
微博个性化转发行为预测新算法
2016-12-06 07:58权义宁宋建锋苗启广
西安电子科技大学学报 2016年4期
唐 兴,权义宁,宋建锋,邓 凯,朱 海,苗启广
(1.西安电子科技大学计算机学院,陕西西安 710071; 2.周口师范学院计算机科学与技术学院,河南周口 466001)
微博个性化转发行为预测新算法
唐 兴1,权义宁1,宋建锋1,邓 凯1,朱 海2,苗启广1
(1.西安电子科技大学计算机学院,陕西西安 710071; 2.周口师范学院计算机科学与技术学院,河南周口 466001)
目前,对微博转发行为预测主要是对所有微博用户的历史数据进行学习,从而得到转发模型.但是这类模型需要对所有用户的转发行为进行全局预测,存在同质性且无法对具体用户进行个性化预测的缺陷.针对这些问题,提出了基于多任务学习的个性化微博转发行为预测算法.对新浪微博进行了数据抓取、分析和特征选择,根据社会学中影响力的理论,针对微博用户之间进行社交信息交流而导致相互影响的特点,引入了多任务学习方法,以逻辑回归预测模型作为基准算法,将预测模型分为全局模型与个性模型进行学习.预测模型把对每个用户转发行为的预测对应为多个任务,根据微博用户间的社交交互对这些任务进行关联.实验结果表明,所提出的模型能够有效地对单个用户的微博转发行为进行预测,并且提高了转发行为预测的准确率.
多任务学习;个性化;转发行为;社交网络;微博;数据挖掘
近年来,线上社交网络的迅猛发展吸引了研究者的注意.微博是一个基于关注关系的信息共享、传播的线上社交网络平台.在微博中,用户通过发布微博分享他们感兴趣的信息与状态,该用户的关注者对该用户的某条微博进行转发,这就使得该条微博在社交网络中进行了一跳传播.经典的信息模型包括线性阈值模型与独立级联模型[1].这两种模型都需要假定信息在用户之间的传播概率,通常将传播概率设为某个固定的值或者假定服从某个已知的概率分布.这样就造成了信息在网络中传播的同质性现象,无法对个体进行差异性分析.转发行为是组成信息传播的原子行为,因此,对转发行为的研究成为信息传播的一个基本问题.
通常将预测用户对某条微博转发行为定义为一个二分类问题[2-5].根据对微博数据的分析,将具体某条微博量化为特征向量T.然后对每条微博根据转发情况进行标记,存在转发历史则标记为1,没有被转发则标记为0.根据得到的特征向量与标记,文献[2]通过人工实验的方法,证明了分类算法在对微博转发行为预测问题上的可行性,并进一步改进了他们的Passive-Aggressive算法.文献[3]提出了特征加权模型,通过对Twitter中转发行为预测准确性的研究,对每组特征加以区分.同样,文献[4]通过不同模型来对Twitter中的转发行为进行预测来分析特征的重要性.这些研究都是利用在用户微博数据上建立学习模型,给出了相应的机器学习算法来处理用户微博转发预测问题.
另一方面,由于局部用户数据存在稀疏性的特点,预测模型通常是基于所有用户的微博数据学习相关模型,对转发行为进行预测.这样的全局模型无法对一些具体用户行为进行预测.另外,由于用户的预测模型都是基于同一参数模型,因此具有同质性.为解决这个问题,引入了多任务学习框架[6-10].多任务学习是一种迁移学习方法,通过对多个相关任务进行同时学习来改善学习性能,多个任务之间由于存在一定的关系,任务之间的学习过程会起到相互牵制的作用.在某些任务样本少的情况下,能够利用任务之间的关系改善学习效果.文献[9]利用多任务学习框架对社交网络中用户活跃性进行了个性化预测.文献[10]则引入多任务学习框架对内容信息网络中信息传播行为进行了预测.
针对影响用户转发行为的特征选取问题,文献[11]对Twitter中影响转发行为的相关因素进行了分析与讨论,利用统计学的方法,对某些关键因素进行了显著性分析,但是受到不同数据集中的数据特征不一致的影响,无法适用于其他数据集.
