
基于改进PageRank算法的微博用户影响力排序研究
2016-11-29 01:28:31丁温雪徐家兴朱颢东
湖北民族大学学报(自然科学版) 2016年3期
丁温雪,徐家兴,朱颢东
(郑州轻工业学院 计算机与通信工程学院,河南 郑州 450002)
基于改进PageRank算法的微博用户影响力排序研究
丁温雪,徐家兴,朱颢东*
(郑州轻工业学院 计算机与通信工程学院,河南 郑州 450002)
针对传统的PageRank算法中存在主题漂移和偏重旧网页的弊端,提出了一种基于改进PageRank算法的微博用户影响力排序方法——TSPR算法.该算法将时间因素作为横向标度,采用TF-IDF方法计算网页间的相似度,并具体分析某个时间段用户搜索主题相似度的变化.通过计算网页PR值的大小,从而对微博用户影响力进行排序.仿真实验结果表明,该算法改善了微博用户影响力排序效果,与此同时,提高了搜索质量和准确率.
PageRank算法;时间因子;主题相似度;用户影响力排序
截至2016年6月,CNNIC发布的报告[1]中指出,我国网民规模达到7.10亿,半年共计新增网民2 132万人,半年增长率为3.1%,较2015年下半年增长率有所提升.互联网技术发展迅猛,微博早已成为人们进行信息交流的重要平台.经典的PageRank算法[2]忽视了用户的个性化需求,网络的内容和结构是不断变化的,用户实际访问时常常忽略时间因素,这是不符合用户行为规律的.如何根据用户实际需求与搜索主题相似度这两种因素,从而改进PageRank算法对重要网页进行排序成为了重点研究的问题.
目前,众多专家学者运用PageRank算法的相关改进算法对微博用户影响力进行排名.在国内,随着互联网技术的普及,面对大规模的用户群.陈淑鑫等[3]通过分析传统的本体映射方法及相似度计算方法无法处理模糊信息的缺陷提出了一种新的基于向量空间模型的模糊概念相似度计算方法.实验结果表明,该方法有效地处理了模糊信息间的相似度问题.黄贤英等[4]提出基于语义的文本相似度算法.不同格式的文本类型对文本相似度算法的适用能力也各不相同,因此他们分别给出了短文本词性切分、关键词权值计算、词性空间相似度计算、中/英文本相似度计算的方法进行研究,有效地识别了“僵尸”用户.在国外,针对传统的PageRank算法没有考虑主题对排序结果的影响,W.Gang,W.Yimin等[5]在主题相似度方面进行了改进,该方法不但把网络的拓扑结构作为度量基础,还加入了上下文相关性和主题敏感度等相关影响因素,最后,通过大量的仿真实验,验证了他们的假设.Weng J等[6]提出了TwitterRank算法,不但考虑了网络结构与用户交互,而且还分析了主题的相似性,并将它与现有的算法进行对比,综合所有获取到的主题计算出每个Twitter用户的影响力之和,从而达到对Twitter用户的影响力排序的目的.
针对传统PageRank算法中存在的缺陷,本文提出了一个基于网页质量、时间因子不断更新[7]、分析网页主题相关[8]的内容的改进型PageRank算法.
1 相关技术
Larry Page和Sergey Brin认为网页之间通过超链接相互连接,互联网上不计其数的网页就构成了一张超大的图.用户从全部网页中随机选择一个网页进行浏览,通过超链接在网页上不断跳转到每个网页时,都会有两种选择:①到此结束;②继续选择一个链接浏览.因此,计算一张网页,例如网页A的等级的标准公式如式(1).
