
基于用户信任度和社会相似度的协作过滤算法*
2016-11-30 05:25杨海月朱玉婷施化吉
电子技术应用 2016年1期
杨海月,朱玉婷,施化吉,徐 慧
(1.江苏大学 计算机科学与通信工程学院,江苏 镇江212013;2.大全集团,江苏 扬中 212211)
基于用户信任度和社会相似度的协作过滤算法*
杨海月1,朱玉婷1,施化吉1,徐慧2
(1.江苏大学 计算机科学与通信工程学院,江苏 镇江212013;2.大全集团,江苏 扬中 212211)
个性化推荐算法是解决社交网络中信息过载问题的一种有效方法,已成为社交网络中的研究热点。协作过滤算法是被广泛应用的个性化推荐算法,但由于未考虑社交网络的一些重要社交信息及数据稀疏问题,故其在解决社交网络的推荐问题时推荐效果不佳。为此,提出一个基于用户信任度和社会相似度的协作过滤算法。首先根据用户-项目矩阵计算用户相似度,然后通过社交网络计算用户信任度和社会相似度并将三者融合,最后根据融合后的值形成最近邻集,并据此产生推荐结果。经实验分析,文中提出的算法较其他算法在解决社交网络的推荐问题时有更高的推荐精度。
协作过滤;数据稀疏;用户信任度;社会相似度;社交网络
0 引言
随着社交网络的迅猛发展,网络上的信息呈爆炸式增长,出现了“信息过载”问题。个性化推荐被认为是解决该问题最有效的方法[1],常用的个性化推荐算法主要有协作过滤[2]、基于内容推荐[3]、混合推荐[4]等,协作过滤算法是其中的研究热点[5]。
协作过滤算法在解决社交网络的推荐问题时因未考虑社交网络的一些重要社交信息及数据稀疏问题,故其推荐效果不佳。文献[6]提出的方法在一定程度上缓解了数据稀疏问题,对冷启动用户的推荐精度有一定提高,但对所有用户的推荐精度不高。文献[7]提出方法仅考虑了朋友关系这一社交信息而忽略了用户相似度的影响,故推荐精度也不高。文献[8]提出的方法研究了用户项目间的信任关系,但未考虑用户间信任关系,故未能缓解数据稀疏问题。这些研究表明社交网络中个性化推荐的精度有待提高且数据稀疏问题也没有得到很好的解决。为此,提出一个基于用户信任度和社会相似度的协作过滤算法(User Trust and Social Similarity-based Collaborative Filtering Algorithm,UTSSCF)。首先根据用户-项目矩阵计算用户相似度,然后通过社交网络计算用户信任度和社会相似度并将三者融合,最后根据融合后的值形成最近邻集,并据此产生推荐结果。
1 用户信任度计算
文献[9]的研究表明社交网络中的用户更倾向于采纳信任的人的推荐。因此,用户信任对社交网络的个性化推荐有着重要影响。在社交网络中,若A和B有直接联系(如A关注B),则A对B有直接信任关系;若A对B且B对C有直接信任关系,则A对C有间接信任关系。文中把社交网络中用户信任关系划分为直接信任关系和间接信任关系,分别以直接信任度和间接信任度进行度量。
定义1(社交网络S)设U表示S中用户节点集合,E表示S中用户间的直接信任关系集合,W表示S中用户间的直接信任度T的集合,S则可用三元组表示成S(U,E,W)。其中,U={u1,u2,…,un},|U|=n;E={<u,v>|u,v∈U};W={T(u,v)|u,v∈U}。