为解决特征选择问题,笔者对抓取的微博数据[12]使用统计分析的方法对特征的区分性进行了分析,给出了微博转发预测中选取特征的一般性思路.基于选取的特征,利用社交影响的作用将个体用户的转发预测作为相互关联的单个任务进行学习,最后,得到基于多任务学习的转发预测算法.
1 基于多任务学习的个性化转发行为预测算法
1.1问题描述
首先,形式化定义微博中的行为历史.
定义 已知微博有向关系网络G={V,E},其中,V为用户集合,E为用户之间的有向关注关系集合.如果用户vi(vi∈V)关注用户vj(vj∈V),则存在有向边:vi→vj,其中,vi能够收到用户vj的所有原创与转发微博.对于用户vj的一条微博m,定义用户vi的行为历史:Ai={vi,vj,m}i,j.
文中对每个用户抓取得到数据,根据定义,把同该用户的相关的历史转发微博建立转发列表.为了对转发行为进行预测,将该问题建模为二分类问题.
问题 对每条历史微博{vi,vj,m}抽取相关的特征T=〈t1,t2,…,tn〉,同时将该条数据标记为yi,j,m.若yi,j,m=1,则表示vi转发了vj的微博m;否则,表示vi没有转发vj的微博m.基于标记得到的历史数据{T, yi,j,m},如何给出每个用户对应的预测模型{wi}?
1.2预测模型
逻辑回归模型是通过在输入特征上建立线性函数,是一种较为常用的二分类算法.首先,逻辑回归模型优化算法复杂度较为简单,是线性回归的一种.对于较大规模的数据,这种复杂度是可以接受的;其次,逻辑回归模型具有一定的可解释性.训练得到的模型能够通过得到的权值来为每个特征在数据中所起的重要程度提供一定程度的解释;最后,逻辑回归模型的分类结果是以概率的形式给出的.这样对于某个用户的某条微博,模型能够以概率大小的方式给出用户对该条微博的兴趣程度,这样能够为将用户接收到的微博进行重排序提供数值参考.因此,文中使用逻辑回归作为对个性化转发行为进行预测的基准算法.

进一步,可将分类算法等价于一个带正则项的优化目标函数,即
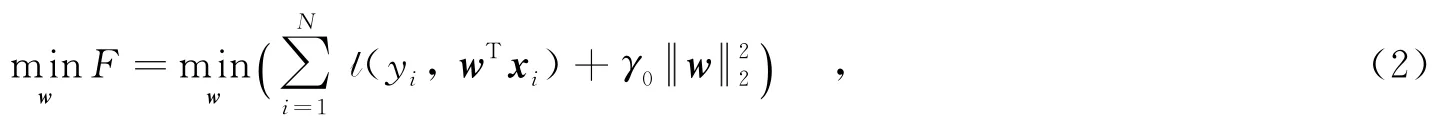
其中,γ0为正则化系数.
通常,相同的特征对不同的用户具有不一样的权重.当用户A和B同时关注了同一个用户C的微博,用户C发出某一条微博后,这两个用户对该微博的转发情况很可能存在不同,用户A可能会因为微博内容进行转发,而用户B可能会因为该微博转发人数过少而选择不转发.所以只考虑全局的转发历史得到的结果一般不够准确,无法对单个用户转发行为进行预测.因此,引入多任务学习方法,将用户的转发行为预测对应为一组相关联的模型.
多任务学习模式基于一个这样的事实:这些任务在某种程度上都是相关的.形式化定义如下:将个体的任务定义为wi,个体任务可以分解为wg和wi两部分,其中,wg是所有任务相互关联作用的公共参数,wi是对应于每个具体任务的部分的个性参数.在网络中,由于个体之间存在社交影响力作用[9],因此,可认为每个用户的微博转发行为存在相关性.
