
一种面向100Gbps网络的L7-filter硬件加速方法
2016-12-09 06:35:11付文亮
电子学报 2016年11期
付文亮,郭 平,周 舟
(1.北京理工大学计算机科学与技术学院,北京 100081;2.中国科学院信息工程研究所信息内容安全技术国家工程实验室,北京 100093)
一种面向100Gbps网络的L7-filter硬件加速方法
付文亮1,郭 平1,周 舟2
(1.北京理工大学计算机科学与技术学院,北京 100081;2.中国科学院信息工程研究所信息内容安全技术国家工程实验室,北京 100093)
L7-filter是当前广泛应用的流量分类系统,其采用基于正则表达式匹配的深包检测方法,通过检测数据包有效载荷中存在的字符串特征对流量进行分类.然而,由于计算复杂度高、存储消耗大等原因,现有L7-filter软硬件方法的处理性能严重不足,不能适应当前40Gbps以及更高性能骨干网络.在对L7-filter的应用层协议规则集进行分析,总结其中广泛存在的特征的基础上,本文提出了一个硬件加速方法,其通过有针对性的数据模型、算法优化、匹配架构设计以提高流量分类系统的处理能力.为了验证方法的可行性,采用了基于Virtex6的FPGA板卡实现原型系统并对其进行评估.实验结果表明,原型系统的数据吞吐率可以达到约115Gbps.
流量分类;正则表达式匹配;100Gbps;FPGA
1 引言
随着互联网应用进一步发展,其逐渐渗透到人们生活的各个方面,为人类生活提供了极大便利的同时,也为网络安全领域提出新的挑战.一方面,互联网安全环境日趋复杂,针对网络应用漏洞而产生的木马、蠕虫攻击等恶意行为逐渐增多,现有网络安全系统亟待加强针对网络应用的检测能力,应用层协议识别成为网络安全、管理系统的核心功能之一[1];另一方面,随着网络接入带宽遵循丹尼尔定律快速增长[2](即每年增长约50%),40Gbps及更高性能骨干网络标准逐步普及,现有应用层协议识别方法性能不足[3],成为制约相关网络安全、管理系统发展的重要瓶颈.
L7-filter是当前主流的应用层协议识别系统,其采用了基于正则表达式匹配的深包检测方法对数据包有效载荷中的字符串特征进行识别[3].由于具有识别率高、识别准确率高等优点,L7-filter常被用于网络安全相关系统.然而,受其核心正则表达式匹配方法处理能力制约,现有L7-filter软件检测速率仅达到百兆级别[4].为了提高性能,正则表达式匹配加速方法成为研究热点.具体来看,现有加速方法分为基于通用处理器的软件方法、基于特定处理器的软件方法(如网络处理器)、基于可编程芯片的方法等.
基于通用处理器的软件方法主要利用硬件平台处理器主频高、内存大等特点,在Linux等开源操作系统上通过标准编程语言进行实现.为了达到高性能,基于通用处理器的加速方法主要针对软件算法进行优化,涉及压缩状态机[5]、合并状态[6~8]、分组规则[9]等.然而,由于硬件平台并行能力有限(匹配引擎数量有限,单引擎融合成百上千规则,造成状态机爆炸)、代码执行效率不高等原因,该类加速方法只能提供千兆级别吞吐率.
为了解决通用平台并行性不足的问题,研究者提出使用网络处理器(Network Processor,NP)、图像处理器(Graphic Processing Unit,GPU)、众核处理器(Many-Core Processor)等专用处理平台实现加速.由于计算核心数量较多,该类型加速方法能够运行多个独立匹配引擎,降低了每个引擎的状态机规模.相关研究证明,基于众核平台[10]、GPU[11,12]的匹配方法性能可以达到万兆级别.然而,由于匹配引擎频繁读取存储器、需要通过额外硬件接口与软件驱动获取网络数据等原因,该类方法无法适用于40Gbps以及更高性能网络.
随着信息技术的快速发展,具有天然并发性、丰富逻辑资源、高可扩展性等优势的现场可编程逻辑门阵列(Field-Programmable Gate Array,FPGA)进入人们视线.FPGA加速方法可分为两类:基于存储器和基于芯片逻辑资源.
基于存储器的方法将状态机跳转规则和命中状态存入存储器,通过引擎查询存储器实现状态机运转.匹配时,引擎根据输入字符和当前活跃状态索引跳转表以找到下一时刻活跃状态,并根据当前活跃状态索引命中状态表以判断是否匹配成功.为了提高系统吞吐率、增加规则支持的数量,相关研究主要从降低状态机存取开销的角度出发,针对状态机跳转的统计特性[13]、状态跳转辅助变量[4,14,15]、状态机合并[16]等进行优化.通用存储器的优化也为该方法带来一定性能提升[17].然而,由于频繁读取存储器、重复设置匹配引擎导致计算复杂度增加等问题,该类加速方法处理能力不能满足骨干网络要求.
基于芯片逻辑资源的匹配方法通过将状态机映射到FPGA可编程逻辑资源(如查找表和触发器)实现匹配.为了达到高性能,Yamagaki N.等人对非确定有限状态机(Nondeterministic Finite Automata,NFA)进行扩展[18],通过将1字符输入非确定有限状态机(如非特指,下文状态机均特指非确定有限状态机)转化为等价的多字符输入状态机以提高匹配引擎的处理能力.然而,由于多字符输入状态机在输入字符宽度较大时存在状态机规模膨胀的问题,该方法仅仅适合输入字符数量不超过8字符的情况,提供千兆级别处理能力[18].
由于不需要共享处理器、存储器等硬件资源,基于FPGA逻辑资源的加速方法具有较高的并行性和优化潜力.此外,该类方法具有较低的生产与维护成本,且基于FPGA芯片的子系统更适合嵌入到相关网络系统.基于上述发展现状,本文首先针对L7-filter规则集及多字符输入状态机规模膨胀问题进行研究,并有针对性的提出一个新型多字符输入状态机,从数据模型角度出发降低状态机规模及正则匹配的计算复杂度;然后,针对匹配模型的特点,提出一个基于Bitmap的优化方法,从算法角度进一步降低匹配的计算复杂度;最后,提出一个适合FPGA芯片的高性能匹配架构,从具体实现角度出发提高加速方法的性能.
