
基于LDA与距离度量学习的文本分类研究
2016-12-10 22:09詹增荣程丹
湖南师范大学学报·自然科学版 2016年5期
关键词:文本分类
詹增荣+程丹


摘 要 提出了一种基于隐含狄利克雷分布(LDA)与距离度量学习(DML)的文本分类方法,该方法利用LDA为文本建立主题模型,借助Gibbs抽样算法计算模型参数,挖掘隐藏在文本内主题与词的关系,得到文本的主题概率分布.以此主题分布作为文本的特征,利用DML方法为不同类别的文本学习马氏距离矩阵,从而较好的表达了文本之间的相似性.最后在学习到的文本间距离上,利用常用的KNN及 SVM分类器进行文本分类.在经典的3个数据集中的实验结果表明,该方法提高了文本分类的准确率,并且在不同的隐含主题数目参数下能体现较好的稳定性.
关键词 文本分类;距离度量学习;隐含狄利克雷分布;主题模型
中图分类号 TP391.41 文献标识码 A 文章编号 1000-2537(2016)05-0070-07
Abstract A text classification method based on Latent Dirichlet Allocation (LDA) and distance metric learning (DML) were presented. The method models text data with LDA, which generate the topic distribution of different text through detecting the hidden relationship between different topics and words inside the text data, and parameters of the model are estimated with Gibbs sampling algorithm. The generated topic distribution is used as the features of the text data, and the DML method is used to learning the Mahalanobis distance metric for different classes so that the similarity between text data are well presented. Classifiers like KNN or SVM are used to classify text data based on the learning distances. Experimental results showed that this method can improve the text classification accuracy and is robust in setting different topic number.
Key words text classification; distance metric learning; latent Dirichlet allocation; topic model
随着互联网的高速发展,文本数据作为最主要的信息载体之一以指数级的速度不断增长.因此,如何有效地从海量文本数据中挖掘出有用的信息成为当前的迫切需求.文本自动分类技术作为自然语言处理的关键技术近年来广泛受到关注并得到了快速的发展,已成为当前研究的热点.文本自动分类的过程中主要的技术包括了文本的预处理、特征的提取、文本的表示、分类器的设计,以及分类效果的评估等.
在文本分类研究中,向量空间模型(Vector Space Model,VSM)[1]是数据挖掘领域经典的分析模型之一.VSM利用统计词在文本和文本集中出现的频率来表征词对文本的重要性,最终将文本表示成一个向量,并通过余弦等不同的距离度量方式来计算文本之间的相似度.然而,由于自然语言的复杂性,类似文本语义等复杂问题并不能在VSM中得到建模,而且利用VSM表示文本得到的数据空间是极度高维且稀疏的.近年来,以隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)[2]为代表的主题模型成为研究的热点.基于LDA主题模型进行建模能很好地考虑文本语义的相似性问题,因而被广泛应用到各个文本分类算法中,如Bao[3]、姚全珠[4]、李文波[5]等都使用LDA模型来对文本进行分类.
样本间的距离度量是模式识别领域研究的核心问题之一,它对分类、聚类等模式分析任务非常重要,如K近邻、支持向量机等分类算法的准确率就非常依赖于距离的定义.在文本分类中,为文本的特征向量选择适合的距离度量方法将直接影响到最终分类的效果.为此,许多学者分别提出了不同类型距离度量学习(Distance Metric Learning,DML)方法,即从给定训练集的相似或不相似的样本中学习一个距离度量来提高分类或聚类等任务的准确率.Davis[6]等给出了一种基于信息理论的方法去学习一个马氏距离,Weinberger[7]等阐述了就提高KNN分类器的准确率中的大间距框架的距离学习问题,Kulis[8]等给出了距离学习的综述.多数的DML研究都是着重在寻找一个线性矩阵来最优化全局数据间的可分离性和紧凑性,但是如果不同类别的数据呈现出不同的分布,寻找一个适合全局数据的距离度量线性矩阵往往不太现实.一个可行的方法是针对不同的局部数据来学习不同的线性矩阵,从而满足不同局部数据的最佳距离度量矩阵.