在基于多任务学习框架上,将每个用户的转发行为预测对应一个独立的任务.定义每一个任务需要学习的权值向量为Vi,这个任务的目标可以分为两部分:Vi=wg+wi,其中,wg为全局的特征权值向量,而wi对应于具体单个用户的局部权值特征向量.每个Vi通过wg相互关系,wg是根据所有的转发行为数据进行学习得到的,而wi是对单个用户的转发历史数据进行学习得到的向量.这样个性化的模型可归纳为
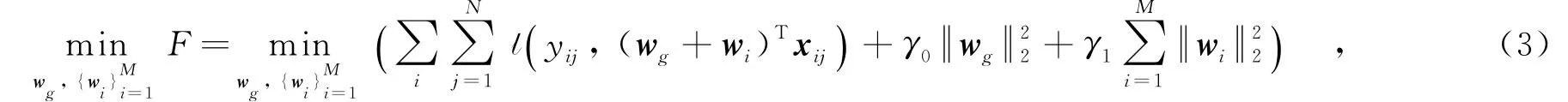
其中,M是用户的数量,xij是属于用户i的第j个数据样本点.通过设置正则化系数γ1的值,能够调节个性化对模型的影响.当减少γ1时,模型具有更好的个性化,但是可能会对单个用户的转发数据产生过拟合;当γ1增加时,wi在优化过程会趋于零,模型效果则等价于单任务模型.
1.3学习算法
目标函数式(3)为凸函数,因此,采用梯度下降算法进行优化.这里分别对wg和wi进行求偏导,得到
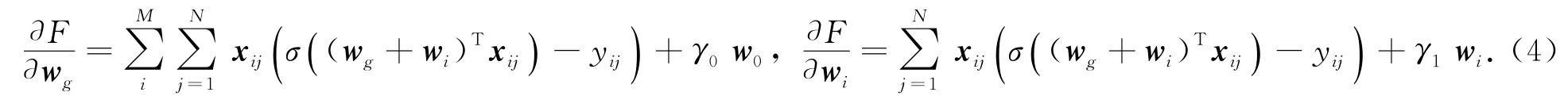
根据求得的偏导,分别迭代更新wg和wi,直到结果收敛.更新规则如下:
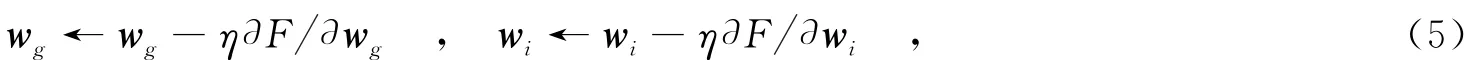
其中,η表示学习的速率.具体的迭代步骤如下面算法所示.算法的复杂度主要由两个循环构成:O(I·M),其中,通过设置合适的学习步长,设定收敛条件为参数不再显著变化,这样在较少迭代次数的情况下便能达到收敛,得到最优解.对每个用户可使用适当的并行算法进行同时训练,这样可进一步减少算法的复杂度.
算法 个性化转发行为预测算法.
输入:用户转发数据xij=〈T1,T2,…,Tn〉,正则化参数为γ0、γ1和β,学习速率为η,最大步长为I.
输出:全局参数wg和个性化参数{wi}.
初始化:随机设置wg和{wi}
1.for i=1 to I do:
3. for j=1 to M do:
4. 固定wg,更新
5. end for
6. if满足收敛条件:
7. break
8. end if
9.end for .
2 实验与分析
2.1数据描述
本实验的数据来自于新浪微博.由于存在垃圾粉丝、僵尸用户等情况,数据存在大量噪声,会影响最后的预测结果,因此,文中随机选取活跃的用户作为研究对象.在实验中,假设一个活跃用户必须满足以下条件:①关注数与粉丝数必须大于50;②观察周期内每个星期所发微博数必须大于10.根据这两个条件筛选出12 013个活跃用户.以这些用户为种子,抓取了对应的关注网络,该网络总共包含92 034个用户和1 272 871组关注数对应于网络的边.同时,设定观察周期为2013年7月1日到9月30日.网络中所有用户总共发表了9 913 495条微博.在这些微博集合中,分别有716 178条转发微博和9 197 317条原创微博.表1给出了抓取得到的数据集的主要特性,其中,微博总数由原创微博数与转发微博数共同构成.