1.1直接信任度计算
在S中若u和v有直接联系,则u对v有直接信任关系,并用直接信任度T进行度量。
定义2(直接信任度T)若S中有一条从u指向v的边,则u对v的直接信任度T(u,v)为1,否则,为0。
考虑到后文选取的用户相似度度量方法(见4.1节)的取值范围是[-1,1],故要对 T进行归一化处理,使得归一化的直接信任度tr取值限定在[0,1]。归一化处理后得到的直接信任度如式(1)所示。

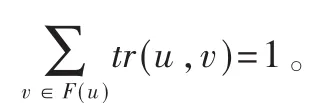
1.2间接信任度计算
若u对v有间接信任关系,则可用间接信任度T′进行度量。
定义3(间接信任度T′)若在S中至少存在一条从u到v的路径,则u对v有间接信任关系,又u到v的最短路径为 path={<u,u1,u2,…,uk,v>|min(k+1)∧u,v,ux∈U,1≤x≤k},则u对v的间接信任度T′(u,v)=(tr(u,u1) +tr(u1,u2)+…+tr(uk,v))/(k+1)。
另外,根据小世界理论设置max(k+1)为6。若S中u到v的max(k+1)大于6,则T′(u,v)=0。
1.3用户信任度计算
如上所述,文中把用户信任度分为直接信任度和间接信任度,故用户信任度是它们的综合值。设Tr(u,v)表示u对v的用户信任度,A表示tr(u,v),B表示T′(u,v),则用户信任度的计算如式(2)所示。

2 社会相似度计算
文献[10]的研究表明用户间共有的朋友数越多,其社交、兴趣、偏好越相似。因此,用户间共有的朋友数也是一个影响社交网络个性化推荐的重要因素,文中用社会相似度定量其影响程度。
定义 4(社会相似度 Ss)Ss(u,v)指 S中任意两个直接相连的用户节点u和v间共有的朋友数占它们总朋友数的比值,则其计算如式(3)所示。

其中,F(u)={u′|<u,u′>∈E∧u,u′∈U}(F(v)同理),表示从u和v共同指向的用户节点数,表示从u及v指向的用户节点数之和。
3 UTSSCF算法
3.1用户相似度计算
计算用户相似度是为了寻找兴趣偏好相似的用户,从而据此产生推荐结果。设S中u和v已评价项目并集为 Iuv=Iu∪Iv,则 u和v的用户相似度计算如式(4)所示。
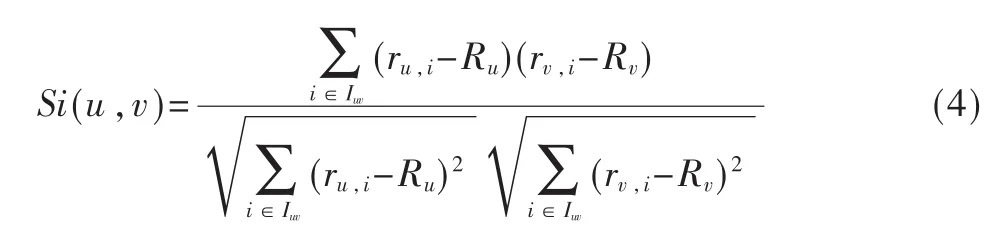
其中,ru,i和rv,i分别表示u和v对i的评分,Ru和Rv分别表示u和v对Iuv中所有项目评分的平均值。
3.2用户相似度、用户信任度和社会相似度的融合
由于社交网络中用户-项目矩阵很稀疏,故将用户相似度、用户信任度和社会相似度进行融合以缓解数据稀疏的问题。
设 We(u,v)表示 Si(u,v)、Tr(u,v)和 Ss(u,v)融合后的值,则We(u,v)的计算如式(5)所示。
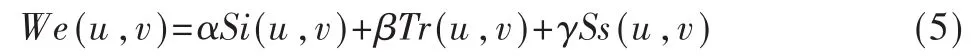
其中,α、β、γ分别表示 Si(u,v)、Tr(u,v)、Ss(u,v)所占的比重,且α+β+γ=1。
3.3产生推荐结果