基于以上考虑,本文提出基于LDA和距离度量学习的文本分类方法.该方法首先利用LDA模型对文本集进行建模,即利用文本的统计特性将文本语料映射到各个主题空间,挖掘隐藏主题与词的分布,从而得到文本的主题分布.然后,以此分布为文本特征,针对不同类别的文本通过距离度量学习得到适合该类别文本与其他文本最佳距离度量矩阵.最后,根据得到的不同类别文本的距离度量矩阵计算文本数据与该类别文本间的距离,再放到常见的KNN[9]或SVM[10]分类器中实现文本的分类.
1 相关理论
1.1 LDA模型
LDA模型[2]是由Blei提出等人在2003年提出的一种对离散数据集建模的主题概率模型.LDA模型相对于传统的LSI[11]和PLSI[12]等模型不仅具有更加清晰的层次结构而且解决了随着训练文本数目增加主题个数不断增加导致的过渡拟合问题,从而更加适合于大规模语料库分析.
LDA是一种非监督机器学习技术,它的基本思想是文本由多个潜在的主题所构成,而每个潜在的主题又由文本中若干个特定词汇构成.它将文本、主题、词的结构构成三层贝叶斯概率模型,即文本中的主题服从Dirichlet分布,且任一主题中出现的词服从多项式分布.如图1所示,LDA模型具有非常清晰的层次结构.
1.2 GP采样
LDA对参数的估计比较常用的方法包括了变分推算方法和Gibbs抽样方法.其中Gibbs抽样算法属于马尔科夫链-蒙特卡罗(Markov Chain-Monte Carlo,MCMC)的一种特例,它通过构造收敛于目标概率分布的马尔科夫链,并从链中抽样出接近于该概率分布的样本.由于Gibbs抽样算法简单且容易实现,对于联合概率分布维度较高的情况非常适用,因此成为主题模型最常用的参数估计算法.
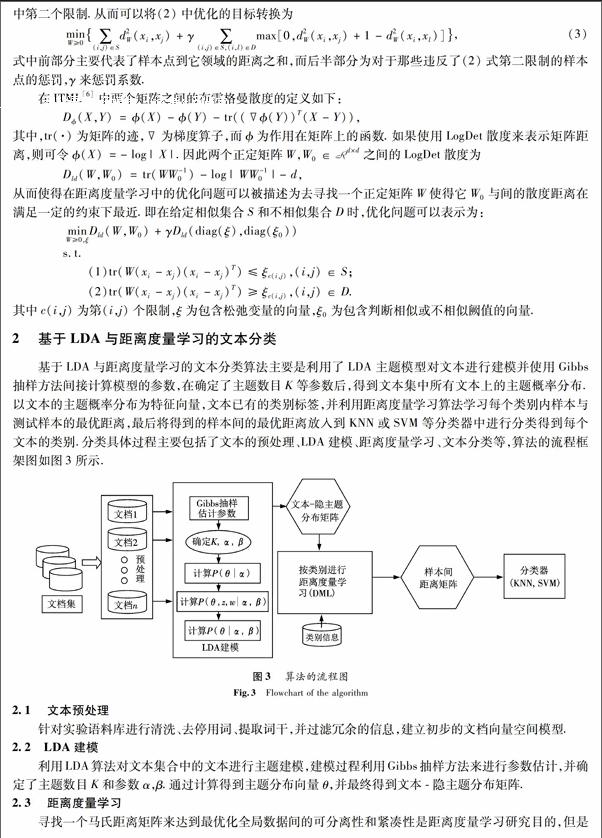
在式(1)中,需要估计的定参数有两个,一个是在参数α下产生的文档中主题的分布θ;第二是在确定主题后,由参数β产生的主题中词的分布φ.利用Gibbs抽样算法可以得到:
θm,k=ntk+ak∑Kk=1nkm+ak, φk,t=ntk+βt∑Vt=1ntk+βt,
其中φk,t为主题k中词项t的概率;θm,k为文本m中主题k的概率;ntk表示主题k中出现词项t的次数;V为所有文档中出现的词的总数.
