
基于改进AdaBoost分类器的一种目标识别算法
2016-11-23 08:30文贡坚
无线互联科技 2016年20期
唐 杰,文贡坚
(国防科学技术大学 自动目标识别国防重点实验室,湖南 长沙 410073)
基于改进AdaBoost分类器的一种目标识别算法
唐杰,文贡坚
(国防科学技术大学 自动目标识别国防重点实验室,湖南 长沙 410073)
文章提出一种基于改进AdaBoost分类器的目标识别算法,用于克服当前级联AdaBoost分类器存在的分类识别性能不足的问题。首先,对训练样本提取图像的海量Haar-like特征,然后对提取的特征基于AdaBoost算法进行特征选择和分类器构建,最后利用所选择的特征和训练得到的AdaBoost分类器进行目标的两类识别。实验结果表明,本方法优于传统的方法,具有较好的应用意义。
AdaBoost算法;Haar-like特征;目标识别
近年来,在目标识别领域,机器学习主要通过研究计算机学习问题来代替人的工作,这也逐渐成为该领域的一个研究热点。机器学习领域的分类问题需要解决的关键点和难点主要有以下两点:目标表征与建模、设计与训练分类器。目标表征和建模问题,实质上也是一个目标特征选择问题。Hu等[1]提出了Hu不变矩特征,推导出具有平移、旋转和缩放不变性的7个不变矩的表达式。Lowe等[2]创建梯度方位和位置直方图,以此来描述特征,得到尺度不变变换特征(Scale Invariant Feature Transform,SIFT),对一定的尺度变化、旋转和平移具有不变性。Tola等[3]提出Daisy特征描述子,也是基于梯度直方图,同时利用高斯权重和圆形对称核与方位地图进行卷积,改善了密集计算的性能。Dalal等[4]提出方向梯度直方图概念,即为梯度方向直方图(Histogram of Oriented Gradient,HOG)特征,对图像几何和光学的形变,都能保持很好的不变特性。Papageorgiou等[5]首次提出的Haar-like特征,即为矩形特征值的一种表示形式,具体特征值表示为具有相同形状和尺寸的矩形区域的像元值之和的差。由于其计算简单,能有效解决目标遮挡问题,得到了广泛的应用。针对分类器的设计与训练问题上,分类器必须与上述目标表征和建模相匹配才能达到最好的分类识别效果。Vanpik等[6]提出的支持向量机(Support Vector Machines,SVM),完成了低维向量到高维空间的映射过程,在目标识别领域开始得到广泛应用。Trevor等[7]从训练集中找到和新数据量最接近的k条记录,决定类别的方式是通过投票,这种最近邻节点算法(K-Nearest Neighbor,KNN)在多分类问题上表现较好。Viola等[8]通过boosting算法训练多个不同的弱分类器,并将其融合,在人脸检测上取得显著效果。因此,本文提出一种基于改进的AdaBoost分类器的识别算法,用于目标识别,并在相关视频序列数据上进行实验,证明算法有效性。
1 算法流程
整个目标识别流程主要分为两个部分:离线部分,即训练过程;在线部分,即识别过程。离线部分主要是从海量训练样本中提取海量的Haar-like特征,然后输入到离散AdaBoost分类器中进行训练;在线部分主要指对测试样本提取Harr-like特征,然后输入到已经离线训练好的AdaBoost分类器中进行目标的存在性检测。具体的识别流程如图1所示。
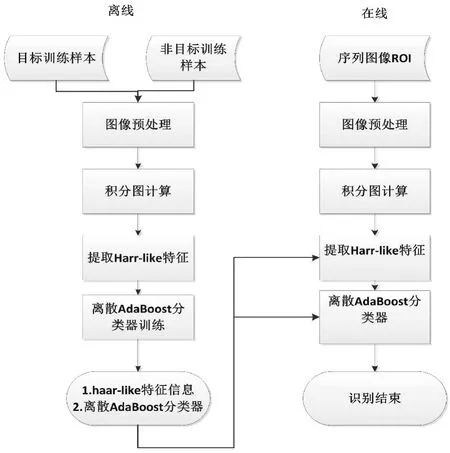
图1 算法结构图
2 离线训练部分
2.1图像预处理
将所有训练样本归一化为24×24的灰度图中,同时得到每个归一化后的正向、斜向积分图,方便后续计算处理。
2.2Haar-like特征提取
Haar-like特征广泛应用于目标检测技术中,其对客观对象直接进行建模。特征表征方式简单形式,所以利于快速计算。同时,形状多种多样,可以涵盖很多目标特性。最初的Haar-like特征由Papageorgiou等人提出。2001年,Viola等[9]通过计算积分图(Integral Image)的方法,得到4种形式的类Haar特征值,极大地加快了目标检测事的特征获取速度。后来,Lienhart等[10]人在最开始提出的Haar-like特征的基础上进行改进,进一步提出了另外14种扩展的Haar-like特征。本文采用扩展的Haar-like特征,共14种特征,如图2所示。图3为用于描述车辆特征的Haar-like特征示例。
2.3特征选择
通过AdaBoost算法从以上获得的大量haar-like特征中进行特征选取过程,选取对最后目标识别结果真正有用的特征,逐渐剔除无用的特征信息。
2.3.1传统 AdaBoost分类器
1995年,由Freund等[11]提出一种新的迭代方法,即AdaBoost算法。新的迭代算法可以解决Boosting算法的局限性,同时合理地避免了以往算法存在的过拟合(overfitting)现象。算法通过改变数据分布来实现效果,先自主学习形成弱分类器,然后根据上轮分类争取率来确定每个样本的具体权值。增大分类错误的权值,减少分类正确样本的权值。最后将每次训练得到的弱分类器根据一定的规则融合起来变成决策分类器,使用决策分类器对目标进行分类识别。
Adaboost算法流程如图4所示。其中,在第t轮训练后,αt通过弱分类器ht(x)来进行性能评价,分类错误的样本权重εt决定弱分类器ht(x)分类错误之后的作用贡献值,αt是εt的减函数,εt与αt成反比例关系,同时作用于弱分类器ht(x)的重要性。分类错误εt≥0.5时,算法中止,不再进行迭代运算并删除迭代过程中生成的弱分类器。εt=0时,训练集样本均分类结果正确,这时所有样本权重更新为零,样本权重失去意义。简单地,最终的强分类器H(x)由所有的弱分类器h1(x),h2(x),……hT(x)通过加权求和得到。

