
数据挖掘在传统洪水预报方案中的应用
2016-11-30 10:11姜涛
东北水利水电 2016年11期
姜涛
(水利部松辽水利委员会,吉林长春130021)
数据挖掘在传统洪水预报方案中的应用
姜涛
(水利部松辽水利委员会,吉林长春130021)
数据挖掘就是从大量数据中提取或挖掘一般性规律规律。文中利用weka数据挖掘平台的多元线性回归算法和决策树算法,对两种传统经验洪水预报方案进行了建模和评估,一定程度上提高了洪水预报方案精度。
数据挖掘;weka;洪水预报方案
1 前言
洪水预报方案是开展实时洪水作业预报的基础,方案精度的高低直接决定作业预报的成败。按照水文情报预报规范的技术要求,只有精度达到乙级及以上的洪水预报方案方可正式发布预报,丙级方案只能为防汛决策提供参考。
目前,水文模型在国内应用越来越广泛,但合成流量法、降雨径流相关图法这两种传统的经验预报方法仍在国内得到很多应用。这两种预报方案参数少,使用简单,有一定经验的预报员很容易完成一次精度较高的实时洪水作业预报。但在实时洪水作业预报过程中,也暴露出很多问题。一是预报方案信息的提取还停留在人工查线读数阶段,虽然很多系统实现了自动读取预报方案信息的功能,但信息的“根源”还是来自手工绘制的曲线。二是对历史水文数据的分析深度不够,常常因为人类活动影响,导致方案精度不高;三是缺乏理论基础,属于“黑箱”预报方法。
近年来,数据挖掘作为一门新兴的数据处理技术日益成熟,挖掘平台功能越来越强大,集成的算法越来越多,它可以在没有明确假设的前提下发现数据内在的关系,挖掘有价值信息、发现知识,与传统的数据分析、查询有着本质区别,因而在水利上的应用也越来越广泛。
2 数据挖掘
WEKA是一个开源的数据挖掘工作平台,集成了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化,是现今最完备的数据挖掘工具之一。文中主要利用weka数据挖掘平台的回归分析中多元线性回归算法和分类中的决策树算法,实现两种传统经验洪水预报方案模型化,进一步提高洪水预报方案精度。算法原理如下:
2.1 回归分析算法
回归分析研究一个变量和一组其它变量之间相关关系的方法,是统计方法中应用最广泛的方法。回归分析按照回归变量的个数不同可以分为一元回归分析和多元回归分析,按照回归的形式不同可以分为线性回归分析和非线性回归分析。通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以通过对变量进行变换,从而转换为线性问题来解决。回归分析主要解决以下几个方面的问题:
1)确定几个特定变量之间是否存在相关关系,如果存在的话,找出它们之间合适的数学表达式。
2)根据一个或几个变量的值,预报或控制另一个变量的取值,并且要知道这种预报或控制的精确度。
3)进行因素分析,确定因素的主次以及因素之间的相互关系等。
2.2 决策树算法
决策树是一种常用于预测模型的算法,它通过将大量数据有目的分类,从中找到一些有价值的,潜在的信息。决策树主要的作用是对集合进行分类,或者是发现某类对象的特征模式。它的主要优点是描述简单,分类速度快,特别适合大规模的数据处理。利用信息论中的互信息(信息增益)寻找数据库中具有最大信息量的字段,建立决策树的一个结点,再根据字段的不同取值建立树的分支;在每个分支子集中,重复建立树的下层结点和分支的过程,即可建立决策树。