2 L7-filter规则集特征分析
正则表达式是描述字符串特征的有效工具,其每个字符或者为具体字符(如a,b等),或者为描述字符模式的元字符.L7-filter协议规则主要有两种元字符:集合元字符和重复元字符.前者用于描述具体字符的集合(如元字符“.”代表匹配除“ ”外的任意一个具体字符);后者用于描述字符的重复模式(如元字符“*”代表前一字符重复1次或多次).从本质看,元字符及多个元字符互相影响造成了正则匹配计算复杂度高、存储消耗大等问题[19].本节针对L7-filter规则集[20]进行分析,找到其中广泛存在的规则特征,并以此作为硬件加速方法的基础.其中,整个规则集包含了125条正则表达式,涵盖了常用互联网应用,如P2P、聊天、游戏、邮件等.需要注意的是,本节探讨的规则特征不仅适用于L7-filter规则集中已有的应用协议,还体现了网络应用在通信中普遍存在和广泛使用的特征.换句话说,本节提炼的规则特征具有一定的普适性.
2.1 特征起始位置
L7-filter协议特征主要由网络通信中自定义的内容类型标识、命令等关键字构成.这些关键字往往被安排在数据包的固定位置以方便通信端进行解析,例如FTP数据包的用户有效载荷前三个字符通常是“220”.本文首先针对协议特征的起始位置是否固定进行统计,结果如表1所示.规则集中约76%协议特征从用户有效载荷的第一个字符开始.经典的状态机及其衍生算法并未针对这一规则特性进行优化.
为了提升性能,如果基于分而治之的思想对正则表达式进行合理拆分,通过顺序识别多个子特征达到检测目的,则起始位置固定的协议特征往往具有较低的识别复杂度.
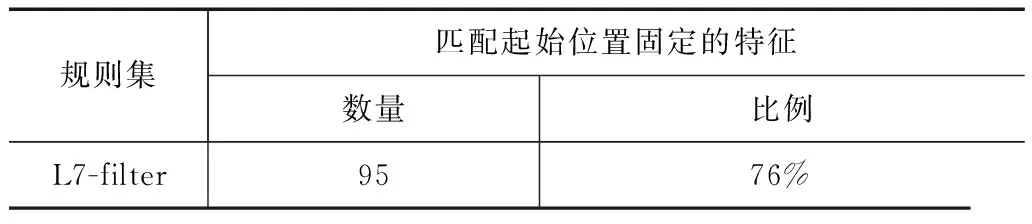
表1 L7-filter规则集起位置统计
2.2 重复元字符
重复元字符(如“*”,“+”等)是协议特征正则表达式的重要组成.由统计可知,L7-filter规则中约80%至少含有1个重复元字符;约10%含有5个以上重复元字符(个别协议规则甚至有16个).
为了考量L7-filter规则集对多字符输入状态机规模的影响,作者根据L7-filter的协议特征集生成输入字宽不同的多字符输入状态机,并对其状态机规模(主要指跳转数量)进行统计,结果如图1所示.从趋势来看,多字符输入状态机的跳转数量随着每周期处理字符数的增加指数增长;从具体数字来看,同单字符输入状态机相比,在每周期处理32字符情况下,多字符状态机跳转数量平均增长500多倍;每周期处理128字符情况下,状态机跳转数量平均增长超过百万倍.由于FPGA芯片硬件资源有限,多字符输入状态机数据模型仅能够适用于每周期处理字符较少的情况.
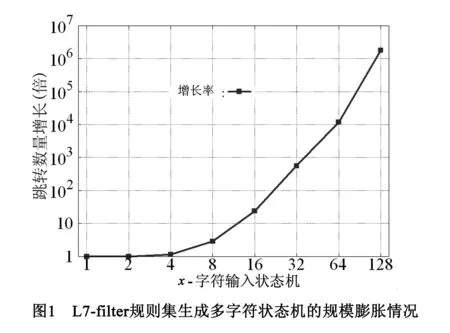
为了进一步明确重复元字符数量与状态机膨胀的关系,我们将L7-filter规则集转换为32字符输入状态机,并根据其状态机规模膨胀程度进行分类(同单字符输入状态机相比),如表2所示.状态机跳转数量膨胀率小于10的规则平均仅含有0.64个重复元字符;状态机跳转数量膨胀率超过10000倍的协议规则平均含有5.3个重复元字符.上述结果进一步说明重复元字符的数量是影响多字符输入状态机规模的重要因素.在L7-filter协议规则集条件下,如何提高单周期处理字符数量的同时控制状态机规模是本文要解决的一个重要科研问题.

表2 32字符输入状态机重复元字符数与跳转数增长关系
2.3 集合元字符
如表3所示,L7-filter的规则集中,带有集合元字符的正则表达式比例为69%,且平均每条规则含有5个集合元字符.
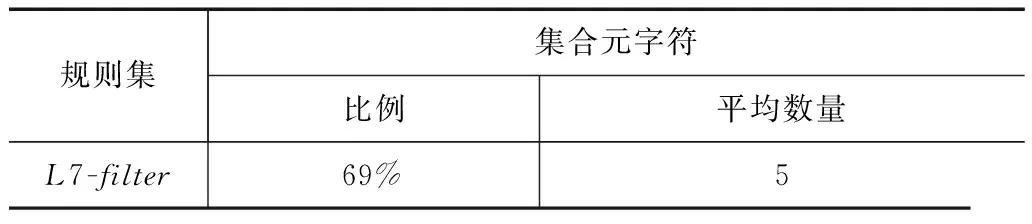
表3 L7-filter规则集集合元字符统计
通常情况下,集合元字符与重复元字符配合可能导致匹配计算复杂度增加.例如,为了识别IMAP协议(其正则表达式为“^(〔 ok|a[0-9]+noop)”,匹配引擎识必须能够识别字符集合[0-9]至少1次,至多上千次(受包长限制),其状态机规模与复杂度远大于非集合元字符的情况.
此外,如果采用拆分正则表达式、通过多个子状态机配合识别协议特征,集合元字符与重复元字符配合还可能造成出现多个中间匹配结果的情况,具体问题将在下节详细分析.
3 基于Link-NFA的硬件加速方法
本节首先提出一个扩展的多字符输入状态机模型,称为Link-NFA;然后,针对Link-NFA的特点提出一个基于Bitmap的优化方法;最后,提出一个适合FPGA的高性能匹配架构,从实现角度出发提高匹配性能.
3.1 Link-NFA
Link-NFA对已有状态机模型进行扩展,使用多个相关联的多字符输入状态机(简称Sub-NFA)对正则表达式进行识别.Sub-NFA每周期可以处理k个字符,最多有1个指向其起始状态的重复跳转(处理k个相同的字符,该字符称为BRPT).多个Sub-NFA之间通过Link跳转承接逻辑关系,且后续Sub-NFA的首个状态均有1个重复跳转.
Link-NFA可以由9元组{S,∑,s0,F,k,σbasic,σlink,L,θ}表示,其中:S为状态集合;∑为输入字符集合;s0为起始状态集合;F为结束状态集合;k为每周期处理字符数量;σbasic为Sub-NFA内部跳转函数:S×∑k→Sσlink为跨越Sub-NFA跳转函数S→S;L标识当前输入的k字符中,哪些已经被处理;θ为输入替换函数:S×∑k×L×BRPT→∑k.
