
基于SVM模型的恶意PDF文档检测方法
2016-11-14 00:58徐建平
电脑知识与技术 2016年24期
徐建平
摘要:该文针对现有的PDF文档检测方案存在准确度低、易混淆等问题提出一种基于SVM模型的智能检测方法,同时结合PDF文档格式分析技术,实现对恶意PDF文档的检测。论文先对PDF文档中JavaScript代码进行定位、提取、解码、去混淆化等处理,得到原始的JavaScript代码。然后对得到的原始JavaScript代码提取相应的特征向量,再利用SVM分类器进行静态检测。最后对检测出来的恶意PDF文档的JavaScript代码中恶意代码部分shellcode部分,利用libemu仿真工具实现行为模拟运行,得到详细的恶意行为报告。实验表明该方法能有效检测出恶意的PDF文档,检测率有所提高,漏报率明显降低。
关键词:PDF文档;JavaScript代码;SVM
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)24-0090-03
Abstract:In order to solve the problem of low accuracy and easy to confound in view of the existing PDF document detection scheme. In this paper, an intelligent detection method based on SVM model is proposed, which is combined with the PDF document format analysis technology to realize the detection of malicious PDF documents. First, the paper on the PDF document JavaScript code for positioning, extracting, decoding, to be confused, and other processing, get the original JavaScript code. Then extract the corresponding feature vector from the original JavaScript code, and use the SVM classifier for static detection. Finally, the malicious code in the JavaScript code of the detected malicious PDF code part of the shellcode, using libemu simulation tool to achieve the behavior of the simulation run, get a detailed report on the malicious behavior. Experimental results show that the method can effectively detect the malicious PDF document, the detection rate has increased, the false negative rate decreased significantly.
Key words:PDF document; JavaScript code; SVM
1 背景
2008年以前恶意代码对PDF[1]文档的利用技术还不是很成熟,相应的PDF文档漏洞还比较少,其主要的检测方式都还处在特征码扫描的阶段。随着PDF市场占有率的迅速提高,PDF漏洞也开始增多,因为Office漏洞越来越少,而利用难度也越来越大,同时对恶意Office文档的检测技术已经非常成熟,于是PDF代替Office成为热门的恶意代码的有效载体。由于恶意代码对计算机的严重破坏性,检测和防止含有恶意代码的PDF文档已成为计算机安全领域的重要目标。
目前,针对PDF攻击方式大多数都与JavaScript相关,其检测模型主要有三类:基于特征码的静态检测模型、基于跟踪JavaScript行为的动态检测模型以及动静结合检测模型。2012年,Laskov和NedimSrndic提出了针对PDF文档第一个静态检测模型——PJScan模型[2]。PJScan模型开创性地实现了从 PDF文档中提取JavaScript代码,并且真正实现了对恶意 JavaScript代码的静态检测。但是该模型也有不足之处。首先,在提取JavaScript代码时没有对JavaScript代码进行去混淆化处理,这样导致提取到的特征向量被无用的信息所充斥,导致有用的特征向量的权值降低,影响检测率。其次,采用的one-class SVM分类算法允许一定比例的样本点超出范围,这样漏报率会提高。