3 应用实例
3.1 多元线性回归算法改进合成流量预报方案
3.1.1 研究区概况
大赉水文站位于嫩江干流下游,是嫩江流域总控制站,集水面积221 715 km2。富拉尔基至大赉水文站区间,右岸有雅鲁河、绰尔河、洮儿河几大支流汇入,左岸没有支流汇入。大赉水文站洪水一般是以干流来水为主,洮儿河洪水受月亮泡水库控制一般对干流洪水影响较小,雅鲁河支流罕达罕河在碾子山控制断面下游汇入雅鲁河,因而在特殊大水年份,要考虑该河洪水对干流洪水影响。
大赉水文站现有预报方案之一为嫩干富拉尔基水文站、雅鲁河碾子山水文站、罕达罕河景星水文站、绰尔河两家子水文站合成流量与大赉水文站洪峰流量相关,方案合格率为75%,为乙级方案。
合成流量法是河道洪水预算方法之一,通常称为河道相应水位(流量)法,是根据天然河道洪水波运动原理,分析洪水波上任一位相水位(流量)沿河道传播过程中的变化规律。在支流来水较大的情况下,通常采用合成流量法。
3.1.2 研究步骤
1)数据预处理。数据挖掘的基础是数据的数量和质量。数据量越大,越能从数据中发现洪水的一般性规律,数据的准确性和可靠性也是一切建模和分析是否有效的关键。数据挖掘的优势也在于可以从海量的水文历史资料中按照相关性、可靠性、最新性等原则,挑选出与研究最有用的部分。
该研究直接从松花江流域实用洪水预报方案(2003年版)中摘取了富拉尔基、碾子山、景星、两家子、大赉水文站的9场合格场次洪水历史特征数据,建立符合weka平台数据格式要求的数据集,如表1所示。另外,为了验证模型精度,将方案中2场不合格场次洪水特征数据,作为检验模型精度的数据集,如表2所示。
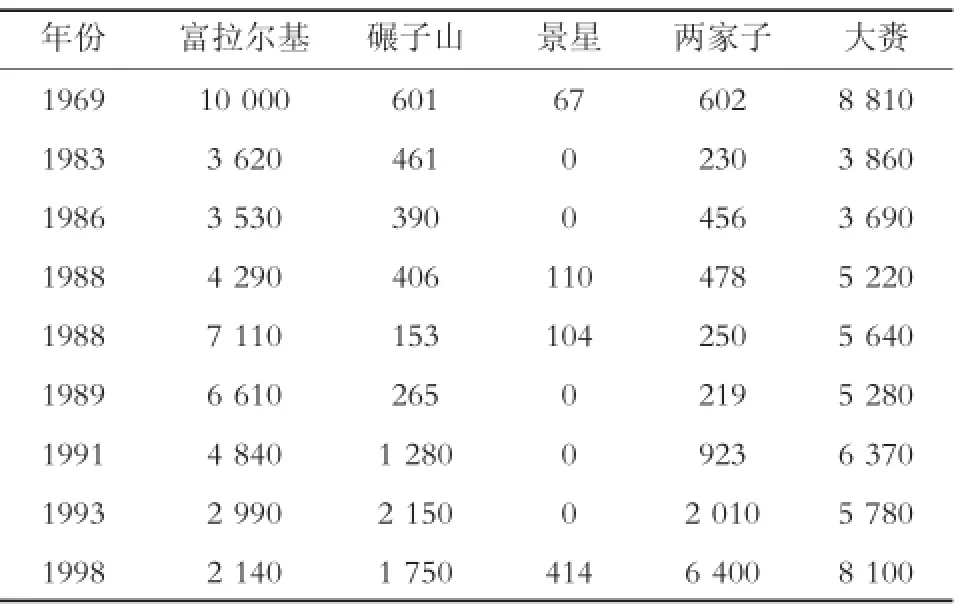
表1 合格场次洪水特征数据 流量:m3/s

表2 不合格场次洪水特征数据 流量:m3/s
需要注意的是还有一场不合格场次洪水特征数据被弃用,主要是因为富拉尔基至大赉水文站区间河段在1998年第三场特大洪水发生时,堤防多处决口,大赉站洪峰数据为还原数据,因而不参见建模。
2)选择算法,建模。利用W eka软件的Explorer读取数据,选择线性回归建立预报模型;选择表1的数据集做为训练数据,选择表2的数据集做为检验数据集;系统运行,得出模型的回归方程如下:
Q大赉=0.631×Q富拉尔基+1.636×Q碾子山+7.411× Q两家子+769.692
3.1.3 模型评估
1)利用回归方程建立的模型,用于检验的不合格场次洪水测试精度均达到合格标准,方案合格率为11/12×100%=92%,为甲级方案,远高于原乙级方案的合格率75%。详见表3。
2)模型中不包含景星站这个变量,主要是由于景星站洪水对大赉站洪水贡献过小,在表1中景星站最大洪峰流量仅为414 m3/s,占大赉站洪峰流量的5%,属于不敏感参数,在数据挖掘过程中被舍弃。但是,当景星洪峰较大时,如1998年8月11日8时,景星洪峰流量高达2 400 m3/s,应该将景星洪峰流量与碾子山洪峰流量合并后,再输入模型计算,就可以得到令人满意的预报结果。

表3 不合格场次洪水检验 流量:m3/s