(1)
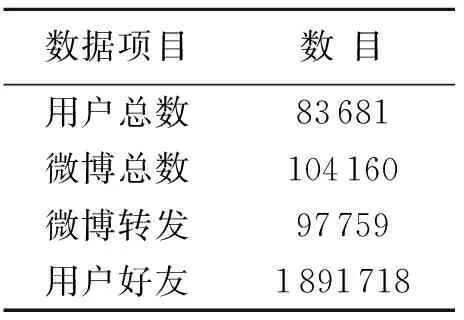
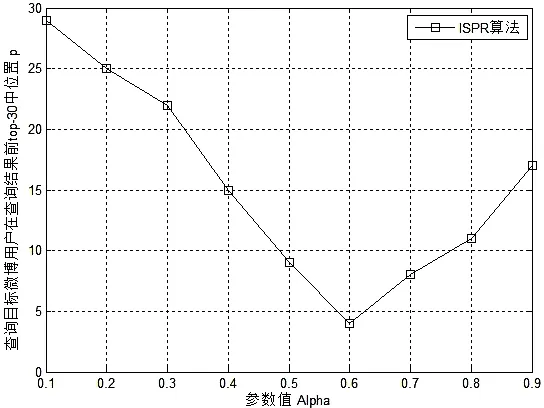
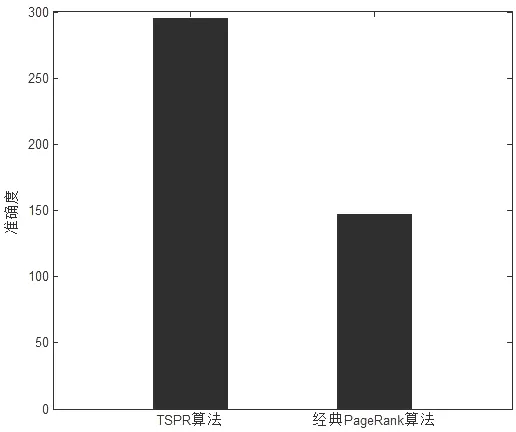
式(1)中,n表示全部网页的总数量,PR(A)表示其中的一张网页(例如网页A)的PR值,PR(Pi)表示链接到A的网页Pi的值,C(Pi)表示网页Pi的出栈链接数量.为避免网页之间出现悬挂链接而导致稳态概率无法收敛的情况,在这里,引入阻尼系数d(0 随机游走模型定义参见文献[9].假设用户以相等的概率在当前页面的所有超链接中随机选择一个链接继续浏览.当经过很多次游走之后,每个网页被用户访问到的概率就会趋向于一个稳定值.算法迭代关系式如下所示: (2) 式(2)中,in(i)表示指向网页i的网页集合,out(j)表示网页j指向的网页集合.斯坦福大学的Haveliwala于2002年在《Topic-sensitivepagerank》一文中提出了PersonalRank算法.用user节点和item节点替换式(1)中的网页节点就可以计算出每个user和每个item在全局的重要性,从而给出全局的排名,然而,需要计算行为节点相对于某一个用户节点u的相关性.该算法能够为用户个性化所有相关行为进行排序.它的迭代公式如下: (3) 式(3)中,用ri替换了1/n,也就是说从不同点开始的概率不同.u表示推荐的目标用户,这样使用上式计算的就是所有顶点相对于顶点u的相关度.PersonalRank算法[10]执行步骤的伪代码如下: 假设从每个点开始的概率都是相同的 Step1:初始化每个节点的初始概率值,如果对用户u进行推荐,则令u对应的节点的初始访问概率为1,其他节点的初始访问概率为0,然后再使用迭代公式计算. Step2:从用户u对应的节点开始游走,每到一个节点都以1-d的概率停止游走并从u重新开始. Step3:以d的概率继续游走,从当前节点指向的节点中按照均匀分布随机选择一个节点往下游走. Step4:经过很多轮游走之后,每个顶点被访问到的概率也会收敛,趋于某个稳定值. 对于PageRank来说,因为每个节点的初始访问概率相同,所以所有节点的初始访问概率都是1/n(n是节点总数).虽然随机游走模型考虑到用户的实际需求,但是却忽略了网页之间内容的相关性,容易造成主题漂移现象. 2.1 主题相似度 在当前的基于PageRank的改进算法中,杨武等[11]运用改进的空间向量模型,即TF-IDF公式,计算出存在链接关系的网页u和网页v分别关于词语ti的权值W′(i,u)和W′(i,v).将网页内容定义为向量空间模型中的向量,本文采用余弦向量度量法,从而计算出各微博在内容上的相似性.因此,相似度权值计算公式如式(4). (4) 在式(4)中,网页ui和网页vi的内容相似度权值,由W(ui,vi)表示;词语ti在网页u中的词项权值,由W′(i,u)表示;词语ti在网页v中的词项权值,由W′(i,v)表示. 利用计算公式(5),计算出网页内容相似度在公式(7)中所占的比重. (5) 在式(5)中,Wuivi表示用户vi在用户ui的所有出度中,内容相似度所占据的权重;Oui表示用户ui指向用户vi的集合,k∈Oui. 2.2 时间因子 一般地,用网页被搜索引擎搜索到的数目来表示网页本身存在的时间长短,针对PageRank算法中存在的偏重旧网页、忽视新的有价值网页的现象,论文结合时间反馈因子,计算公式如式(6). (6) 式(6)中,T作为网页被搜索引擎搜索到的周期次数.Wt为网页的时间反馈因子.e作为常数,它的取值为e=(1-d)/n,它与搜索引擎访问到的网页总数目n有关,还受到式(1)中d的影响.一般而言,搜索引擎的搜索周期是15~30d.假如一个网页在网络中存在的时间愈久,相应的,它在每个搜索周期里被访问到的概率愈大.换言之,单个网页的存在时间与搜索引擎访问到其的次数是成正比的. 2.3 改进的PageRank算法 本文提出了一种TSPR算法(TimeandSimilarityPageRankAlgorithm),将此算法运用到微博用户影响力排序中,观察排序结果.在研究微博用户影响力排序中,考虑到主题相似度和时间因子在计算PR值时所占比重不同.因此,引入比例系数α、β,且α+β=1.计算公式如(7). (7) 式(7)中,TSPR(ui)表示微博用户影响力计算的PR值.