过滤方法和包装方法[12]。在本实验中,采用的是RF灰盒算法和人工选取的方法,在不断迭代的RF算法中,利用RF算法的变量重要性度量对特征进行排序,并寻找较大影响因子的叶子节点给予保留,多次迭代进行比较,目的剔除掉流量数据中无关的、冗余的特征,最终得到高准确率,低时间消耗的特征选择结果。迭代公式:Xt=Dt-1αT(Xt∈Rm×k,Dt-1∈Rm×n,α∈Rn×k),其中,Xt为第t次迭代的生成k维数据集,D0为原始数据集,Dt-1为第t-1次迭代的数据集(t≥1)。αT为迭代矩阵(α中只有0和1),且每迭代一次,迭代矩阵会发生变化。
在决策树中,无论对于连续或非连续变量,分裂属性节点的选择直接影响到决策树分类和预测的性能。常用的决策树中,C4.5的信息增益率,分类回归树(classification and regression tree,CART)的Gini纯度指标,都有较好的性能。RF作为一个多种决策树分类器集成的模型,集成了多种分裂与剪枝模型。
实验中将采用Gin指标和信息增益率对训练数据集进行属性筛选,对特征的选取提供理论依据和可选择方案。Gini指标相关公式如下
(4)
(5)
信息增益率相关公式如下
(6)
分裂信息熵为
(7)
信息增益率为
(8)
Gain(An)=Entropy(S)-Entropy(SA)
(9)
特征选择流程图如图1所示 。

图1 流量多特征选择模型流程图Fig 1 Flow chart of flow multi-feature selection model
3.2 数据集
伦敦玛丽女王大学(Queen Mary,University of London)的Moore A等人[13]于2003年从1 000个与互联网相连的校园网用户上,以24 h为一个采集周期,采集了10个时段的10个TCP流量数据,对流数据的持续时间、分组大小、时间间隔、往返时延等的数学统计特征(包括最大、最小、平均大小、方差等度量)以及标志位字段、端口号等做了详细的记录。
Moore_Set总共包含377 526个网络流量样本,每条TCP双向数据流都是以完整的三次握手同步—确认字段(synchronous-acknowledge character,SYN-ACK)开始,以结束—确认字段(finished-acknowledge charater,FIN-ACK)结束,并抽象得到249项属性,且最后一项为目标流量的类别,详细描述可参考文献[13]。
3.3 实验结果分析
在实验中,工具采用新西兰怀卡托大学的Weka—3.7.13,实验主机为CPU为Inter i5—3470,主频为3.20G Hz和3.19 GHz,内存为3.48GB的搭载winXP系统的PC主机。本文的实验研究对象为Moore_Set的前4个数据集,即Moore_Set 1~4总共93 881个样本,在不进行任何特征选择的情况下,采用RF对其进行分类,袋外误差为0.003 6,准确率为99.658 1 %,平均建模时间为128.38 s。
本文选取Gain Ratio Attribute Eval(GRAE)和Info Gain Attribute Eval(IGAE)两种评估器对流量进行第一次选择排序,即RF决策树的分裂点选择法则[14],并且阈值T=22,选取特征排序后结果如表2。
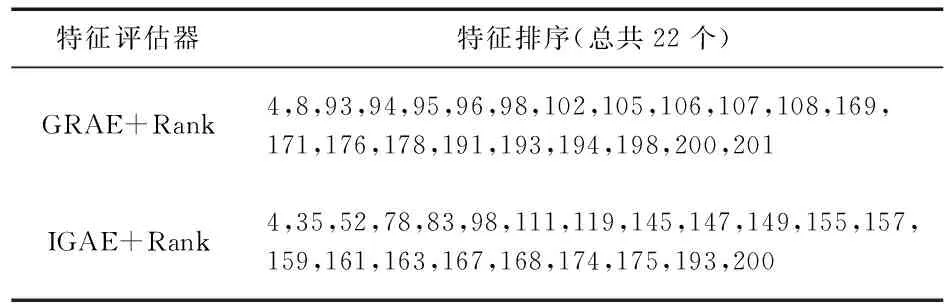
表2 第一次特征选取