针对以上缺点,本文提出一种基于SVM模型的检测方法,首先对提取到的JavaScript代码进行解码与去混淆化等处理,然后考虑样本规模影响运行速度,使用LibSVM分类器。此外,对已经判断出的恶意样本中shellcode部分,利用libemu仿真工具实现行为模拟运行,得到详细的恶意行为报告。
2 基于SVM模型的恶意PDF文档检测方法
2.1 检测流程
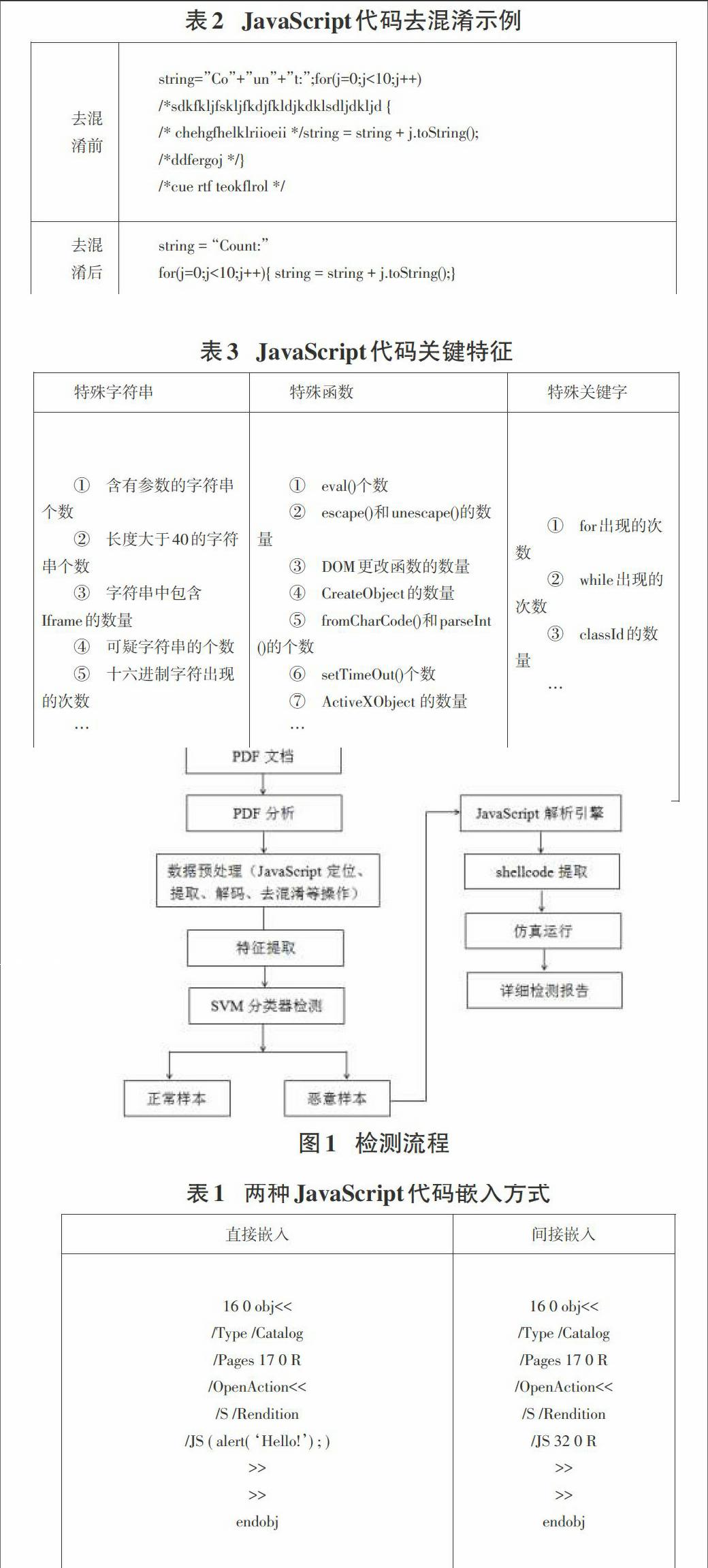
本方法的检测流程主要分两部分,第一部分主要是对实验样本进行检测,第二部分主要提取判断出来的恶意样本的shellcode部分进行仿真运行,得到详细的检测报告。如图1所示。
2.2 数据预处理
嵌入到PDF文档中的JavaScript代码极大地丰富了PDF 文档的功能和显示效果,这也就给了攻击者编写具有恶意行为的 PDF 文档的机会,但是PDF文档中的JavaScript 代码通常是经过编码压缩和对象间接引用处理后的。因此在提取JavaScript代码之前要对PDF文档结构进行分析,然后对定位的JavaScript流对象进行解压缩,最后才能将其提取出来。
1)JavaScript代码定位与提取
在PDF文档中,JavaScript代码通常绑定在活动字典上,会以一些关键字进行标识,而且主要嵌入在关键字“/JS”的字典中。JavaScript代码有两种嵌入方式:通过/JS关键字直接嵌入和通过/JS关键字间接调用。两种嵌入方式对比如表1所示。
对于提取JavaScript代码有两个重要的标识:/JavaScript和/Rendition。在一般的PDF文档中,可以根据这两个标识定位到JavaScript代码的入口位置。如果以/Rendition 为标识,则必须有一个关键字/JS,如果以/JavaScript为标识,则不一定有关键字/JS。/JS字典中包含JavaScript代码,因此就可以提取到相应的JavaScript代码。
2)JavaScript代码解码
如果JavaScript代码嵌入方式是间接引用的话,就必须对间接引用对象中的内容进行解码操作。解码步骤:①调用静态函数GetAllObjectBlobs,返回流中的所有字符;②判断是否有“FlateDecode”字段,没有跳到④;③调用解码函数FlateDecodeToASCII进行解码;④保存结果。
3)JavaScript代码去混淆处理
攻击者为了躲避检测,使用各种混淆技术进行逃避。攻击者所使用的混淆技术主要有两种:字符串分割技术和增加冗余代码技术。字符串切割技术是将一字符串切割成若干个子串,然后使用字符连接操作符将字符串连接起来;增加冗余代码技术是在代码中添加大了大量的无关注释,增加有效特征码的提取难度。
因此,在进行特征提取之前,需要对JavaScript代码进行去混淆处理,首先需要删除与JavaScript代码运行无关的注释,即如果有以“/*”为起始点和以“*/”为结束点的字符串,则直接删除;其次将切割后的字符串进行还原操作,即如果代码中有 “+”字符,并且前一个字符“"”,且后一个字符“"”,则删除这三个字符。JavaScript代码去混淆示例如表2所示。
2.3 特征向量提取
恶意代码中会出现很多特殊的函数或者特殊的字符串,比如0c0c,0a0a,%u,spray,crypt 等字符、一些通用函数(eval()、escape()、unescape()、replace()、fromCharCode()),以及一些常用的存在漏洞的函数(getIcon()、Collab())。因此,本方法采用一些特殊字符串、特殊函数、特殊关键字出现的次数作为是否恶意代码的判断依据。本文根据文献[3]得出一些JavaScript代码的关键特征如表3所示。
2.4 SVM分类器检测
支持向量机(Support Vector Machine,SVM)分类器是一种监督式的学习方法,广泛应用于统计分类以及回归分析。针对训练样本较大导致训练速度下降的问题,台湾林智仁(Chen-Jen Lin)教授与2001年开发了一套支持向量机的库LibSVM[4],该库运算速度快而且开源,相比较SMO算法运行快得多,因此选择LibSVM构建SVM分类器。
利用上一小节得到的JS特征向量集进行训练得到最优的SVM模型,然后利用该模型对测试样本特征集进行分类。基于SVM模型的特征训练及测试步骤如下:①收集实验样本;②按照表3提取关键特征,并对正常样本的特征和恶意样本特征进行标记;③使用Weka平台中LibSVM方法,采用十字交叉验证方法调整相关参数对特征集进行训练,获取最优的SVM模型的参数;④利用训练得到的模型对测试样本进行分类。