1.3 距离度量学习
2 基于LDA与距离度量学习的文本分类
基于LDA与距离度量学习的文本分类算法主要是利用了LDA主题模型对文本进行建模并使用Gibbs抽样方法间接计算模型的参数,在确定了主题数目K等参数后,得到文本集中所有文本上的主题概率分布.以文本的主题概率分布为特征向量,文本已有的类别标签,并利用距离度量学习算法学习每个类别内样本与测试样本的最优距离,最后将得到的样本间的最优距离放入到KNN或SVM等分类器中进行分类得到每个文本的类别.分类具体过程主要包括了文本的预处理、LDA建模、距离度量学习、文本分类等,算法的流程框架图如图3所示.
2.1 文本预处理
针对实验语料库进行清洗、去停用词、提取词干,并过滤冗余的信息,建立初步的文档向量空间模型.
2.2 LDA建模
利用LDA算法对文本集合中的文本进行主题建模,建模过程利用Gibbs抽样方法来进行参数估计,并确定了主题数目K和参数α,β.通过计算得到主题分布向量θ,并最终得到文本-隐主题分布矩阵.
2.3 距离度量学习
寻找一个马氏距离矩阵来达到最优化全局数据间的可分离性和紧凑性是距离度量学习研究目的,但是在数据呈现出不同的分布的情况下,很难得到一个适合全局数据的距离度量矩阵.因此,本节提出为不同的类别样本数据学习一个适合该类别的马氏距离矩阵w,用于表达该类别内数据样本与其他数据样本的距离度量.
设C1,C2,…,CM为数据样本的类别,M为类别总数目,对于类别p中的数据样本集{xp1,xp2,…,xpNp}(Np为类别p中的样本数目),为了学习到一个参数矩阵Wp来最优的表达该类别中样本与测试样本间的距离,可以将训练样本中的任意样本xpi,xpj,xql(其中p≠q),作为(3)式中的限制来训练得到最优参数矩阵Wp.同理也可以得到其他类别的参数矩阵W1,W2,…,Wm,从而将(3)式中的问题可以被重新描述为:
其中相似集合S和不相似集合D的定义为:当学习某一类别p的马氏距离矩阵时,S中的元素为该类别所有元素的二元组合,D中的为该类别的元素与其他类别元素的二元组合.
2.4 文本分类
根据LDA建模获得的所有文本的主题概率分布矩阵,结合样本类别信息利用距离度量学习算法计算出样本之间的距离,然后放到常见的KNN或SVM分类器中进行分类得到相应的测试样本的类别.
3 实验设计与结果分析
3.1 实验环境
实验在CPU为Intel Core 8核、内存为16G、操作系统为Windows 7的PC机上进行.主要算法采用了Matlab来实现,LDA算法利用文[13]中提供的Matlab Toolbox来实现,距离度量学习算法及KNN分类器算法是在ITML[6]中的算法的基础上改进得到.SVM分类器选取了台湾大学林智仁教授开发设计的LIBSVM[14]作为分类器的训练环境实现.
3.2 实验数据
实验选择了3个经典的数据集Reuters21578,20Newsgroups和TDT2作为实验的数据,数据来源及预处理都来自于文[15].Reuters21578是路透社1987年中新闻专线的文档集合.它包含了21 578个样本,分成135个类别.为了实验方便剔除了属于多个类别的样本,并从中选取了最大的9个类别集合共7 258个数据作为实验数据.20Newsgroups文档集合包含了18 846个文档,平均分布为20个类别,为了减少实验有效性,选取了全部类别作为实验数据.TDT2(NIST Topic Detection and Tracking)文档集包含了来自6个不同新闻源的文档集合,总共有11 201个文档数据,并被分成96个语义类别.为了简化实验结果,剔除了属于多个类别的文档数据,最后只保留了9 394个文档.所有的数据集合都按照文[15]的方法做了预处理,包括剔除无用词语、应用波特词干算法等.最后都按照按照0.7的比例划分训练集和测试集.
3.3 评估方法
为了较好地描述模型对文本分类的效果,实验从分类的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F测量来评估测试的结果,其中F测量是一种结合精确率和召回率的平衡指标.对于分类问题可以用表1所示的混合矩阵来表示分类结果的情况.根据表中的描述,实验中各个评估方法的定义如下(其中一般取值为1):
3.4 实验结果分析
在经典的3个数据集进行预处理后分别采用3种算法进行实验,包括传统的KNN分类;LDA建模后进行KNN分类(LDA-KNN);LDA建模后利用距度量离学习算法计算样本间距离后再进行KNN分类(LDA-DML-KNN).实验得到结果如表2所示(其中LDA的主题数取值为100),从表2中可以看出,基于LDA主题模型与KNN相结合算法(LDA-KNN)相对于传统的KNN算法具有较高的准确率,在Reuters和TDT数据集上的多项指标都有超过15%的提高.而融合距离度量学习的分类算法(LDA-DML-KNN)比LDA-KNN算法在准确率等指标上具有5%左右的提升.