经过选取特征集按照排序依次递减,得出的正确率如图2所示。实验中,通过上述两种方式,依次将特征值按照特征排序,不断提高阈值,删除掉后几项,分别得到特征值数目为22,18,12,9,6的五种情况。IGAE算法中,准确率最高99.742 2 %,最低99.730 5 %;GRAE算法中,准确率在99.651 7 %~99.477 %,两种算法准确率都比特征选择前的99.658 1 %高,而整体IGAE算法比GRAE算法准确率高。随着特征数目的减少, IGAE算法准确率没有太大变化,甚至出现升高的情况,而GRAE算法的准确率虽逐渐小幅度降低,但也出现了不降反升的现象(如9特征和6特征时)。由此说明,当剔除冗余分类特征后,准确率不仅不会减小,反而保持不变甚至提高。对比这两种算法,选取IGAE+Rank的特征排序方法。不同特征数目时RF建模消耗时间对比如图3所示。
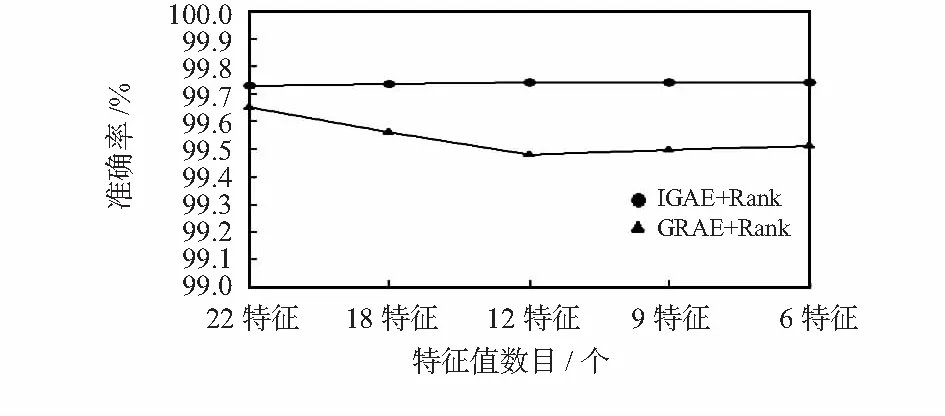
图2 两种特征选取算法准确率对比图Fig 2 Comparison of accuracy of two algorithms on feature selection
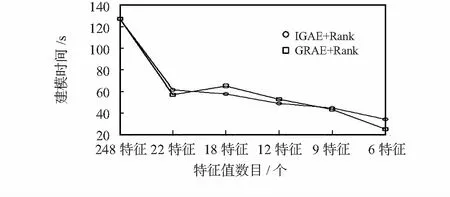
图3 RF建模时间消耗对比图Fig 3 Comparison of modeling time consumption of RF
重新改变阈值 ,结合上文常用于特征选择的物理特征与文献[15],引入{8,43,44,47,48,91,93,94,95,96,109,110,119,120,213,227,230}具有物理意义的特征属性,其中8:Client Port;43,44:total_packets;47,48:pure_acks_sent;91,93,94,95,96:mss_requested和segm_size;109,110:initial_window-packets;119,120:data_xmit_time;213:inter-arrival time;227,230:bulk。结合之前的排序,总结出26个特征属性{4,8,43,44,47,48,91,93,94,95,96,98,107,108,109,110,119,120,193,198,200,201,213,227,230}。经过不断剔除物理属性相近的值,并不断迭代RF分类器,得出如图4的准确率变化图。
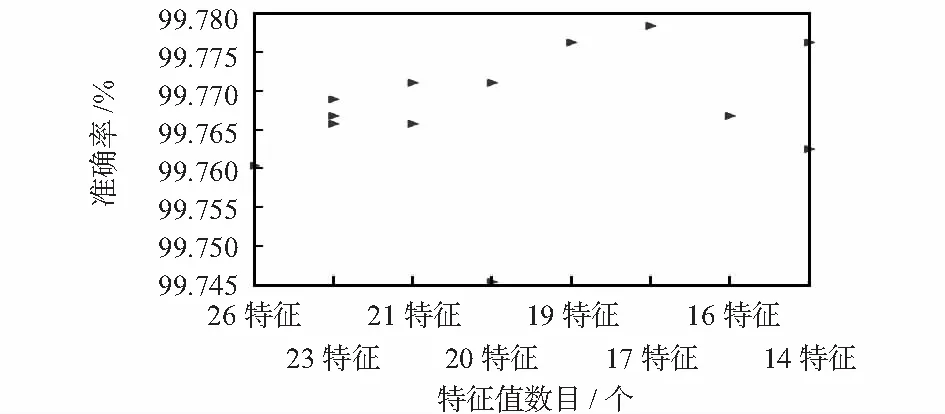
图4 不同特征准确率对比Fig 4 Comparison of different characteristic accuracy
图4中,同一横坐标下,造成不同准确率的关键原因在于剔除特征属性的不同。经过不断比较迭代,最终确定了7个特征属性值:{4,8,98,107,193,198,200},在该数据集下,准确率到达了99.780 6 %。
将数据集重新选取特征,采用优先搜索+基于相关性的特征选择(best first+correlation-based feature selection,BF+CFS)算法对数据子集分别进行特征选择,并对生成的特征集进行二次特征选择;采用分治投票(divide-conquer and voting,DV )[16]算法进行分治投票选择,可得出表3,下文中本实验的特征子集提取算法用RF排序(RF+rank)表示。