表1 抓取得到的数据集性质
将数据集以2013年8月31日为分界点,分别构成训练集合与测试集合.另外,由表1可以看出,转发微博数与原创微博数非常不平衡(接近1∶12),因此,这里以1∶2的比例对转发微博与原创微博进行抽样,表2给出了最后实验中使用的数据集情况.
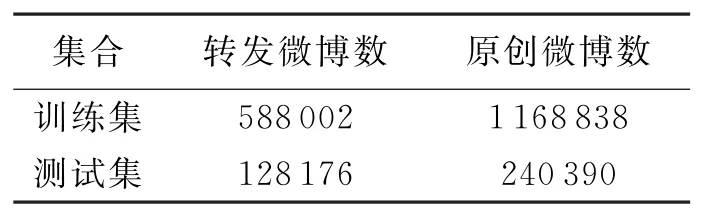
表2 使用数据集特性
2.2特征选择
对于监督学习,特征选取是影响最终分类性能的重要影响因素.由于受微博字段的限制,将微博数据中存在的可用特征分为:用户特征、结构特征与文本特征[11].用户特征描述了用户在微博上的行为特征,主要包括:用户是否加V,V代表用户身份是否被官方认证;用户发微博的数量,表示了用户的活跃程度.这里,用户的特征主要为:用户是否加V、用户的原创微博数、用户转发微博数、用户的工作经历、学习经历和用户的兴趣数.结构特征描述了用户在网络中的结构特性,包括关注数与粉丝数,用户在网络中的PageRank值[13].文本特征描述了用户所发微博的方式.文中使用Latent Dirichlet Allocation主题模型[14]对微博文本进行了主题分类.通过余弦相似度计算微博和用户兴趣之间的相似性.除此以外,还有微博文本的长度、微博中是否带统一资源定位符(Uniform Resource Locator,URL)、微博是否@某个用户、微博的转发数、微博的点赞数、微博的评论数、微博带的话题数和微博的发布时段.
2.3特征分析
为筛选能够区分转发数据与非转发数据的特征,采用统计方法来对数据进行分析.对于用户加V、微博中带URL等二值特征,通过统计分析,表明无法对类别进行区分.对于数值型特征,这里使用箱线图对每个类别上的数据统计特性进行表征,图1给出了特征选择中所有可用特征的箱线图.从图1可以看出,除了微博长度外,其他的特征都能够区分开转发与非转发的关系.因此,基于对箱线图的比较,抽取了表3所示的特征.

表3 选取特征总结
2.4评价指标
一般情况下,采用信息检索中的标准指标有准确率P、查全率R和F1值来评价预测结果.
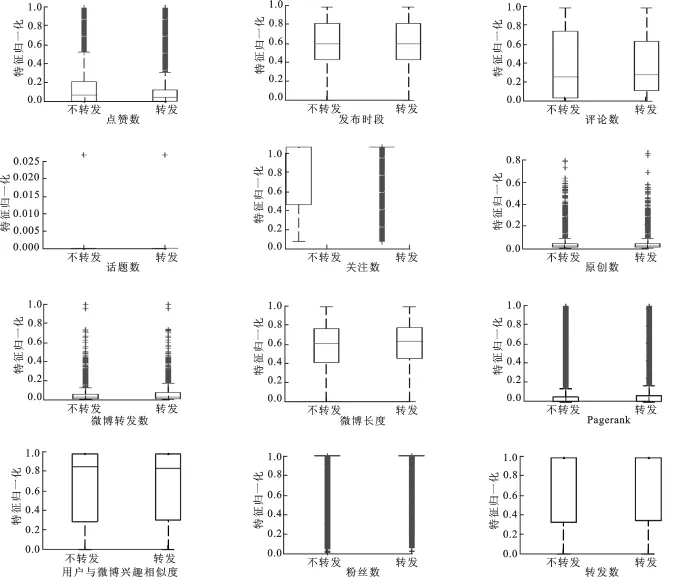
图1 特征箱线图
(1)准确率是被正确预测为转发的微博数占所有预测为被转发的微博数的比例.