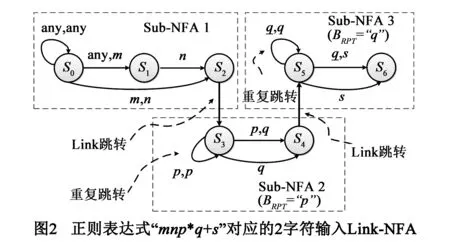
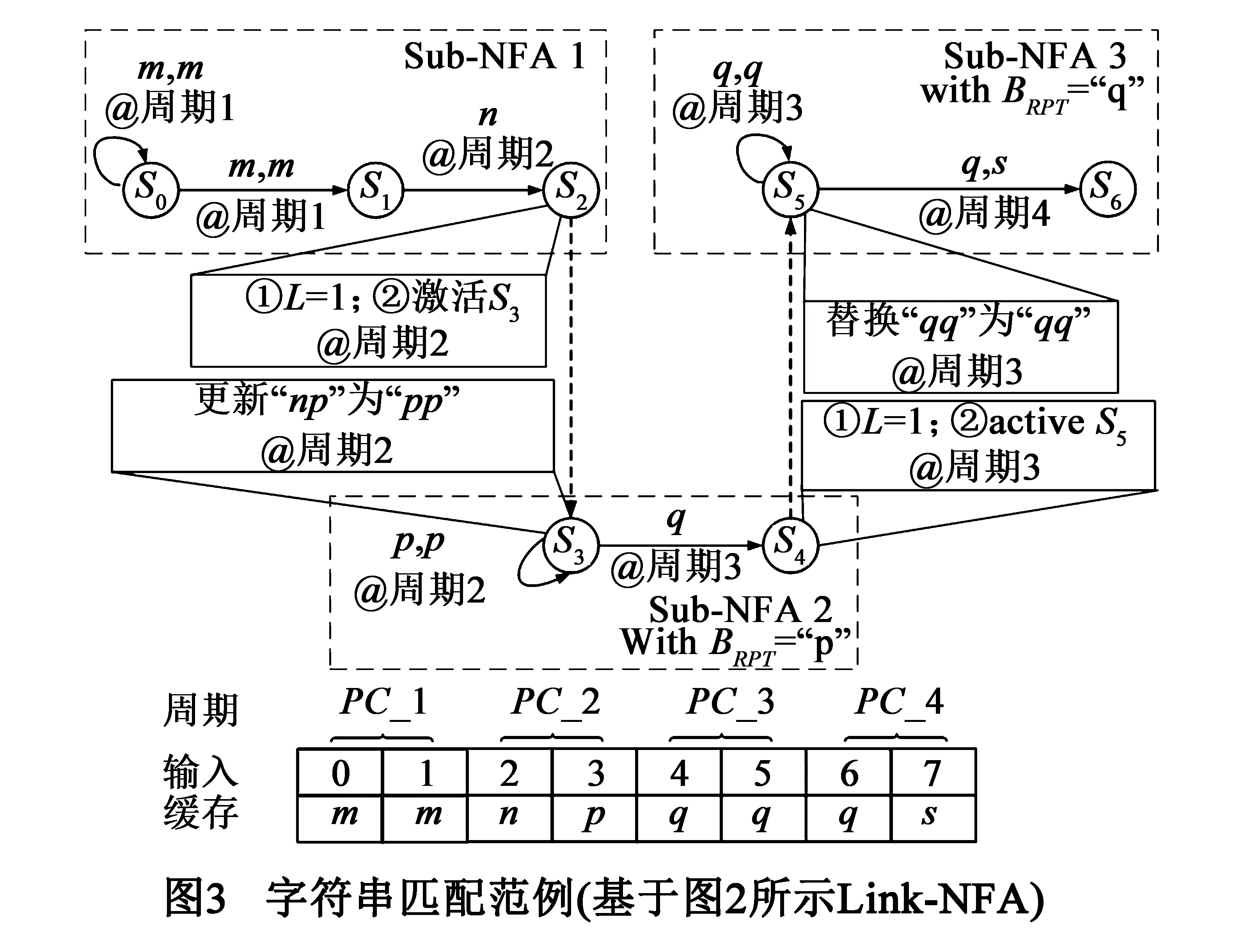
图2为表达式“mnp*q+s”对应2字符输入Link-NFA范例.Link-NFA根据两个跳转函数决定下一活跃状态:σbasic和σlink.如果当前状态不是某Sub-NFA的最终状态,则使用σbasic函数确定下一活跃状态且其在本Sub-NFA中;否则使用σlink函数确定下一活跃状态且其在后续Sub-NFA中(跨Sub-NFA).
如果当前Sub-NFA仅处理了当前k字符输入的前L个字符,则后续Sub-NFA应当跳过已经被处理的字符继续匹配.Link-NFA使用替换函数θ完成上述工作.具体来说,函数θ使用L个后续Sub-NFA的BRPT来替换当前输入中已经被处理的前L个字符,并将L与更新过的输入传递给后续Sub-NFA.
基于Link-NFA的正则表达式匹配方法见算法1.每匹配周期开始时,REGEX-MATCH-TOP函数从Input-Buffer读取k个字符,并从Link-NFA起始状态或本周期活跃状态开始调用PROC-INPUT函数进行匹配.PROC-INPUT函数根据当前活跃状态、输入k字符、已处理字符个数和跳转函数σbasic找到下一时刻活跃状态.需要注意的是,如果下一活跃状态是某Sub-NFA的结束状态(非Link-NFA结束状态),则需要调用σlink以找到后继Sub-NFA,并标记当前输入k字符中已经被处理过的字符.匹配过程中,系统不断递归调用PROC-INPUT函数直到某处理周期输入的k字符全部被处理完成或者匹配成功.


图3描述了如何用Link-NFA处理字符串“mmnpqqqs”.其中,对应2字符输入Link-NFA状态机的信息如图2所示.每个处理周期开始时,系统从缓冲区读取2个字符.匹配从状态S0开始,并根据σbasic激活状态S0和S1(处理周期1结束).由于输入字符已处理完毕,系统从缓存区再读取2个字符,并根据其中第1个字符和σbasic激活S2.由于S2是Sub-NFA1的最终状态,所以根据S2与σlink激活S3(Sub-NFA2的第1个状态).同时,由于仅处理了当前输入的1个字符,所以L置为1.根据更新函数,系统将输入“np”替换为“pp”,并依照当前状态S3和σbasic激活状态S3(处理周期2结束).系统按照上述逻辑继续匹配,直到最终状态S6被激活,并报告匹配成功.