图2 Haar-like特征

图3 描述车辆特征的Haar-like特征示例
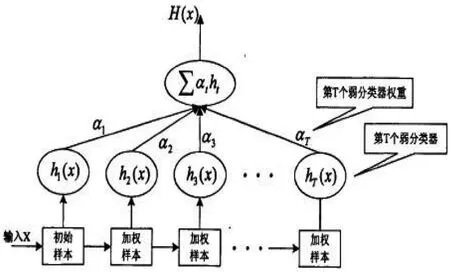
图4 AdaBoost 算法示意图
2.3.2改进AdaBoost分类器
算法所构建弱分类器,具体定义为:

其中x为图像中24×24大小的检测窗口,f(x)为计算矩形特征值的函数,θ为弱分类器的阈值,P用来表示不等式的方向。根据弱分类器的定义可以看出,确定一个弱分类器需要确定θ和P。
将特征集合中的每一个特征在所有样本上的特征值作为阈值集合。训练一个弱分类器,要在特征集合中寻求每一个特征的最佳阈值,确保该特征对所有样本的分类误差能够维持在最低状态。之后,选取最优弱分类器的任务就简化为在所有已训练好的弱分类器中,找出分类误差最低的弱分类器。
本文则针对传统的阈值设置方法,提出一种更加适合样本分布规律的自适应阈值设置方法,以提高分类识别性能。假设得到的算法中最佳分类位置为η,传统的计算分类阈值,通过求取平均值,即:
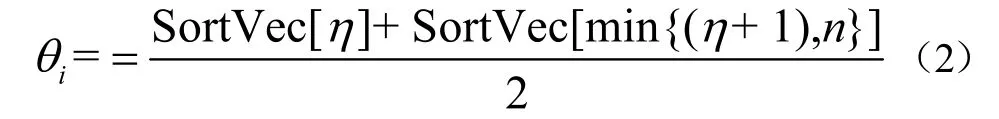
但是,求平均获取阈值的方法存在一定的局限性,即其反映不了训练样本的具体分布形式,为此,提出一种可以自适应样本分布规律的分类阈值设置方法:特征值满足小于等于SortVec[η]时,类别为Label(Label ∈{-1,+1}),则当特征值满足大于等于SortVec[η+1]时,类别为一的Label。可得,特征值满足小于等于SortVec[η]时类别为Label的先验概率为:
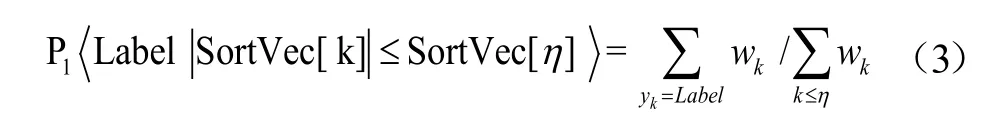
特征值大于等于SortVec[η+1]时类别为一的Label的先验概率为:

