
传感器网络中基于抽样的带权近似Top-k查询算法
2016-12-03 07:19刘彩苹蔡玉武毛建旭龙亚辉
湖南大学学报(自然科学版) 2016年10期
刘彩苹,蔡玉武,毛建旭,龙亚辉
(1.湖南大学 信息科学与工程学院,湖南 长沙 410082;2.湖南大学 电气与信息工程学院,湖南 长沙 410082)
传感器网络中基于抽样的带权近似Top-k查询算法
刘彩苹1,蔡玉武1,毛建旭2*,龙亚辉1
(1.湖南大学 信息科学与工程学院,湖南 长沙 410082;2.湖南大学 电气与信息工程学院,湖南 长沙 410082)
提出一种适用于传感器网络的抽样带权阀值过滤近似Top-k聚集查询算法.该近似算法会将无线传感器网络划成几个两两不相交的簇进行处理,在汇聚节点进行预处理以及在各个簇内进行抽样过滤处理,在抽样过程中给可靠而重要的节点赋上相应更大的权值,同时根据节点采集的信息具有时间相关特性,在簇内进行抽样阀值过滤处理,每个簇头节点都会接收到该簇内的Top-k候选子集,然后将每个簇的子集发送给Sink节点,该Sink节点将接收到能代表整网Top-k样本候选集.仿真实验结果显示该算法只需发送少量的数据,更小的抽样样本,并能满足任意精度要求.
无线传感器网络;抽样算法;Top-k查询
近年来,随着信息技术的快速发展,物联网时代已经悄悄向我们走来,无线传感器网络是物联网技术中关键技术之一.该技术广泛使用在现代化信息农业[1]、矿井智能化探测开采[2]和智能家居[3]等方面.传感器网络是由许多廉价的微型节点组织而成,可以在其监测范围内经由路由算法自组织成一个网络.用户在网络中会进行聚集查询处理,而Top-k查询是最常见的操作之一,具有非常大的实际意义,例如:用户在进行空气质量监测时,甲需要了解PM2.5值最大的k个值,乙需要了解空气质量指数最大的k个值,有时甲和乙对查询的精度标准和要求不一样,需要设计出能适应不同用户查询精度的Top-k聚集查询处理算法以便来满足多用户的实际应用需求.
由于传感器网络中的节点通信范围、计算处理、存储容量和能量大小都非常有限,聚集查询算法第一要务就要考虑节能,最大化网络的寿命.节点能量耗尽而失效,网络拓扑结构随时发生变化,而且节点在发送数据丢包和通信连接失败时,就会破坏生成的路由树,在很多情况下,传感器网络无法得到用户精确的查询分析结果.近年来,许多学者提出了许多能在传感器网络中进行近似查询的算法,近似算法能减少节点数据的发送量,节约节点的能量,最大化提高网络的寿命.
文献[4]提出一种垂直数据处理的Top-k算法.算法的主要思想是生成路由树,在路由树中进行Top-k查询,同时采用历史数据进行处理.文献[5]使用位图压缩机制减少节点间数据的发送量.节点能量和存储空间,但是恶意节点利用桶的信息可以估计出查询结果.文献[6]提出了一种近似Top-k聚集查询算法.该算法对传感器节点感知的数据进行抽样,并用线性模型得到满足用户精度要求的近似查询结果.文献[7]利用传感器节点感知数据的时空相关性.该算法采用综合样本抽样和数据压缩技术进行聚集查询.文献[8]提出了连续k近邻查询算法.算法的核心思想是采用环查询和变量维护技术减少节点数据的发送量.
文献[9]使用了一种概要查询处理技术.与其它查询算法不同的是在查询处理过程中只需要传输概要信息,而不需要传感器节点的感知值,这种技术可以减少节点的能量开销.文献[10]利用传感器网络的时间和空间相关性原理进行近似查询处理,减少节点数据的发送,降低能量的消耗.
