
网络交易拉圾评论智能识别研究
2016-11-19 16:22赵静娴
现代情报 2016年4期


〔摘 要〕定义垃圾评论边界,利用智能算法有效识别垃圾评论。对垃圾评论进行内部细分,构建评价指标体系,并提出一种改良决策树方法对垃圾评论进行智能评估,并提供可读性规则。基于Matlab语言实现,通过实证研究,验证所构建的垃圾评论识别模型能够达到较高预测精度。提供了一种高效的多在线评论多分类智能识别方法,为垃圾评论的分类监管治理提供技术支持。
〔关键词〕垃圾评论;数据挖掘;决策树;神经网络
DOI:10.3969/j.issn.1008-0821.2016.04.011
〔中图分类号〕G206.2 〔文献标识码〕A 〔文章编号〕1008-0821(2016)04-0057-05
〔Abstract〕The paper defined the boundary of review spam,used intelligent algorithms to effectively detect review spam.The internal subdivision of review spam,evaluation index and an improved decision tree method for intelligent evaluation of review spam with readable rules are proposed.The empirical research based on Matlab showed the model can achieve higher prediction accuracy.The paper provided technical support for the review spam classification regulatory governance through proposing an efficient method for intelligent multiple classification of online reviews.
〔Key words〕review spam;data mining;decision tree;neural network
通过互联网进行商品交易已经成为最近十年以来迅猛发展的商业模式,深刻而迅速的改变了传统商业模式。消费者可以通过查看以往交易购买者对所购商品和服务的评价来判断卖家商品和服务的好坏,是互联网交易不同于传统商业模式的优势之一。成交评论是后继消费者对拟购商品进行判断的重要依据之一,也是商家有针对性的改进服务,改进产品促进销售的根据,因此客观真实有效的交易评价是促进互联网商业形态健康发展具有重要意义。
另一方面,各种交易评论由评论者主观输入,由于各种原因出现了多种无效,无用,甚至虚假的垃圾评论,对互联网经济的发展产生了负面影响。同时,由于交易评论对后继交易判断的重要性,也出现了很多故意进行虚假评论以促进或打压特定卖家的行为,对互联网经济的发展的负面影响更为突出。因此,如何在海量的评论中识别并筛除垃圾评论,成为近期研究的热门课题之一[1]。
本文以海量评论信息中垃圾评论的有效智能识别为目标,首先发展了以往相关研究中对垃圾评论的认识,明确了垃圾评论的种类和判断标准,然后构造一种神经网络与决策树相结合的智能算法,发挥两种算法的优势达到高效准确识别垃圾评论的目的。最后,通过实证分析验证了方法的有效性和准确性。
1 相关研究
近年来,针对垃圾评论识别的研究在国内外逐步开展,Jundal在2007年最早进行了相关研究,将垃圾评论划分为虚假评论、无关评论和非评论,并运用Logistic回归模型对图书、音乐等其他制造类产品垃圾评论进行了识别[2]。Ott等以旅馆评论为研究对象,通过评论内容和语言特征,从心理学、文本语料等方面分析垃圾评论的特征,用SVM方法对旅店类垃圾评论进行了识别研究[3]。Mukherjee等在2011年使用频繁挖掘模式寻找被选群体,再通过计算垃圾信息值,使用SVM模型识别群体垃圾评论[4]。随后Mukherjee等在2013年基于内容相似度、最大评论数、评论重复度等评论人行为特征通过聚类分析对垃圾评论进行了识别[5]。国内方面,何海江对利用Logistic回归模型和利用SVM支持向量机的垃圾评论识别方法的性能进行了比较[6]。陈燕方通过对文本语料进行低可信度判断,提出了一种基于评论产品属性的情感倾向评估模型[7]。李霄等使用支持向量机模型对垃圾评论进行了识别,并通过与Logistic模型对比证明了机器学习算法的优势。目前大多数研究仅对评论进行了垃圾评论与非垃圾评论的二分类[8]。孟美任等虽然通过CRFs模型对在线商品评论进行了四分类识别,但识别的标准仅为评论的可信程度[9]。而实际上从欺骗性、干扰性、无效性的不同角度,垃圾评论可以分为不同的类别,不同类别之间在发布动机、危害程度、分辨难度上都有所不同,相应的治理方式也应该有所区别。因此,本文将从多维度对垃圾评论进行分类,并给出基于神经网络与决策树相结合的在线评论四分类模型,为不同类别的垃圾评论识别和治理提供技术支持。