2.5 shellcode分析
通过1.2小节提取到的JavaScript代码中一般都包含了shellcode代码,大部分的PDF文档中所包含的恶意代码都隐藏在shellcode代码中。但是大多数情况下攻击者对该部分进行了压缩和模糊化[5]。因此,要先利用 JS 解析引擎对其进行解混淆操作,以便能够通过libemu仿真模拟执行其代码,进一步分析shellcode代码的执行路径。
从JavaScript代码中提取出来某个字符串包含的一段shellcode功能代码:“u0E8A%u55FF%u5704%uEFB8%u6A3C%u5A44%uE2Dl%uE22B…..%uEOCE%uFF60%u0455%u7468%u7074%u2F3A%u642F%u6C6F%u6170%u7373%u6967%u6576%u2E6E%u7572”。然后将其转换为十六进制的机器码。
libemu是一款用C语言实现的基于x86的shellcode检测的库。这里通过使用libemu加载转换后的十六进制码,从而达到对shellcode进行检测,包括使用GetPC启发式检测、静态分析、二进制方式的动态分析、Win32API HOOK等。
为了增强分析报告的可读性,报告生成条目按不同资源类型的行为加以分派,并通过用文本文件的形式呈现出来,供分析人员参考使用。
3 实验分析
3.1 数据收集
为了验证方法的有效性,本文的恶意PDF文件从Virustotal,VX Heavens上收集了恶意PDF文档100个,收集了正常文档200个,所有正常文档均为平时日常使用的文档。
3.2 评估策略
在检测中,采用检测率(TP) 即正确分类的恶意代码数与恶意代码总数的比值和误检率(FP) 即正常文件被认定为恶意代码数与正常文件总数的比值来评价检测方法的优劣。分类准确率(ACC) 也被应用到检测算法优劣的评估中,其为正确分类的样本数与所有测试样本数的比值。
3.3 有效性验证
为了验证本文提出的方法的有效性,使用Weka平台中LibSVM方法,采用十字交叉验证方法调整相关参数对特征集进行训练,获取最优的SVM模型的参数,然后,利用训练得到的模型对测试样本进行分类,最后将本文提出的方法实验结果与PJScan模型的实验结果进行比较,如表4所示。
4 结束语
本文提出了一种基于SVM模型的智能检测方法,对提取到的JavaScript代码进行解码、去混淆化处理等处理,保证提取的特征向量的质量。然后考虑到样本规模以及检测速率的问题,采用LibSVM分类器进行特征的训练和学习。在Weka平台进行仿真实验表明该方法对PDF文档检测的检测率有一定提高,漏报率有一定程度上的降低。此外,对已经判别出的恶意样本中shellcode部分使用libemu仿真工具进行模拟运行,从而能够提高分析人员快速修复漏洞的效率。
参考文献:
[1] PDF Reference.Adobe Portable Document Format[Z].Version 1.7, 2006.
[2] Laskov P,Nedim Srndic.Static detection of malicious JavaScript-bearing PDF documents[C]//Proceedings of the 27th Annual Computer Security Applications Conference. ACM, 2011: 373-382.
[3] Likarish P,Jung E, Jo I. Obfuscated malicious JavaScript detection using classification techniques[C]. IEEE,2009:47-54.
[4] 林智仁. LIBSVM -- A Library for Support Vector Machines[EB/OL]. http://www.csie.ntu.edu.tw/~cjlin/libsvm
[5] Porst S. How to really obfuscate your PDF malware[C]. RECON, 2010.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
中国石油石化(2022年12期)2022-07-16
保定学院学报(2022年2期)2022-04-07
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