实际上,节点在放置时往往出现分布不均匀的情况.目前的Top-k聚集查询算法有时并不能反映监测区域真实情况,例如下面情况:在环境污染监测的区域,越靠近人类居住或者水源的区域越重要,可能这些区域的空气质量指数并不是很高,但是它已经对人们的健康产生了影响,需要给用户报警提示.还有传感器网络监测某一小区的噪声大小,查询者需要了解噪声大小会影响居民最高的k个点,在监测范围内,离居民比较近的点噪声分贝值虽然不是最大的,但是它对居民的影响超出了远处分贝值比它高的点.为了满足实际的需要,可以对重要的区域增加权值的参数,扩大它的作用效果,从而更加能够反映传感器网络监测区域的真实情况[11].
传感器网络节点感知的数据具有时间和空间相关性,可以利用网络的历史查询信息估算出一个抽样阀值,在每个簇内进行抽样过滤处理时,只有大于阀值的感知值才会被发送给簇头节点,从而能够减少节点不相关信息的发送,节约能源,提高网络的寿命.
1 带权近似Top-k查询定义
如果在网络进行聚集查询时,网络是由N个节点组成,则把节点的集合记为I={1,2,3,…,N}.传感器网络存在一个能量和处理能力都强大的汇聚节点,根据路由算法以汇聚节点为根生成最小生成树,在进行聚集查询时汇聚节点会将用户的请求分发给所有节点.在t时刻,网络中各节点感知到的数据集合为Dt={d1,d2,…,dN},di={di.v,di.id,di.t}其中di.v是节点的物理感知值,di.id是标识节点的唯一ID,di.t是感知数据时的时间戳.
定义1k是自然数,且|I|≥k,在t时刻时,数据集合Dt的带权Top-k集合记为W-Top(k,Dt),是I的一个真子集,同时W-Top(k,Dt)要符合以下要求:
1)W-Top(k,Dt)⊂I;
2)|W-Top(k,Dt)|=k.
3)对于∀i∈W-Top(k,Dt),∀j∈IW-Top(k,Dt)均满足widi≥wjdj.
其中W={w1,w2,…,wN}是网络中节点赋与相应的权值,wi≥1,1≤i≤N.
定义2 对∀ε>0,Dt的近似W-Top(k,Dt)记为ε-W-Top(k),其中,ε-W-Top(k)要符合以下要求:
1)ε-W-Top(k)⊂I;
2)|ε-W-Top(k)|=k;
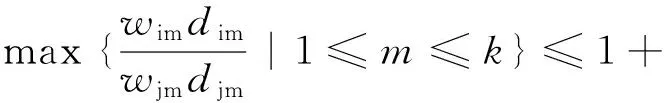
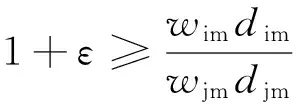
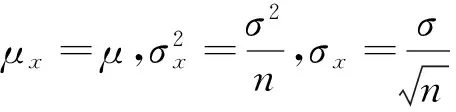

证明 如果i∈top(k,X),j∉top(k,X),并且pX(i)>(1+ε).pX(j),则称(i,j)对是相关联的.
在样本S中,如果(i,j)对是相关联的并且满足pS(i)≤pS(j),则(i,j)对是弱交换对,ε-W-Top(k,S)是Top(k,S)误差为ε的近似值当且仅当在S中没有弱交换对.
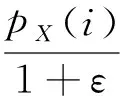
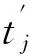
2 基于抽样带权近似过滤Top-k查询处理
算法 基于抽样的带权近似过滤Top-k查询处理算法所涉及参数定义如下所示:
Dt={d1,d2,…,dN},表示在t时刻,传感器网络中各节点感知到的数据集合,di={di.v,di.id,di.t}中di.v是节点的物理感知值,di.id是标识节点的唯一ID,di.t是感知数据时的时间戳.
W-Top(k,Dt),表示在t时刻时,数据集合Dt的带权Top-k集合.