2 在线评论的类别划分
根据评论发布者的目的、以及评论影响程度等方面的不同,可以将在线商品评论分为以下4类:
2.1 非垃圾评论
该类评论是消费者在购买、使用商品后,给出的真实的、客观的、详尽的体验描述,可以为后续消费者了解产品、决定是否购买提供参考,也可以为商家了解自我,有针对性的提升自我提供帮助,同时也是构建良好的、公平的网络购物环境的重要组成部分。
2.2 欺骗性评论
评论发布者出于推销或诋毁的目的,发布的与事实不相符的虚假性描述,或者是在极端的情感状态下,书写的过于主观的不真实评论。虚假评论中介与职业虚假评论者的存在使得大量的虚假评论充斥着网络,给消费者带来了极大的误导,严重干扰了电商的公平竞争环境,进一步还会对整个网络购物平台的生存带来不可估计的冲击[10]。
2.3 干扰性评论
此类评论类似于垃圾邮件,往往是出于广告宣传或者是单纯发泄的目的,因此常常包含电话号码、QQ号码或者网站链接地址。该类评论内容与所评价商品无关,对消费者误导作用较小,较易识别。
2.4 低效用评论
该类评论字数较少,常常是由于超出评价时间而由系统自动给出的系统性评价,或者是消费者为了赚取某些积分而敷衍性给出的并不涉及具体体验感受的简短评价。例如:好、不错、沙发等。
3 基于神经网络与决策树相结合的垃圾评论识别方法3.1 特征选择
特征属性的选择是识别方法研究的基础,不同商品或电商网站的特征决定了其评论的、特征可能有所不同,比如对电子产品的评论中对参数的描述可能会多一些,而食品类产品可能对送货速度更为敏感。增加属性选择的范围,并筛选针对特定交易类型较为有效的特征属性将对提高辨识准确度降低运算量有所帮助。依据垃圾评论特征和影响因素的相关研究,本文提出特征属性池的概念。特征属性池是和垃圾评论识别相关的有可能表现垃圾评论特殊性的属性的集合。针对不同商品类型,不同交易平台,有效的特征属性可能不尽相同,为了避免重复的人为选取特征属性造成的主观性影响、计算效率低等问题,本文在建立特征池的基础上,由后续的智能算法自主选取特征属性并建立识别模型。
目前的研究大多从评论内容和评论人两方面考虑,具体包括评论内容的翔实程度、评论的语法语义和结构特征、观点的倾向性、评论风格、时效、情感极性、评论者背景经验等。另外根据龚思兰等对在线商品信息可信度影响因素的实证研究[11],本文增加了文本情感倾向与评分的匹配度特征以及商家自身活动特征,共设定22个评论特征属性,如表1所示。
3.2 评估方法
决策树是一种树形分类器,通过各个节点对属性的选择最终得到符合误差标准的树形分类结构,相比于其它分类计算模型,决策树的突出特点是可以输出可读性规则。但是烦琐的离散化和后剪枝步骤计算代价较大,针对高维大数据库数据效率不高。为了对垃圾评论进行高效分类并且输出可读性规则用来监控分析网路交易从而有针对性的采取管理措施,同时避免后剪枝等计算,本文提出一种神经网络与决策树相结合的垃圾评论识别算法模型。该方法利用神经网络无须先验知识,主观输入少的特点对评论的特征属性集进行裁剪选择,降低了数据维度,同时避免了决策树后剪枝等复杂计算。其具体步骤为:
3.2.1 对连续属性运用BMIC算法离散化
BMIC离散化算法是一种基于以正规增益熵作为离散化标准的优化离散化算法。它证明了以正规增益为离散标准的离散区间分割点集合属于切点集合,进而通过合并临界点和小数点区间直接得到离散分割点避免了大量计算,而且可以根据分类结果自动生成最优离散区间个数不需要参数设定[12]。
3.2.2 按照归一化的输入输出关联值将特征池中的所有属性排序
该方法用样本值的变化而引起的输出变化的之和的归一化值UIOC作为衡量数据属性重要性的标准。属性的UIOC值越大属性越重要。UIOC的计算公式为:
UIOC(k)=1max(A)-min(A)∑x(i,k)-x(j,k)×signy(i)-y(j) i≠j
(1)