3.2 Link-NFA构造方法
图4为构造Link-NFA的流程图,其中包含如下4个步骤:
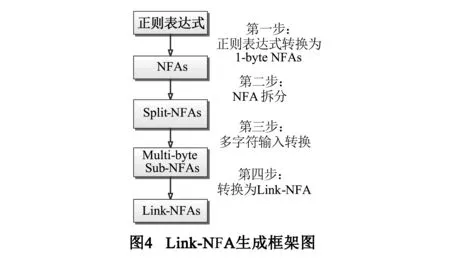
(1)根据经典算法将正则表达式转换为NFA[19];
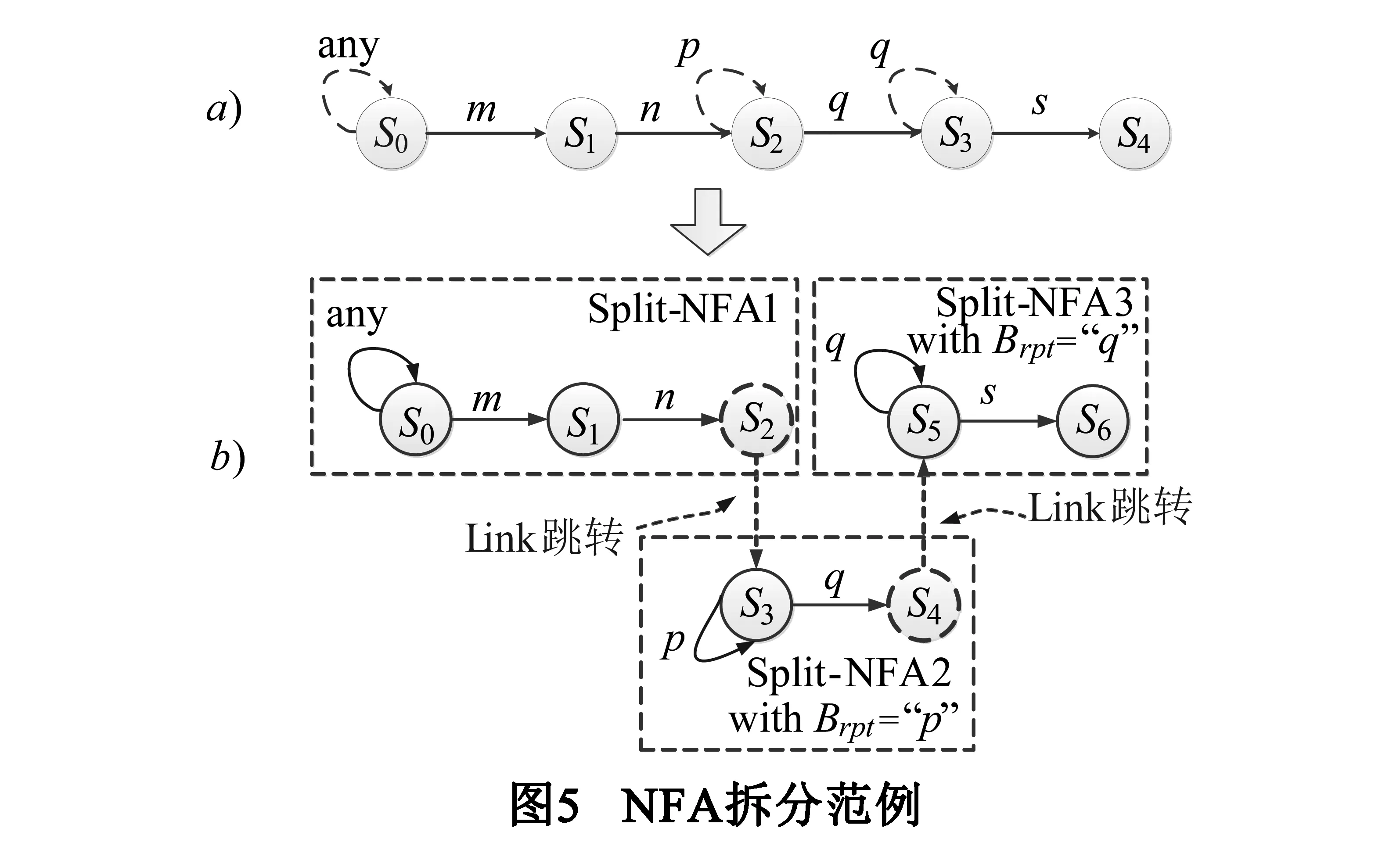
(2)将NFA拆分为Split-NFA,每个Split-NFA仅包含1个重复跳转,且彼此通过Link跳转相连.需要注意的是,为了保证逻辑完整,接连的Split-NFA有1个状态重叠.图5为Split-NFA的范例,子图a,b分别为拆分前、后对应的状态机,虚线为连接子状态机的Link跳转;
(3)将Split-NFA转换为k字符输入状态机[18],且转换时不考虑Link跳转;
(4)标记每个跳转可以处理的字符数量,从而完成Link-NFA构造.
3.3 优化Link-NFA
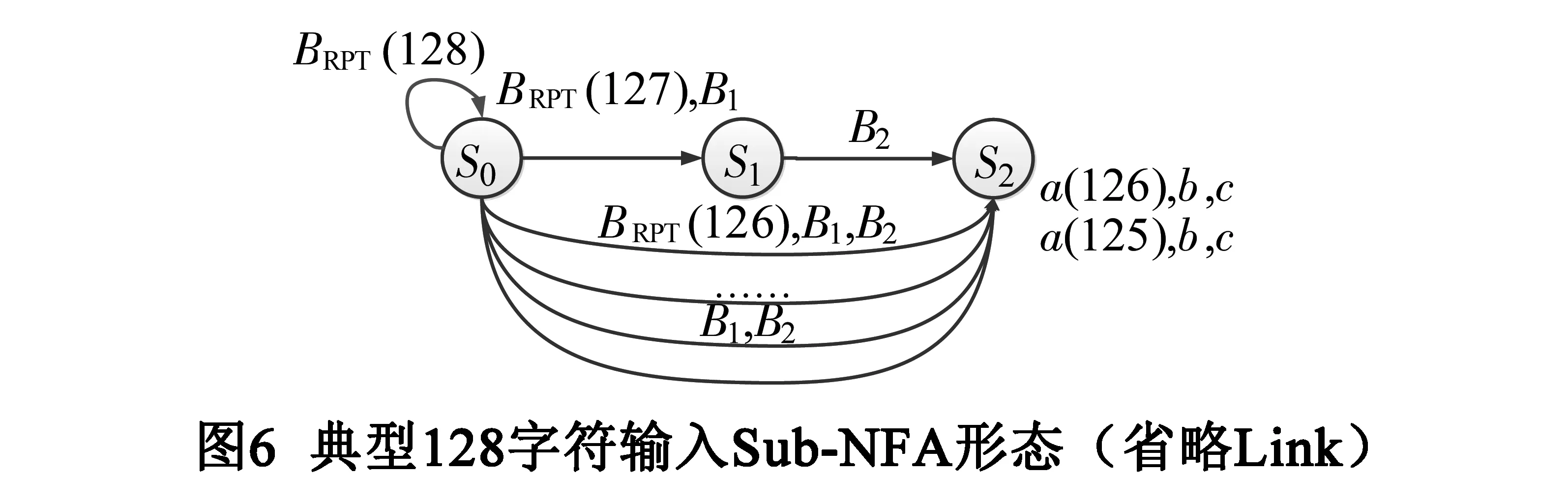
在Link-NFA模型中,Sub-NFA相对规整,其典型模式如图6所示.从硬件成本来看,实现图6所示Sub-NFA共需实现130个跳转,每个跳转匹配数量不同的字符,其消耗硬件逻辑资源量也不同.为了便于量化,我们用所需匹配字符的数量作为衡量硬件资源消耗的指标.图6所示Sub-NFA共需要匹配8512个字符的硬件资源,其中每周期输入的128个字符分别与不同数量的BRPT比较占了其中很大一部分.
