
应急响应处理流程
2016-11-26 09:08
网络安全和信息化 2016年7期
应急响应研究领域目前最被广为接受的流程是PDCERF方法学,该方法学将应急响应整个流程划分为准备(Preparing)、检测(Detection)、抑制(Control)、根除(Eradicate)、恢复(Restore)和跟进(Follow)六个阶段。在实际应急响应过程中,也不一定严格存在这六个阶段,也不一定严格按照这六个阶段的顺序进行,但是PDCERF是目前适应性较强的应急响应的通用方法学。下面结合一个实际案例,对这六个阶段分别予以介绍。
案例背景
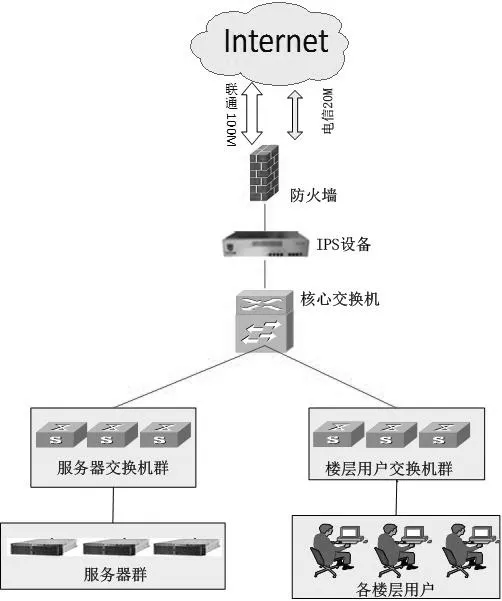
图1 公司内部网络架构图
某公司自有数据中心拥有近百台服务器,服务器上部署有各类业务系统提供给用户使用,其中部分服务器与Internet隔离,仅仅为内部用户提供服务,而另外一部分服务器则利用NAT端口映射技术开放给外部用户使用。为保障Internet接入的稳定性,公司引入了联通和电信两条Internet线路,其中联通线路带宽为100Mbps,属于主用线路;电信线路带宽为20Mbps,属于备用线路。公司对于信息安全十分重视,不仅在Internet出口网关处部署了防火墙(Juniper ISG2000)、IPS(启明星辰NIPS-3060)等安全设备,以防范来自Internet的网络安全威胁,而且对于内网的管控也相当严格,员工电脑都安装了企业级杀毒软件,而且在全网范围内部署了准入控制相关产品,不符合安全策略的主机将无法接入网络。同时,员工办公电脑的USB接口、光驱等都被禁止使用,以防U盘、光盘等外来介质给内网带来病毒感染的威胁。整个公司内部网络架构是典型的“核心—汇聚—接入”三层架构,如下图1所示。
为了保障业务连续性,提升信息安全应急响应能力,公司内部参照PDCERF流程建立了较为完善的信息安全应急响应机制,范围包含服务器、网络、业务系统等多个方面。本文以“服务器遭受DDoS拒绝服务攻击”事件为例,来介绍该公司的应急响应流程。
准备阶段
准备阶段是信息安全事件响应的第一个阶段,即在事件真正发生前为事件响应做好准备。这一阶段极为重要,因为事件发生时很可能需要在短时间内处理较多的事务,如果没有做好足够的准备工作,那么将很难及时地完成响应工作。该公司在攻击事件发生前,做了相应的准备工作,主要有如下几点。
1.为防止病毒的侵害,该服务器安装了卡巴斯基企业版杀毒软件,并定时自动升级病毒库。
2.为防止业务数据的丢失,每天晚上都会通过自动备份软件,将服务器上的数据备份到异地的备份服务器上。
3.由于该服务器发布 在 Internet上,为 防止来自Internet的网络攻 击,在 Internet出 口网关处部署了防火墙和IPS,配置了相对严格的Untrust -> Trust区域的访问控制策略,同时保证IPS设备的特征库定时更新,以抵御更多种类的网络攻击。