W={w1,w2,…,wN}表示由可信度赋与节点的权值,wi≥1,1≤i≤N.
ε,且ε≥0,相对误差.

qi,表示第i个簇的抽样概率,其中i=i,2,…,r.
H(k)节点抽样时的过滤阈值.
基于抽样的带权阀值过滤近似Top-k聚集查询算法如下:
输入
1) Sink节点存有网络中所有节点的权值,其中Wmax和Wmin为最大最小权值.
2)t时刻网络中节点采集到的数据集合Dt={d1,d2,…,dn}.
3) 样本容量S.
输出 ε-W-Top(k)候选集
算法详细步骤如下所示:
ⅰ)将节点的所有权值均保存在Sink节点上,Sink节点根据定理1计算出q1的概率值.并由(ε,δ)和以前查询统计数据估算本次抽样的样本大小,记为S.
ⅱ)根据传感器网络中时间相关性原理,汇聚节点由ε-W-Top(k)的历史查询信息计算节点在抽样时的过滤阈值H(k)来筛选数据以便减少网络中数据的发送量.
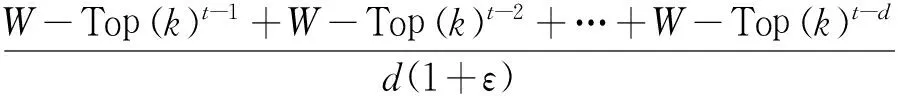
式中W-Top(k)t-1表示抽样算法返回t-1时刻ε-W-Top(k)集合排列时在集合中第k位的值,d的大小可以根据实际情况设置.
ⅲ)汇聚节点给第Ri个簇头节点发送信息(q1,Wmax,Wmin,S,H(k)),1≤i≤r.第Ri个簇头节点接收到汇聚节点发送过来的信息后就进行簇内节点抽样算法.
4)汇聚节点最终将会收到所有簇头节点发送回来的信息ε-W-Top(k)候选集的子集.
3 簇内抽样带权阀值过滤近似Top-k聚集
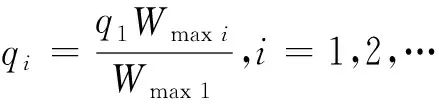
2)簇头节点会根据抽样概率qi计算第Ri个簇的样本大小是S*qi,并记为Si.簇头节点随机独立均匀地产生Si个属于{Ri1,Ri2,…,RiRi}的节点ID集合,并且把ID集合为Mi.然后簇头节点会将集合Mi及H(k)值传送给该簇内的所有节点.
3)若j∈Mi且节点j的感知信息满足dj.v≥H(k),则把节点j的感知信息传送给簇头节点,否则节点j不向簇头节点传送数据,最终簇头节点会收集到该簇内所有抽样的数据ε-W-Top(k)-Subi.
由上面的分析可知,基于抽样带权阀值过滤近似Top-k聚集查询算法如下:
The algorithm of ε-W-Top(k)
Input:W,S,Dt,ε,σ
Output:The set of ε-W-Top(k)
The sink get q1and H(k) by theorem 1 and history data
For any cluster headi,i=1,2,…r
{

Si←S*qi
//簇头节点随机独立均匀地产生Si个属于{Ri1,Ri2,...,RiRi}的节点ID集合
Mi←{Ri1,Ri2,...,RiRi}
j←0
while j<|Mi| do
if(dj.v≥H(k))
ε-W-Top(k)-Subi←dj.v
j←j+1
end while
}
return ε-W-Top(k)
节点发送所有权值的时间复杂度为O(n), 簇内节点抽样算法的时间复杂度为O(rRi),故最差时间复杂度为O(n2).
4 实验仿真及结果分析
在伯克利分校研究者研发的TAG[13]平台上进行实验.仿真实验中的感知数据来自于Berkeley Intel实验室传感器网络监测真实环境时得到的温度数据.
