
面向制造领域文本的多标签分类方法
2016-11-29 13:54王庆文
制造业自动化 2016年2期
杨 莹,王庆文
(北京航空航天大学,北京 100191)
面向制造领域文本的多标签分类方法
杨 莹,王庆文
(北京航空航天大学,北京 100191)
机械制造领域存在大量的领域知识,这些领域知识将特征项与文本类别关联起来,有助于区分文本的类别。基于此,本文提出一种融合领域知识的多标签分类方法旨在提高机械制造领域文本的分类性能,该方法首先采用融合领域知识的x2统计特征选择方法得到文本表示特征项集合和对应的相关度矩阵R,R反映了各特征项与类别的相关度;然后将文本是否包含某类别标签这一事件和文本与该类别的相关度关联起来,文本与该类别相关度视作特征项与该类别相关度的集聚,其相关度越大,文本包含该类别标签的概率也越大,统计文本各类别相关度的贡献率,根据最大后验概率准则推理文本类别标签集合。在3个多标签分类常用评测指标下的实验结果表明:与MLKNN方法进行对比,对于机械制造领域文本,融合领域知识的多标签分类方法具有更好的分类性能。
机械制造领域;领域知识;相关度;多标签;文本分类
0 引言
随着互联网和信息技术的快速发展,互联网数据量剧增,有研究表明,文本信息这一类非结构化数据占了互联网数据的50%以上,因此,对文本信息的处理显得尤为重要。文本分类是对文本进行有效管理的一种方式,方便用户进行查询、定位信息等,同时文本分类也是信息检索,信息过滤,数据挖掘等相关领域的技术基础[1]。机械制造领域研究的内容非常广泛,包括材料分析,制造加工,车间管理调度,机构设计应用,检测监控等,各研究内容不完全独立,存在着交叉研究,因此对机械制造领域的文本进行分类时,文本可能包含多个类别标签。基于此,本文将对面向机械制造领域文本的多标签分类问题展开研究。
目前多标签文本分类问题的解决方法主要有两种:问题转换法和算法适应法[2]。问题转化法的思想是首先根据一定的规则将多标签问题转化为一个或多个单标签问题,然后利用单标签学习算法进行处理。算法适应法则是通过扩展单标签学习算法来适用于多标签学习问题,无需将多标签文本转化为单标签问题。张敏灵提出了一种基于K近邻的多标签文本分类方法:MLKNN,该方法是一种典型的算法适应法,使用K近邻方法统计近邻样本的类别标签信息,通过最大化后验概率的方法推理待分类文本的标签集合[3]。与其他多标签分类方法相比,MLKNN方法具有无需学习,实现简单,分类性能好的特点,为此,许多学者在其基础上展开了进一步研究。张敏灵后来针对MLKNN未考虑标签间的相关性的不足提出一种新型多标记懒惰学习算法IMLLA,这种方法在对文本每个类别进行预测时利用了蕴含于其他类别中的信息,充分考察了多个标签的相关性[4]。Ruben Nicolas提出了一种基于案例推理学习的多标签分类方法MLCBR,MLCBR基于案例推理学习近邻样本标签重用概率的阈值,使用近邻样本标签的分布概率推理文本的类别标签集合,与MLKNN相比,其算法复杂度低且分类性能相当[5]。Everton AlvaresCherman采用MLKNN方法进行多标签分类时,不仅考虑样本的K近邻标签集合还考虑近邻样本的K近邻标签集合用于推理样本的标签,与原始的MLKNN方法相比,其方法的准确率有进一步的提高[6]。
目前采用的多标签分类方法基本都是基于机器学习的思想。根据经验,有些专业词汇具有明显的类别倾向性,是判断文本类别的重要依据,如:当文本中大量出现“云制造”、“制造服务”这些词语时,我们很容易将文本联想到制造工程这一类别。我们称“云制造”和“制造服务”包含的行业内流通度高、众所周知、与具体类别相关的语义知识为领域知识[7],显然领域知识有助于文本分类。在实际应用中,往往由于样本集的有限性,机器学习不能将特征项的领域知识都学习出来用于分类,在机械制造领域,存在着大量的领域知识。基于此,本文提出一种融合领域知识的多标签分类方法旨在进一步提高机械制造领域文本的分类性能。
1 融合领域知识的多标签文本分类方法
1.1特征选择
特征选择一般采用机器学习的方法,其步骤是构造特征项的评估函数,依据评估函数计算每个特征项的权重,权重越大表示特征项区分文本类别的能力越强,特征项被选择的可能性也越大,按照权重降序排列,确定阈值,选取排名满足条件的特征项表示文本,常用的特征选择方法有:文档频率,信息熵,互信息和X2统计等。本文采取的特征选择方法将领域知识和机器学习结合起来。
有研究结果指出X2统计方法的降维效果比较好[8],本文首先选择X2统计作为特征选择的方法,其计算方法如下所示:

其中,N表示文本总数,A表示包含类别标签ck和特征项wi的文本数量,B表示不包含类别标签ck但包含特征项wi的文本数量,C表示包含类别标签ck但不包含特征项wi的文本数量,D表示不包含类别标签ck和特征项wi的文本数量。考虑到B=C=0时,式(1)取得最大值N,将式(1)进行归一化处理,χ2统计值的计算公式变换为如下所示:

特征项wi与类别ck的相关程度包含正相关和负相关两种情况,由原始公式(1)的数学意义可知,当ADBC>0时,特征项wi与类别ck呈正相关,此时wi的出现使得文本倾向于包含类别ck,x2(wi,ck)值越大,这种倾向性越明显;当时AD-BC≤0,特征项wi与类别ck呈负相关,此时wi的出现使得文本倾向于包含类别ck以外的标签,包含类别ck的倾向性则为最小值0。因此,将特征项wi与类别ck的正负相关性考虑进去,将式(2)变换为如下所示:
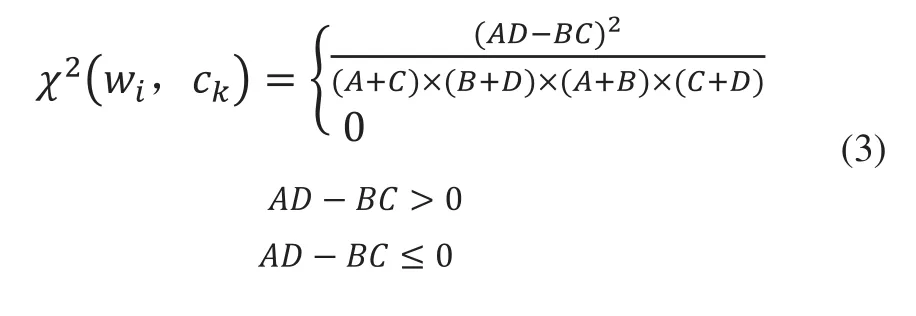
式(3)中,x2(wi,ck)取值范围为[0,1],对于多类问题,通常首先计算特征项wi对于每个类别的x2统计值,将其表示为x2统计列向量x2(wi)=(x2(wi,c1),…,x2(wi,ck),…,x2(wi,cm)),m为数据集的类别标签总数,然后取列向量x2(wi)中值最大的元素作为特征项wi的x2统计值x2(wi)value,即:
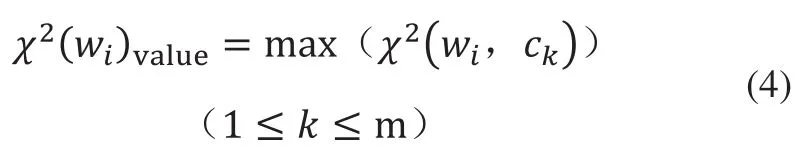
确定排名阈值α,将所有特征项的x2统计值x2(wi)value按降序排列,选择排名为α和α之前的特征项用于表示文本,则文本表示特征项集合为W'=(w1',w2',…,wi',…,wα')。
对于机械制造领域文本,由于数据集样本数量有限,有些词汇只是集中出现在某一类别的少量文本中,根据式(3)可知,这些词汇的x2统计值较小,与文本类别的相关度较小。然而根据经验,这类词汇很可能包含领域知识,与某类别相关度较大,有助于文本分类。除此之外,还有一些专业词汇未出现在数据集中,一般这些词汇不会作为文本表示特征项,然而当待分类文本包含这些特征项并且这些特征项包含领域知识时,这些词汇能够有效地的区分文本类别。基于此,本文提出一种融合领域知识的特征选择方法,在x2统计方法的基础上融合领域知识选择出有助于文本分类的特征项,领域知识的融合主要体现在以下两个方面:
1)修改出现在数据集中的特征项的x2统计值列向量x2(wi)。对于那些出现在数据集中,并且包含领域知识的特征项,根据经验修改该特征项的x2统计值列向量x2(wi),向量中每个元素的取值范围为[0,1],值越大表示特征项与某类别的相关程度越大;
2)增加未出现在数据集中,但是包含领域知识的特征项。根据经验构造这些特征项的x2统计值列向量x2(wi),向量中每个元素的取值范围为[0,1],值越大表示特征项与某类别的相关程度越大;
最后,根据阈值α得到表示文本的特征项集合W=(w1,w2,…,wi,…,wα),集合W中的每一个特征项对应一个x2统计列向量x2(wi),这些列向量形成了一个相关度矩阵R=(x2(w1),x2(w2),…,x2(wi),…,x2(wα)),R反映了各特征项与类别的相关度。与x2统计方法相比,融合领域知识的特征选择方法增加和修正了特征项的x2统计向量,从而更加准确的反映了特征项与各类别的相关度,有助于区分文本的类别。
1.2多标签分类方法
领域知识一般将特征项与文本的类别关联起来,因此本文提出融合领域知识的多标签分类方法基本思想是将文本是否包含类别标签ck这一事件和文本与类别ck的相关度关联起来,根据最大化后验概率推理文本是否包含类别标签ck。
首先引入相关符号和定义:给定文本X及对应的类别向量C(X)。文本X表示为向量X=(x1,x2,…,xi,…,xα),xi对应特征项集合W中的一个特征项wi,表示wi在文本X中出现的频率;C={c1,c2,…,ci,…,cm}表示数据集的类别标签集合;C(X)=(C(X,c1),C(X,c2),…,C(X,ci),…C(X,cm))表示文本X的类别向量,类别标签ci对应C(X,ci),如果文本包含标签ci则C(X,ci)=1,否则C(X,ci)=0;ξ(X,ck)表示文本X与类别ck的相关度。
1.2.1相关度计算
本文将文本X与类别ck的相关度看作是各特征项与类别ck的相关度的集聚,那么ξ(X,ck)的计算方法可由式(5)表示:

其中xi表示特征项wi在文本X中出现的频率,x2(wi,ck)表示特征项wi与类别ck的相关度。由上文可知,x2(wi,ck)是相关度矩阵R中的一个元素,根据式(3)计算或经验知识确定。
对于不同的文本,由于其篇幅的不同,文本中各特征项的频率具有较大的差异,由式(5)可知,包含类别标签ck的不同文本与类别ck的相关度差异较大。本文引入类别相关度贡献率δ(X,ck)这一定义,将文本与类别ck的相关度归一化处理,用来衡量不同的文本与各类别相关度的大小,其计算方法如下:
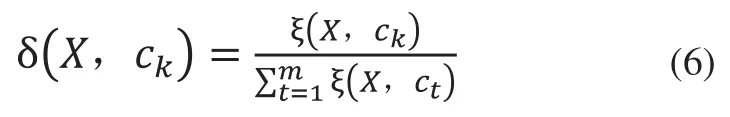
其中ξ(X,ck)表示文本X与类别ck的相关度,表示文本X与各类别标签的相关度之和。δ(X,ck)的取值范围是[0,1],δ(X,ck)越大,文本包含类别标签ck的概率越大,否则文本包含类别标签ck的概率越小。
1.2.2多标签分类

根据贝叶斯法则可得:


其中N表示训练集文本数量总和,N(ck)表示包含标签ck的文本数量,N'(ck)表示不包含标签ck的文本数量,N(ck,s)表示包含类别标签ck且类别ck相关度贡献率小于s的文本数量,N'(ck,s)表示不包含类别标签ck且与类别ck相关度贡献率大于或等于s的文本数量。
根据上述分析,融合领域知识的多标签文本分类方法的具体实现步骤可由图1表示。
2 实验结果与分析
为了验证分类方法的有效性,实验中建立制造领域数据集作为实验库,该数据集包含六个类别:材料工程,动力学,机构,机器人,仪器科学与技术和制造科学与技术。语料库中总共有970个样本,其中约10%的样本包含多个类别标签。
本文将MLKNN作为对比算法,采用多标签文本分类中常用的3个评测指标[9](汉明损失,准确率,召回率)比较两种分类方法在制造领域文本数据集上的性能。汉明损失考察的是文本预测分类结果与实际分类结果的差异,评估了预测标签错误的次数;准确率考察的是文本预测标签属于文本实际标签的情况,评估了预测标签的平均准确度;召回率考察的是文本预测分类结果与实际分类结果相符的情况,评估了预测标签的平均查全率。

图1 融合领域知识的多标签文本分类算法
【】【】

表1 本文方法与MLKNN性能比较
由表1可以看出,对于评测指标汉明损失、准确率和召回率,与MLKNN相比,本文方法具有较明显的优势。因此,本文提出的融合领域知识的多标签文本分类方法对于制造领域文本具有较好的分类性能。
3 结论
机械制造领域存在大量的领域知识,这些领域知识将特征项与文本类别关联起来,有助于区分文本的类别,基于此,本文提出了一种融合领域知识的多标签文本分类方法。该方法将文本是否包含某类别标签这一事件和文本与该类别的相关度关联起来,在进行特征选择时,充分利用已有的领域知识增加和修正衡量特征项与类别相关程度的x2统计向量,从而选择出更为准确,具有代表性的特征项表示文本。实验结果表明,与MLKNN多标签文本分类方法比较,对于机械制造领域文本,本文方法的总体分类性能更优。
[1] 周浩.中文多标签文本分类算法研究[D].上海交通大学,2014.
[2] Tsoumakas G,Katakis I,VlahavasI.Mining Multi-label Data. Data Mining and Knowledge Discovery Handbook[M]. Maimon O, RokachL.2nd ed.Springer,2010:667-685.
[3] Zhang Minling, Zhou Zhihua. ML-kNN:A lazy learning approach to multi-label learning[J].Pattern Recognition,2007(7):2038-2048.
[4] 张敏灵.一种新型多标记懒惰学习算法[J].计算机研究与发展,2012,11:2271-2282.
[5] Ruben Nicolas,Andreu Sancho-Asensio, ElisabetGolobardes, Albert Fornells, Albert Orriols-Puig, Multi-label classification based on analog reasoning[J].Expert Systems with Applications, 2013(40):5924-5931.
[6] Everton AlvaresCherman.Lazy Multi-label Learning Algorithms Based on Mutuality Strategies[J].Intell Robot Syst,2014(10):1007-1022.
[7] 朱靖波,陈文亮.基于领域知识的文本分类[J].东北大学学报,2005,08:733-735.
[8] 庞观松,蒋盛益.文本自动分类技术研究综述[J].情报理论与实践,2012,02:123-128.
[9] Tsoumakas G.Multi-label classification[J].International Journal of Data Warehousing&Mining ,2007(3):1-13.
A multi-label classification method for manufacturing-text
YANG Ying, WANG Qing-wen
TP391.1
A
1009-0134(2016)02-0010-05
2015-10-14
国家科技重大专项:汉川机床采用国产数控系统加工大型机床零件应用示范工程(2012ZX04011-011)
杨莹(1992 -),女,江西樟树人,硕士研究生,研究方向为企业信息化。
猜你喜欢
少儿画王(3-6岁)(2020年4期)2020-09-13
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
西夏学(2016年2期)2016-10-26
智能系统学报(2015年4期)2015-12-27
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
浙江大学学报(工学版)(2015年1期)2015-03-01
