
基于主分量分析的苹果叶部3种常见病害识别方法
2016-11-28 16:03师韵王旭启张善文
江苏农业科学 2016年9期
师韵+王旭启+张善文
摘要:苹果叶部的3种常见病害(斑点落叶病、花叶病和锈病)严重影响苹果的产量和质量。病害识别是病害防治的基础,传统的苹果病害识别方法不能有效选择病害的分类特征。基于主分量分析算法,提出一种叶片颜色、形状和纹理特征相结合的苹果病害识别方法。首先对苹果病害叶片图像进行预处理,降低图像干扰;然后利用改进的分水岭方法分割病斑,提取病斑图像的颜色、形状和纹理特征,组成特征矩阵;再利用主分量分析(PCA)对该矩阵进行维数约简,得到低维分类特征;最后利用BP神经网络识别苹果的3种病害类型。结果表明,该方法能够有效识别苹果的3种病害,平均识别率超过94%。
关键词:苹果病害识别;特征提取;主分量分析(PCA);BP神经网络
中图分类号: S126; TP391. 41 文献标志码: A
文章编号:1002-1302(2016)09-0337-04
苹果含有丰富的碳水化合物、维生素、微量元素和果胶等,是世界水果中产量和消费以及益处最多的水果之一。但是,苹果病害严重影响了苹果的产量和质量[1-3]。当前,西部广大果农病害防治技术水平不高,防治粗放,农药乱配滥用现象比较普遍,造成果品农药残留超标,果品质量下降,且防治成本大。要防治苹果病害,首先要识别病害类型[4-8]。叶片是很容易观察、采集和处理的部位,也是一般苹果病害症状首先出现的部位。因此,多年来苹果叶片症状是果农和植保人员诊断病害的重要依据之一。目前苹果病害诊断大多采用经验定性诊断方法。该方法的主观性较强,对专家的依赖性较高,容易混淆症状相似的病害。为了准确识别病害,计算机图像处理是一种很好的方法,但由于苹果病害种类多,病害叶片形状及叶片病斑的颜色、纹理和形状的差异性大,呈现出复杂、多样、无规则的特点,使得目前很多病害识别方法的效果不理想[5,9-11]。
本研究提出一种基于主分量分析(PCA)的苹果病害叶片的颜色、形状和纹理特征相结合的苹果病害识别方法,该方法综合提取苹果病害叶片图像的多种分类特征,然后利用PCA进行维数约简,再利用BP神经网络进行训练,实现对苹果病害的快速分类识别。
1 材料与方法
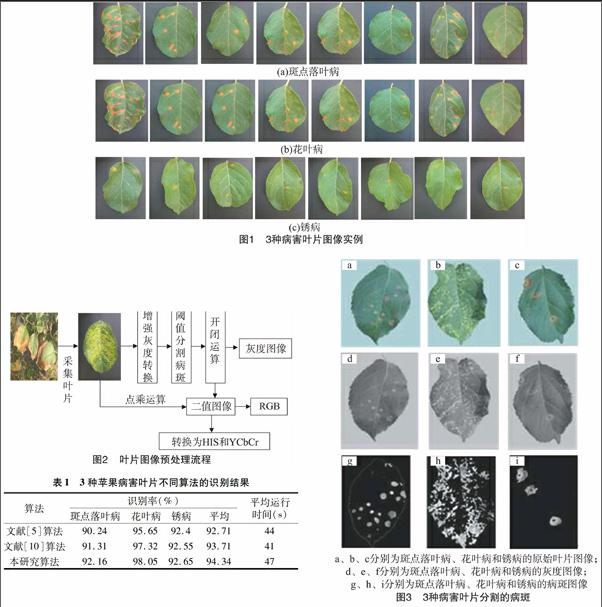
为了研究基于苹果病害叶片图像处理的苹果病害识别的方法,选用了3 种易混淆的常见苹果病害:斑点落叶病、花叶病和锈病为研究对象。苹果斑点落叶病危害叶片,造成早落,叶片染病初期出现褐色圆点,其后逐渐扩大为红褐色;苹果花叶病主要在叶片上形成环斑型、狼斑型等各种类型的鲜黄色病斑;苹果锈病叶片初患病正面出现油亮的橘红色小斑点,逐渐扩大,形成圆形橙黄色的病斑,内含大量褐色粉末状锈孢子。肉眼不容易区分斑点落叶病和锈病2种病害。本研究所使用的这3种苹果病害叶片图像均是在西北农林科技大学苹果园利用佳能EOS 700D单反数码相机在上午10:00—11:00时间段采集得到。为了便于后续处理,以灰色纸片作为背景色,在自然光照的非强光条件下对自然发病的苹果叶片进行活体图像采集,得到苹果病害叶片数字图像。拍摄时尽量使相机的镜头与苹果叶面所在的平面平行,使光线在苹果叶片上均匀分布,避免产生明显的形变。为了使测量准确,每次采集叶片图像时,尽量使苹果叶片充满整个画面。由于拍摄环境的影响,采集到的有些叶片图像难免存在阴影和大量噪声。因此,在采集到的数字叶片图像中挑选出光照较均匀的图像各50幅作为试验的样本图像。图1为试验中采集到的苹果常见3种病害叶片图像实例,图像格式为BMP,图像宽度为320像素、高度为240像素。
2 苹果病害叶片图像预处理