其中,下标为k的训练样本的权值和真实标签分别是wk,yk。以上得到的两类概率值反映了两类训练样本的分布规律,以样本的分布形式规律为依据,我们设置分类阈值如下:

最后将弱分类器组合成强分类器,以完成后面目标的检测识别过程。
3 在线识别过程
在线识别过程为对特定识别区域,对目标进行存在性检测,在本文中即是对车辆目标的存在性问题的解决。测试样本区域存在车辆,类别输出为1;不存在车辆,类别输出为-1。整个识别过程包括4个部分:图像预处理、积分图计算、Haar-like特征提取和改进的AdaBoost分类器进行分类识别。
前两个部分图像预处理和计算积分图,均与之前的离线训练过程作相同的处理。后面Haar-like特征提取部分,结合离线训练过程中位置、类型信息和结构等特征信息,来计算相应的haar-like特征值,得到相对应的特征向量。最后A利用daBoost分类器,通过特征向量对特定识别区域,完成车辆的存在性验证,输出最后的分类结果。
4 实验分析
本次试验主要应用在车辆目标视频序列图像的目标识别情况中。实验数据主要为从网上下载的各种视频中截取的序列图像。这些图像中,包括各式各样的场景,比如房屋、建筑、高速公路、立交桥、城市道路等等,当然样本中的车辆也包括各种类别,比如小轿车、公共汽车、皮卡、货车等等。而且样本复杂性高,包括车的颜色以及各个车的距离等均不一样,原则是保证样本能包含各类情况,包含有车辆型号、光照、拍摄角度等各种不同的情况。对于包含车辆的样本,本文称之为正样本;对于非车辆样本,即不包含目标特征的样本本文称之为负样本。负样本可以包括很多非车的背景图片,比如房子,行人、路面、植物等等。本文共收集了9 321张训练样本,其中2 301张正样本,7 020张负样本。正负样本的示例如图5—6所示。
本章实验中主要采用以下两种方式对目标识别效果进行评价:车辆识别率、虚景率。分别定义如下:
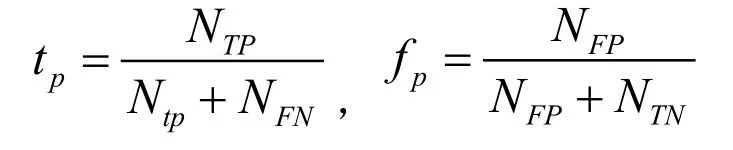
其中NTP,NFP,NTN和NFN分别表示测试样本中算法正确检测的车辆数目,将非车辆误识别为车辆的个数,正确识别的非车辆数目和将车辆误识别为非车辆的个数。这里做了2组实验分别与传统的AdaBoost方法进行比较,结果如表1—2所示。
表1显示,本文的自适应样本分布规律的设置阈值的方法的检测识别效果要优于传统的方法。表明本文文中的阈值设置方法,能够更好地反映训练样本的分布形式和规律.
表2反映,本文的改进方法在训练时间上有了更大的进步,比传统的训练方式节省了大量时间,改善了离线训练的耗时问题。