计算出We(u,v)后,选择We(u,v)最大的l个用户作为u的最近邻集Ns。根据Ns中的用户评分数据预测u对未评价项目I的评分Pu,I,并将预测评分最高的 k个项目推荐给u。预测评分的计算如式(6)所示。
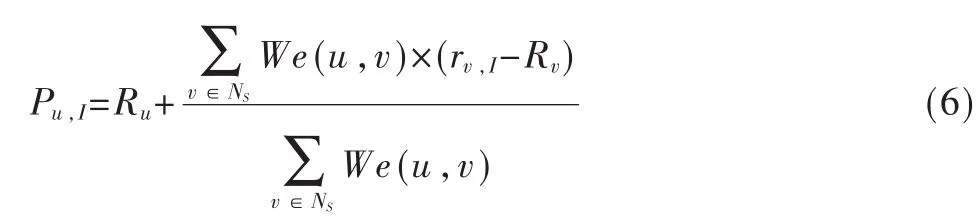
其中,Ru和Rv分别表示u和v对所有项目评分的平均值,rv,I表示 v对 I的评分。
3.4算法描述
UTSSCF算法的推荐步骤可分为用户相似度计算、用户信任度和社会相似度计算、形成最近邻集、预测评分、产生推荐结果5个阶段。算法1为UTSSCF算法的具体实现步骤。
算法1 UTSSCF算法
输入:用户-项目矩阵 UI,社交网络 S,目标用户 u,其它用户 v,推荐项目的个数 k,待推荐的项目集合Ir。
输出:给u的推荐结果Re。
步骤1:根据UI,利用式(4)计算u与v的Si(u,v);
步骤2:根据S,先按定义2得到u对v的T(u,v),并按式(1)计算出 tr(u,v),然后按定义 3计算 u对 v的T′(u,v),接着按式(2)计算 u对 v的 Tr(u,v),最后按式(3)计算u对v的Ss(u,v);
步骤 3:对步骤 1和步骤 2得到的 Si(u,v)、Tr(u,v)和Ss(u,v)利用式(5)计算出We(u,v)。然后,根据We(u,v)为u选取最近邻集Ns;
步骤 4:对于 Ir中的每个项目 I,根据式(6)计算 u对I的 Pu,I;
步骤5:根据步骤4得到的Pu,I,将 Ir中的所有I进行排序,选择前top-k个I作为给u的Re。
4 实验设计与分析
4.1实验数据来源
实验采用的数据集是目前在度量算法推荐精度中较常用的Epinion1数据集,由49 290个用户、139 738个项目、664 824个评分和487 182条信任声明组成。其中评分是从1到5的整数,信任值是0或者1(0表示不信任,1表示信任)。
4.2实验评价标准
实验采用平均绝对误差MAE(Mean Absolute Error)和均方根误差RMSE(Root Mean Square Error)衡量算法的推荐精度。MAE和RMSE的计算分别如式(7)和式(8)所示。
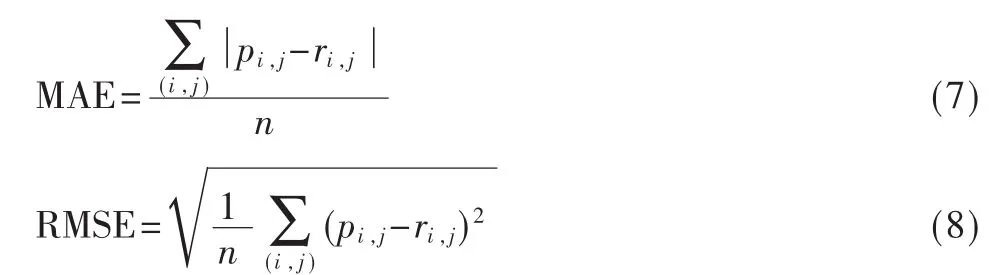
其中,n为评分的总数,pi,j代表用户 i对项目 j的预测评分,ri,j代表用户 i对项目 j的实际评分,MAE值和RMSE值越小表示推荐精度越高。
4.3实验结果与分析
为验证 UTSSCF算法的推荐精度,随机将 Epinion数据集的80%作为训练集,剩余的20%作为测试集。训练集用来训练或者学习算法中的相关参数,测试集用来验证推荐结果的精度。
实验1(参数 α、β、γ的学习):因为 α+β+γ=1,所以只需要对任意2个参数进行学习即可。实验中分别考虑当α=0.1、β从0.1到0.8变化时,及当α每增加0.1直到0.8、β从0.1到0.8变化时对推荐精度的影响。经实验发现,当α=0.2、β=0.4、γ=0.4时是最优值。
实验 2(邻居数的影响):实验 2是观察 UTSSCF算法的MAE值和RMSE值随邻居数变化而变化的情况。当邻居数分别取 5、10、15、20、25、30、35、40时,实验结果如图1所示。
