
云计算环境中资源优化推荐技术研究
2016-12-01 09:55吕晓晴
现代电子技术 2016年21期
吕晓晴
(河北师范大学汇华学院,河北石家庄050000)
云计算环境中资源优化推荐技术研究
吕晓晴
(河北师范大学汇华学院,河北石家庄050000)
随着系统规模的不断扩大和数据获取量的指数级增长,在传统推荐系统的冷启动、精确性、扩展性等问题严峻化的同时,实时性问题亦成为面向海量数据推荐系统新的瓶颈点。基于传统推荐领域的主流算法,提出了一个扩展向量推荐模型。根据扩展模型对推荐算法中对象的向量进行合理扩展,通过相似度计算等过程动态选取推荐集,完成对目标对象更精确的推荐。实验结果表明,与传统推荐算法相比,基于新模型的推荐算法可以显著地提升推荐效果,成功克服冷启动问题。
扩展向量推荐模型;协同过滤;Slope One;ALS-WR;分布式计算
0 引言
由于推荐系统应用的普及,提高系统的用户体验一直是各个系统应用不断的追求。由于推荐系统中的推荐算法在运行过程中涉及大量的数据计算过程,而海量数据环境下,运算所需的时间越来越大,实时完成系统应用是面向海量数据推荐系统的瓶颈点。面对海量数据的存储,常用数据库早已超出负荷,系统的可扩展性问题也日益凸显。针对其瓶颈点,很多研究方案被提出,但将精度、实时性和可扩展性同时完美的融合在一个系统中是该领域一直以来面临的挑战。
针对传统推荐算法面向海量数据时的可扩展性和数据稀疏性问题,基于分布式环境下的数据挖掘和并行处理技术,本文除对推荐算法本身进行优化改进外,提出了一种基于Hadoop分布式平台完成推荐算法分布式实现的改进方案,即使用对海量稀疏数据具有良好支持的HDFS来存储用户交互矩阵并将其作为数据源,同时基于MapReduce分布式计算框架,将推荐算法的计算任务均衡地分配给Hadoop集群内的每台机器,从而有效地提高推荐算法的执行效率,同时在大规模分布式数据计算点,再次有效地将GPU引入进行辅助计算。
1 基于扩展向量的推荐模型
将新模型具体应用在基于项目的协同过滤推荐算法中,优化后的算法流程如下:
扩展向量:基于新模型对项目的特征向量进行扩展,即可得项目的扩展特征向量表示为:

式中:eitemj表示第j个项目对应的扩展特征向量,1≤j≤M,M为站点中的项目集合I的总数;p(i,j)表示第i个用户对第j个项目的偏好值,l≤i≤N,N为站点中的用户集合U的总数;aitem(j,k)表示第j个项目本身具有的第k个属性值,l≤k≤Q,Q为站点中项目的属性个数。所述偏好值可以代表系统中用户对项目的评分大小、评论长短、购买与否以及浏览次数等信息。所述项目属性值可以是项目本身具有的项目内容、类别、价格、年份、适用人群,产地等属性信息。同理,用户的扩展特征向量可以表示为:

式中:euseri表示useri的扩展特征向量,l≤i≤N,N为站点中的用户总数,p(i,j)表示第i个用户对第j个项目的偏好值;auser(i,k)表示第i个用户本身具有的第k个属性值,l≤k≤R,R为站点中用户相关属性的个数。具体的,所述用户属性值可以包括年龄段、性别、专业类别等。
最近邻搜索:最近邻搜索意味着寻找目标项目的最相似邻居。所有的相似度计算基于扩展特征向量和相似性度量方法展开,优化后的相似性度量方法具体如下所示:
基于欧式距离的相似度,如下:

基于谷本相关的相似度,如下:

式中:sim′(j,j′)表示对象j和对象j′的扩展特征向量之间的相似度,其相似度计算方法基于扩展向量展开。其中,基于项目的协同过滤算法即为计算候选被推荐项目与其他项目的相似值,itemj和itemj′代表两个不同的项目,Uj代表对itemj给出评分的用户集合,Uj′代表对itemj′给出评分的用户集合,Aj意味着itemj的属性信息集合,Aj′意味着itemj′的属性信息集合。由于项目的扩展特征向量考虑了项目本身具有的属性信息,使其参与相似度计算的向量更加精确,所以在理论上相似度是更加准确的。完成所有相关的计算后可以得到项目的相似矩阵。而且基于sim,项目的最近邻居也被获取到。
得到预期偏好矩阵:计算候选推荐项目的预测评分值,如下:
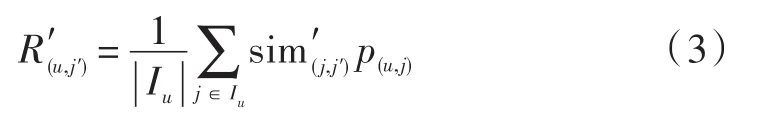
式中:R′(u,j′)用来评估用户useru对itemj′的偏好值,其计算基于目标项目的最近邻的偏好值;Iu代表对用户u给出过偏好值的item集合。
做出推荐:对候选推荐对象的推荐值R′(u,j)按照从大到小的顺序进行排序。选取前W个项目推荐给用户useru,W是人为设定的某一正整数。经过上述操作步骤,即可完成新模型在基于项目的协同过滤推荐模型的应用。
2 云计算环境下大数据的推荐系统设计
2.1系统的体系结构
不同时期的推荐系统,面对的数据量也有质的不同,从几十条记录到现在的一千万条记录,单机的推荐系统已无法满足其处理需求。
面向海量数据的推荐系统的架构如图1所示,其构建于物理集群之上,基于本地数据库和推荐算法的使用,为用户提供注册、节目推荐和节目交互等功能,其中节目交互包括新节目的推荐榜单、热播节目的榜单、用户对节目评分,以及用户可以获取对其产生的推荐列表等功能。其中系统将服务工程中产生的数据存储在文件中,并部署在HDFS上,并运用Map-Reduce并行计算框架和CUDA并行计算框架处理系统运行过程面对的海量数据处理问题,最终高性能、高质量的完成系统的各个功能,提高用户的体验。所以,从下至上,系统的体系结构分为三成:物理资源层、数据处理层(存储和计算)和应用层。
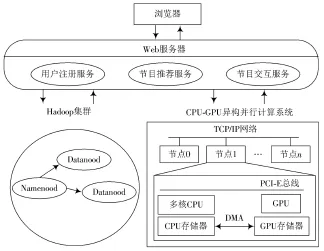
图1 云计算环境下大数据的推荐系统的架构图
2.2系统的数据支撑平台的设计
系统的数据支撑平台的设计如图2所示。对于面向海量数据的推荐系统,在用户数量较多的情况下可以对其按照地域进行分区存储,将系统应用层涉及的目标用户的最终推送数据存储在目标用户对应的地域数据库中。本地数据库对应的数据库表增加分区partition即可。这些数据库可以部署在不同的地域。对于每一个用户,其对电影的评分信息存储在分布式文件系统中,分布在该地域的Hadoop集群上。因为大多数对数据库的访问操作都具有局部性,所以,通过地域进行划分,降低了数据传送的代价,而且当网络出现故障时,仍然允许对局部数据库的操作。
由于底层采用HDFS,所以可以存储海量数据、也便于扩充。利用地域进行数据分区,对用户推荐的同时间接考虑了地域文化,一方水土孕育一方文化,一方文化造就一方人的性格,利用人性格的地域同一性使得对用户的推荐更加准确。
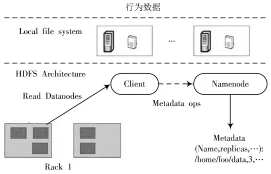
图2 系统数据支撑平台的设计
2.3系统的智能推荐模块设计
(1)推荐算法的选择
系统采用提出的新混合算法,即基于项目的Slope One分布式推荐算法,对应于混合推荐算法文本框。此外,本系统还采用了基于双重相似的协同过滤推荐算法、ALS-WR多种推荐算法彼此并行运行。对于系统提供的功能,采用多种算法呈现结果,可以最大程度地消除冷启动问题,同时可以为用户提供更为丰富的推荐列表供其选择,最大程度地满足用户的需求。
(2)数据预处理模块
数据预处理模块的功能分为两类:一种是对从系统功能层取得的数据进行优化整合并转化成算法需要的数据源格式存储在数据支撑平台的HDFS上;第二种是将推荐算法所需要的数据从数据支撑平台获取,进行相应的优化整合转化成算法所需要的二次数据源,供算法运行过程中使用。由于数据预处理过程中涉及的数据处理可以分为离线进行和在线进行两种,所以提高数据支撑平台利用率的同时也减小了系统的在线负载。其中可以离线进行处理的数据,比如对HDFS上的数据进行定时更新、选择性存储并更新算法运行过程中产生的临时文件以供下次使用,比如项目与项目之间的相似性文件等。
(3)算法运行模块
算法运行模块功能为运行基于Hadoop的推荐算法。其中输入为数据库中经过数据预处理得到的数据源,比如,系统指定格式的用户对项目的评分数据。输出是系统各项功能中所需的数据,比如对目标用户的具体的推荐项目列表。
3 推荐结果评估及系统实现
仿真实验对三种推荐算法分布式实现的实验结果进行呈现和分析,具体包括评估标准的介绍、实验数据集的选取以及不同维度推荐效果的对比。
本文取用GroupLens实验室提供的MovieLens 100K,1M以及10M数据集,其中分别包含了十万条,一百万条和一千万条用户的偏好记录。这些信息记录是从1997年9月19日—1998年4月22日,7个月时间里MovieL-ens网站(movielens.umn.edu)的用户对电影的真实评分。使用这些不同大小的数据集可以很好地测试基于新模型的三种推荐算法分布式实现的实际性能。
3.1推荐结果比较
为对比不同推荐算法基于新模型的推荐结果,在一个小型HOD集群上进行了验证。实机配置为:Dell Power Edge SC1430,英特尔至强5110(1.6 GHz)CPU两颗(双核),4 GB物理内存,300 GB硬盘(RAID 0模式),都处在100M局域网中。使用3台实机搭建Hadoop集群,三台实机分别作为pbs_server,namenod和datanode节点。在所有的节点上安装Python 2.5.1以及Hadoop发行版本的可执行程序。依次使用GroupLens三个数据集在实验集群上进行测试。
3.1.1不同推荐算法使用新模型前后的比较
使用MovieLens 100K数据集,分别运行三种推荐算法的分布式实现,得到使用新模型前后算法的准确率和召回率的对比实验结果,如表1所示。

