
基于相关距离Fisher比的混合参数用于说话人识别
2016-11-11 05:40唐宗渤王茂蓉周
大众科技 2016年1期
唐宗渤王茂蓉周 萍
(1.桂林电子科技大学信息科技学院,广西 桂林 541004;2.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004)
基于相关距离Fisher比的混合参数用于说话人识别
唐宗渤1王茂蓉2周 萍2
(1.桂林电子科技大学信息科技学院,广西 桂林 541004;2.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004)
为了得到更具区分性的特征参数,采用改进的MFCC提取方法,即低方差性的多窗谱估计MFCC,并在其基础上引入了短时TEO能量和 MFCCΔ动态特征参量组合特征进行说话人识别。由于直接将两者进行组合会造成维度过高,计算复杂度增加,为此提出了相关距离Fisher比来对特征参数进行加权和维度筛选,最后送入GMM-UBM分类器模型进行识别。实验表明,改进的混合特征参数相较于单一的特征参量,具备更好的识别能力,使得识别率有一定程度的提高。
说话人识别;多窗谱MFCC;相关距离Fisher比;TEO;混合特征
说话人识别系统已经在社会各个领域得到了广泛的应用,如司法侦查、电子商务和金融等领域,是国内外研究的热点,其发展已比较成熟,但如何进一步提高说话人识别率是语音识别领域一个热门课题。目前最常见的特征参数有MFCC参数、LPC参数、LPCC参数、HHT倒谱系数、基因频率等[1]。
其中MFCC反映人对语音的感知特性,相对于其它特征具有强抗噪性,高识别率的特点,已成为说话人识别领域应用最为广泛的特征参数。但MFCC也存在一些不足,如实时性不够理想,高方差性的缺点,对此,许多研究者在对MFCC的提取方法上进行改进,文献[2]提出用观察性的多窗谱估计来代替传统的提取 MFCC算法中的单级窗和离散傅里叶变换,使得系统具有更好的系统鲁棒性。文献[3]首先对MFCC特征参数进行研究,求取其差分和加权Mel系数,将它们进行维度筛选和扩张,得到混合特征参数,使得系统的鲁棒性得到提高,但其运算量过大,因此,本文提出的改进算法是在多窗谱MFCC的基础上加入短时TEO能量,来提取EMFCC和一阶差分 MFCC。由于简单的将两者进项组合会带来大量的冗余信息,达不到预期的效果,反而会增加系统的运算开销,故本文提出使用相关距离Fisher比,相比于传统的Fisher比只能反映每维参数对识别系统的贡献大小,该算法将每维参量间的相关性考虑进去,选出可分程度相对较大的分量,进行加权降维,组成新的混合参数。通过实验验证,该混合特征提高了系统的整体识别性能。
1 特征参数提取
特征参数的选取影响系统识别的好坏,本文利用多窗谱提取 MFCC,并加入 TEO能量,然后提取出 EMFCC、ΔMFCC ,利用相关距离Fisher比来对其进行降维,然后对说话人识别贡献大的参量加以相对较大的权重系数,构造出混合特征参量。相比于传统的 MFCC,本文所提算法将表征语音信号时域特征的一阶差分MFCC和反映语音信号能量特征的 EMFCC相结合,得到更能完整描述说话者个性特征的混合参数。又由于特征参数的维数越多,计算量就越大,相比于文献[3]将差分和加权Mel系数组合得到17维的特征参量,而我们所求的混合参数是12维的,使得系统识别性能提高的同时大大降低了计算复杂度。综上,本文所提方法理论上是有效的。
1.1 多窗谱MFCC
文献[10]等提出Mel倒谱系数,能够很好地描述语音信号的频率特性。利用Mel三角滤波器组提取MFCC特征参数。其中,MFCC特征参数是在Mel频率尺度上提取出来的,两者之间的转关系换如(1)式所示,
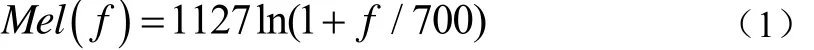
式中:f为频率,单位为Hz。
首先用一阶数字滤波器对语音信号进行预加重,再对预加重过的语音信号分帧加窗处理。然而,在对信号加窗分帧处理操作时,短时分析的参数特征的优劣取决于窗函数的选取。通常语音信号加窗采用单级窗函数,而单级窗虽然减少了频谱估计的偏差,却使得信号频谱估计仍存在较大方差[10]。为减小信号中设备信息的频谱损失有效保留大部分频谱信息,本文使用多窗谱估计代替单级窗,其原理框图如图1所示,