其中UIOC(k)为第k个属性的输入输出关联值,x(i,k),x(j,k)分别为第i,j个样本的第k个条件属性值。y(i),y(j)分别为第i,j个样本的决策属性值。max(A)为属性A的最大值,min(A)为属性A的最小值。
3.2.3 用径向基神经网络(RBF Neural Networks)对属性进行筛选
RBF是一种前馈三层网络,其神经元数量根据不同任务需要而自适应选定与初始赋权无关,具有良好的泛化能力和快速收敛的特性,适宜处理难以解析的规律性。取UIOC值最大的前50%属性用RBF神经网络进行训练及分类并和增减前后属性的RBF神经网络的分类准确率想比较,直到找到增减属性后分类准确率均下降时停止筛选。分类准确率最高的一组属性作为建立决策树的属性集合。
3.2.4 在筛选后的属性集合上建立正规增益为属性选择标准的决策树
NG(A,S)=∑4t=1-pilog2pi-∑j∈value(A)SjS∑4t=1-pilog2pilog2n
(2)
其中pi是属于类别t的样本占总样本数的比例。Value(A)为特征A的取值集合。S和Sj分别为样本总数以及特征A取值为j的样本个数。
3.3 垃圾评论识别流程
本文首先采用中科院计算技术研究所的ICTCLAS工具,并通过加入HowNet情感词典和自定义词典对评论语料进行分词和词性标注等预处理,再运用神经网络与决策树相结合的模型对数据进行分类。具体流程如图1所示:
4 网络交易垃圾评论识别实证研究
4.1 实验准备及实验过程
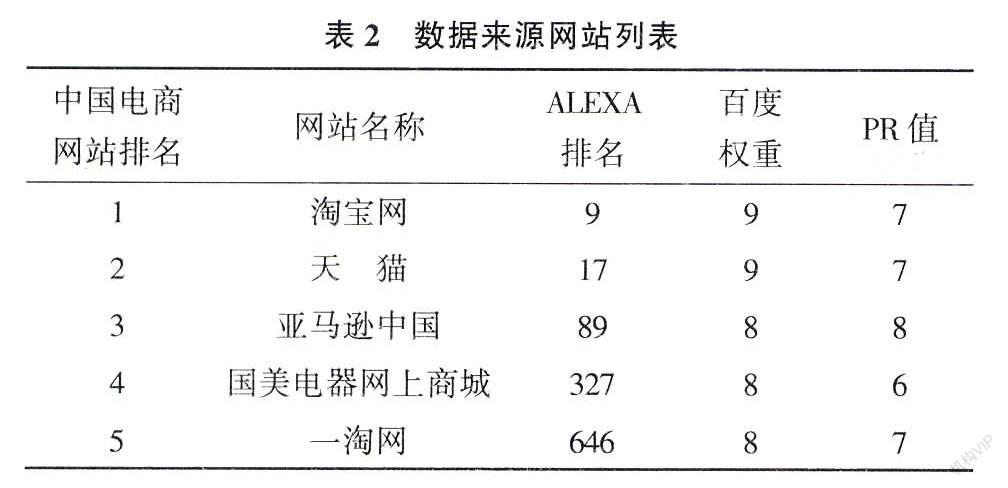
实验材料准备阶段首先根据Alexa中国电商类网站2014年的排名,选择前5名的如下电商网站作为实验数据采集的来源。
设定网络交易商品为数码相机、服装、图书3类,搜集2014-2015年的商品评价,选择其中的11 000条评论作为实验数据。选择3组志愿者,每组3人,在组内通过讨论人工标注评论类别,再对照3组结果,将人工标注结果不一致的评论去除,最终得到评论9 420条,其中非垃圾评论4 721条,欺骗性垃圾评论1 385条,干扰性垃圾评论659条,低效用垃圾评论2 655条。随机生成70%样本作为训练集,30%作为验证集。所有实验均在matlab软件上实现。
4.2 实验结果分析
实验是对每个验证集子例属于哪一类评论做出判断,属于四分类问题,文本识别常用查准率、查全率、综合F值3类性能评估指标如表3所示。由实验结果可以看出,本文方法对在线评论类别的识别效果较好,2 826个测试样本中有2 276个归类正确,总体准确率达到80.5%。在4类样本中,欺骗性垃圾评论是隐蔽性最强、识别率最低的,容易被误判为非垃圾评论。这是由于有些诋毁或推销目的的造假者为避免被发现,会在无关痛痒的问题上做细微的与自己目的相反的情感评价,以保持文本情感平衡。
为了进一步说明本文方法的有效性,将本文实验数据中的欺骗性、干扰性及低效用垃圾评论统一归纳为垃圾评论,再运用文献[8]中的基于SVM以及Logistic回归的方法进行垃圾评论识别,对比实验结果见表4。可以看到垃圾评论的查准率、查全率、综合F值以及评论总准确率方面,本文模型分别高于SVM模型0.9、2、1.5和3.3个百分点,另外值得注意的是文献[8]中的SVM及Logistic回归模型只是对商品评论进行了二分类,而本文则是进一步对垃圾评论进行了不同类别的划分,因此在难度上要高于简单的垃圾与非垃圾的二分类。如表2最后一行所示,如果只要样例被正确划分为垃圾评论,而不必考虑具体是欺骗型、干扰性还是低效用性垃圾评论,则本文试验结果在查准率、查全率、综合F值、总准确率上均远高于SVM模型。
为了进一步验证本文方法的稳定性,对以上数据采用4次交叉法重新实验,4次实验结果的各性能指标如图2~4所示:
图2 4次实验的查准率指标
因为训练集的子例是随机选取,使各个类型的子例在训练集中所占的比例不同,数据的结构会有所变化,但每组实验的识别精度大致相同,说明方法的稳定性较好。从筛选后用于建立决策树的属性来看,也存在比较稳定的趋势,具体情况如表5所示。