苹果病害叶片图像的质量直接影响后续的病害识别率。在叶片图像采集过程中,由于受到采集设备、环境等影响,图像存在分辨率低、背景复杂、病斑边缘模糊等特点。所以,需要对病害叶片图像进行预处理。常用的病害叶片图像预处理操作有图像格式转化、图像去噪、图像增强、削弱图像中颜色、叶柄、虫洞等无用或干扰信息,使病斑区域的特征更明显。为了有效去除噪声,较好地保留图像的细节并突出病斑特征,在试验对比的基础上,首先选用自适应直方图均衡化方法,扩展叶片图像灰度范围,对叶片图像进行对比度增强,然后选用叶片彩色图像中值滤波方法,即在叶片图像的R、G、B通道上分别应用中值滤波方法滤波后,再进行通道融合,得到滤波后的彩色图像,较好地抑制叶片图像的噪声,保留叶片图像的分类信息。再利用Top-Hat方法与归一化彩色空间法相结合,可使不同光照度下所采集的叶片图像的R、G、B通道数据处理结果差异很小,以此降低图像亮度对色彩的影响。图2为叶片图像预处理流程。
3 苹果叶片图像病斑分割
病斑图像分割是病害叶片图像分析与模式识别中一个重要的环节,病斑分割的好坏直接影响后续特征提取与识别结果。本研究的对象是自然环境下拍摄的苹果病害叶片图像,背景复杂、分辨率低,不能直接用于病害分类特征提取[3,10-11]。因此,采用改进的水平集彩色图像分割方法,即基于区域和边缘的变分水平集彩色图像分割方法[12-13]。该方法充分利用了目标图像的区域信息和边缘信息,并用欧氏距离代替了灰度加权值,使得彩色图像的颜色空间信息得到充分利用。首先,用N1个水平集函数将图像分割成N(N﹥1)个区域,每个水平集函数代表1个分割区域,通过建立独立多水平集函数可以消除冗余的轮廓,从而避免分割区域的重叠和漏分,获得更加精确的颜色边缘。为了避免水平集函数在每次迭代后需重新初始化符号距离函数,增加的能量惩罚项能使水平集函数在演化过程中保持为逼近的符号距离函数。再将分割的病斑归一化图像转化为灰度图。最后,采用形态学中的开运算和闭运算处理,得到不受叶片虫洞和叶柄等影响的二值化图像。3种苹果病害叶片原图与病斑分割结果如图3所示。
4 特征提取
由于苹果病害叶片的病斑图像复杂、多样、无规律,且随时间而变换,不能用数学模型来表示[14]。很多基于图像维数约简的人脸、掌纹和步态等识别方法不能用于苹果病害识别。由于不同类型病害叶片的病斑图像的颜色、形状和纹理之间存在差异,可以提取病斑图像的分类特征,构成特征向量,进行病害识别。下面介绍从分割后苹果病斑图像中提取病害的颜色、形状和纹理的分类特征计算方法[9,11,15-16]。
4.1 颜色特征
由RGB颜色模型转换到HIS和YCbCr颜色模型,利用归一化直方图的统计特征分别计算颜色R、G、B、H、I、S、Y、Cb和Cr的均值、方差、偏度、能量、熵等5个统计特征参数,作为病害叶片图像分类的颜色特征。
4.2 形状特征
计算病害叶片病斑图像的面积、周长、周长直径比、周长长宽比、圆形度、纵横轴比等6个无量纲的量,作为病斑图像的形状分类特征,具体如下:
由以上分析可以得到每幅病斑图像的45个颜色特征、6个形状特征和4个纹理特征,由此组成一个维数为55的特征向量。
5 基于主分量分析(PCA)的苹果病害识别
尽管可以提取病斑图像的很多分类特征,但这些特征之间可能存在相关性,而且各个特征对病害分类的贡献大小不同,一些特征可能降低病害的识别率。所以,需要对得到的众多特征进行特征提取或维数约简。但当特征维数较大时,不容易快速地提取出对分类结果贡献大、独立、不相关的特征。
主分量分析(PCA)考虑了各个特征之间的相互关系,利用维数约简的思想,在损失很少信息的前提下将多个特征转换为少数几个互不相关的特征,成为主成分。每个主成分均是原始变量的线性组合,且各个主成分之间互不相关,这就使得主成分比原始变量具有某些更优越的性能,从而进一步使病害类型识别过程变得简单、快速、准确[17]。
主成分分析常常通过以下5步解决:
第1步,将提取的特征进行标准化处理,以消除各个特征在数量级或量纲上对后续分类结果的影响。
第2步,将训练集中每个病斑图像标准化后的特征组成1个特征向量,再将所有的特征向量组成1个特征矩阵,计算相关系数矩阵。
第3步,计算特征矩阵的特征值及对应的单位特征向量。特征值在某种程度上可以看成表示主成分分类力度大小。如果特征值小于1,说明该主成分的解释力度还不如直接引入原变量的平均解释力度大。因此一般可以用特征值大于1作为纳入标准。
第4步,计算主成分的方差贡献率和累积方差贡献率。一般来说,提取主成分的累积方差贡献率超过85%就可以,由此确定需要提取多少个主成分。