微博总数越大,用户之间的交互性越多,网页之间的相似度就越高,这在一定程度上避免了主题漂移问题.该算法结合时间反馈因子,攻克了提取网页发布时间的瓶颈,能更准确地判断网页不断更新的日期.网页PR值的大小受网页发布时间长短影响,这有利于旧网页沉淀、新网页迅速上浮.这有效地抑制了“僵尸用户”现象. 表1 用户数据统计情况 3.1 实验准备 由于新浪对微博做了爬虫设置,限制了一个小时内每个IP地址对它的访问量.调用官方API获得的数据噪声小,处理起来比较方便.本文采用新浪微博作为实验数据平台,结合广度优先算法和深度优先算法,一层一层的获取用户及用户之间的数据.其中新浪微博的各个模块共划分成12类主题,主要包括科技、体育、文化、天气、房地产、电影、教育、政治、生物、明星.本文是从2016年1月1日至当年的2月15日采集到的数据.将部分用户微博信息作为研究数据,数据包括用户集U,微博数据集Z,微博网页集θj,微博文本集X等.数据存储内容主要有: 1)用户信息:用户UID,用户昵称,性别,所在地,创建微博的时间,用户主页URL,粉丝数,关注数,微博数; 2)微博信息:微博MID,发布时间,微博内容,微博来源,转发数,评论数,被赞数,发表用户UID,微博所属主题; 3)收听关系:用户UID、粉丝ID; 4)关注关系:用户UID、关注ID. 由于新浪微博的限制,每个用户最多只能获取到200个关注人的信息,因此搜集到的好友关系不是很全面.把所有的搜集到的微博用户数据进行合并,并用爬虫工具简单清洗,去掉重复项.最终获得的用户数据统计情况如表1所示. 实验环境设置: 1)硬件方面:1台惠普服务器,3.4 GHz Intel i7-4790,1 TB硬盘和2台惠普 PC 3.6 GHz Intel 处理器,4 G内存,500 G硬盘. 2)软件方面:Win7操作系统,Matlab仿真工具,MySQL 5.5 数据库. 图1 参数值α的取值对微博用户查询结果前30项数据中位置P的影响Fig.1 The parameter valueα value impact on micro-blog query results before the 30 position in the P data 图2 改进前后的PageRank算法的精确度对比Fig.2 The accuracy comparison of the PageRank algorithm before and after the improvement 8大主题经典的PageRank算法WPR算法Timed-PageRank算法TSPR算法星座0.8200.8840.8900.940教育0.8300.9400.9000.970电影0.5410.5830.6240.660科技0.5160.5200.5400.560旅游0.5000.5120.5200.530汽车0.5400.5310.5290.563房地产0.6890.7240.7960.824美食0.6750.7280.7870.795 3.2 实验结果与分析 3.2.1 参数取值 初始化每个节点的初始概率值,则令初始访问概率为0.经过数据计算,当α=0.1,β=0.9时,即,用户主题相似度比重很小,时间因子的比重很大,此时,用户想要搜索到的微博用户之间的相似度小,时间周期长;反之,当α=0.9,β=0.1时,所要查找的微博用户比较靠前,但此时都是一些旧的微博用户,新用户的很少参与到影响力排序的结果中,因此,二者都达不到微博用户影响力的真实排序的目的.然而,当文章取α=0.6,β=0.4时,微博用户在查询结果前topk[12](在这里,k取30)中的位置P是最靠前的,从而求出比例系数的取值.实验对比结果如图1所示. 3.2.2 准确率对比 为了获得本文提出的相似度权值和时间因子等因素对改进型TSPR算法性能的影响,将文章改进型的TSPR算法与其他基于PageRank的相关算法作比较.例如:经典的PageRank算法、WPR算法[13]、Timed-PageRank算法[14],把这4种算法放在一起分别作对比.运用Matlab工具进行仿真实验.取搜索到的前600项数据作为标准结果集.对要查找的网页主题与实际查询到的网页进行相关性分析.本文利用查准率(又称为准确率)作为衡量查询结果的质量标准.由于用户习惯性关注前50页的查询结果,因此文章选择前50项作为样本,实验对比结果如表2所示. 通过仿真实验对比结果,发现改进的TSPR算法在各类主题的查询中,查准率均高于其他三类算法,各类主题相关的查全率均在50%以上.