考虑某时刻输入,如图7所示,其由三个部分组成:已处理,软匹配和硬匹配.已处理部分长度由L标识(已知);软处理由不同数量的BRPT组成;硬处理输入部分实质决定下一活跃状态.为了降低成本,作者使用基于Bitmap的方法快速跳过软处理部分,直接从硬处理部分进行匹配,从而降低实现状态机的硬件成本.

具体来说,优化算法先针对当前k字符输入和BRPT生成k-bit Bitmap:如果输入的第i个字符是BRPT,则Bitmap的第i个位为1,否则为0.然后,通过查找Bitmap中第L位以后的第1个0bit即找到硬匹配的起始位置.优化后算法的匹配成本主要由三部分组成:生成Bitmap、找到其中第1个0bit以及比对硬匹配部分的字符.进行优化后,实现图6所示状态机共需要匹配1162字符(三部分各匹配128,1032及2字符).同未优化相比,降低硬件资源消耗约86.3%.
需要注意的是,优化方法仅适用于软处理与硬处理部分划分清晰的情况,即BRPT不包含硬处理部分的首字符(图7中B1).否则该优化方法不适用.例如,BRPT为‘any’(即匹配任意字符)且当前输入中有多个满足Sub-NFA逻辑的子串,则可能在该Sub-NFA产生多个中间匹配结果,每一个结果对应一个不同的L.这一问题将在后续章节分析解决.
3.4 Link-NFA匹配架构
在Link-NFA中,每个Sub-NFA仅负责识别正则表达式的一部分.为了达到匹配的高性能,本文提出一个基于流水线的匹配架构,如图8所示.其中各条流水线用于处理起始位置在不同阶段的匹配进程.如果某周期处理完输入字符后激活了Stage-2中的状态,则被激活状态应当“下移”至流水线Line 2等待下一处理周期继续匹配.
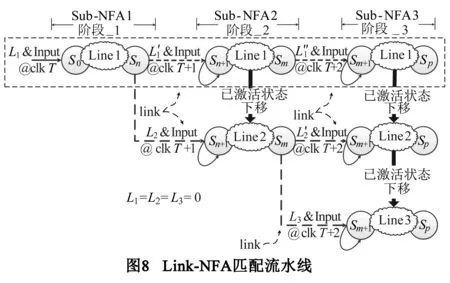
此外,考虑到BRPT为‘any’(即匹配任意字符)且当前输入中有多个满足Sub-NFA逻辑的子串的情况,其可能产生多个匹配结果.由于流水线各阶段单周期只能处理一个输入,Link-NFA匹配架构应当在该Sub-NFA与后续Sub-NFA之间连接队列以存储中间结果.针对同批次k字符输入,中间结果具有不同的L.Sub-NFA是否可能产生多个匹配结果由其对应的正则表达式逻辑决定.使用队列带来的额外资源消耗将在下一节详细进行评估.
4 评估
评估从理论分析和实际测量两个角度进行.首先,将L7-filter的协议规则集转换为每周期处理字符数量不同的Link-NFA,对状态机跳转数量及其增长趋势进行统计,并与多字符状态机进行对比,从理论上对Link-NFA状态机的规模与计算复杂度进行分析.然后,实现了基于Link-NFA的硬件原型系统,并针对原型的实现成本、检测效率进行测量与分析.其中主要考察原型系统的硬件资源成本、可扩展性、处理能力、延迟等关键参数.
为了达到上述目的,作者首先基于Linux系统和Python语言搭建了Link-NFA编译系统,其可以将正则表达式转换为基于硬件描述语言的Link-NFA状态机;然后使用Xilinx Design Suite 13软件和Virtex6 xc6vlx550t可编程芯片平台实现了基于Link-NFA的硬件原型.为了获取原型系统的关键性能(如处理延迟等),作者采用基于NetFPGA的数据流产生器[21]发送、标记数据包,并通过对比标记获得相关参数.
4.1 跳转数量
状态机跳转数量直接决定其匹配算法的计算复杂度.图9描述了Link-NFA与多字符输入状态机跳转数量膨胀度与每周期处理字符数量的关系.