通过对实验生成规则集的归纳,可以发现以下主要规律:(1)内容不包含商品信息,且数字或字母超过一定字符数时,属于干扰性垃圾评论的概率较大。(2)低效用类垃圾评论在所有垃圾评论样本中所占比例最高,其识别的准确率也最高,大量的系统性评论以及单字或几个字的敷衍性好评仅通过文本长度即可识别。(3)欺骗性垃圾评论与非垃圾评论最容易相互误判,他们大都包含商品信息,在情感极性上欺骗型垃圾评论虽不如非垃圾评论均衡,但随着造假者经验的不断提高,单纯的文本类特征已不足以满足识别要求,评价者行为特征的加入可以使模型识别获得更优的效果。另外被广大消费者普遍认为十分重要的“评论者信用等级”在4次试验中只有2次入选模型,而评价频度和重复率因素却分别4次和3次入选。这与职业虚假评论中介以及大量的职业刷客群体的存在有着很大关系。职业刷客通过大量的交易往往拥有较高的信用等级,所以信用等级的高低在欺骗性评论识别中反而并非决定性特征属性。
5 结束语
随着网络交易的快速发展,对交易评论进行实时跟踪、有效识别各类垃圾评论并采取相应的有效治理策略是构建有序的电商竞争环境,促进网络交易健康发展的必然要求。本文使用神经网络与决策树相结合的方法,对网络交易在线评论进行了智能四分类识别。通过与文献[8]中模型结果的对比,证明了本文方法的有效性。随着移动互联营销的发展和电商评论要求的细分,垃圾评论特征可能发生变化,今后有必要随着要求的更新进一步优化模型。
参考文献
[1]聂卉,王佳佳.产品垃圾评论识别研究综述[J].现代图书情报技术,2014,(2):63-70.
[2]Jindal N,Liu B.Review Spam Detection[C].In:Proceedings of the 16th International Conference of Word Wide Web.Banff,Alberta,Canada.New York,NY,USA:ACM,2007:1189-1190.
[3]Ott M.Choi Y J.Cardie C,et al.Finding Deceptive Opinion Spam by Any Stretch of the Imagination[C].In:Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg.PA,USA:Association for Computational Linguistics,2011:309-319.
[4]Mukherjee A,Venkataraman V.What Yelp Fake Review Filter Might Be Doing?[C].In:Proceedings of the 7th International Conference on Weblogs and Social Media.Palo Alto:AAAI Press,2013:409-418.
[5]Mukherjee A.Liu B.Wang J,et al.Detecting Group Review Spam[C].In:Proceedings of the 28t h ACM International Conference on Information and Knowledge Management,Hyderabad,Indea.New York,NY,USA:ACM,2011:1123-1126.
[6]何海江,凌云.由Logistic回归识别Web社区的垃圾评论[J].计算机工程与应用,2009,45(23):140-143.
[7]陈燕方,李志宇.基于评论产品属性情感倾向评估的虚假评论识别研究[J].现代图书情报技术,2014,(9):81-90.
[8]李霄,丁晟春.垃圾商品评论信息的识别研究[J].现代图书情报技术,2013,(1):63-68.
[9]孟美任,丁晟春.在线中文商品评论可信度研究[J].现代图书情报技术,2013,(9):60-66.
[10]陈燕方,娄策群.在线商品虚假评论形成路径研究[J].现代情报,2015,(1):49-53.
[11]龚思兰,丁晟春,周夏伟,等.在线商品评论信息可信度影响因素实证研究[J].情报杂志,2013,(11):202-208.
[12]赵静娴,倪春鹏,詹原瑞,等.一种高效的连续属性离散化算法[J].系统工程与电子技术,2009,(1):195-199.
(本文责任编辑:孙国雷)
猜你喜欢
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
重型机械(2016年1期)2016-03-01
信息通信技术(2015年6期)2015-12-26
大连工业大学学报(2015年4期)2015-12-11
郑州大学学报(医学版)(2015年1期)2015-02-27
海军航空大学学报(2015年4期)2015-02-27