(2)查全率是被正确预测的微博数占实际被转发全部微博数的比例.
(3)F1值则是综合评价准确率与查全率的指标,即F1=2PR(P+R).
2.5实验结果分析
为验证所提出模型的预测性能的提升情况,选取了被动攻击(Passive-Aggressive,PA)算法[2],逻辑回归以及支持向量机作为对照算法,在所抓取到的数据集上进行训练与验证.由于数据量较大,使用的分布式实验环境为1台主节点和8台子节点组成的Spark集群,其中,主节点和子节点机器均为4核Intel Xeon E7-8837,2.67 GHz,16 GB内存,Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)为2.5 TB.
表4给出了以召回率和准确率为指标总体的实验结果,其中,以个性化预测算法简称文中提出的算法.由实验结果可以看出,PA算法过于简单,召回率与准确率都比较低;而相对于作为基准算法的逻辑回归算法,文中提出的个性化预测算法能够在召回率和准确率两个性能指标上得到显著提升;支持向量机虽具有比较好的分类效果,但由于对照算法都是基于全局数据训练得到的模型,所以整体分类效果都没有文中算法的好.而文中算法引入个性化因子,提升了分类效果.由图2的F1值比较结果可以看出,文中算法能够得到较优的F1值.
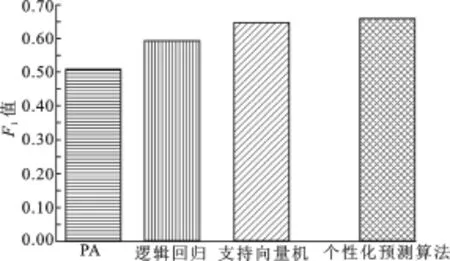
图2 F1值实验结果
为确定个性因素对模型的影响,用基准算法逻辑回归作为对照算法.为看出γ1的变化,这里设置γ1值分别为[0.01,0.10,1.00,10.00,100.00],实验结果如图3所示.可以看出,当γ1值过小时,会导致模型过拟合使得最终分类效果不佳;而当γ1过大时,会导致模型中的个性化部分失去作用,效果接近普通的逻辑回归,无法利用用户之间的关联性进行多任务学习.为验证提出的模型在转发历史数据不同情况下的分类情况,根据微博条数将用户分为1~10、10~100、100~500、500~1 000、1 000~2 000这5组,其中每组抽取1个用户,总共抽取20次.同时,用效果较好的支持向量机为代表,与文中提出的算法进行对照,结果如图4所示.

表4 实验结果
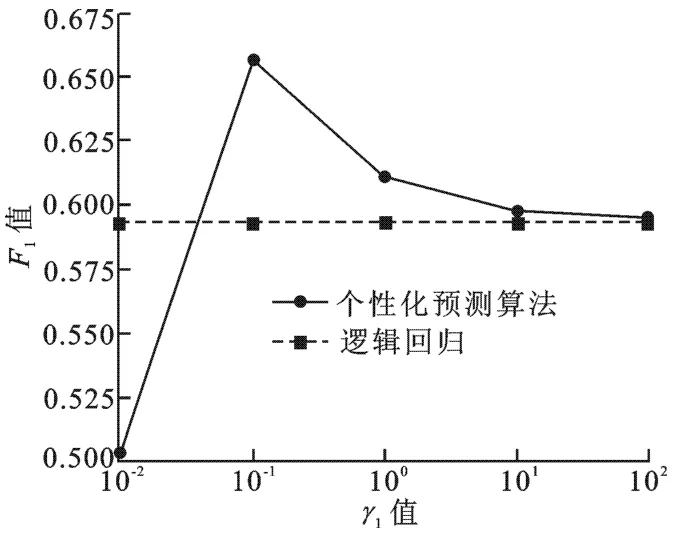
图3 γ1对模型的影响
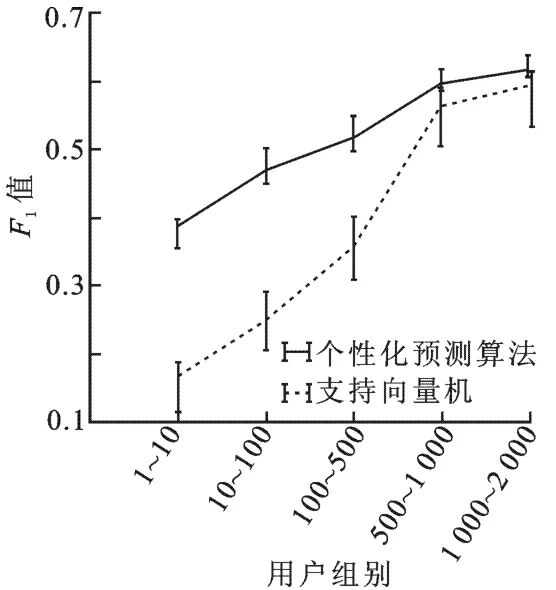
图4 用户集合上的模型对比
由图4可以看出,随着历史数据的增多,F1值会递增,支持向量机受数据规模的影响比较大.文中提出的模型在每个用户组上的F1值震荡要远小于支持向量机的,且在数据逐渐增多的情况下,个性预测模型的F1值震荡也在减少.这说明这些用户关注的人也是具有一定的活跃程度,通过用户之间的转发行为联系缓解了数据的稀疏程度,相比支持向量机能够得到更好的效果,这也说明了模型能够达到个性化的要求.
3 结束语
