
Logistic回归模型的经验似然统计方法及其应用
2016-12-08 06:39郎英,解婷婷,曹赛男
中国科技信息 2016年20期
Logistic回归模型的经验似然统计方法及其应用
信用风险又称为违约风险,是商业银行面临的最主要风险.要想避免其发生,首先需要解决的就是如何度量及预测风险.由于Logistic模型在数据采集、变量选择和模型构建方面比较符合我国的实际情况,且具有可靠的识别和预测能力。故采用该模型来构建针对我国上市公司的信用风险预警模型.在对Logistic模型的参数进行估计时,采用经验似然估计法。
基于经验似然的参数估计
经验似然的估计方法
经验似然方法最早由 Owen提出,其本质是在约束条件下,求非参数似然比的极大值,而总体参数由约束条件带入极大似然比中.假设Xi(i=1,2…n)是独立同分布的样本,F为分布函数,θ为p维待估参数向量.由于F分布未知,用非参数似然来对θ进行讨论,定义如下非参数似然函数:

把E( g( x,θ))=0作为约束条件,从而定义了似然函数:
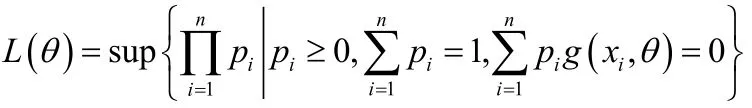
即是Qin & Lawless于1994定义的半参数模型中,参数θ的经验似然函数。由拉格朗日乘子法,可以将问题转化为最大化其约束条件为:
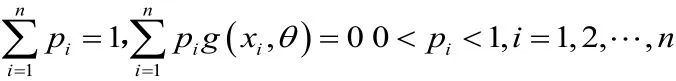
则拉格朗日函数可表示为:
则θ的对数经验似然函数可表示为:
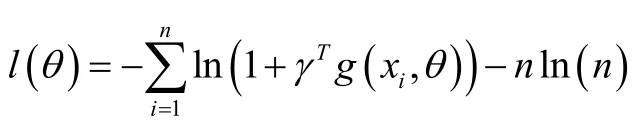
Logistic模型的经验似然估计
对于Logistic模型,
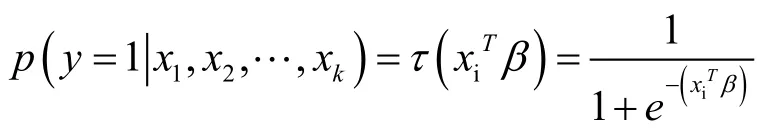
参数β的对数似然函为:
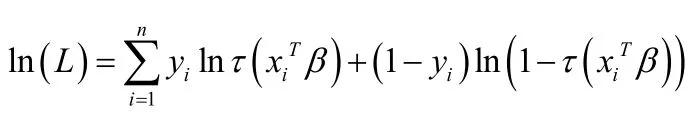
关于参数β求导,化简可得到估计方程为:
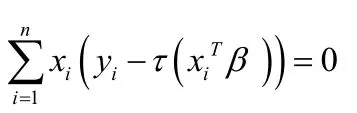
则参数β的对数经验似然函数为:
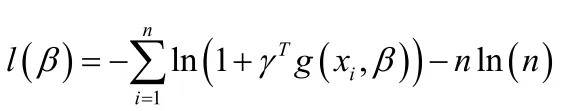
把γ, β看成两个独立变量,定义
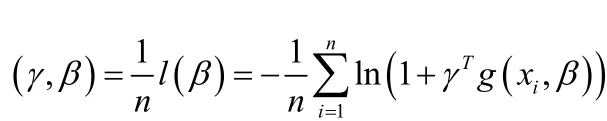
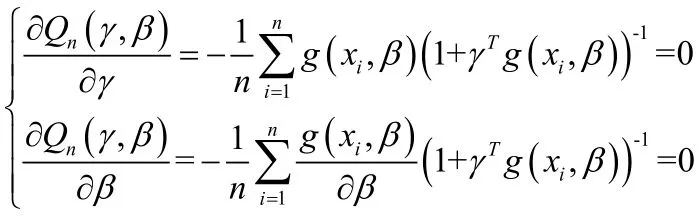
实证分析
数据与指标选取
本文以沪深A股2015年18家ST公司作为风险样本,遵循相应原则选择不存在风险的54家非ST公司为配对样本.Y表示t年的状态,X表示财务指标比率,使用样本t-2年的财务数据构建信用风险预警模型.在前人基础上选择了常用的18个指标:净资产收益率、总资产收益率、主营业务利润率、每股净资产、每股收益、固定资产与股东权益比率、应收账款周转率、固定资产周转率、总资产周转率、净资产周转率、资产负债率、流动比率、速度比率、产权比率、主营业务增长率、固定资产投资扩张率、总资产扩张率、净资产增长率。
因子分析
