
少数民族语言信息资源计算机辅助阅读系统架构设计
2016-11-21 01:22赵生辉西藏民族大学管理学院
图书馆理论与实践 2016年10期
赵生辉(西藏民族大学管理学院)
少数民族语言信息资源计算机辅助阅读系统架构设计
赵生辉
(西藏民族大学管理学院)
利用信息技术消减语言文字的差异性所带来的沟通障碍是民族地区信息资源管理迫切需要解决的问题。在机器翻译技术之外,计算机辅助跨语言阅读系统(CARS-IRMLC)是民族地区政府公共服务机构为只掌握了国家通用语言服务对象所特别设计的跨语言阅读环境,该系统以“简化通用语义代码体系”作为多种少数民族语言同义语素的定位、关联、检索的逻辑基础和语义信息转换的逻辑中介。目前CARS-IRMLC在我国民族地区政府机关和图书馆、档案馆、博物馆等公共文化机构具有广泛的应用前景。
少数民族语言;信息资源共享;计算机辅助阅读;跨语言信息检索;机器翻译
目前,我国正在使用的少数民族语言在80种以上,正在使用的少数民族文字在30种左右。[1]语言文字的多样性,在造就中华民族文化丰富多彩特征的同时,也给不同民族人群之间的相互理解带来了诸多不便。利用信息技术消减语言文字的差异性所带来的沟通障碍,是民族学、语言学、计算机科学、信息管理等领域研究人员一直试图解决的问题。
在少数民族语言文字信息处理技术领域,于洪志研发了藏汉双语信息系统;[2]戴玉刚研发了以中文为核心的多语言基础资源库;[3]丁晓青研发了少数民族文字的统一识别平台;[4]塔娜等构建了面向跨语言信息检索的蒙汉语义词典;[5]艾斯卡尔·艾木都拉开发了基于维吾尔语和汉语的双语档案信息管理系统;[6]由国内多家研究机构共同参与的国家科技支撑计划项目“少数民族语言文字信息处理共性关键技术研究与示范应用”取得多项成果。[7]
在多民族语言信息资源共享技术方面,研究人员一直寄希望于少数民族语言文字机器翻译(Machine Translation)技术的发展和成熟。然而,由于人类自然语言的复杂性,机器翻译的效果与人们的期望和需求还有较大的差距。受到市场规模、语料库规模、研究人员数量、经费支持力度等多种因素的制约,目前我国少数民族语言文字机器翻译技术整体上还处在初级阶段,研究成果也仅限于部分小型实验系统,无法满足广泛应用的需要。在机器翻译技术之外,发展面向读者现实需求的计算机辅助跨语言阅读体系就成为一种更为经济和现实的选择。
少数民族语言信息资源“计算机辅助跨语言阅读”(Computer-Aided Cross-languages Reading,CACLR)系统是我国民族地区政府公共服务机构为只掌握了国家通用语言服务对象所特别设计的跨语言阅读环境。在该环境中,用户可以用自己熟悉的国家通用语言文字作为工具,检索由各种少数民族语言文字生成的信息资源,阅读和理解这些信息资源的主题和内容,并可以根据系统自动生成的阅读建议,选择进行人工高精度翻译、概要浏览或者放弃阅读等操作。少数民族语言信息资源计算机辅助跨语言阅读系统在我国民族地区政府机关和图书馆、档案馆、博物馆等公共文化机构具有广泛的应用前景,也适用于互联网少数民族语言信息资源的跨语言辅助阅读,实施后对我国民族团结的战略格局将产生深远的影响。
1 需求分析
对于只掌握了国家通用语言文字的用户而言,阅读和理解少数民族语言信息资源会遇到各类困难和障碍,如:无法了解所看到的少数民族语言信息资源的主题和内容;无法搜集到尽可能全面的同一主题、多种语言文字的信息资源;无法判断信息资源是否符合自己的信息需求等。这些困难和障碍是用户基于自身知识储备无法有效解决的,只能求助于专业的翻译人员或相关领域专家;在没有找到合适的翻译人员或者领域专家时,只能暂时放弃对该信息资源的阅读。计算机辅助阅读则为用户提供了一种新的选择,改善用户在阅读少数民族语言信息资源时的无助感,获得更好的阅读体验。一般而言,少数民族语言信息资源的跨语言阅读需求主要有以下方面。