其中,关于星座、教育方面的查询率分别高达94%、97%,这是跟用户的行为习惯及用户经常进行话题互动紧密结合的;在科技、旅游等方面,用户很少进行交互活动,因此查询率也就相对较低.然而,TSPR算法与其他四种基于PageRake算法进行比较,均优于其他算法. 最后,经过随机抽样,对页面排序结果进行评价.为了均衡准确率和召回率两个评价指标,通过做实验的方法得知,当特征项的个数取值为10的时候,不仅运算量较小,而且查准率和召回率(又称为查全率)达到一个最优的效果,此时,准确率达到92.88%,召回率达到83.48%. 3.2.3 满意度调查 从计算机学院随机选择60名研究生对本文提出的TSPR算法进行满意度调查.对采集的结果采用评分制.非常满意得6分,比较满意得4分,感觉一般得2分.从图中可以看出,改良之后的PageRank算法的准确度比原始的PageRank算法高得多,从而证明了其优越性. 针对传统的PageRank算法本身存在的问题,文章提出了一种基于改进PageRank算法的微博用户影响力排序的研究方法.通过对相关主题权值和时间因子等因素进行分析计算,为用户影响力排序提供了一种参考方法.在不同主题的复杂因素的环境中将它与其他PageRank算法进行对比试验,通过数据计算比较,发现四种算法的准确率对比明显,改进后的算法计算出的用户影响力排序结果均优于现有的用户影响力相关改进算法,结果更加贴近现实,表明了TSPR算法的有效性和可行性. [1] CNNIC.Statistical Report on the Development of the thirty-seventh China Internet Network[R].Beijing:China Internet Network Information Center,2016:75-76. [2] 王德广,周志刚,梁旭.PageRank算法的分析及其改进[J].计算机工程,2010, 36(22):291-292. [3] 张凌宇, 陈淑鑫, 张光妲,等.一种基于向量空间模型的模糊本体映射方法[J].计算机应用研究,2014,31(5):1459-1462. [4] 张金鹏,黄贤英.基于语义的文本相似度算法研究及应用[D].重庆: 重庆理工大学, 2014. [5] WU G,WEI YM.Arnoldi versus GMRES for computing pageRank: A theoretical contribution to google′s pageRank problem[C]//Proceedings of the 4th ProQuest,USA IEEE,2012:192-199. [6] WENG J,LIM E P,JIANG J,et al.Twitterrank: finding topic-sensitive influential twitterers[C]//Proceedings of the third ACM international conference on Web search and data mining,ACM,2010:261-270. [7] WANG X T,HAO Z F.Analyzing the influence of social network users combined with the time factor[D]. Guangdong: Guangdong University of Technology,2015:15-41. [8] PENG W,WANG J,ZHAO B,et al.Identification of Protein Complexes Using Weighted PageRank-Nibble Algorithm and Core-Attachment Structure[J]. IEEE/ACM Transactions on Computational Biology & Bioinformatics,2015,12(1):179-192. [9] 曹姗姗,王冲.基于网页链接与用户反馈的PageRank算法改进研究[J].