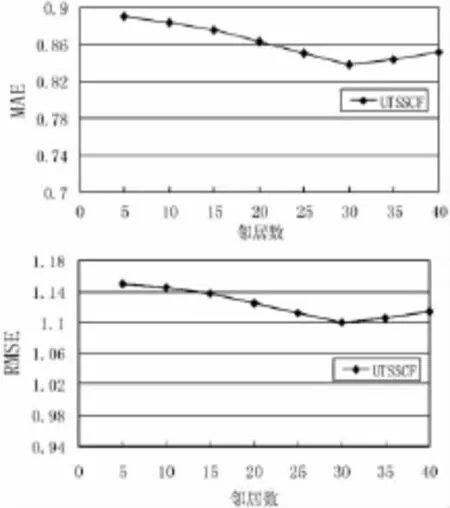
图1 邻居数对MAE值和RMSE值的影响
从图1可以看出UTSSCF算法的MAE值和RMSE值随着邻居数的增加先逐渐减小再逐渐增加。在邻居数为30时,UTSSCF算法的MAE值和RMSE值均达到最小值。这说明当邻居数为30时,UTSSCF算法的推荐精度最高。
实验3(USTTCF算法与其他算法的比较):实验3的目的是比较UTSSCF算法与其他算法的推荐精度。实验3中参数设置为 α=0.2,β=0.4,γ=0.4,邻居数为 30,实验结果如图2所示。实验中选择以下算法与UTSSCF算法进行对比:(1)协作过滤推荐算法(Collaborative Filtering Recommendation Algorithm,CF);(2)基于用户相似度的协作过滤推荐算法[11](User Similarity-based Collaborative Filtering Recommendation Algorithm,USCF);(3)基于综合信任度的协作过滤推荐算法[5](Comprehensive Trust-based Collaborative Filtering Recommendation Algorithm,CTCF)。
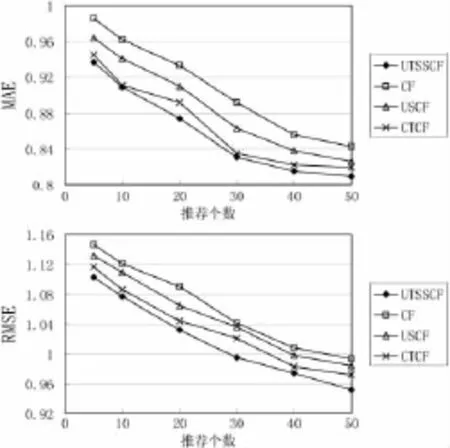
图2 各类算法的比较
从图2可以看出USCF算法优于CF算法,CTCF算法优于USCF算法,而UTSSCF算法又优于CTCF算法。USCF算法优于 CF算法是因为 USCF算法针对社会网络对用户相似度进行重新定义,所以USCF算法在该实验数据集上取得了比CF算法更好的实验结果。CTCF算法优于USCF算法是因为CTCF算法考虑了用户信任关系,由此可见,考虑用户信任关系确实有助于提高算法的推荐精度。UTSSCF算法优于 CTCF算法是因为UTSSCF不仅考虑了用户信任关系,还有社会相似度。此外,在图2所示的整个变化过程中,UTSSCF算法的MAE值和RMSE值比其它算法都低,这说明UTSSCF算法能够提高推荐精度。
5 结论
针对社交网络中个性化推荐精度不高和数据稀疏的问题,提出了一个基于用户信任度和社会相似度的协作过滤算法。首先根据用户-项目矩阵计算用户相似度,然后通过社交网络计算用户信任度和社会相似度并将三者融合,最后根据融合后的值形成最近邻集,并据此产生推荐结果。经实验分析,UTSSCF算法较其他算法在解决社交网络的推荐问题时有更高的推荐精度。UTSSCF算法只考虑了用户信任度和社会相似度,而社交网络中的社交信息还有很多,如社区、上下文信息、主题等。在协作过滤算法中引入更多社交信息是后续要研究的内容。
[1]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[2]王玉祥,乔秀全,李晓峰,等.上下文感知的移动社交网络服务选择机制研究[J].计算机学报,2010,33(11):2126-2135.