1.1少数民族语言信息资源的跨语言检索需求
跨语言信息检索(Cross-LanguageInformation Retrieval)是指用户以自己熟悉的语言文字来构建和提交检索提问式,系统据此检索出符合用户需求的多个语种的相关信息。跨语言信息检索的出现,主要是为了应对互联网多语言信息资源共存对信息查全性的要求,使得内容符合用户需要的多个语种的信息资源都可以被检索到。作为信息检索非常重要的研究领域,跨语言信息检索从20世纪90年代中期开始得到了广泛的关注,一些商业公司已经可以提供英语等使用较为广泛的语言文字的多语言信息检索服务。在我国少数民族语言信息资源阅读过程中,用户同样有着跨语言信息检索需求,如要查询我国少数民族节日相关信息,使用藏文、蒙古文、维吾尔文作为记录文字的信息资源都应该被检索到。在现实生活中,用户有少数民族语言信息资源的阅读需求时,找到可以翻译单一语种信息资源的专业人员相对容易,但是要找到同时熟悉多种语言文字的翻译人员就非常困难,更不要说找到同时可以看懂数十种少数民族语言文字的人了。因此,少数民族语言信息资源跨语言检索正是发挥了计算机在信息检索领域的优势,使用户通过一次检索就可以得到尽可能全面的信息检索结果。
1.2少数民族语言信息资源的语义提示需求
少数民族语言信息资源在阅读过程中最大的阅读障碍是用户对少数民族语言文字符号的语义内涵无法识别和理解,如果计算机能够提供相应的语义提示功能,则可以大幅度降低跨语言阅读的难度。“语义提示”(Semantic Cue)与文本的精确翻译有着很大的不同,“语义提示”一般只限定在词汇和简单句型层面,即可以让用户通过提示信息了解信息资源的主题和概要内容,很少涉及语法问题,其技术实现的难度因此要低一些。语义提示的方式有多种,如利用鼠标的悬停菜单进行语义提示,在信息文本当中进行语义混杂提示以及采用源语言和目标语言的双语对照排列进行语义提示等。由于“语义提示”基本上相当于源语言和目标语言等价语素的直接翻译,因此,语义提示信息的位置往往不符合语法规则,顺序连读往往不能准确反映源语言的真实语义,但作为一种计算机辅助阅读的手段,这种方法基本能够满足浏览和判断主题相关性的需求,因而也是一种可以接受的解决方案。
1.3少数民族语言信息资源的阅读建议需求
用户在进行少数民族语言信息资源跨语言阅读时,只能进行语义信息的概要浏览,对于各类信息资源与用户需求的符合程度往往不能做出精确判断。计算机辅助阅读则可以通过需求模型的方法有效解决这一问题。如,系统可以允许用户输入若干检索词并给出其权重,在检索过程中系统可以计算每个信息资源中相关词汇的词频信息,并根据需求模型计算出符合程度指数,从而可以对检索到的所有结果按照与需求的符合程度进行排序。基于上述的需求符合程度指数,系统可以进一步为用户自动生成阅读建议。例如非常重要的信息资源,建议用户找专业翻译人员进行高精度翻译工作,一般性信息资源则建议用户进行全文浏览,低度相关的信息资源建议用户浏览标题和元数据进行即可。为了减少用户寻找专业翻译人员的难度,系统同时可以通过网络方式提供用户与翻译人员进行相关服务提交和执行的在线平台。
1.4少数民族语言信息资源阅读的文化支持需求
我国少数民族文化极其丰富多彩,传统语言文字当中蕴含了大量体现本民族文化特征的词汇,这些词汇的国家通用语言词义往往是根据少数民族词汇的发音进行翻译的,即使计算机阅读系统提示了其国家通用语言的词义,用户还是无法准确理解其内涵。因此,少数民族语言信息资源的计算机辅助阅读系统应该为用户的这种需求提供一定程度的支持,如可以建立少数民族文化常用术语解释列表,检索结果当中提供与该术语的链接信息,从而帮助用户进一步了解该术语所描述语义对象的准确信息。
1.5少数民族语言信息资源的移动辅助阅读需求