第5步,计算主成分。由具有最大特征值的特征向量构成映射矩阵。大量实际情况表明,如果根据累积贡献率来确定主成分个数往往较多,而用特征值来确定又往往较少,很多时候应当将两者结合起来,以综合确定合适的个数。
由以上分析,可以归纳出PCA的苹果病害识别的过程为:
(1)对苹果病害叶片图像进行预处理;(2)对病害叶片图像分割,得到病斑图像;(3)提取病斑图像的颜色、形状和纹理特征,进行归一化处理,得到特征向量矩阵,再构造特征矩阵;(4)利用PCA得到主分量,构造映射矩阵A;(5)由A对待识别的病斑的特征向量进行维数约简;(6)利用BP神经网络分类识别病害类型。
BP神经网络分类器包括输入层、隐层和输出层。输入层神经元个数由叶片病斑特征矩阵主分量的个数决定,输出层神经元个数为病害类别数。试验时需要人工设定BP神经网络的隐层个数、隐层神经元数量和学习率等参数。待识别的病斑图像进行预处理、特征提取、基于PCA的维数约简等步骤后得到待分类低维向量,再输入训练好的BP神经网络分类器可得到病害识别结果。
6 验证试验
为了验证所提出的方法的有效性,对常见的3种苹果病害斑点落叶病、花叶病和锈病的叶片图像数据库上各50幅叶片图像进行病害识别试验。每种病害叶片的前30 幅,共90 幅作为训练样本,其余的60幅作为测试集,依次编号。对所有叶片图像进行预处理和病斑分割,然后提取每幅苹果图像的颜色、形状和纹理等共55个特征值,组成特征向量;由所有训练集中的特征向量组成1个60×55的特征矩阵A;利用统计产品与服务解决方案软件(Statistical Product and Service Solutions,SPSS)中的PCA过程:“分析→降维→因子分析”,求A的协方差矩阵,取前M个特征值所对应的特征向量,构成一个55×M的矩阵B,这个矩阵为映射矩阵,A乘以B,就得到了1个60×M的新的降维后的低维矩阵C,作为BP分类器的训练集数据。由B可以得到任一待识别病害叶片的病斑图像的低维特征向量,输入BP分类器,进行类别识别。试验中采用Matlab软件进行BP神经网络训练。在利用训练数据集训练BP神经网络前,先将训练数据C进行归一化处理,以避免数据饱和,加快网络收敛。网络训练的输出目标矩阵大小为1×60,每个元素分别对应于60个输入样本的类别。训练BP神经网络,直至总误差小于给定值,认为网络训练完毕。本试验中,PCA的主分量数取为10,其累计方差贡献率在90%以上。BP分类器的误差取为0.001,试验重复进行50次,计算识别结果的平均值,试验结果见表1。为了说明本研究算法的有效性,与文献[5]和[10]的苹果叶片病害识别方法进行比较。这2种方法都是提取分类特征和Hu提出的7个不变矩,再分别利用BP神经网络和支持向量机进行病害识别。表1中给出了3种算法的识别结果。
试验结果表明,在3种苹果病害识别中,本研究算法的平均识别率达到94.34%,高于其他2种算法,其中苹果花叶病的识别率超过98%。
7 讨论与结论
文献[5]应用二值图像标记法提取病斑边缘,计算出病斑个数、面积、圆形度、与叶片面积比、复杂度和叶子的面积等6个形状特征参数,以及Hu的7个不变矩共13个参数,再利用BP神经网络进行识别;文献[10]提取病害叶片病斑图像的颜色直方图、颜色矩、灰度共生矩阵、常规形状和Hu的7个不变矩等特征,并对提取特征进行比较,选择了15类特征参数,再利用支持向量机进行识别。这2种方法没有考虑提取的特征对病害分类的贡献大小。而本研究算法提取55个特征,不是进行特征选择,而是利用PCA快速得到主分量,再在新的低维特征空间进行识别。所以,该方法适用于提取很多特征情况下,而且考虑了各个特征的重要程度。
3种算法对斑点落叶病的识别率都比较高,是因为该病害的特征与另外2种病害叶片的区别较大。出现错分的原因是斑点落叶病与早期的锈病病斑很像,只是颜色有所差异,在纹理特征和形状特征方面很相近,而文献[5]中没有选用颜色特征,所以识别率不高。