线上社交网络的信息传播是研究的热点问题.文中从数据特征抽取开始,对不同特征的区分性进行了统计分析.通过统计分析能够有效地为微博转发行为预测问题提供高区分性的特征.基于微博用户之间的社交接触,以逻辑回归作为基准算法引入多任务学习框架,每个用户的转发行为预测对应为多个任务,将微博用户间的社交交互用来将这些任务进行关联,解决了单个转发行为学习任务可能遇到的数据稀疏问题.用真实的微博数据测试实验的结果表明,同传统的分类算法相比,文中所提出的算法能够有效地对微博转发行为进行预测.下一步工作中,将进一步考虑微博转发时间对转发行为的影响,并对在线实时微博信息流进行预测处理.
[1]李栋,徐志明,李生,等.在线社会网络中信息扩散[J].计算机学报,2014,37(1):189-206. LI Dong,XU Zhiming,LI Sheng,et al.A Survey on Information Diffusion in Online Social Networks[J].Chinese Journal of Computers,2014,37(1):189-206.
[2]PETROVIC S,OSBORNE M,LAVRENKO V.RT to Win!Predicting Message Propagation in Twitter[C]// Proceedings of the 5th International Conference on Weblogs and Social Media.Barcelona:AAAI,2011:586-589.
[3]张旸,路荣,杨青.微博客中转发行为的预测研究[J].中文信息学报,2012,26(4):109-114,121. ZHANG Yang,LU Rong,YANG Qing.Predicting Retweeting in Microblogs[J].Journal of Chinese Information Processing,2012,26(4):109-114,121.
[4]XU Z H,YANG Qing.Analyzing User Retweet Behavior on Twitter[C]//Proceedings of the 2012 International Conference on Advances in Social Networks Analysis and Mining.Washington:IEEE Computer Society,2012:46-50.
[5]曹玖新,吴江林,石伟,等.新浪微博网信息传播分析与预测[J].计算机学报,2014,37(4):779-790. CAO Jiuxin,WU Jianglin,SHI Wei,et al.Sina Microblog Information Diffusion Analysis and Prediction[J].Chinese Journal of Computers,2014,37(4):779-790.
[6]ARGYRIOU A,EVGENIOU T,PONTIL M.Multi-task Feature Learning[C]//Advances in Neural Information Processing Systems 19.Vancouver:MIT Press,2007:41-48.