[3]QU W,SONG K S,ZHANG Y F,et al.A novel approach based on multi-view content analysis and semi-supervised enrichment for movie recommendation[J].Journal of Computer Science and Technology,2013,28(5):776-787.
[4]王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,2012,23(1):1-20.
[5]朱强,孙玉强.一种基于信任度的协同过滤推荐方法[J].清华大学学报:自然科学版,2014,54(3):360-365.
[6]HWANG W S,LI S,KIM S W,et al.Data imputation using a trust network for recommendation[C].Proceedings of the companion publication of the 23rd international conference on World wide web companion.International World Wide Web Conferences Steering Committee,2014:299-300.
[7]YIN C,CHU T.Improving personal product recommendation via friendships'expansion[J].Journal of Computer and Communications,2013,1(5):1-8.
[8]DENG S G,HUANG L T,WU J,et al.Trust-based personalized service recommendation:A network perspective[J]. Journal of Computer Science and Technology,2014,29(1):69-80.
[9]JAMALI M,ESTER M.A matrix factorization technique with trust propagation for recommendation in social networks[C]. Proceedings of the 4th ACM conference on Recommender systems.ACM,2010:135-142.
[10]GUO G,ZHANG J,THALMANN D.Merging trust in collaborative filtering to alleviate data sparsity and cold start[J].Knowledge-Based Systems,2014,57(2):57-68.
[11]荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
Collaborative filtering algorithm based on user trust and social similarity
Yang Haiyue1,Zhu Yuting1,Shi Huaji1,Xu Hui2
(1.School of Computer Science and Telecommunication Engineering,Jiangsu University,Zhenjiang 212013,China;2.Daquan Group Company,Yangzhong 212211,China)
Personalized recommendation algorithm as an effective method to solve the information overload problem has become a research hotspot in social networks.Without considering some important social information of social networks and the data sparsity, the collaborative filtering algorithm which is a widely used personalized recommendation algorithm has poor recommendation effect for recommendation issues of social networks.Therefore,this paper proposes a collaborative filtering algorithm based on user trust and social similarity.Firstly,the algorithm calculates user similarity according to the user-item matrix and calculates user trust as well as social similarity through constructed user network.Next,the user similarity,user trust and social similarity will be merged to form a comprehensive value,which is used to produce neighbors.Accordingly,recommendations are produced.The experimental results show that the proposed algorithm has higher recommendation accuracy than other algorithms in solving the recommendation issues of social networks.
collaborative filtering;sparse data;user trust;social similarity;social networks
TP301.6
A
10.16157/j.issn.0258-7998.2016.01.026
江苏省科技支撑计划(BE2011156)
2015-08-18)
杨海月(1992-),通信作者,女,硕士研究生,主要研究方向:个性化服务、数据库技术,E-mail:haiyue_yang1@163.com。
朱玉婷(1991-),女,硕士研究生,主要研究方向:社会网络分析。
施化吉(1964-),男,硕士,教授,主要研究方向:智能信息处理、社会网络分析。
中文引用格式:杨海月,朱玉婷,施化吉,等.基于用户信任度和社会相似度的协作过滤算法[J].电子技术应用,2016,42(1):100-103.
英文引用格式:Yang Haiyue,Zhu Yuting,Shi Huaji,et al.Collaborative filtering algorithm based on user trust and social similarity [J].Application of Electronic Technique,2016,42(1):100-103.
猜你喜欢
作文成功之路·小学版(2019年8期)2019-09-18
人大建设(2019年4期)2019-07-13
小学生学习指导(低年级)(2019年4期)2019-04-22
环球时报(2018-01-23)2018-01-23
读者(2017年14期)2017-06-27
桃之夭夭B(2017年2期)2017-02-24
汽车维护与修理(2015年5期)2015-02-28
高中生·青春励志(2014年11期)2014-11-25
IT经理世界(2014年5期)2014-03-19