随着我国移动通信技术的飞速发展,移动互联网已经成为用户进行信息交互的重要方式,随着时间的推移其发展空间还在日益扩大,可以预见未来基于移动通信设备的少数民族语言计算机辅助阅读模式将成为一种新的潮流。在移动互联网环境下,用户的少数民族语言信息资源管理需求可以得到全方位的支持,如用户在图书馆看到某语种少数民族语言文献后,只要进行简单设定,再拍照上传,系统就可以识别该文献的文字信息,并启动语义提示功能给出该文献词汇的国家通用语言的语义提示信息。移动互联网使得少数民族语言信息资源计算机辅助阅读的应用范围得到了拓展,用户进行阅读的时间地点不再是固定的某一机构,如用户在我国民族地区看到一个使用少数民族文字记录的地理标记或者在某景点看到一个少数民族文字牌匾,均可以将其拍照上传以获得国家通用语言文字的语义提示。
上述需求中,跨语言检索需求、语义提示需求、阅读建议需求和文化支持需求属于基本需求,是少数民族语言信息资源计算机辅助阅读系统开发必须考虑的问题。基于移动通信设备的少数民族语言信息资源计算机阅读辅助需求属于高级阶段的需求,要在满足前四个基本需求情况下,相关技术和方法的发展成熟后才能完全实现,如少数民族语言文字自动识别技术,少数民族语言信息资源语义信息的自动检索和标注技术等,因而可以认为是一种未来的目标模式。
2 技术原理
少数民族语言信息资源计算机辅助阅读的关键任务是研究和开发“少数民族语言信息资源计算机辅助阅读系统”(CARS-IRMLC),该系统实现信息资源跨语言检索和少数民族语言国家通用语言语义提示的主要原理是基于专门构建的多民族语言“简化通用语义代码体系”(Simplified Universal Semantic Code System,SUSCS)。
2.1多语言语义转换的主要方法
计算机辅助跨语言阅读的关键是实现不同语种语言文字等价语素之间的语义转换,目前在机器翻译领域常用的技术手段主要有:机读双语词典(Machine-Read Bilingual Dictionary)、双语语料库(Bilingual Corpus)、多语言叙词表(Multilingual Thesauri)、多语言本体(Multilingual Ontology)等,这些方法主要是为实现语言文字的对等翻译而设计的,需要有专门的语言学知识作为基础,并且要经过长期的积累和优化才能最终投入应用。我国少数民族语言文字机器翻译技术目前还处在初级阶段,能够支持机器翻译的技术资源非常少,为了实现少数民族语言信息资源跨语言辅助阅读需求,本文以各少数民族语言文字双语词典为基础,提出了一种基于通用代码体系实现多语种信息语义转换的方法。
2.2通用语义代码的概念与功能
“通用语义代码”是对“通用语义空间”(Universal Semantic Space)的一种形式化表述方式。这里的“通用语义空间”,是指人类社会的各种自然语言所描述的语义对象及其关系所构成的虚拟空间,是客观世界和思维活动各类语义对象的总和。“通用语义空间”与各种自然语言的“语义空间”之间是“表现”和“映射”关系:一方面,通用语义空间是一种观念意义上的空间,它无法脱离自然语言空间而独立存在,通用语义空间的语义对象必须通过某种具体的自然语言才能展现出来从而被人们所理解;另一方面,任何一种自然语言本质上是对“通用语义空间”进行映射的结果,相当于以某种具体的自然语言所展现的“通用语义空间”视图。从“通用语义空间”视角看来,机器翻译方法实际上是实现“通用语言空间”不同语种“自然语言视图”的切换过程。那么,如果可以用代码表达通用语义空间的语义对象,并基于这一代码,实现多个自然语言视图当中等价语素的语义关联,则可以非常方便地实现这些等价语素不同语种语义之间的切换,可以大大降低不同语种语言文字等价语素转换的难度和执行速度。综上所述,“通用语义代码”(Universal Semantic Code,USC)是一种为实现多语言信息交流而专门设计的人工编码体系,该体系独立于任何一种具体的自然语言,其存在主要是为多种自然语言同义语素的定位和关联提供逻辑基础,也是多种自然语言一体化信息检索和语义共享的逻辑中介(见图1)。
