
随机样本在人工神经网络地下水质分级中的应用
2016-11-22 03:09:08魏敬铤叶振维内蒙古自治区环境科学研究院内蒙古呼和浩特010011
低碳世界 2016年30期
魏敬铤,叶振维(内蒙古自治区环境科学研究院,内蒙古呼和浩特010011)
随机样本在人工神经网络地下水质分级中的应用
魏敬铤,叶振维(内蒙古自治区环境科学研究院,内蒙古呼和浩特010011)
本文应用计算机随机生成样本的方法,解决神经网络在实际应用中样本数量不足的问题,结果表明,可以有效提高网络训练的效率和精度。
随机样本;神经网络;水质分级
引言
目前,我国普遍采用的水质评价方法主要包括单项组分评价和综合评价。综合评价方法中,水质受污染程度是由多个污染因子共同决定的,为更加准确的评价水污染状况,目前已发展出多种评价方法[1],如模糊聚类法、灰色聚类法等,由于污染物与地下水质量级别的非线性关系,计算方式复杂、计算量大,利用神经网络的非线性拟合能力和学习能力能够较快速的对监测数据进行分类,但分类误差受很多因素影响,本例主要探讨通过增加样本数量的方式,提高网络训练效率和分类精度。
1 BP网络建立
目前人工神经网络[2]应用最广泛的是BP神经网络,因其具有很强的自适应能力,通过建立网络模型,输入训练样本,将误差反向传播给网络进行修正,逐步获得不断接近输入与输出对应关系的目标网络。
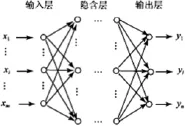
图1BP网络拓扑图
神经网络是由神经元相互连接而成,一般包括三层:输入层、中间层(隐含层)[3]和输出层。根据本例输入层节点为6,输出层为1,故隐含层节点数取13,建立地下水分级的网络模型。
2 案例应用
本例矿区位于内蒙古河套灌区北缘,北依狼山山脉,由于开采年限较长,疏干作用导致地下水中盐分含量大、矿化度高。根据主要超标因子分布情况,选取溶解性总固体、高锰酸盐指数、亚硝酸盐氮、氯化物、硝酸盐氮、硫酸盐6项指标进行评价。根据《地下水质量标准》(GB/T14848-93),将预期输出结果设定为0.2~1.0五个等间距级别,分别对应水质的Ⅰ~Ⅴ类(见表1~2)。
由于输入数据数据范围不同,甚至相差几个数量级,要在同一个模型下运算,需要对数据进行归一化处理,本例采用最多最小法,公式如下:
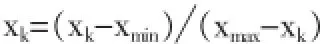
式中xmin为序列中最小数,xmax为序列中最大数。
3 计算结果和分析
选取因实际监测样本偏少,采用计算机随机生成10、100、500、1000、10000份样本,分别作为训练样本,迭代次数设为1×104,以实际监测数据作为测试样本进行结果验证,计算结果如表3。
计算结果显示,在样本数量很少时,偏差很大,基本不能满足分类要求;随着样本数量的增加,网络偏差值减少很快。
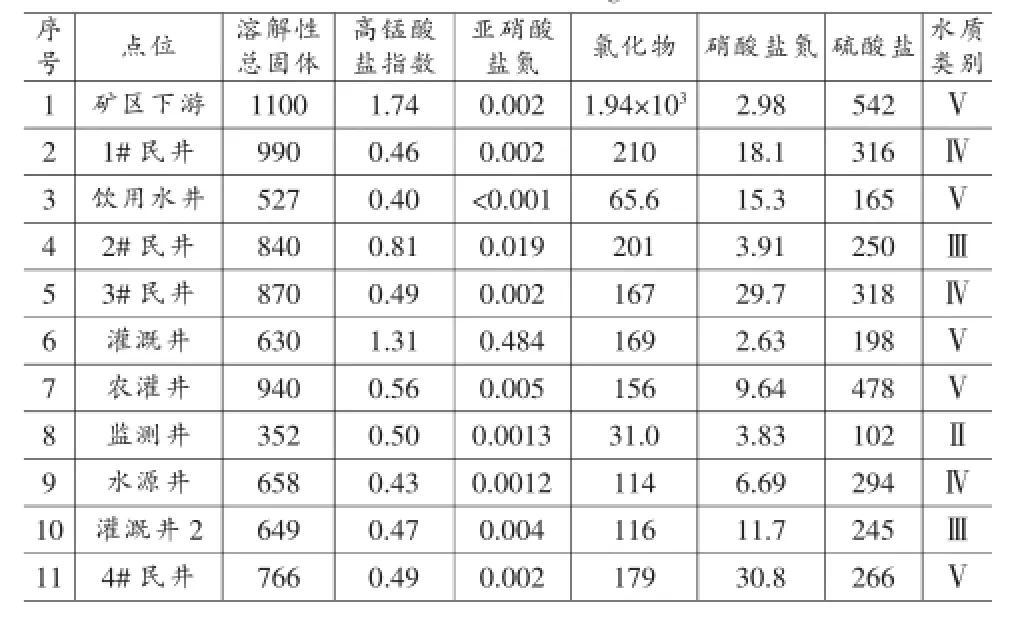
表1 水质监测表(mg/L)

表2 地下水质量分类标准(GB/T14848-93)[4]

表3 不同样本数量分类结果汇总
4 结论
采用神经网络方法进行地下水质分级具有很高的运算效率,是可以广泛应用的一种方法。但当监测样本数量较少时,分类误差很大,准确度可能满足不了工作需求。通过使用计算机产生随机样本,通过神经网络训练不断修正网络参数和权重,可明显提高分类准确率。
[1]王华东,刘永可,王健民,等.水环境污染概论[M].北京:北京师范大学出版社,1984.
[2]袁曾任.人工神经元网络及其应用[M].北京:清华大学出版社,1999.
[3]封志勇,蒋文杰,董志芬,等.人工神经网络法在地下水水质分级中的应用.贵州工业大学学报(自然科学版),2003,32(4):95.
[4]《地下水质量分类标准》(GB/T14848-93).
X824
A
2095-2066(2016)30-0007-01
2016-10-12
魏敬铤(1981-),男,中级工程师,大学本科,主要从事水污染防治工作。
猜你喜欢
心电与循环(2021年4期)2021-11-29 02:41:56
心电与循环(2020年3期)2020-06-18 13:43:12
空间科学学报(2020年4期)2020-04-22 01:17:12
电子制作(2019年10期)2019-06-17 11:45:10
中国医疗保险(2017年6期)2017-07-18 11:28:19
中国卫生(2016年5期)2016-11-12 13:25:50
中国眼镜科技杂志(2016年17期)2016-10-24 08:36:30
中国卫生(2015年10期)2015-11-10 03:14:22
中国卫生(2015年6期)2015-11-08 12:02:44
建筑材料学报(2014年4期)2014-03-11 17:08:16