表1 不同阈值设置方法的评估结果
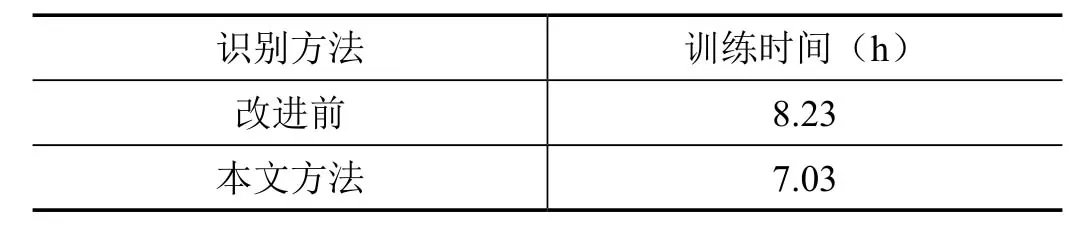
表2 训练时间对比效果
最后,将改进后的算法用于高速公路视频序列图像识别中,效果如图7所示。
5 结语
本章提出了一种改进AdaBoost分类器的目标识别算法,并利用相关视频序列数据进行了实验,分析了算法的识别效果。在算法分类器生成过程中,提出一种自适应样本分布规律的设置阈值的方法。实验结果显示,本文提出的改进AdaBoost分类器算法,改善了离线AdaBoost分类器的训练耗时的问题,并且提高了分类识别的性能。

图5 正样本(车辆)

图6 负样本(非车辆)

图7 视频序列图像车辆识别效果
[1]HU M K. Visual Pattern Recognition by Moment Invariant[J].Information Theory, 1962(8):79-187.
[2]LOWE D G.Local feature view clustering for 3d object recognition[C].United States: IEEE Computer Society Conference on Compute Vision and Pattern Recognition(CVPR2001),2001.
[3]TOLA E, LEPEIT V, FUA P. Daisy: An efficient dense descriptor applied to wide-baseline stereo[J]. Pattern Analysis and Machine Intelligence, 2010(32):815-803.
[4]Navneet Datal, Bill Triggs. Histograms of Oriented Gradients for Human Detection[C].United States: IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2005.
[5]PAPAGEORGIOU C, OREN M, POGGIO T.A general framework for object detection[C].United States: International Conference on Computer Vision, 1998(8):122-124.
[6]VAPNIK V N.The nature of statistical learning theory[M].New York: Springer-Verlag, 1995.
[7]TREVOR H.Discriminant Adaptive Nearest Neighbor classification[J].Pattern Analysis and Machine Intelligence, 1996.
[8]VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]. USA: IEEE International Conference on Computer Vision and Pattern Recognition, 2001.
[9]VIOLA P A, JONES M J.Robust real time face detection[J].Computer Vision(S0920—5691), 2004(2):137-154.
[10]LIENHART R, MAYDT J.An Extended Set of Haar-like Features for Rapid Object Detection[C].IEEE ICIP,2002(1):900-903.
[11]FREUND Y, SCHAPIRE R E.Experiments with a New Boosting Algorithm[A].In Proceedings of the 13th Conference on Machine Learning, Morgan Kaufmann[C]. USA:Proceedings of the 13th Conference, 1996.
An algorithm based on improved AdaBoost classifier for object recognition
Tang Jie, Wen Gongjian (Defense Key Laboratory of Automatic Target Recognition of National University of Defense Technology, Changsha 410073, China)
An algorithm based on improved AdaBoost classifier for object recognition is proposed to solve the problem of poor recognition performance for traditional AdaBoost based on cascaded AdaBoost classifier. First of all, the Haar-like features are extracted from the training samples, then we use the improved AdaBoost classifier training method to feature extraction and classifier training. Finally, two classes classification is performed by using the AdaBoost classifier and the selected features. As it can be seen, experiments show that the proposed algorithm has better performance than traditional methods.
Adaboost algorithm; Haar-like features; object recognition
唐杰(1992— ),男,山东潍坊,硕士研究生;研究方向:自动目标识别。
猜你喜欢
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
电子测试(2018年1期)2018-04-18
河北遥感(2017年2期)2017-08-07
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
衡阳师范学院学报(2016年3期)2016-07-10
东北电力大学学报(2015年1期)2015-11-13