图1 提取多窗谱MFCC参量
其公式如下:
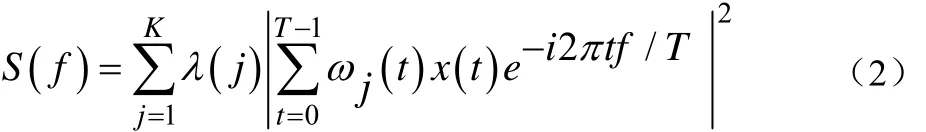
由图2可知,多窗谱函数不仅可以减少语音的频谱损失,而且还能提升语音的低频部分,多窗谱的这个优点有效地提高了了传统MFCC低频部分的噪声鲁棒性,有利于对后续特征参数的分析选取。另外,通过一系列的实验测试,当子窗个数为 6个时,无论是系统识别率还是运算时间都能达到最佳,所以本文多窗谱函数子窗个数为6个。
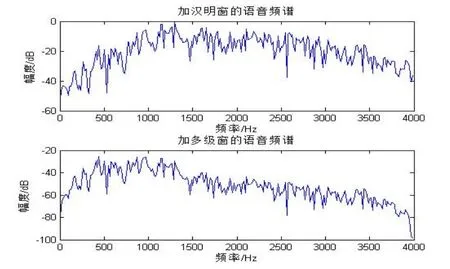
图2 加单级窗(汉明窗)和多窗谱的语音频谱对比
提取MFCC参数具体步骤[6]是将进过上述预处理后的信号Xt(τ)对其取模的平方,然后送入 Mel三角滤波器组滤波,求取对数能量,再对输出向量作DCT,得到MFCC,提取。计算公式如下,

其中:n为所取MFCC的个数;Cj(n)为第j帧的第n个MFCC系数;Sj(m)为语音信号的对数能量谱;M为24即滤波器数。除去代表直流成分的Cj(0),得到Cj(1),…,Cj(n),然后由式(6)求取表征信号动态特性的ΔMFCC系数Dt(n),
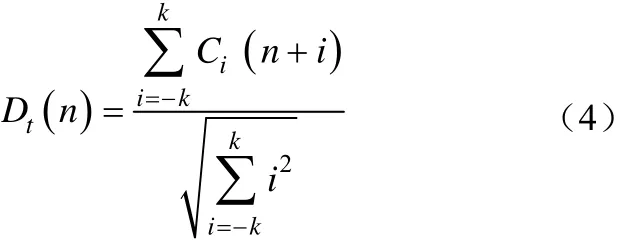
其中,k为常数,一般取为2。
1.2 短时TEO能量
Teager能量算子(Teager Energy Operator,TEO)实际上是一个非线性算子,它是由Teager等人[6]提出的,能够很好地表征信号的瞬时能量值,将其加入到特征参数中,辅助进行说话人识别。但我们首先要对 TEO能量进行归一化处理,并求其对数能量。TEO的具体求取过程是,先求TEO,并对其分帧加窗,最后求各帧信号的TEO能量,其计算公式为式(5)

其中,(ETEO)t是第t帧的TEO能量,τ为每帧样点数;L为帧长,本文取为256。
对其进行归一化能量并取其对数,其计算公式如(6),然后把其加入到MFCC特征向量的第一维,组成EMFCC特征向量,最后与MFCCΔ经相关距离Fisher比加权和维度筛选,组成混合参数。
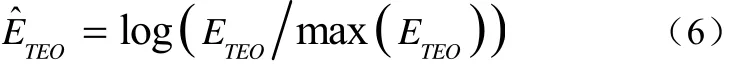
2 相关距离Fisher准则加权降维
通过以上对特征参数的提取,笔者得到了12维的EMFCC和12维的MFCCΔ,若直接把它们混合,得到了24维混合参数,造成信息的冗余。不仅增加系统的运算量,而且由于不同的特征参量所包含的表征说话人的个性特征的信息不同,对识别的贡献也各不相同,故不能将每维特征向量都同等对待。为消除冗余信息,笔者采用相关距离 Fisher准则,其中Fisher比的计算公式(7)所示,

