
基于用户多页面浏览模式下的网络结构推荐系统的研究
2016-11-19 06:10朱立夫刘向东
智能计算机与应用 2016年5期
朱立夫 刘向东

摘要:针对用户普遍使用的多页面浏览器产生树型结构的浏览路径,web日志中将会呈现非时序的日志记录。本文提出了一种新的自上而下的用户访问路径收集算法,进而得出的用户在一次会话中可能访问的复数目的页面,由此得出全局目的页面访问频度矩阵,此矩阵的数据作为实现基于网络结构的推荐系统的核心数据。
关键字:访问路径树形;推荐系统;网络结构
中图分类号 TP274 文献标识码 A
Research on network structure recommendation system based on multi page browsing mode
ZHU Lifu1, LIU Xiangdong1
1(Changsha Furong Region People's ProcuratorateTechnical Department, Changsha 410016, China)
Abstract: Browsing path for the tree structure of multi page browser which is widely used by users, the web log will show non sequential log records. This paper presents a new top-down user access path collection algorithm, and then come to the complex page a user in a session may visit , resulting in a global page access frequency matrix. This matrix data could be used as core data based on the recommendation system from the network structure.
Key words: access path tree; recommended system; network structure
0 引言
在Internet电子商务网站中,客户在网站上的每一次点击,作为网站后台的Web服务器都会将这个动作如实地记录在日志中,这为分析用户访问频率、用户访问路径、用户访问目的等信息提供了数据来源。通过分析Web浏览日志,发现用户的访问模式,提取用户的访问兴趣,将得到的各种用户信息进行整合研究,从而生成有效的决策信息,即可为用户提供个性化推荐,同时还能进一步优化网站的拓扑结构。当前数据挖掘技术与Web日志分析已经实现了优质紧密结合。其中,Chen等人在1996年提出了可以将数据挖掘技术应用到Web领域中的思想,并且探讨基于Web事务的Web日志挖掘过程,用以发现用户的访问模式,由此又定义了最向前引用算法MF的概念。Zaiane等人则将Web服务器日志保存为数据立方体(Data Cube),然后对数据立方体进行数据挖掘和联机分析处理(OLAP)。而实现这些算法的前提是从Web日志中探究会话识别,并分离出用户会话,进而提炼出用户访问路径。针对用户普遍使用的多页面浏览器产生树型结构的浏览路径,Web日志中将会呈现非时序的日志记录。基于此,本文提出了一种新的自上而下的用户访问路径收集算法,运行得出用户在一次会话中可能访问的复数目的页面,由此得出全局目的页面访问频度矩阵,该矩阵的数据将可作为实现基于网络结构的推荐系统的核心数据。