计算机科学,2014,41(12):179-182. [10] CHEN X,WANG P,QIN Z,et al.HLBPR: A Hybrid Local Bayesian Personal Ranking Method[C]// International Conference Companion on World Wide Web. International World Wide Web Conferences Steering Committee,2016. [11] 李稚楹,杨武.基于网页内容和内容反馈的网页排序PageRank算法研究[D].重庆:重庆理工大学,2012. [12] SILBERSTEIN A S,BRAYNARD R,ELLIS C,et al.A Sampling-Based Approach to Optimizing Top-k Queries in Sensor Networks[J].Icde,2013:68-68. [13] WANG C H,ZHU J P.Improved inequality transfer weight PageRank algorithm[J].Computer Engineering & Design,2010,31(10):2231-2230. [14] GANESH V.Timed PageRank and branching heuristics in CDCL SAT solvers[J].Banff International Research Station for Mathematical Innovation & Discovery,2014,24(1):11-29. 责任编辑:时 凌 Research on Ranking of Micro-blog Users′ Influence Based on Improved PageRank Algorithm DING Wenxue,XU Jiaxing,ZHU Haodong* (School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450002,China) Aiming at the shortcomings of the traditional PageRank algorithm,a kind of ranking method based on improved algorithm(TSPR) was proposed.In this algorithm, the time factor is used as the scale,the TF-IDF method is used to calculate the similarity between web pages,and the variation of the similarity between the users in a certain period of time is analyzed.By calculating the PR value of the Web page,micro-blog users′ influence is ranked.The simulation results show that the proposed algorithm can improve the ranking effect of micro-blog users and enhance the quality and accuracy of the search. PageRank algorithm;time factor;topic similarity;ranking of users′ influence 2016-08-11. 国家自然科学基金项目(61201447). 丁温雪(1988- ),女,硕士生,主要从事智能信息处理、模式识别研究;* 1008-8423(2016)03-0256-05 10.13501/j.cnki.42-1569/n.2016.09.004 TP301 A2 算法改进
3 实验

4 结束语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
电子制作(2018年10期)2018-08-04 03:24:38
儿童绘本(2018年5期)2018-04-12 16:45:32
电子制作(2017年2期)2017-05-17 03:54:56
自动化学报(2017年7期)2017-04-18 13:41:02