选取简单的Top-k抽样近似算法和本文的基于抽样带权阀值过滤近似Top-k聚集查询算法进行对比实验.
简单Top-k抽样近似查询算法由Sink节点随机独立地产生样本大小为S的样本,Sink节点将样本S广播到网络中进行抽样,如果节点编号在抽样样本中,就将该节点的信息发送给汇聚节点,汇聚节点收到数据后输出前k个最大值作为Top-k查询的近似结果.而带权近似Top-k查询抽样算法只需抽样本簇中少量数据发送给簇头节点,大大减少了数据的发送量,节省了网络中节点的能量.图1可以说明这种变化趋势.

Top-k的值
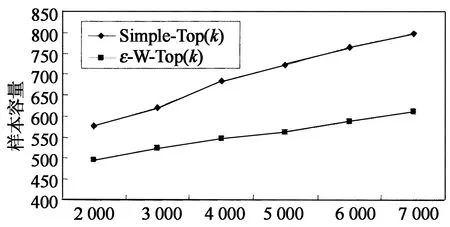
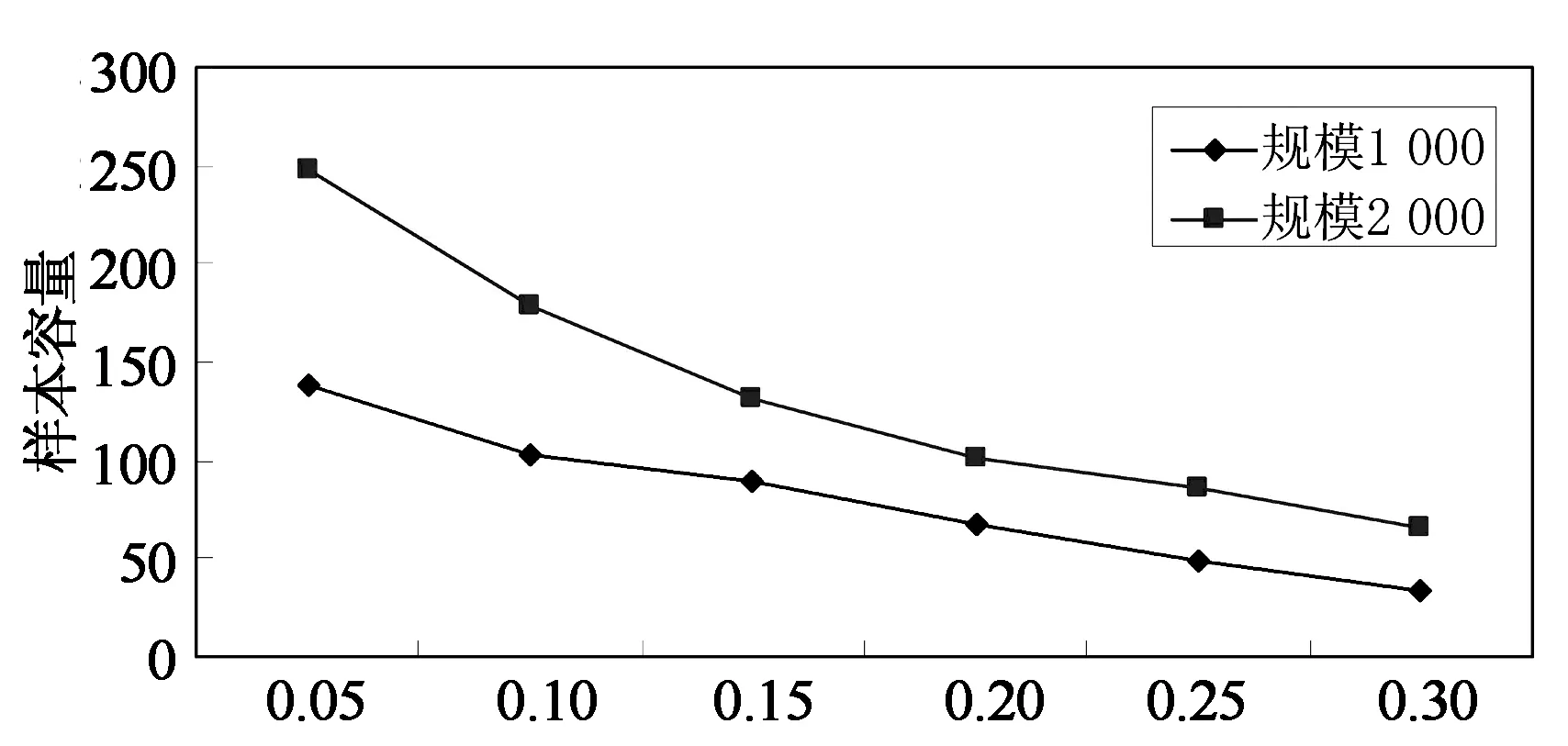
选取简单Top-k簇内抽样近似查询算法和本文带权过滤簇内抽样算法在不同的网络规模下应当选取样本容量的大小关系如图2所示.