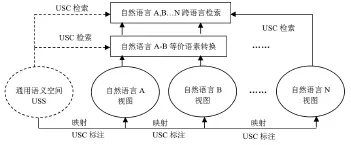
图1 多语言通用语义代码的技术原理
2.3多民族语言简化通用语言代码体系概述
“多民族语言通用语义代码体系”是专门针对我国多民族语言信息资源共享需求而设计的代码体系,是实现我国多民族语言信息资源语义转换的核心技术和基础资源。鉴于通用语义代码设计工作的复杂性和长期性,在研究初期可以根据需求对通用语义代码体系进行适度简化,如,通用语义编码主要针对等价词汇和常用等价例句,原则上不对语法现象进行编码,从而大大降低了编码体系构建工作的难度。本文将这种经过了适度简化的人工编码体系称为“多民族语言简化通用语义代码体系”(Simplified Universal Semantic Code System,SUSCS)。
“通用语义代码”本身并没有任何特殊含义,其建构必须以某种具体的自然语言作为语义参照对象,结合我国语言文字工作的总体规划,多民族语言通用语义代码体系的构建应当以国家通用的汉语和规范汉字作为参照语言文字。因此,对少数民族语言信息资源进行“简化通用语义代码体系”(SUSCS)的标注,本质上是参照国家通用语言文字进行语义映射的过程,因而也是以国家通用语言文字为核心的多民族语言信息资源共享体系的实现方式。
根据现实需求,我国多民族语言“简化通用语义代码体系”拟采用开放式结构设计,初期主要进行国家通用语言文字和蒙古语、藏语、维吾尔语、哈萨克语、柯尔克孜语、壮语、傣语、朝鲜语等使用人口较多,具有较大社会影响力的少数民族语言文字(少数民族语言的古代文字暂不在研究范畴)的统一编码,今后根据实际需要可以继续补充其他语种的少数民族语言文字。
基于通用语义代码的语义转换是一种新的视角和方法,为了验证这种方法的可行性,笔者进行了小规模的探索性实验。选取国家通用语言100个词汇按照数字1~100进行语义编码,对藏文和蒙古文的同义词进行关联;分别用藏文和蒙古文的上述词汇组成简单句子,再进行语义编码标注,最后采用国家通用语言文字关键词进行检索,相同语义不同语言的多个文档均可检索到。实验结果表明,采用简化通用语义代码体系进行跨语言信息检索在原理上是可行的。
3 架构设计
根据少数民族语言信息资源计算机辅助阅读的需求结构和技术原理,少数民族语言信息资源计算机辅助阅读系统(CARS-IRMLC)的体系架构见图2。在图2当中,CARS-IRMLC系统主要分为基础代码、预处理、阅读辅助、信息输出等环节,每个环节又细分为多个模块,主要研究内容如下。
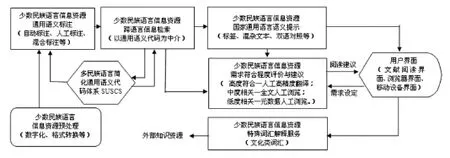
图2 CARS-IRMLC系统总体架构
3.1基础代码体系
SUCSC是少数民族语言信息资源计算机辅助阅读系统建设的关键,决定了整个体系建设的成败。鉴于通用语义代码设计工作的复杂性和长期性,本项目拟根据研究需求对通用语义代码体系进行适度简化,设计依据主要是国家通用语言与各语种少数民族语言的双语词典。参照国家通用语言文字词典建立基本代码体系,各少数民族语言的同义语素根据双语词典与通用语义代码进行关联,形成以国家通用语言为参照的多语言同义词表,同时选取部分常用同义句进行统一编码,原则上不对各类语言文字语法规则进行编码。需要说明的是,实验过程中所使用的“简化通用语义代码体系”是根据各类语言的高频词汇和句例制作的原型系统,目的是验证技术原理的可行性,在应用和推广之前还需要进行大规模补充完善和持续进化。
3.2预处理功能