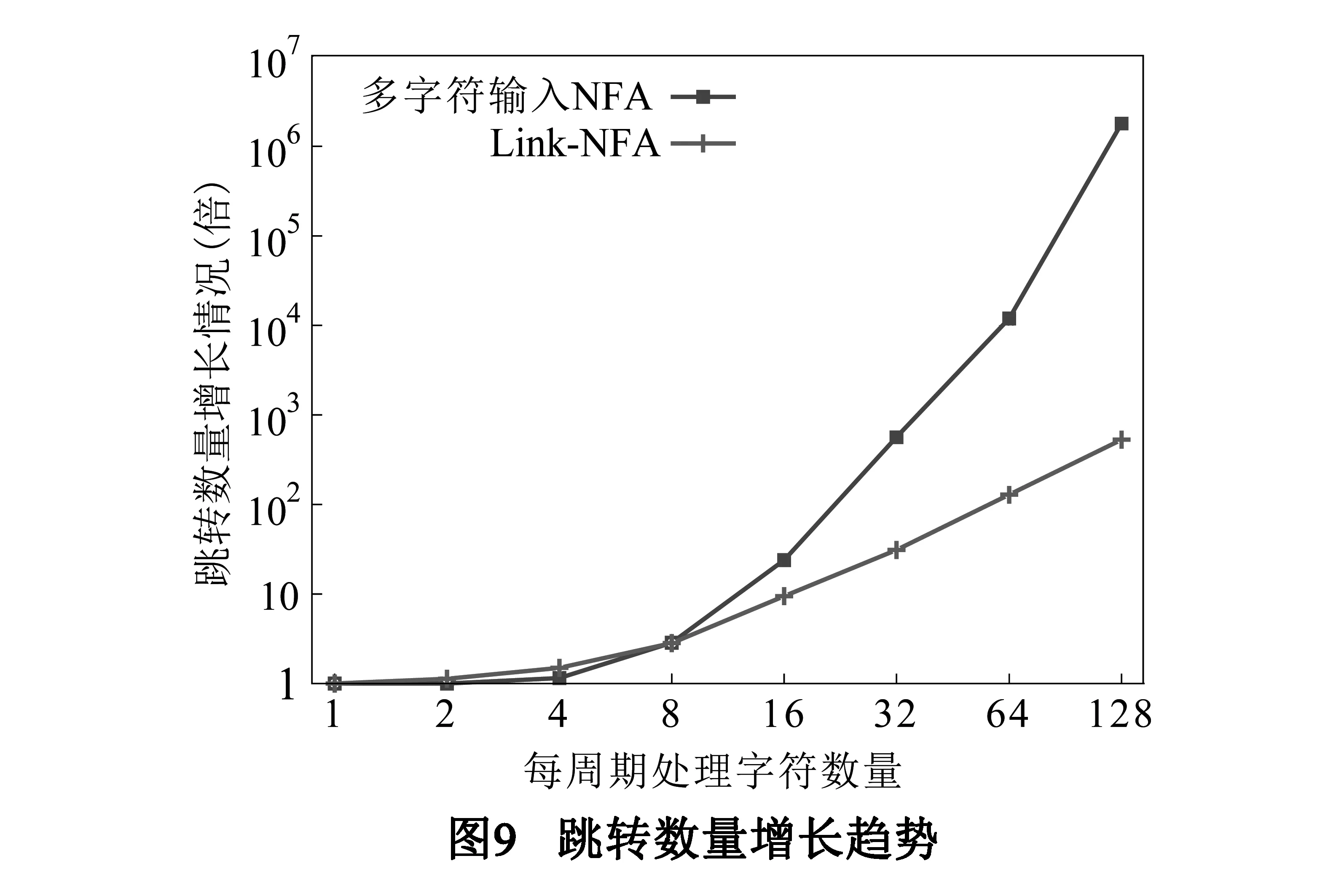
从具体数字来看,每周期处理32字符时,Link-NFA状态机跳转数量增长近32倍,其膨胀率比多字符输入状态机低了1个数量级;每周期处理128字符时,状态机跳转数量增长100多倍,其膨胀率比多字符状态机低了3-4个数量级.
从增长趋势来看,多字符输入状态机跳转数量与其每周期处理字符数量近似指数关系;Link-NFA中跳转数量与其每周期处理字符近似线性关系.这一结果符合Link-NFA的设计预期,即通过多个子状态机对重复元字符进行隔离,避免多个重复元字符在多字符输入状态机转换时互相影响,从而降低状态机规模膨胀.由上述结果和分析可知,同多字符输入状态机相比,Link-NFA可以有效降低状态机膨胀规模,更适应输入字符数量较多的情况.
4.2 FPGA资源使用率
为了验证Link-NFA的可用性,作者实现了输入字符宽度不同的Link-NFA匹配引擎,并对其资源消耗情况进行统计,结果如图10所示.总的来看,硬件原型系统消耗的查找表资源与输入字符数量近似线性关系.每周期处理128个字符时,FPGA芯片的查找表资源使用率约为15%.实验结果与跳转数量增长趋势一致:跳转数量越多,计算复杂度就越高,查找表使用率随之增加.实验过程中芯片触发器资源使用率始终在10%左右,其与状态机的状态数目相关且不随Link-NFA输入字符数量增加而显著变化.
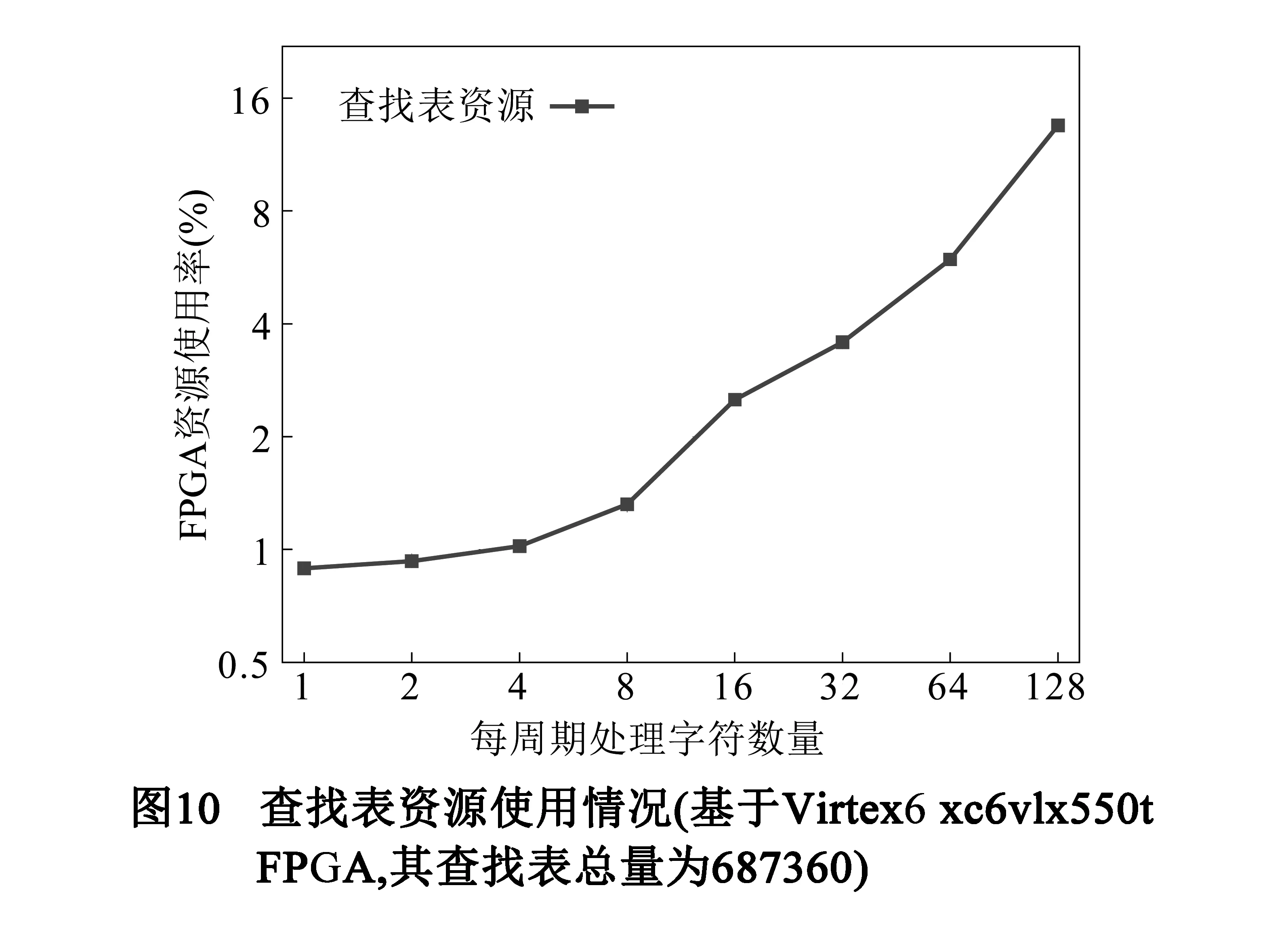
针对Sub-NFA可能产生多个匹配结果的情况,作者使用基于片上存储器的队列对中间数据进行缓存.在原型系统中共使用了约45个18Kbits片上存储器模块,占总数的7.1%,远小于实现复杂计算的查找表使用率.此外,片上存储器的使用率与协议规则本身有关,不受输入字符数量的影响.