其中,ui、u代表第i个说话者和全部说话者参量均值估计,代表第i个说话者第j句话的特征参数,i=1,2…M;j=1,2…N 。
从式(7)可以看出Fisher比只能反映每维参数对识别系统的贡献大小,但未将每维参量间的相关性考虑进去,故本文相关距离的 Fisher比来进行加权降维。相关距离顾名思义就是指每一维特征参数与其他各维参量之间的距离,它的值越大,则表明该维参量与其他维参量间所包含的共同信息就越少,它们之间的相关性也就越弱。该准则有效地克服了Fisher比的局限性,避免了每两维特征之间重叠的过多的信息,造成信息的冗余,增加系统的开销,更好的筛选出能表征说话人个性特特征的有效维度,提高系统的整体性能。其公式如式(8)和(9),
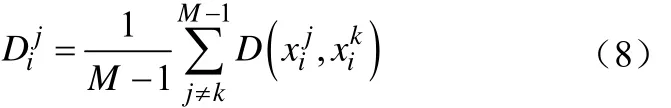

通过式(9)可知,H和F之间是成正比关系的,但和相关距离成反比关系,也就是说 F的值越大,相关距离 Fisher比H也就越大。图3给出了MFCC的相关距离Fisher比,由图可知,MFCC第一维的贡献值是最小的,故用短时TEO能量代替第一维,理论上说明,该混合特征是有效的。图 4给出了EMFCC和MFCCΔ每一维参量之间的相关距离Fisher比。
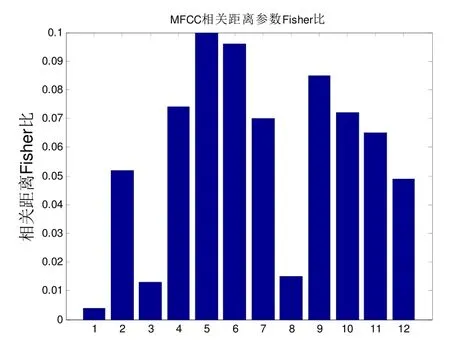
图3 MFCC参数相关距离Fisher比

图4 两个参数各维分量的Fisher比
从图3中可以看出,MFCC最后一维的贡献值式最小的,故用短时TEO能量来代替最后一维向量;从图4中可以看出,不同分量的相关距离 Fisher比的值是不同的,表明对说话人识别贡献值也是不同的,笔者则根据图 4分别选出 EMFCC和差分MFCC中区分度最大的6维构成12维的混合特征参数,对相关距离 Fisher比大的赋予较大的权重系数,反之则赋予相对较小的权重系数,通过上述这种加权降维区分了不同维特征向量对说话人识别系统的的贡献。
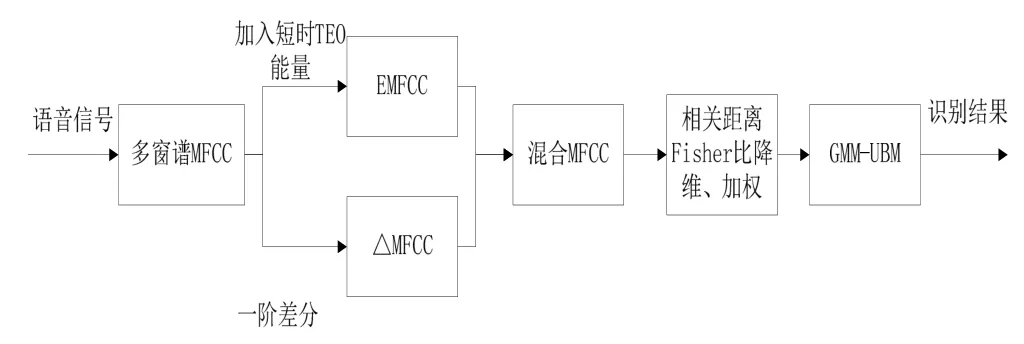
图5 本文算法系统原理框图
3 结果与分析
实验使用50人语音库(男女各25),每人分别录制10段长约3 s的语音,7段用于训练,3段用于测试,采样频率8 KHz,采样精度16 bit。在同一背景噪声,不同信噪比下,进行说话人识别,其中实验中均采用16阶GMM-UBM作为识别模型。通过实验可知,本文方法原理简单,且计算量相对较小,在信噪比较低时识别率也能较高。
为了证明本文所提混合特征参数的有效可行,表1给出了四种不同信噪比下对传统MFCC与多窗谱MFCC进行实验。表2给出了文献[3]算法与本文所提算法识别率的对比。表3给出了两种不同降维方法的识别率对比。图6给出了相关距离 Fisher比在对特征参数进行加权前后系统识别率的比较。