[7]EVGENIOU T,PONTIL M.Regularized Multi-task Learning[C]//Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2004:109-117.
[8]CARUANA R.Multitask Learning[J].Machine Learning,1997,28(1):41-75.
[9]ZHU Y,ZHONG E,PAN S J,et al.Predicting User Activity Level in Social Networks[C]//Proceedings of the 22nd ACM International Conference on Conference on Information and Knowledge Management.New York:ACM,2013: 159-168.
[10]FEI H,JIANG R,YANG Y,et al.Content Based Social Behavior Prediction:a Multi-task Learning Approach[C]// Proceedings of the 20th ACM International Conference on Information and Knowledge Management.New York:ACM, 2011:995-1000.
[11]LIU Z,LIU L,LI H.Determinants of Information Retweeting in Microblogging[J].Internet Research,2012,22(4): 443-466.
[12]陈庆丽,张志勇,向菲,等.面向多媒体社交网络的访问控制模型[J].西安电子科技大学学报,2014,41(6):181-187. CHEN Qingli,ZHANG Zhiyong,XIANG Fei,et al.Research on the Access Control Model for Multimedia Social Networks[J].Journal of Xidian University,2014,41(6):181-187.
[13]PAGE L,BRIN S,MOTWANI R,et al.The PageRank Citation Ranking:Bringing Order to the Web[R].Palo Alto: Stanford Info Lab,1999.
[14]BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].The Journal of Machine Learning Research,2003, 3(4/5):993-1022.
(编辑:齐淑娟)
Novel algorithm for predicting personalized retweet behavior
TANG Xing1,QUAN Yining1,SONG Jianfeng1,DENG Kai1, ZHU Hai2,MIAO Qiguang1
(1.School of Computer Science and Technology,Xidian Univ.,Xi’an 710071,China; 2.School of Computer Science and Technology,Zhoukou Normal Univ.,Zhoukou 466001,China)
Recently,models for predicting the user retweet behavior are based mainly on the historical retweet data of all users.However,these models are of homogeneity and could not predict a particular user’s behavior.To overcome these problems,we propose an algorithm for predicting personalized retweet behavior.Based on crawled Weibo data,we have conducted an analysis and a selection of retweet features. According to the influential theory,we introduce the multi-task learning framework to divide the tasks into common global tasks and many individual tasks.Our massive experiments show that our algorithm is effective in predicting personalized retweet behavior.
multi-task learning;personalization;retweet behavior;social networks;microblog; data mining
TP391
A
1001-2400(2016)04-0051-06
10.3969/j.issn.1001-2400.2016.04.010
2015-04-20 网络出版时间:2015-10-21
国家自然科学基金资助项目(61472302,61272280,U1404620,41271447);教育部新世纪优秀人才支持计划资助项目(NCET-12-0919);中央高校基本科研业务费专项资金资助项目(K5051203020,JB150313,JB150317,K5051303018,BDY081422);陕西省自然科学基金资助项目(2010JM8027);西安市科技局资助项目(CXY1441(1));地理信息工程国家重点实验室开放研究基金资助项目(SKLGIE2014-M-4-4);NSFC-广东联合基金(第二期)超级计算科学应用研究立项和国家超级计算广州中心资助项目;模式识别国家重点实验室开放课题基金资助项目(201600031)
唐 兴(1988-),男,西安电子科技大学博士研究生,E-mail:tangxing@stu.xidian.edu.cn.
网络出版地址:http://www.cnki.net/kcms/detail/61.1076.TN.20151021.1046.020.html
猜你喜欢
意林彩版(2022年2期)2022-05-03
北京大学学报(自然科学版)(2022年1期)2022-02-21
好日子(2021年8期)2021-11-04
文苑(2020年4期)2020-05-30
第一财经(2020年4期)2020-04-14
中国生物医学工程学报(2019年6期)2019-07-16
文苑(2018年17期)2018-11-09
汽车与新动力(2016年6期)2017-01-04
自动化学报(2016年3期)2016-08-23
小天使·四年级语数英综合(2015年7期)2015-07-06