鉴于主题数(T)的大小会影响实验的效果,实验针对不同的主题数目在3个数据集上分别使用KNN和SVM两个分类器进行了测试,测试结果如图4所示,其中KNN的领域数目k=10,SVM采用了高斯核函数(其中参数σ=1/4),且为了训练样本间不同类别的样本距离取样本到相互间距离的中值.在3个实验集合实验结果中,当主题数取得T=100时已经具有较好的效果.其次,结果表明融合距离度量学习的分类算法不仅取得较高的准确率且更加稳定.此外,在实验中SVM分类器比KNN分类具有更好的分类效果,特别是在20Newsgroups数据集上.
4 总结
本文将LDA主题模型和距离度量学习应用到文本分类中,不仅将文本深层次的语义知识嵌入到模型中,并且学习了不同文本深层次语义之间的距离度量,从而提高了文本分类的准确率.此外,由于LDA主题模型所建立的文本主题空间的维度要远远小于文本的向量空间模型,大大提高了计算了速度.在文本分类常用的3个实验数据集进行的实验结果表明,该方法可以明显提高文本分类效果,模型可以为数据挖掘、自然语言处理等学科的研究和实现提供借鉴与参考.
参考文献:
[1]SALTON G, WONG A, YANG C S. A vector space model for automatic indexing [J]. Commun ACM, 1975,18(11):613-620.
[2]BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Machine Learning Res, 2003,29(3):993-1022.
[3]BAO Y, COLLIER N, DATTA A. A partially supervised cross-collection topic model for cross-domain text classification; proceedings of the 22nd ACM international conference on information & knowledge management[C]. F. ACM, 2013.
[4]姚全珠,宋志理,彭 程. 基于LDA模型的文本分类研究 [J]. 计算机工程与应用, 2011,13(1):150-153.
[5]李文波,孙 乐,张大鲲. 基于Labeled-LDA模型的文本分类新算法 [J]. 计算机学报, 2008,31(4):620-627.
[6]DAVIS J V, KULIS B, JAIN P, et al. Information-theoretic metric learning[C]//Proceedings of the 24th international conference on Machine learning, F. ACM, 2007.
[7]WEINBERGER K Q, SAUL L K. Distance metric learning for large margin nearest neighbor classification [J]. Machine Learning Res, 2009,10(2):207-244.
[8]KULIS B. Metric learning: A survey [J]. Found Trends Machine Learning, 2012,5(4):287-364.
[9]COVER T M, HART P E. Nearest neighbor pattern classification [J]. Inf Theory, IEEE Trans, 1967,13(1):21-27.
[10]BURGES C J C. A tutorial on support vector machines for pattern recognition [J]. Data Mining Knowledge Discovery, 1998,2(2):121-167.
[11]DUMAIS S T. Latent semantic indexing (LSI): TREC-3 report [J]. Nist Special Publication SP, 1995,9(2):219.
[12]THOMAS H. Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, Berkeley, California, USA, F. ACM, 1999.
[13]GRIFFITHS T L, STEYVERS M. Finding scientific topics [J]. Proc Nat Acad Sci, 2004,101(suppl 1):5228-5235.
[14]CHANG C C, LIN C J. LIBSVM: a library for support vector machines [J]. ACM Trans Intell Syst Technol (TIST), 2011,2(3):27.
[15]ZHANG D, WANG J, CAI D, et al. Self-taught hashing for fast similarity search[C]//Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval, F. ACM, 2010.
(编辑 CXM)
猜你喜欢
电脑知识与技术(2016年30期)2017-03-06
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
湖南大学学报·自然科学版(2016年4期)2016-08-12
中国教育信息化·基础教育(2016年2期)2016-05-31
软件(2015年5期)2015-08-22