从协议实现数量来看,本文使用的Xilinx Virtex6 xc6vlx550t芯片最多可以支持约850条应用层协议的识别.如果使用硬件资源更多的Virtex7系列FPGA,则协议支持数量最高能达到约4000.考虑到常用协议数量,Link-NFA完全可以支持对当前主流网络应用的识别.
由上述分析可知,现有芯片技术完全可以支撑每周期输入128字符的Link-NFA匹配引擎.大跨度(每周期处理字符较多)Link-NFA具有可实现性.
4.3 吞吐率
系统吞吐率是正则表达式匹配引擎的重要参数,其直接关系到网络检测设备的在线处理能力.具体来说,基于FPGA的协议识别系统吞吐率T由以下公式决定:
T=Freq×N×8
其中Freq为匹配引擎的实际工作频率,N为每周期处理的字符数量,8为字符转换为比特的常量.因此,基于Link-NFA的匹配方法是否能够达到高吞吐率还取决于系统工作频率.
图11为每周期处理不同字符数量的情况下,原型系统能够达到的最低工作频率与吞吐率.从趋势上看,系统工作频率随着每周期处理字符数量增加而降低.这主要是因为Link-NFA跳转数量增加导致计算复杂度增长,进而导致芯片布局布线复杂度增大.然而,由吞吐率来看,频率降低的负面影响远小于增加每周期字符处理数量带来的性能提升,原型系统吞吐率单调递增并在每周期处理128字符时达到性能最大值.此时系统工作频率约为113MHz,吞吐率约为115Gbps,达到设计初衷.
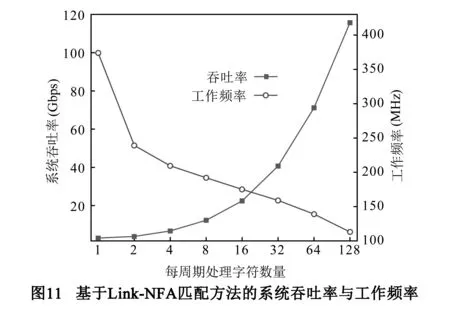
表4对L7-filter软件方法、本文提出的硬件加速方法以及其他平台有代表性算法的性能进行对比.由数据可知,本文提出的方法处理能力是L7-filter软件方法的100多倍;同已有基于FPGA平台的Lookahead方法相比,性能提高了约3.38倍.因此,本文提出的方法具有先进性,且其可以满足当前产业界对应用层协议识别方法的性能需求.

表4 性能比较
4.4 处理延迟
处理延迟指系统处理1个数据包所需的平均时间.处理延迟的大小直接关系到该类型应用层识别系统是否适合在线部署.我们对原型系统的处理延迟进行测量,并与L7-filter的软件方法进行比较,结果如表5所示.在整个测量过程中,Link-NFA 始终保持较低延迟,其平均值为0.41us,相对L7-filter软件方法的加速比约为587.4.上述结果主要由以下两个原因.首先,FPGA芯片可以直接读取网口数据,避免了由数据总线、网卡接口、驱动等带来的延迟.其次,Link-NFA最高可以工作在113MHz,其最多15周期处理1个数据包(受重复元字符数量影响),相对软件方法处理效率更高.
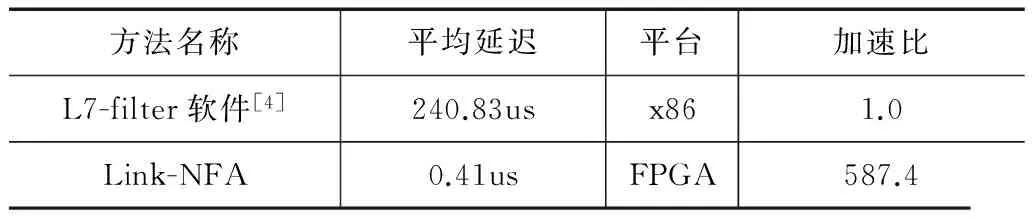
表5 处理延迟对比
5 结论与展望
本文提出了一个高效的硬件加速方法,其通过合理的数据结构、基于Bitmap优化方法和专用匹配架构以提高流量分类系统的处理能力.使用基于Virtex6 FPGA板卡对匹配方法进行验证的结果表明,本文所提出的方法可以提供约115Gbps吞吐率.在现有技术条件下同已有FPGA算法相比,本文提出的方法要快约3.38倍.
由网络安全领域发展趋势可知,传统角色单一的防火墙、入侵检测系统已经不适合当前日趋复杂的网络环境.具备应用层协议识别、防火墙、入侵检测、网络管理等多重角色的新型网络安全设备成为未来发展的重要趋势.例如,我国新一代网络防火墙标准就将应用层协议识别作为其核心功能之一.本文提出的加速方法立足于产业界未来5~10年需求,从研制子系统的角度出发,提出高性能应用层协议识别方法,适合嵌入复合型网络安全设备,顺应了未来复合型网络安全系统发展趋势,具有较高的产业价值与科研价值.