预处理是实现少数民族语言信息资源计算机辅助阅读的前提,主要包括技术预处理和语义标注等工作。技术性预处理主要包括:①对以纸质文档存在的少数民族语言信息资源进行数字化加工,结合文字识别技术和人工转录方法,将其转换为计算机可以处理的少数民族语言文本文件;②为了保证多语种少数民族语言文字的正常显示,需要将各语种信息资源按照GB18030信息编码标准进行转换,以保证其兼容性;③为了便于进行信息处理,需要将各种应用软件产生的文本格式统一转换为TXT格式。通用语义代码标注是实现计算机辅助阅读的基础工作,主要通过三种方式完成:①自动标注,由程序调用多语言通用语义代码体系完成自动标注,工作精度较低;②人工标注,在标注程序辅助下由人工完成对语义的精确标注,工作速度较慢;③混合标注,由程序完成基础标注,人工方式进行确认和修改。
3.3阅读辅助功能
阅读辅助功能是系统的主要建设目标,包括跨语言检索、语义提示、用户建议、文化支持等部分。
(1)少数民族语言信息资源跨语言信息检索算法及实现。主要基于多民族语言简化通用语义代码体系,实现跨语言信息资源检索。如,以国家通用语言文字为检索词,程序首先查找该检索词的SUSCS编码,然后在系统中查找所有标注为该编码的信息资源,而不论其采用的是何种语言文字。
(2)少数民族语言信息资源通用语义提示功能的实现。国家通用语言语义提示是实现少数民族语言信息资源计算机辅助阅读的主要方式,基于查询SUSCS编码表当中的多语言同义语素关联表来实现,语义提示主要基于三种模式:①标签提示模式。阅读过程中鼠标滑过的文字以标签形式现实其国家通用语言文字语义;②混杂文本模式。文本当中的少数民族语言词语之后括号内显示其国家通用语言文字语义;③双语对照模式。以段或篇为单位,分别显示少数民族语言文字和国家通用语言文字语义。
(3)少数民族语言信息资源用户需求符合程度评价与建议功能实现。CARS-IRMLC系统允许用户输入多个国家通用语言文字的关键词并设定其词频阀值,在进行跨语言检索过程中,自动计算上述数据,根据结果为用户提供阅读建议。系统可以提供的阅读决策主要有三类:①高度符合。说明该信息资源对用户非常重要,建议用户将文本提交给专业的人工翻译人员进行高精度人工翻译。②中度相关。说明该信息资源与用户需求有一定关联,但是需求强度还不足以达到阀值,建议用户逐一进行全文浏览以判断相关资源的取舍。③低度相关。说明该信息资源主题与用户需求可能有一些联系,建议用户进行标题等元数据项的快速浏览以判断其取舍。
(4)少数民族语言信息资源辅助阅读文化支持功能的实现。文化支持功能是属于在用户了解少数民族语言信息资源通用语义提示信息的基础上,为了帮助其准确理解相关文化类词汇的含义而提供的延伸性服务,其实现方式主要是建立各少数民族语言文字特殊术语词汇的解释性列表,提供该词汇与外部知识资源之间的链接,从而使其阅读时可以进行参考,帮助其理解这些术语的内涵和性质。
3.4用户界面
少数民族语言信息资源计算机辅助阅读系统用户界面设计,系统根据用户使用系统的不同情境设计三种种类的用户界面。①文献阅读器界面。主要适用于图书馆、档案馆、博物馆等文献信息资源数量较多的机构提供少数民族语言信息资源服务时使用。②网络浏览器界面。即少数民族语言网络信息资源阅读器插件,用户使用Internet Explore等网络浏览软件访问少数民族语言文字网页的时候,只要加载该插件即可进行国家通用语言语义提示,并给出网页的阅读建议。③移动设备阅读器界面。根据移动通信设备显示信息的特点,设计符合用户使用习惯的辅助阅读界面,使用户可以远程接受公共信息机构的辅助阅读服务。
CARS-IRMLC系统主要是针对少数民族语言信息资源跨语言辅助阅读基本需求,基于计算机网络环境而设计的。在系统各项关键技术取得突破并基本成熟之后,笔者拟基于这些技术探索基于个人移动通信设备的少数民族语言信息资源辅助阅读系统,用户的移动通信设备装载了该系统,可以随时随地将看到的少数民族语言信息资源拍照并上传到系统,系统根据文字识别等技术进行预处理并基于SUSCS进行阅读辅助,给用户反馈通过国家通用语言文字语义提示并提供阅读建议。由于该系统可以实现中国多民族语言文字的语义共享,暂定名为“中文通”。
[1]中华人民共和国国务院新闻办公室.中国的民族政策与各民族共同繁荣发展[M].北京:人民出版社,2009,32.