表1 100K数据集的不同推荐算法使用新模型前后的对比
由表1可以看出,新模型的应用使推荐算法的准确率和召回率都得到了不同程度的提升。所以基于扩展向量的推荐模型可以在一定程度上解决推荐算法在精度方面的问题。另外,三种推荐算法的成功应用也说明了新模型广泛的适用性。
3.1.2基于新模型的不同推荐算法的比较
为了得到基于新模型的三种推荐算法的对比性能,本实验分别使用MovieLens 100K和1M数据集来运行三种算法的分布式实现,将得到的关于精准度和运行速度两方面的实验结果直观地呈现在表2~表4和图3,图4中。

表2 基于新模型和100K数据集的不同推荐算法的比较

表3 基于新模型和1M数据集的不同推荐算法的比较

表4 运行100K数据集的不同推荐算法的时间对比ms
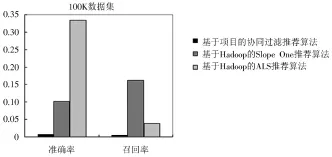
图3 基于新模型和100K数据集的算法推荐效果对比图

图4 基于新模型和1M数据集的算法推荐效果对比图
通过图3,图4可以得出,基于新模型的ALS推荐算法的准确率最高,基于新模型的Slope One推荐算法的召回率最高,而协同过滤推荐算法在准确率和召回率两方面都处于较低水平。综合考虑准确率和召回率两个方面,可以得出基于新模型的ALS推荐算法的精准度最好,基于新模型的Slope One推荐算法次之。同时,由表4可以得出,协同过滤推荐算法的运行时间最短,与其他两个算法相比,有质的飞跃。
3.1.3关于冷启动的解决
针对三种推荐算法关于解决冷启动的理论,可以采用MovieLens 100K数据集对其进行实验验证。针对数据集中有历史评分的项目对象,随机选取20个将其评分数据变为0。运行三种推荐算法,得到对实验对象的预测评分,与原始评分进行对比,得到准确率,实验结果如表5所示。

表5 关于冷启动不同推荐算法的精度对比
根据实验结果可以得出,新模型的使用使三种推荐算法都成功地解决了冷启动问题。而且三种推荐算法对基于项目的协同过滤推荐算法的应用最为成功。所以新模型可以在一定程度上解决传统推荐算法的冷启动问题。
3.2推荐效果综合总结
将推荐结果的评估和算法的复杂度以表格的形式呈现,即可得到如表6所示的内容。