同基于软件、专用处理器等方法比,本文提出的方法具有吞吐率高、能耗低、空间小等特点,不仅适合骨干网、数据中心等应用场景,还适合物联网、车联网等应用场景.后续研究可以从理论与具体应用两方面深入进行.在理论方面,可针对Link-NFA本身的问题进行深入优化,探索Sub-NFA可能产生多个匹配结果、如何进一步降低匹配引擎硬件资源消耗、将字符输入数目进一步扩展到整个数据包等问题,进一步提高Link-NFA与硬件加速器的效率.在实际应用方面,考虑研制专用协议识别芯片,将所提出的L7-filter加速方法嵌入到实际设备中,并根据测量与应用结果对其进行改进.
[1]GA/T1177-2014,信息安全技术 第二代防火墙安全技术要求[S].
[2]J.Nielsen.Nielsen’s law of internet bandwidth[EB/OL].http://www.nngroup.com/articles/law-of-bandwidth/,2015-3-12.
[3]Application layer packet classifier for Linux[EB/OL].http://l7-filter.sourceforge.net/,2005-02-18.
[4]付文亮,嵩天,周舟.RocketTC 一个基于FPGA的高性能网络流量分类架[J].计算机学报,2014,37(2):414-422.FU Wen-liang,SONG Tian,ZHOU Zhou.RocketTC:A high throughput traffic classification architecture on FPGA[J].Chinese Journal of Computers,2014,37(2):414-422.(in Chinese)
[5]Antonello Rafael,et al.Design and optimizations for efficient regular expression matching in DPI systems[J].Proceedings of Computer Communications,2015,61:103-120.
[6]Wang Kai,Zhe Fu,Xiaohe Hu,and Jun Li.Practical regular expression matching free of scalability and performance barriers [J].Proceedings of Computer Communications 2014:97-119.
[7]Wang Jianhua,et al.A regular expression matching algorithm based on high-efficient finite automaton[J].Proceedings of Journal of Computing Science and Engineering,2014:78-86.
[8]WANG X,et al.StriFA:Stride finite automata for high-speed regular expression matching in network intrusion detection systems[J].IEEE Systems Journal,2013,7(3):374-384.
[9]Liu Tingwen,et al.Towards fast and optimal grouping of regular expressions via DFA size estimation[J].IEEE Journal on Selected Areas in Communications,2014,32(10):1797-1809.
[10]Shukla Surendra Kumar,et al.A survey of approaches used in parallel architectures and multi-core processors[J].For Performance Improvement.Proceedings of Progress in Systems Engineering,2015:537-545.
[11]Vasiliadis Giorgos,et al.GASPP:a GPU-accelerated stateful packet processing framework[A].Proceedings of 2014 USENIX Conference on Annual Technical Conference[C].Philadelphia:USENIX,2014.321-332.
[12]FEITOZA SANTOS A,et al.Multigigabit traffic identification on GPU [A].Proceedings of the First Edition Workshop on High Performance and Programmable Networking[C].New York:ACM,2013.39-44.
[13]Van Lunteren J,et al.Hardware-accelerated regular expression matching at multiple tens of gb/s[A].Proceedings of 31th IEEE INFOCOM[C].New York:ACM,2013.1737-1745.
[14]Smith R,et al.XFA:faster signature matching with extended automata[A].Proceedings of IEEE Symposium on Security and Privacy (S & P)[C].New York:IEEE,2008.187-201.
[15]Becchi M and Cadami S.Memory-efficient regular expression search using state merging[A].Proceedings of IEEE INFOCOM[C].New York:ACM,2007.1064-1072.
[16]Bando M,et al.Scalable lookahead regular expression detection system for deep packet inspection[J].IEEE/ACM Trans on Networking,2012,20(3):699-714.
[17]余慧,王健.一种专用可重配置的FPGA嵌入式存储器模块的设计和实现[J].电子学报,2012,40 (2):215-222.
YU Hui,WANG Jian.The design and implement of a special reconfigureable FPGA embedded BRAM[J].Acta Electronica Sinica,2012,40(2):215-222.(in Chinese)
[18]Yamagaki N,Sidhu R,Kamiya S.High-speed regular expression matching engine using multi-character NFA[A].Proceedings of IEEE Field Programmable Logic and Applications[C].New York:ACM,2008.131-136.
[19]HOPCROFT J E.Introduction to Automata Theory,Languages,and Computation[M].3rd ed,Addison-Wesley Longman Publishing Co,Inc,2006.
[20]Regular expression patterns for L7-filter[EB/OL].http://l7-filter.sourceforge.net/protocols,2015-03-12.
[21]NetFPGA [OL].http://netfpga.org.2015-07-20.
[22]Wang L,et al.Gregex:GPU based high speed regular expression matching engine[A].Proceedings of IEEE Innovative Mobile and Internet Services in Ubiquitous Computing [C].New York:IEEE,2011.366-370.

付文亮 男,1984年出生于河北邯郸市.现为北京理工大学计算机学院在读博士生.主要从事高性能网络、网络安全、节能等领域关键技术研究.

郭 平(通信作者) 男,1957年出生,现为北京理工大学计算机学院教授,博士生导师.主要从事智能计算及其应用研究.
E-mail:pguo@bit.edu.cn
周 舟 男,1983年出生,现为中国科学院信息工程研究所高级工程师.主要从事高性能网络及网络安全相关领域研究.
A Hardware-Accelerated L7-filter Method for 100Gbps Networks
FU Wen-liang1,GUO Ping1,ZHOU Zhou2
(1.SchoolofComputerScienceandTechnology,BeijingInstituteofTechnology,Beijing100081,China; 2.NationalEngineeringLaboratoryforInformationSecurityTechnologies,InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093,China)
L7-filter is a widely used traffic classification system which relies on regular expression matching based deep packet inspect method and can identify network traffic by inspecting string patterns hidden in the packet payload.However,due to considerable computation and storage expenditures,existing L7-filter software and hardware solutions could not offer sufficient performance in the context of 40 Gbps and higher speed networks.Based on analysis of common features of the L7-filter protocol patterns,this paper proposes a hardware-accelerated method which is for achieving high performance and includes customized data structure,optimization and matching architecture.To validate the proposed method,a hardware prototype on Virtex 6 FPGA card is implemented and tested.Experimental results show that the prototype can scan network traffic at a typical rate of about 115Gbps.
traffic classification;regular expression matching;100Gbps;FPGA
2015-04-07;
2015-08-17;责任编辑:蓝红杰
国家自然科学基金(No.61402474)
TP393
A
0372-2112 (2016)11-2561-08
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.11.001
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
北京航空航天大学学报(2019年9期)2019-10-26 02:30:04
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
火控雷达技术(2016年3期)2016-02-06 02:30:28
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
黑龙江科学(2011年2期)2011-03-14 00:39:36