4.建立了针对服务器遭受攻击时的应急响应预案,每半年组织相关人员开展一次应急演练活动。
5.建立支持安全事件响应活动的管理体系,为应急响应提供足够的资源和人员。公司成立了信息安全应急响应处理小组,由IT部门负责人出任组长,负责协调人员和资源。其他组员则各司其职,根据平时所维护的范围,承担对应设备和系统的应急响应工作。
检测阶段
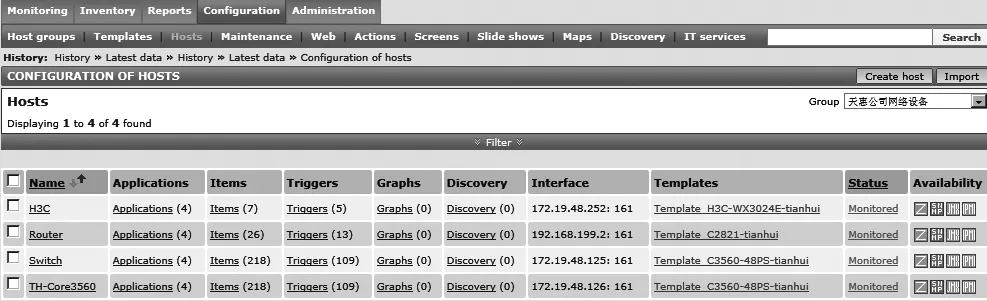
图2 Zabbix网络监控平台示意图

图3 IPS设备日志
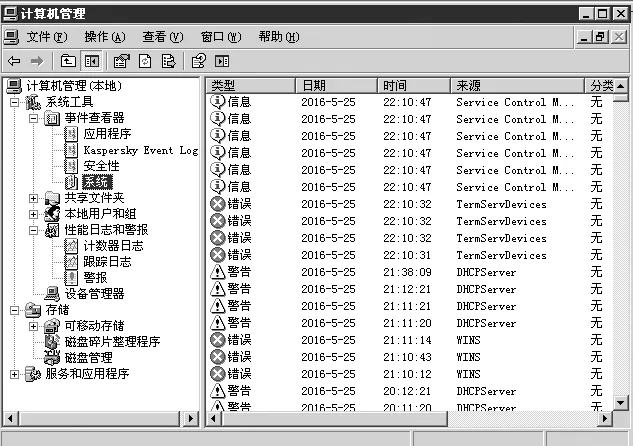
图4 Windows服务器日志检查
检测是指以适当的方法确认在系统或者网络中是否出现了恶意代码、文件和目录是否被篡改等异常现象。如果可能的话,同时确定它的影响范围和问题原因。
从操作角度来讲,事件响应过程中的后续阶段都依赖于检测,如果没有检测,就不会存在真正意义上的事件响应。检测阶段同时也是事件响应的触发条件。该公司日常采取的检测手段如下。
1.利用Zabbix网络监控系统对设备及服务器进行自动实时状态监控,如果目标出现状态异常,如CPU利用率过高、网络服务中断等,则会以邮件和短信的方式向管理员报警(如图2)。
2.每周管理员会提取防火墙和IPS设备上的日志,对整体运行情况进行汇总分析,及时发现安全隐患点并及时整改(如图3)。
3.服务器日志检查。管理员每天登录服务器,检查事件查看器中的系统和安全日志信息,如安全日志中异常登录时间、未知用户登录等,同时检查%WinDir%System32LogFiles目录下的相关日志,分析是否有异常行为发生(如图4)。
4.进程检查。管理员每天登录服务器,检查是否存在未被授权的应用程序或服务正在运行。可以通过服务器上的Windows任务管理器检查当前运行的进程(如图 5)。
5.网络连接检查。如果在应用和服务的层面上无法检测出问题,则需要对网络层面进行检查,可以利用netstat -an命令检查网络连接以及端口开放情况(如图 6)。
某天,网络管理人员突然收到Zabbix报警短信,提示某业务服务器网络丢包严重,丢包率高达40%,业务人员也反映系统查询、更新等操作特别缓慢。公司立即启用应急响应预案,协调相关人员处理该问题。通过查看Zabbix监控系统,该服务器除了丢包率高以外,其他性能指标均正常。登录服务器查看其服务状态,也都没有问题,这说明问题出现在网络层。网络管理人员查看Windows任务管理器里的网络利用率,发现利用率高达80%以上,很显然,丢包率高正是由于网络链路阻塞所导致的。
为了找出网络链路阻塞的“元凶”,网络管理人员使用netstat -an命令查看服务器的TCP连接情况,发现有不少外网IP与本服务器建立了TCP连接,但是该服务器本来就发布在外网,供外网用户使用,这种情况也属正常。但是从目的端口分布来看,有大量外网IP与服务器的22222和23456端口通信,这种现象就不太正常了,因为该服务器提供Web服务和SQL Server数据库服务,正常用户访问应用系统,应该只与80和1433端口进行通信,如果有外网IP与服务器其他端口持续通信,那么很可能是木马程序造成的。