1基于多页面浏览模式的用户访问路径的收集算法
用户访问路径树,指用户通过多页面浏览器访问模式浏览网页形成的网页访问路径。其中定义用户浏览网页的记录集,属性包括会话编号、用户编号、用户访问资源、用户引用页面、以及其他相关信息。具体来说,集合中就是经过数据预处理中的会话识别后得到的结果记录,其他信息则是根据需要添加的不同信息,比如页面大小,访问时间等等。此外,还需定义树的节点,内容包括用户编号、用户访问资源、孩子集合等。
在对Web日志数据进行去除冗余信息,用户识别、会话识别的预处理后,算法将自上而下地搜索用户会话记录,重点关注了记录中的用户访问资源、引用页面和用户信息等属性。该主题算法的基本思想为:首先从单个会话记录的顶部发起搜索,通常第一条记录为用户访问的初始页面或者是从其他网站跳转过来的页面,此页面就会作为新建用户浏览树的根节点。继续向下展开记录搜索过程,对记录进行分析,考察记录的引用页面,是否为先前已建立的树的节点。如果是,则加入树模型中;如果不是,即以此记录的访问页面为根节点,再建一棵用户浏览路径树。直到将此会话记录全部搜索完毕,算法执行结束。
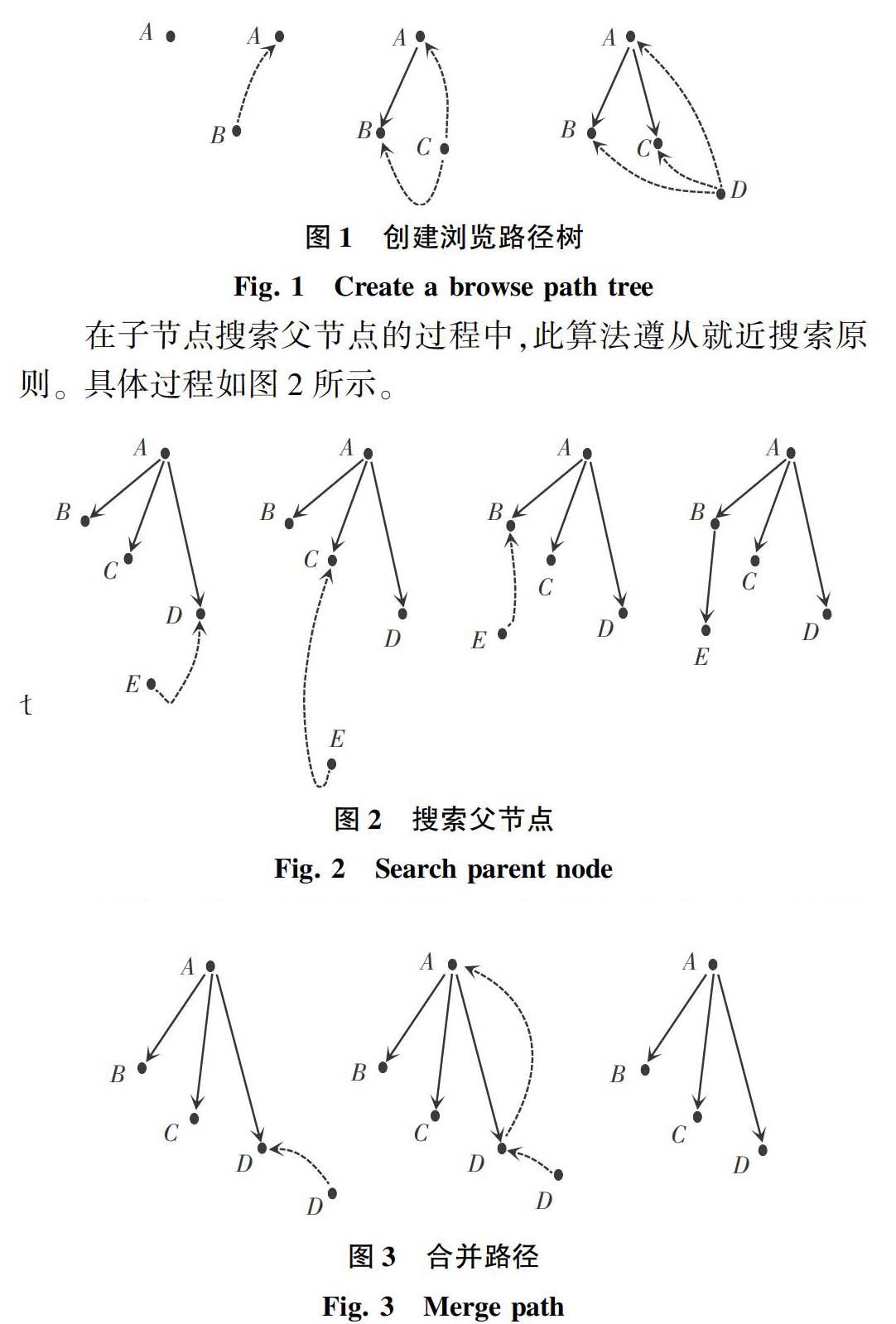
以图1所示的用户浏览情况为例算法的识别过程如下。
如图1所示,首先搜索第一条记录,把A节点作为用户浏览树的根节点。继续向下搜索记录,搜索到B页面所对应的记录。考察此记录的引用页面,引用页面为A页面,将B页面作为A页面的子节点,继续向下搜索。此后将C页面和D页面也加入到A页面所对应的节点下。
在子节点搜索父节点的过程中,此算法遵从就近搜索原则。具体过程如图2所示。
由图2可知在搜索到访问E页面的记录时,E记录是从最后添加的D节点开始搜索的,然后搜索C节点,在搜索B节点时发现与记录的引用页面相符合,所以将E页面添加到B的孩子节点中去。在用户有多棵用户浏览树的情况下,搜索情况也与上面相似,先搜索最近生成的用户浏览树。在搜索会话记录的过程中可能会出现重复数据,即在不同的时间访问了相同的资源并且引用页面也相同,可能是用户使用同一种方式即点击了同一超链接反复访问了同一资源,遇到这样的情况需要合并记录。这一做法的处理实现过程如图3所示。
解析图3可知,如果在搜索会话记录过程中,搜索到了第2个关于D页面的记录,向上搜索父节点的过程中遇到了一个与自己相同的页面,需考察此页面的父节点,如果与自身的引用页面相同则合并记录。
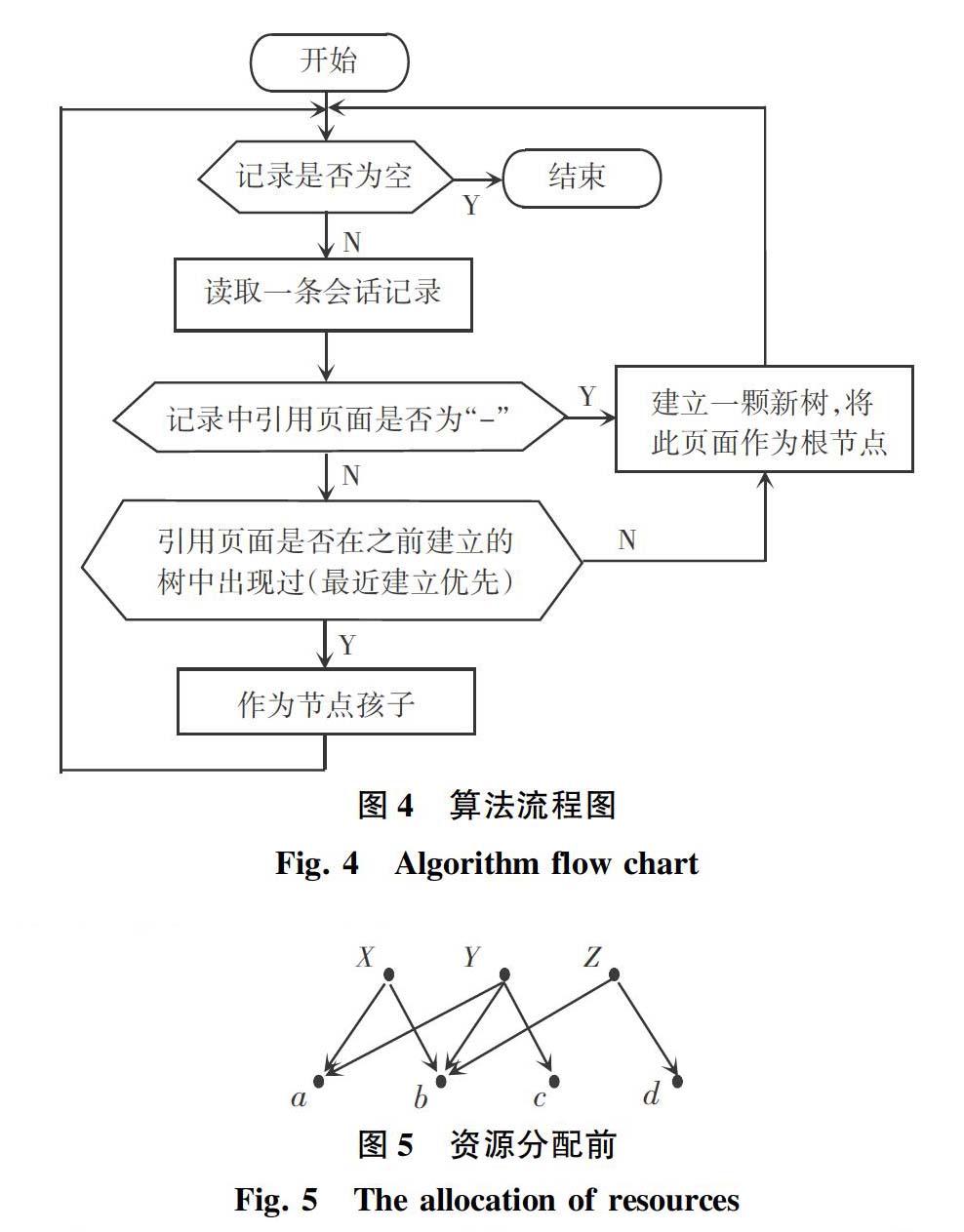
综上可得,整个算法实现流程如图4所示。
实验数据是某商业网站日志中分离出来的711个用户,使用一般用户访问路径识别算法,最终获得了1 352个路径,其中的1 076个路径均属长度为2的短路径。而使用本文算法则总共得出839棵用户访问路径树,但可标识为2个节点的树却仅有517棵。这一结果说明本算法在收集用户访问路径上,把现有算法中并未收集到的大量短的访问路径均已成功合并到了用户访问路径树上,从而减少了短路径的生成数目。
2基于用户多页面浏览模式的网络结构推荐系统的实现
2.1 推荐算法实现