采用以上不同算法提取出的特征子集对Moore_set1~4
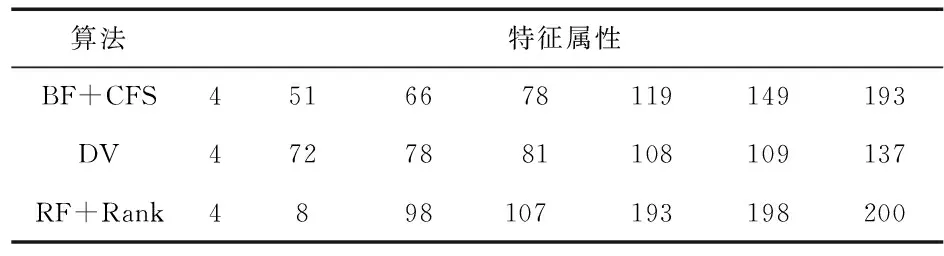
表3 不同算法提取的特征子集比较
数据集进行识别,评估验证采用十折交叉方法对数据进行交叉验证,每次实验重复10次,实验结果取10次重复实验的平均值,并比较Accuracy,Precision,Recall,F-Measure 4个指标。
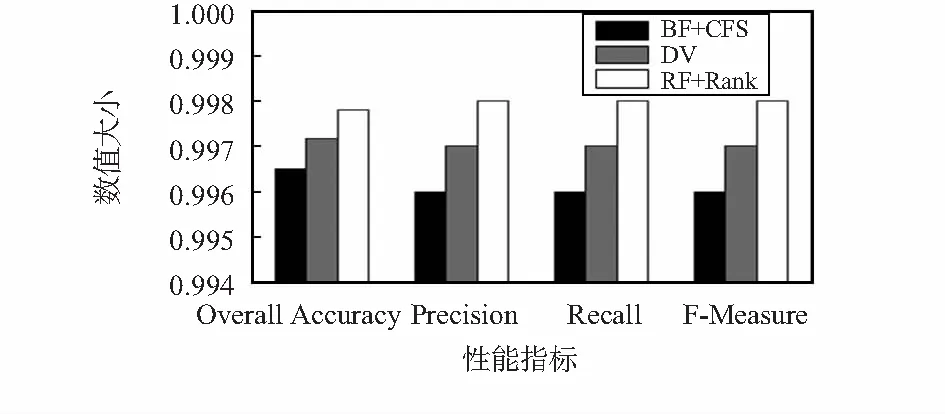
图5 不同特征提取模型性能指标比较Fig 5 Comparison of performance indexes of different feature extraction models
通过对图5的结果分析可知,经过RF模型的识别,不同特征算法表现各异,总体上BF+CFS,DV与RF+Rank算法在度量指标上差距较小,RF+Fank的指标性能最好,在准确率上,比BF+CFS与DV分别提高了0.132 1 %,0.063 9 %。由于RF的算法的优异分类特性,三种算法各自的Precision,Recall和F-Measure三项指标相同,RF+Rank比BF+CFS和DV分别提高0.2 %和0.1 %。因此说明本实验选取的流量特征子集更优越。通过与原始数据分类整体准确率99.658 1 %的对比,本实验的算法为99.780 6 %,总体提高0.122 5 %,且时间上由128.38 s降低为34.63 s,耗费时间大大降低,减少了73 %。尽管准确率提高幅度不大,但是在当今准确率趋于99 %,甚至更高的分类模型下,性能指标的微小提升,对于海量数据来说也是大的进步。
上述实验都是基于RF进行流量分类的,图6通过对比4种分类器的性能:SVM,NaiveBayes,C4.5决策树,RF,结果决策树类分类器明显优于SVM和NaiveBayes,其中SVM准确率、精确率等指标最低,在决策树类中,RF略微优于C4.5算法。
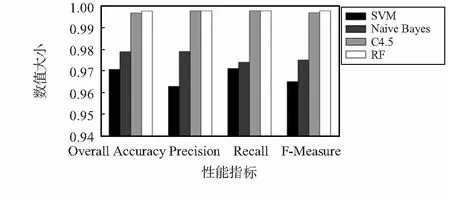
图6 不同分类模型性能指标比较Fig 6 Comparison of performance indexes of different classification models
4 结束语
经过实验验证,本文提出的RF+Rank迭代算法,通过RF模型的分类,在消耗时间上比原始数据集减少了73 %,整体分类准确率增加了0.122 5 %,且特征选择算法性能指标优于其它同类算法,RF模型也优于其它识别分类模型。未来工作重点将在实时性上,对实时流量数据进行分类;同时针对有较大比例不属于已知类的异常的数据集,将改进流量预处理准则,如通过Hellinger距离排除掉异常数据。随着网络规模日益增大、云计算与大数据的普及,本文提出的特征选择算法将使得云计算技术和数据中心网络在现有大规模流量识别中发挥重要作用,提升网络管理效率和服务质量,具有较高的理论研究与实际应用价值。
[1] Ding L,Yu F,Peng S,et al.A classification algorithm for network traffic based on improved support vector machine[J].Journal of Computer,2013,8(4):1090-1096.