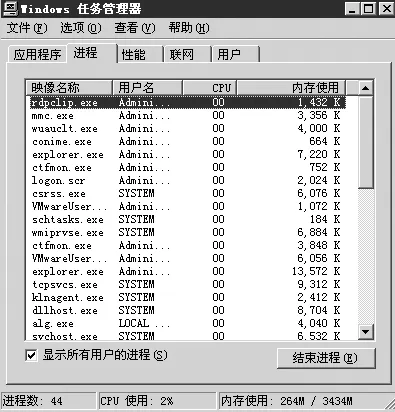
图5 Windows服务器进程检查

图6 Windows服务器网络连接检查
通过查询相关资料,22222和23456这两个端口是Prosiak和Evil FTP两种木马常用的端口,至此,通过检测已经可以确定,该服务器感染了木马,外部的攻击主机正是利用木马程序持续对服务器发起DDoS攻击,耗尽服务器带宽资源,造成业务系统处于瘫痪状态,用户也就无法正常使用系统。
抑制阶段
该阶段是安全事件响应的第三个阶段,是一种过渡或者暂时性的措施,它的目的是限制攻击行为所波及的范围,同时也为了限制潜在的损失。所有的抑制活动都是建立在能正确检测事件的基础上。抑制活动必须结合检测阶段所发现的安全事件的现象、性质、范围等属性,制定并实施正确的抑制策略。本案例在检测阶段已经确定了引发安全事件的原因,现在就必须抑制这次DDoS攻击。
由于IPS并未有效阻止这次攻击,说明这次攻击行为的特征并不在IPS设备的特征库内,所以IPS设备无法抑制此次DDoS攻击。但是此次攻击的目标端口(22222和23456)固定,可以在防火墙上针对该服务器的TCP端口做封禁策略,把从Untrust -> Trust的访问22222和23456端口的数据包全部封禁,这样就能阻断服务器上木马程序与外界攻击主机的通信。
通过采取抑制措施,服务器带宽利用率恢复正常,业务应用也恢复了正常。
根除阶段
在对安全事件进行抑制后,就需要找出事件的根源并彻底消除,以避免攻击者再次使用相同的手段攻击系统,引发安全事件。在根除阶段中,需要利用准备阶段产生的结果。常采取的措施包括分析原因、加强防范、消除根源、修改安全政策等。
本案例虽然通过防火墙端口封禁策略暂时抑制了DDoS攻击,但是木马程序仍然存在于服务器中,服务器仍然有被攻击的风险,必须彻底根除隐患。
1.联系卡巴斯基厂家,让其提供木马专杀工具进行全盘木马查杀,成功查杀若干木马程序,彻底根除此次DDoS攻击的根源。
2.进行服务器操作系统更新,打上最新发布的补丁,减少操作系统漏洞,降低系统被攻击的可能性。
3.将此次攻击情况反馈给IPS设备厂家,督促其尽快制定出防止该类DDoS攻击的特征库,以便从应用层面自动封堵该类攻击。
4.调整防火墙安全策略,根据“最低访问权限”的原则实施访问控制策略。针对该服务器的Untrust ->Trust策略,设置仅仅允许目的端口为80和1433的数据包通过,其他数据包一律封禁,这样就能保证只有业务数据包能够进入内网。同时,由于该服务器并不需要访问Internet,所以将 Trust ->Untrust方向的数据包彻底封禁,防止因为访问恶意网站或者下载文件导致服务器感染病毒或木马。