选取的财务指标间具有很高的相关性,为了克服变量间的多重共线性,采用因子分析法对指标进行简化.运用SPSS对数据进行标准化处理,再对变量进行KMO和Bartlett球形检验,其KMO值为0.696,Bartlett检验对应的显著性概率为0.000,说明原变量适合做因子分析.由因子分析的总方差解释表可知,变量相关矩阵的前 5个因子的特征值大于 1,它们解释了总方差的 86.11%。最终选出5个因子。通过因子旋转方法得到成分得分系数矩阵,如下表所示。
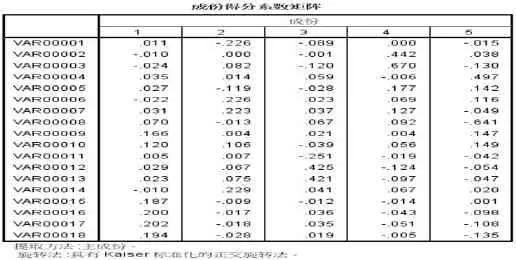
从旋转成分矩阵中可看到,主营增长率、固定扩张增长率在第一个因子的载荷较高,反应了企业的成长能力;固定资产与股东权益比率和每股资产收益在第二个因子上载荷较大,反应了股东获利能力;流动比率和速度比率在第三个因子上载荷较高,反应了偿债能力;总资产收益率和主营业务利润率在第四个因子上载荷较高,反应了盈利能力;固定资产周转率在第五个因子上载荷较高,反应了运营能力。因此,由上表可得到各主成分因子的表达式f1、f2、f3、f4、f5。
Logistic模型参数估计及有效性验证
利用R语言求出logistic模型的极大经验参数估计值为β0=-0.38,β1=0.78,β2=0.69,β3=-0.64,β4=-2.45,β5=0.2,则logistic模型可表示为
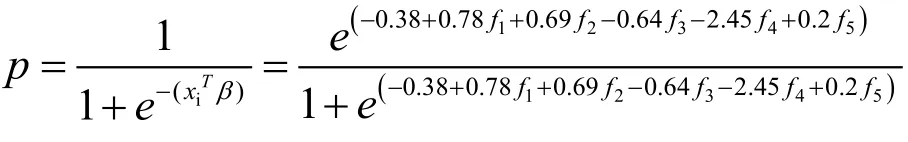
对模型进行验证,把24家测试样本t-2年的数据带入到模型中,并以0.5为最佳判别点,得到判定结果如下:
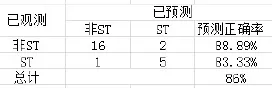
由表可以看出,在检验样本中有 3 家公司被误判,其正确率为 86%.所以文中所构建的 logistic 回归模型的效果还是比较理想的。
结语
将Logistic 回归模型的经验似然方法应用到数据的分类问题中,通过样本筛选、模型创建及模型检验等步骤,建立了基于logistic回归的风险评估模型.将该方法应用到实例中,其预测正确率达到了86%,是一个较为成功的模型.但本文也有很多不足,文中得到的结果都是在参数个数小于样本容量下产生的,关于参数发散情况下Logistic模型的经验似然方法的统计推断和分类问题还有待进一步研究。
10.3969/j.issn.1001- 8972.2016.20.010
猜你喜欢
水上消防(2022年2期)2022-07-22
数学物理学报(2022年1期)2022-03-16
环渤海经济瞭望(2021年10期)2021-03-13
消费导刊(2018年8期)2018-05-25
中国管理信息化(2017年2期)2017-02-17
北京航空航天大学学报(2016年9期)2016-11-16
财税月刊(2016年4期)2016-07-04
中国惯性技术学报(2015年1期)2015-12-19
噪声与振动控制(2015年4期)2015-01-01
火炸药学报(2014年3期)2014-03-20