表1 传统MFCC和多窗谱MFCC识别率的对比

表2 文献[2]算法与本文算法识别率对比
由表1可知,相较于传统MFCC,本文选用的多窗谱估计MFCC的识别率在各种噪声环境下均略高一筹,进而证明了本文使用多窗谱代替单级窗和离散傅里叶变换的提取算法的有效性。由表2可以看出,本文所提方法识别率在四种信噪比环境中都高于文献[2]所提方法识别率,有力的证明了短时TEO能量中含有对说话人识别有用的信息,从而进一步证明本文所提算法是可行的。

表3 两种降维方法对系统识别率的对比
由表3可知,本文采用基于相关距离Fisher准则进行参数降维加权后的系统识别率均在基于 Fisher比算法之上,特别是在信噪比相对较低的环境下,本文所采用的降维加权算法仍然保持了较高的优越性,提高了系统的噪声鲁棒性。通过表1、表2、表3和图6说明了本文算法在没有提高复杂度的同时,使说话人识别率相对于文献[2]有将近3%的提升,从而更加有力的说明了本文所提算法是可行的。
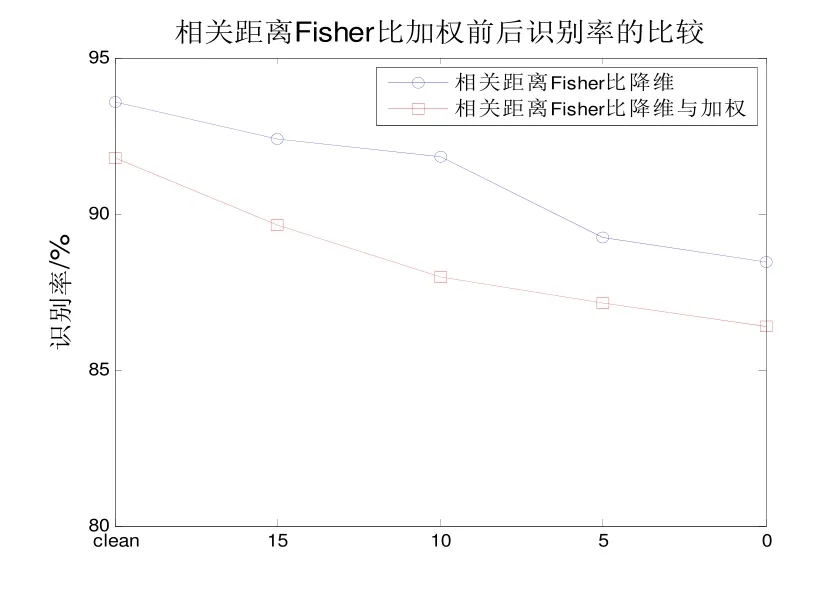
图6 相关距离Fisher比对特征参数加权前后系统识别率的比较
4 结论
本文首先针对传统MFCC提取算法实时性差和高方差性的缺点,提出了多窗谱估计 MFCC,然后将分别表征说话者动态特性与时域特性的EMFCCMFCCΔ引入MFCC参量中,最后通过相关距离 Fisher比对参量进行加权降维,并通过GMM-UBM的说话人识别系统进行说话人识别。实验结果表明,在信噪比相对较低的环境下,本文所提算法在没有增加计算复杂度的同时,提高了系统的整体识别性能,增强了系统对噪声的鲁棒性。
[1] 赵力.语音信号处理[M].北京:机械工业出版社,2012.
[2] Kinnunen T,Saeidi R,Sedlák F,et al.Low-variance multitaper MFCC features: a case study in robust speaker verification[J].IEEE Trans. on Audio,Speech,and Language Processing,2012,20(7):1990-2001.
[3] 柯晶晶,周萍,景新幸,等.差分和加权Mel倒谱混合参数应用于说话人识别[J].微电子学与计算机,2014,31(9):89-91.
[4] 鲜晓东,樊宇星.基于 Fisher比的梅尔倒谱系数混合特征提取方法[J].计算机应用,2014,34(2):556-558.
[5] 李杰,周萍,杜志然.短时TEO能量在端点检测中的应用[J].计算机工程与应用,2013,49(12):144-147.
[6] Teager H,Teager S.Evidence for nonlinear sound production mechanisms in the vocal tract[M].Speech Production & Speech Modeling.[S.l.]:Springer,1990:241-261.
[7] 王伟,邓辉文.基于MFCC参数和VQ的说话人识别系统[J].仪器仪表学报,2006,27(6):2253-2155.
[8] Zhou Ping, Li Xiaopan, Li Jie,et al. Spe-ech Emotion Recognition Based on Mixed MFCC[C].International Conference on Applied Mechanics and Mechanical Engineering,2012:1252-1258.
[9] 曾祺,甘涛,曾红斌.改进的多窗谱MFCC在说话人确认中的应用[J].计算机系统应用,2014,23(11):192-195.
[10] 吴迪,曹洁,王进花.基于自适应高斯混合模型与静动态听觉特征融合的说话人识别[J].光学精密工程,2013,21(6):1598-1604.