3)模型使用简单,可以脱离waka平台。当富拉尔基水文站出现洪峰时,提取其余三站同时流量,代入模型(可以使用excel或计算器),即可准确预报出大赉水文站洪峰流量,预见期长达7 d以上。
4 决策树算法改进降雨径流相关图预报方案
4.1 研究区概况
五道沟水文站是第二松花江支流辉发河的把口控制站,集水面积12 391 km2。流域内水利工程众多,大型水库一座,中小水库几十座,控制面积3 000 km2,占五道沟集水面积的24.4%。
五道沟水文站现有预报方案之一为:P+Pa~R降雨径流相关图预报方案,产流方案合格率为78%,为乙级方案。
4.2 研究步骤
1)数据预处理。该研究直接摘取了五道沟水文站P+Pa~R降雨径流相关图预报方案中40场合格场次洪水历史特征数据,建立符合weka平台数据格式要求的数据集。另外,为了验证模型精度,将方案中11场不合格场次洪水特征数据,作为检验模型精度的数据集。
2)选择算法,建模。利用W eka软件的Explorer读取数据,选择决策树算法建立预报模型;选择40场合格场次洪水历史特征数据做为训练数据,选择11场不合格场次洪水特征数据为检验数据集;系统运行,得出模型的决策树结构。
4.3 模型评估
1)决策树算法建立的预报模型,用于检验的11场不合格场次洪水中,有5场测试精度均达到合格标准,方案合格率为45/51×100%=88%,为甲级方案,高于原乙级方案的合格率78%。详见表4。
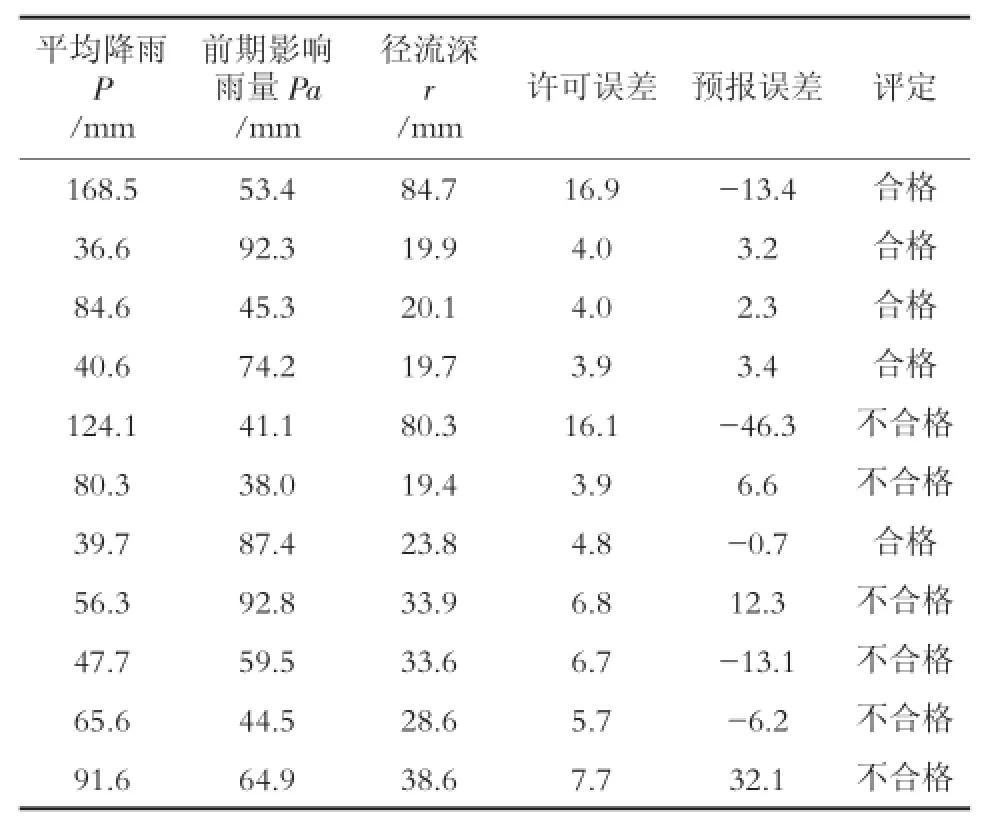
表4 不合格场次洪水检验
2)由于五道沟上游中小水库较多,对河道洪水调蓄作用较大,而又无法量化,容易导致从实测洪水数据分割本场次洪水时误差较大,进而使降雨、前期影响雨量与净流深的关系偏离原有规律。
3)径流深只是P+Pa~R降雨径流相关图产流方案的计算结果,但径流深的预报精度直接决定了洪水总量和洪峰的大小。
5 结语
本文使用两种数据挖掘算法,对两种传统预报方案进行了建模,进一步提高了预报方案精度,可以为经验洪水预报方案编制以及实时洪水作业预报提供借鉴和参考。但在研究中也发现数据挖掘具有如下特点,需要加以注意。
1)数据挖掘在某一领域应用时,需要结合各种专业知识和实际工作经验对建模过程进行科学评估,以确保挖掘到的规律具有一般性,避免不同的研究人员对同样的数据进行挖掘,产生差异较大的结果。
2)数据挖掘平台功能强大,但只是一个提供了大量算法的分析工具,并不是万能的,仍然需要研究人员理解数据挖掘流程,了解算法基本原理和专业知识。
TV124
B
1002-0624(2016)01-0029-03
2016-08-10
猜你喜欢
黑龙江水利科技(2020年8期)2021-01-21
中华建设(2020年5期)2020-07-24
黑龙江水利科技(2020年2期)2020-05-07
成都信息工程大学学报(2019年3期)2019-09-25
中国特种设备安全(2019年5期)2019-07-16
现代计算机(2019年16期)2019-07-15
水电与新能源(2019年5期)2019-05-30
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
电影故事(2015年33期)2015-09-06