本研究利用SPSS进行PCA。由于在SPSS中并没有完整的主成分分析过程,其主成分分析过程集成在因子分析过程中,但并不完善。而主成分的得分需要对因子得分情况进行进一步计算,所以在SPSS中不需保存因子得分情况。对于提取因子的个数问题,一般遵循2个标准,一是累计方差贡献率大于80%;二是其特征值大于1。本试验中之所以设置因子数目为10,是因为通过预先分析,发现前10个主成分可以解释总体信息的99%。
本研究探讨了苹果病害叶片图像预处理、病斑分割、病害特征提取和特征降维方法,分析了基于BP神经网络的病害识别过程。训练后BP神经网络可实现对苹果的斑点落叶病、花叶病和锈病3种病害识别,平均准确率达到94.33%。试验结果表明,该算法对苹果叶部病害识别是可行的。进一步的研究重点是基于农业物联网视频传感器得到的苹果病害叶片图像分割和病害识别方法。
参考文献:
[1]胡 林,周国民,丘 耘. 苹果树图像分割算法研究综述[J]. 中国农业科技导报,2015,17(2):100-108.
[2]郝青梅. 苹果树常见病害识别和防治[J]. 河北果树,2010(6):12-14.
[3]尹秀珍,何东健,霍迎秋. 自然场景下低分辨率苹果果实病害智能识别方法[J]. 农机化研究,2012(10):29-32.
[4]薛永发. 农业生态控制苹果病虫害的有效途径和措施[J]. 果农之友,2010(11):26-28.
[5]李宗儒. 基于图像分析的苹果病害识别技术研究[D]. 杨凌:西北农林科技大学,2010
[6]李宗儒,何东健. 基于手机拍摄图像分析的苹果病害识别技术研究[J]. 计算机工程与设计,2010,31(13): 3051-3053.
[7]霍迎秋,唐晶磊,尹秀珍,等. 基于压缩感知理论的苹果病害识别方法[J]. 农业机械学报,2013,44(10):227-232.
[8]樊景超. 苹果果实病害近红外光谱信息获取与识别模型研究[D]. 北京:中国农业科学院,2011.
[9]王芸芸,王 玺,蒋建兵,等. 山西省苹果树主要病虫害的种类及综合防治[J]. 现代园艺,2014(15):117-118.
[10]毕傲睿. 苹果叶子病害图像识别系统的设计与实现[D]. 西安:西安建筑科技大学,2014.
[11]胡荣明,魏 曼,竞 霞,等. 基于成像高光谱的苹果树叶片病害区域提取方法研究[J]. 西北农林科技大学学报:自然科学版,2012,40(8):95-99.
[12]方江雄. 基于变分水平集的图像分割方法研究[D]. 上海:上海交通大学,2012.
[13]毛 亮,薛月菊,孔德运,等. 基于稀疏场水平集的荔枝图[J]. 农业工程学报,2011,27(4):345-349.
[14]Valliammal N,Geethalakshmi S N. Crop leaf segmentation using nonlinear K means clustering[J]. International Journal of Computer Science Issues,2012,9(3):212-218.
[15]Pydipati R,Burks T F,Lee W S. Identification of citrus diseaseusing color texture features and discriminant analysis [J].Computers and Electronics in Agriculture,2006,52:49-59.
[16]贾建楠,吉海彦. 基于病斑形状和神经网络的黄瓜病害识别[J]. 农业工程学报,2013,29(增刊1):115-121.
[17] Wang H,Li G,Ma Z,et al. Image recognition of plant diseases based on principal component analysis and neural networks[C]. Natural Computation (ICNC),2012 Eighth International Conference on IEEE,2012:246-251.
猜你喜欢
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