Mixed parameters based on fisher criterion with correlation distance in speaker recognition
In order to get more distinguished characteristic parameters, we utilize a improved multitaper MFCC extraction algorithm which with low variance. On the basis of this, we propose mixed characteristic parameters which combined short-time TEO energy with first-order MFCC that time-domain characteristics and reflecting individual voice dynamic characteristics of the speech signal separately. Due to combing the two parameters directly will result in high dimension parameters and increase the complexity of computational, for this reason, we propose a algorithm for feature selection about fisher criterion with correlation distance. Then, the speaker recognition is based on GMM-UBM classification model. Experiments show that the improved mixed characteristic parameter compared to single characteristic parameters has better recognition results and improving the system recognition rate.
Speaker recognition; multitaper MFCC; fisher criterion with correlation distance; TEO; mixed feature
TN912.34
A
1008-1151(2016)01-0013-04
2015-12-10
国家自然科学基金资助项目(61363005);国家自然科学基金资助项目(61462017);广西研究生教育创新计划资助项目(YCSZ2015152)。
唐宗渤(1986-),男,广西桂林人,桂林电子科技大学信息科技学院教师,助理工程师,研究方向为语音信号处理与智能控制;周萍(1961-),女,广西桂林人,桂林电子科技大学电子工程与自动化学院教授,硕士,研究方向为语音识别与智能控制研究。
王茂蓉(1990-),女,江苏徐州人,桂林电子科技大学电子工程与自动化学院硕士研究生,研究方向为语音识别与反蓄意模仿。
猜你喜欢
车主之友(2022年4期)2022-08-27
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
海峡姐妹(2019年12期)2020-01-14
制造技术与机床(2017年11期)2017-12-18
火控雷达技术(2016年1期)2016-02-06
电测与仪表(2015年7期)2015-04-09
物理实验(2015年9期)2015-02-28
数学年刊A辑(中文版)(2014年4期)2014-10-30
声学技术(2014年2期)2014-06-21