[2] 柏 骏,夏靖波,吴吉祥,等.实时网络流量分类研究综述[J].计算机科学,2013,40(9):8-15.
[3] Kalaiselvi T,Shanmugaraja P.Hybrid alforithm for the classification of traffic flows[J].International Journal of Emerging Technology in Computer Science & Electronics (IJETCSE),2016,21(2): 340-343.
[4] 李平红,王 勇,陶晓玲.基于成对约束扩展的半监督网络流量特征选择算法[J].传感器与微系统,2013,32(5):146-149.
[5] de Donato W,Pescape A,Dainotti A.Traffic identification engine:
An open platform for traffic classification[J].Network,IEEE,2014,28(2):56-64.
[6] 朱文波.流统计特征在网络流量分类中的应用研究[D].杭州:杭州电子科技大学,2015.
[7] 王怡萱.网络流量分类方法研究及流量特征分析[D].北京:北京邮电大学,2013.
[8] 周剑峰,阳爱民,刘吉财.基于改进的C4.5算法的网络流量分类方法[J].计算机工程与应用,2012,48(5):71-74.
[9] 陈中杰,蒋 刚,蔡 勇.基于SVM一对一多分类算法的二次细分法研究[J].传感器与微系统,2013,32(4):44-47.
[10] 赵树鹏,陈贞翔,彭立志.基于流中前5个包的在线流量分类特征[J].济南大学学报:自然科学版,2012,26(2):156-160.
[11] 张 建,武东英,刘慧生.基于随机森林的流量分类方法[J].信息工程大学学报,2012,13(5):621-625.
[12] 侯大军,朱伟兴.基于改进粒子群算法的最优特征子集研究[J].传感器与微系统,2010,29(9):64-66.
[13] Moore A,Zue V ,Crogan M.Discriminators for use in flow-based classification[D].London:Queen Mary and Westfield College,2005.
[14] 姚登举,杨 静,詹晓娟.基于随机森林的特征选择算法[J].吉林大学学报:工学版,2014,44(1):137-141.
[15] 叶春明,王 珍,陈 思,等.基于节点行为特征分析的网络分类方法[J].电子与信息学报,2014,36(9):2158-2165.
[16] 高 文,钱亚冠,吴春明.网络流量特征选择方法中的分治投票策略研究[J].电子学报,2015,43(4):795-799.
Research on traffic multi-feature extraction and classification based on random forest*
WEI Ze-kun1, XIA Jing-bo2, ZHANG Xiao-yan1, FU Kai1, SHEN Jian1
(1.College of Information and Navigation,Air Force Engineering University,Xi’an,710077,China;2.Tan Kah Kee College,Xiamen University,Xiamen 363105,China)
Diversity and complexity of network traffic and the high real-time requirement has brought great challenges,meanwhile by the network traffic classification based on machine learning ,the selection of flow statistics feature can quickly and accurately identify traffic,which is of great significance.As a gray box model,random forest(RF) is popular in recent years,which has good recognition ability of the current network traffic.By the algorithm of RF node selection,flow characteristics are selected,and combined with the physical significance to carry out optimization and a number of feature extraction.Experimental results show that the proposed algorithm is superior to the model construction,time-consumption is greatly reduced,meanwhile the accuracy is improved.
traffic statistic feature; random forest(RF); gray box model; feature extraction
10.13873/J.1000—9787(2016)12—0055—05
2016—10—08
陕西省科技计划基金资助重点项目(2012JZ8005); 航空科学基金资助项目(20141996018)
TP 393
A
1000—9787(2016)12—0055—05
韦泽鲲(1992-),男,陕西西安人,硕士研究生,主要研究方向为大数据挖掘和网络态势感知。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
微型电脑应用(2021年3期)2021-03-31 08:56:46
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
电子制作(2017年23期)2017-02-02 07:17:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
西北工业大学学报(2015年4期)2016-01-19 03:31:47
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