表6 推荐算法的综合效果呈现
从表6中可以得出以下结论:协同过滤推荐算法虽然在商业实际应用中较为流行,但是其推荐精度次于其他两种算法;ALS-WR推荐算法虽然推荐的精准度较高,但是面向海量数据,其分布式实现中涉及的U和M会非常巨大,运行时要将它们放入内存,极大地影响了程序的运行效率。而且,算法中含有循环,由于Hadoop在处理循环时性能不够好,所以在运行过程中,此算法的性能不如其他两种算法。
Slope One推荐算法的推荐精度、冷启动的解决、运行速度均为三种算法的折中水平,但是其实现原理较为简单,所以实现复杂度较低。三种推荐算法中,基于项目的协同过滤的运行速度最优,从实验结果中可以得出,相对于其他两种算法,它有很大的优势。
4 结论
本文通过对现有个性化推荐算法的研究,提出了基于扩展向量的推荐模型,并基于Mahout中的组件对三种算法进行模型的具体应用和分布式实现,三种算法具体为Slope One推荐算法、ALS推荐算法和基于项目的协同过滤推荐算法。实验结果表明,新模型的应用能显著提高推荐效果,并且解决了推荐算法常有的冷启动问题。
针对云计算环境下大数据的推荐系统,采用分布式文件系统对数据进行存储,从而实现大数据负载均衡存储的功能。另外,分数据数据库的设计中使用地域对其进行数据库分区,此方法间接考虑了地域文化对人的性格和品位的影响,即利用一个地区的人的性格的同一性,间接达到推荐结果更优的效果。针对面向海量数据推荐系统的精确性问题,基于协同过滤算法和Slope One推荐算法,提出了一种新的混合算法,即基于项目的Slope One分布式推荐算法,并将其分布式实现应用于推荐系统中。针对海量数据处理,使用基于Hadoop的云计算平台的同时,针对一些巨大矩阵运算,采用GPU计算框架完成其并行化实现。云计算和GPU技术的融入缓解了面向海量数据推荐系统面临的扩展性和实时性问题。
[1]相海泉.迎接大数据时代[J].中国信息界,2013(5):38-42.
[2]赵卫中,马慧芳,傅燕翔,等.基于云计算平台Hadoop的并行kmeans聚类算法设计研究[J].计算机科学,2011,38(10):166-168.
[3]曹润涛.基于Hadoop的移动感知系统的设计与实现[D].西安:西安电子科技大学,2012.
[4]SU H Y,WANG C Q,ZHU Y,et al.Distributed collaborative filtering recommendation model based on expand-vector[C]// Proceedings of 2014 International Conference on Multisensor Fusion and Information Integration for Intelligent Systems.[S.l.]:IEEE,2014,989-994.
[5]朱保华,张晓滨.移动用户餐饮个性化需求推荐研究[J].现代电子技术,2015,38(11):13-15.
[6]任品.基于置信用户偏好模型的电视推荐系统[J].现代电子技术,2014,37(16):30-33.
[7]OWEN S,ANIL R,DUNNING T,et al.Mahout in action[M]. US:Manning,2011.
[8]邵泽云,刘正岐.云计算关键技术研究[J].信息安全与技术,2014,5(4):24-25.
Research on resource optimization recommendation technology in cloud computing environment
LÜ Xiaoqing
(Huihua College of Hebei Normal University,Shijiazhuang 050000,China)
With the continuously extending of the system scale and exponential order increase of data acquisition quantity,the problems of cold start-up,accuracy and scalability of the traditional recommendation system are severe,and the real-time problem becomes a new bottleneck of the massive data recommendation system.On the basis of the mainstream algorithm in the traditional recommendation field,an expand-vector recommendation model is put forward.The object vector in recommendation algorithm is expanded reasonably according to the extended model.The recommendation set is selected by means of the similarity calculation and other dynamic processes to recommend the accurate target object.The experimental results show that,in comparison with the traditional collaborative recommendation algorithm,the recommendation algorithm based on this new model can promote the recommendation effect significantly,and overcome the cold start-up successfully.
expand-vector recommendation model;collaborative filtering;Slope One;ALS-WR;distributed computing
TN911-34;TM417
A
1004-373X(2016)21-0024-05
10.16652/j.issn.1004-373x.2016.21.006
2015-12-21
引企入校——创新IT类人才培养的实践平台(2012GJJG136);以培养IT企业适应型人才为目标的软件测试KPI考核体系的构建与研究(2015GJJG275)
吕晓晴(1982—),女,河北石家庄人,硕士,讲师。主要从事计算机应用方面的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
重庆大学学报(2022年6期)2022-06-23
客联(2021年2期)2021-09-10
当代陕西(2019年14期)2019-08-26
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中学数学杂志(初中版)(2016年5期)2016-11-01
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