5.完善网络管理人员操作准则,禁止上传或者下载与工作无关和来源不明的软件到服务器,严禁使用服务器上网进行与工作无关的事情等。
恢复阶段
将安全事件的根源清除后,就进入到恢复阶段。恢复阶段的目标是把所有被攻破的系统或者网络设备还原到它们正常的任务状态,适当的时候解除前面的封锁措施。
在本案例中,恢复阶段的工作相对简单,由于业务系统已经恢复正常,为避免后台数据遭受木马的篡改和破坏,需要采用SQL Server中的数据回滚技术将数据恢复到故障前最近的一个时间点。前面抑制和根除阶段所采取的措施是为了加固系统安全,不影响业务,所以并不需要解除。
跟进阶段
这是应急响应六阶段方法论的最后一个阶段,其目标是回顾并整合发生事件的相关信息。该阶段是最容易被忽视的阶段,但是非常重要,有助于应急响应参与者从安全事件中吸取经验教训、提高技能,也有助于评判应急响应组织的事件响应能力。就本次DDoS攻击案例来说,所做工作如下。
1.对本次DDoS攻击事件的应急响应工作做出评估。本次DDoS攻击发生后,应急响应小组及时启用应急预案,10分钟之内即遏制了安全事件的进一步发展,使业务系统恢复正常运行,保障了系统数据的完整性。同时,在较短时间以内利用多种技术手段完成了对安全威胁源头的彻底根除,保证了业务系统的正常运转。
总之,此次应急响应小组成员反应迅速,严格履行了公司的信息安全应急响应流程,采取措施有效得当,及时化解了此次安全威胁,未给公司和用户带来实质性的损失,应急响应机制充分发挥了作用。
2.讨论遭受攻击的原因,总结经验教训。此次遭受攻击的原因包括多种,如IPS设备未能检测出此次攻击、防火墙的Untrust区域和Trust区域的双向安全策略过于宽松等,但是归根结底,还是网络管理人员的信息安全意识没有到位,制定的安全策略不够细化。
3.完善公司信息安全防护体系,补齐安全短板。一方面从人的角度下功夫,加强对网络管理人员的信息安全意识和能力进行考核,提高相关人员的信息安全意识和应急响应能力;另一方面考虑引入新的基于云安全、大数据分析技术的信息安全产品,这样可以大幅提高防火墙、IPS等设备的拦截能力。同时可以考虑与专业的信息安全应急响应机构合作,优化公司应急响应体系,出现重大信息安全事件时,与专业机构合作处理,提高公司应急响应的水平。
猜你喜欢
江苏安全生产(2022年5期)2022-06-16
中国计算机报(2021年9期)2021-04-26
科学家(2021年24期)2021-04-25
当代陕西(2019年15期)2019-09-02
网络安全和信息化(2018年2期)2018-11-09
网络安全和信息化(2017年6期)2017-11-23
IT时代周刊(2015年7期)2015-11-11
航天器工程(2014年5期)2014-03-11
自动化博览(2014年6期)2014-02-28
中国质量与标准导报(2013年8期)2013-03-11