网络规模
在(ε,δ)和k一定的条件下,简单Top-k抽样近似查询算法进行查询时随机独立地产生样本大小为S的样本.而抽样带权近似过滤Top-k查询处理算法通过给定的(ε,δ)和历史信息估计确定样本的容量S,在查询过程中根据权值确定查询概率计算每个簇内的抽样样本以及依据历史信息过滤抽样的样本值,得到能符合(ε,δ)精度的近似Top-k查询数据.从图2可以看出,在(ε,δ)和k确定的条件下,带权近似Top-k查询抽样算法在同样网络规模大小下样本容量比简单Top-k抽样近似查询算法都要小.
给定k值进行带权近似Top-k查询抽样算法时,抽样的样本容量与用户查询的精度大小和网络规模有着密切的关系,网络中节点的数量越多,查询精度要求越低,抽样的样本大小就越大,从图3的实验结果可以知道这种变化趋势.
不同误差
5 结 语
本文提出一种适用于传感器网络的抽样带权阀值过滤近似Top-k聚集查询算法.与其它Top-k查询处理算法不同,本算法进行分簇抽样处理,并根据实际情况给节点加入了权值参数,同时在每个簇内进行抽样,根据历史信息过滤掉不必要的数据,每个簇头节点会将抽样子集传送给汇聚节点,最终汇聚节点收集到全网的满足用户查询精度的Top-k集合.带权近似Top-k查询抽样算法可以有效地减少节点不相关信息的发送,节约能量,提高网络的生命周期.与普通抽样算法相比,只需要更少的样本容量即可,同时可以满足不同用户对查询精度不同的请求.所以,带权近似Top-k查询抽样算法适用于注重节约节点能量的无线传感器网络,同时能满足多用户的精度要求,以及Top-k查询的近似结果可以反应传感器网络监测区域的真实情况.
[1] BARBAGLI B, BENCINI L,MAGRINI I,etal. A real-time traffic monitoring based on wireless sensor network technologies[C]//Proceedings of the 7th International Wireless Communications and Mobile Computing Conference. Istanbul,Turkey: IEEE Computer Society, 2011:820-825.
[2] ZHANG F, DISANTO W, REN J,etal. A novel cps system for evaluating a neuralmachine interface for artificial legs[C]//Proceedings of IEEE/ACM International Conference on Cyber-Physical Systems. Chicago, USA: IEEE Computer Society, 2011:67-76.
[3] BOCCA M,TOIVOLA J,ERIKSSON M,etal. Structural health monitoring in wireless sensor networks by the embedded goertzel algorithm[C]//Proceedings of IEEE/ACM International Conference on Cyber-Physical Systems.Chicago:IEEE Computer So.Ciety, 2011:206-214.