基于网络结构的推荐算法并不考虑用户和对象的内容特征,而只是将其视作图结构中的一个个单元节点,算法所利用的信息是用户和对象之间的选择关系。在基于网络结构的推荐系统中通常会构建一个二部分网络,其中用户和对象分别构成2个节点集。定义用户集合U,表示为: 。定义对象集合C,表示为: 。通过用户选择对象构成一个 的邻接矩阵。在该矩阵中如果用户j选择了对象i,则元素 的值为1,否则该元素的值为0。算法的目的就是对于任意的用户k,对其还未经历选择的所有对象可依照k的浏览行为、兴趣爱好等方面的因素进行打分,预测k关于这些对象的喜爱程度,并将其提供有效排序,最后再将排名前若干位的对象推荐给用户k。
研究假设用户i选择了若干对象,这里可以看成用户将可调度精力或者金钱平均施付于这若干个对象上。在此,给出演示实例如图5所示。
由图5可见, X、Y、Z分别代表3个用户, 则为可供其选择的对象。诸如,用户X选择了对象a、b。在没有预设加权的情况下,说明用户X将自己的资源平均分配到了所选择的2个对象上。综合其他2位用户,最终分配结果可如图6所示。
综上结果可知,此次分配之后每个对象都得到了用户一定量的资源,这取决于资源选择的用户个数以及用户选择的对象个数。研究过程推理得到对象所产生的资源量可以表述为:
(1)
式中, 表示用户i所选择的对象C。并且:
3结束语
针对用户普遍使用的多页面浏览器产生树型结构的浏览路径,本文提出了一种新的自上而下的用户访问路径收集算法。此算法能够收集到的用户访问路径树,合并短路径到用户浏览树上,减少了短路径的综合实际生成。由此得出全局用户浏览目的页面访问频度矩阵,此矩阵的内容作为实现基于网络结构的推荐系统的核心数据,实验表明建立交叉页面访问频度矩阵在实现基于网络结构的推荐上具有可行性。
参考文献
[1] BüCHNER A G, ANAND S S, MULVENNA M D, et al. Discovering Internet marketing intelligence through Web Log Mining[J]. Sigmod Record,1999,27:54-61.
[2]
Cooley R ,Mobasher B, Srivastava J. Grouping Web Page References into Transactions for MiningWorld Wide Web Browsing Patterns[R]. Minneapolis: University of Minnesota,1997.
[3] CHEN M S, PARK J S, YU P S. Data mining for path traversal patterns in a web enviroment[C]//16th International Conference on Distributed Computing Systems. Hongkong: IEEE Computer Society, 1996: 385-392.
[4] 夏明波,王晓川,孙永强,等. 序列模式挖掘算法研究[J]. 计算机技术与发展, 2006, 16(4): 4-6,10.
[5] 韩家炜,孟小峰,王静,等.Web挖掘研究[J].计算机研究与发展,2001,38(4):405-414.
[6] 张建喜.面向Web日志数据挖掘的研究与应用[D].济南:山东师范大学,2006:12-14.
[7] 乔良.基于马尔科夫模型的用户浏览路径预测研究[D].秦皇岛:燕山大学,2007.