[2]于洪志,王晓军.藏汉双语信息处理系统概述[J].西北民族学院学报(自然科学版),1998(1):1-4.
[3]戴玉刚,何向真.通用藏文模板设计[J].西北民族学院学报,2005(3):29-34.
[4]清华大学新闻网.统一平台少数民族文字识别系统在清华大学研制成功[EB/OL].[2015-02- 08].http://news.tsinghua.edu.cn/new/news.php?id=14 712.
[5]塔娜,等.面向跨语言信息检索的蒙汉语义词典构建[C]//第三届全国少数民族青年自然语言信息处理学术研讨会论文集.北京:中央民族大学出版社,2002:12-15.
[6]刘登峰,艾斯卡尔·艾木都拉.维、汉多语种档案信息管理系统[J].计算机工程,2008(20): 263-268.
[7]中华人民共和国科技部网站.信息技术领域“以中文为核心的多语言处理技术”重点项目[EB/OL].[2015-02-08].http://www.most.gov.cn/tztg/t2006 1001_36442.htm.
The Architecture Design of the Computer-assisted Reading System of Minority Language Information Resources
Zhao Sheng-hui
It is an urgent need to remove the communication barriers dues to language difference with the application of information technologies in information resources management in ethnic minority residence regions of China.Besides Machine Translation technology,Computer-assisted Cross-Language Reading System(CARS-IRMLC)refers to the specially designed cross-language reading environment which public service institutions of minority residence regions provided for their customers who only master national common language.CARS-IRMLC takes Simplified Semantic Code System as the logic medium for positioning,linking and retrieval of synonyms morphemes of multiple minority languages of China,as well as logic intermediary for semantic information transformation.CARS-IRMLC can be widely used in government offices,libraries,archives,museums and other public cultural institutions in minority residence regions of China.
Minority Languages of China;Information Resources Sharing;Computer-assisted Reading;Cross-language Information Retrieval;Machine Translation
G250.78
A
1005-8214(2016)10-0072-05
本文系国家社科基金项目“多民族语言信息资源跨语种共享策略研究”(项目编号:14BTQ008),中国博士后科学基金项目“多民族语言信息共享域的架构模型与规划方法研究”(项目编号:2014M561634),中国博士后科学基金特别资助项目“多民族语言信息资源辅助阅读系统原型设计与开发研究”(项目编号:2015T80539)的阶段性成果。
赵生辉(1977-),男,陕西宝鸡人,西藏民族大学管理学院公共管理系副教授,研究方向:民族信息学、数字人文、电子政务等。
2016-02-03[责任编辑]菊秋芳
猜你喜欢
新世纪智能(语文备考)(2021年9期)2021-12-06
新世纪智能(语文备考)(2021年9期)2021-12-06
新世纪智能(语文备考)(2021年4期)2021-08-06
新世纪智能(语文备考)(2021年4期)2021-08-06
开放教育研究(2020年2期)2020-03-31
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
中国修辞(2017年0期)2017-01-31