[4] CHU D, DESHPANDE A, M.HELLERSTEIN J M,etal.data collection in sensor networks using probabilistic models[C]//In Proceedings of the 22th International Conference on Data Eingineering. Georgia, USA:April 3-7,2006: 234-251.
[5] CAO Q, ABDELZAHER T, HE T,etal.Towards optimal sleep scheduling in sensor networks for rare event detection[C]//Proceedings of IPSN.CA,USA:IPSN, 2005: 20-27.
[6] KOUSHANFAR F, TAFT N, POTKONJAK M.Sleeping coordination for comprehensive sensing using isotonic regression and domatic partitions[C]//Proceedings of IEEE Infocom.Barcelona, Spain: 2006:45-58.
[7] LI J,LI Z.Data sampling control,compression and query in sensor[J] . International Journal of Sensor Networks,2014,2(1/2):53-61.
[8] YAO Yu-xia , TANG Xue-yan, LIM Ee-peng .Localized monitoring of knn queries in wireless sensor networks[J]. The VLDB Journal, 2014,18(1):99-117.
[9] NASRIDINOV A,PARKY H.Optimal aggregator node selection in wireless sensor networks[C]//Proceedings of ICCA.Seoal, Korea:ICCA,2013, ASTL, 2013: 37-39.
[10]DELIGIANNAKIS A,PROCESSING Y K. Approximate aggregation queries in wireless senor networks[J]. Information Systems, 2013, 31(8):770-792.
[11]BI Ran,LI Jian-zhong,CHENG Si-yao.Approximate Top-k query processing algorithm in wireless sensor networks[J].Journal on Communications,2011,32(8):45-54.
[12]BEMSEIN S, BERNSTEIN R. Elements of statistics II: descriptive statistics[M].Newyork:USA McGraw-Hill, 2004.
[13]MADDEN S, FRANKLIN M J, HELLERSTEIN J M.TAG: a tiny aggregation service for Ad-Hoc sensor networks[C]//Symposium on Operating Systems Design and Implementation.Boston:MA,2002:131-146.
Research on the Approximate Algorithm of Top-k Query Based on Weighted Sampling in Wireless Sensor Network
LIU Cai-ping1,CAI Yu-wu1, MAO Jian-xu2†,LONG Ya-hui1
(1. College of Computer Science and Electronic Engineering, Hunan Univ, Changsha ,Hunan 410082; 2. College of Electric and Information Engineering, Hunan Univ, Changsha,Hunan 410082)
An approximate algorithm of Top-k query based on sampling and weight in wireless sensor network was presented. The algorithm divides the network into several disjoint clusters in the sink node and the nodes in cluster to take sampling process. In the process of sampling, greater weight for reliable and important sensor node is given. The sensor node sensing data has a time correlation, and sampling threshold filtering in the cluster. Each cluster head node receives a Top-k candidate subset of the cluster, and then sends the subset to the sink node. Finally, the sink node can receive a Top-k sample candidate that represents the whole network. Simulation experiments show that the algorithm only needs to send small data and smaller samples, and can satisfy arbitrary precision requirements.
wireless sensor networks; sampling algorithm; Top-k query
1674-2974(2016)10-0134-05
2015-06-27
国家自然科学基金资助项目(61370096,61573134),National Natural Science Foundation of China(61370096,61573134) ;国家科技支撑计划资助项目(2015BAF13B00);湖南省科技计划资助项目(2012GK3158)
刘彩苹(1978-),女,湖南邵阳人,湖南大学讲师,博士
†通讯联系人,E-mail:maojianxu@hnu.edu.cn
TP212.9
A
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化·高一版(2021年2期)2021-03-19
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
传感器世界(2019年6期)2019-09-17
知识经济·中国直销(2018年8期)2018-08-23
西部交通科技(2018年2期)2018-06-14
北京航空航天大学学报(2017年5期)2017-11-23
自动化学报(2017年7期)2017-04-18
数学学习与研究(2017年3期)2017-03-09
现代电子技术(2016年15期)2016-12-01