[8] 李静,宋翰涛.创建企业级数据仓库的关键技术[J].计算机应用研究,2001,22(5):90-93.
[9] 纪良浩,王国胤,杨勇.基于协作过滤的Web日志数据预处理研究[J].重庆邮电学院学报(自然科学版),2006,18(5):646-649.
[10] 邓英,李明.用户访问模式挖掘中数据预处理问题的研究[J]. 计算机工程与应用,2002,38(1):188-190.
[11] 刘维娜.Web 日志挖掘相关技术[硕士学位论文].哈尔滨:哈尔滨工程大学,2006.
[12] 刘培刚.Web 挖掘技术在电子商务中的应用研究[J].情报学报,2002,21(6):680-685
[13] YAN T W, JACOBSEN M, GARCIA-MOLINA H, et al. From user access patterns to dynamic hypertext linking [J]. Computer Networks & Isdn Systems, 1996, 28(7-11):1007-1014.
[14] SHAHABI C, ZARKESH A, ADIBI J , et al. Knowledge discovery from users web-page navigation[C]//Proceedings of the 7th International Workshop on Research Issues in Data Engineering (RIDE '97) High Performance Database Management for Large-Scale Applications. Washington,DC,USA,IEEE Computer Society,1997:20-31.
[15] FU Y, SANDHU K, SHIH M Y. Clustering of Web users based on access patterns[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining Workshop on Web Mining. SanDiego,CA:ACM, 1999:560-567
朱立夫(出生年1987),男,硕士研究生,高级工程师,主研领域:数据挖掘、支持决策,身份证号:430102198708034033,手机:13974864354,单位:湖南省长沙市芙蓉区人民检察院,邮编:410016;E-mail:378546859@qq.com
刘向东(出生年1986),硕士研究生,高级工程师,主研领域:数据挖掘、数据库,身份证号:43122419860119543x,手机:13755050784,单位:湖南省长沙市芙蓉区人民检察院,邮编:410016;E-mail:lxd-nan@163.com
通讯地址:湖南省长沙市芙蓉区恒达路87号,邮编:410016
猜你喜欢
经济研究导刊(2022年17期)2022-06-30
电脑爱好者(2021年21期)2021-11-04
动漫界·幼教365(中班)(2021年4期)2021-05-23
诗选刊(2020年12期)2020-12-03
电脑爱好者(2020年17期)2020-09-14
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
