
基于机器学习的卫星干扰源定位系统
2016-11-11 00:55郝才勇钱宁铁
数字通信世界 2016年10期
郝才勇,钱宁铁
(国家无线电监测中心深圳监测站,深圳 518120)
基于机器学习的卫星干扰源定位系统
郝才勇,钱宁铁
(国家无线电监测中心深圳监测站,深圳518120)
针对卫星干扰源定位系统的自动化程度低,定位质量依赖于操作者的经验,且系统定位性能难以优化的问题,本文提出了基于机器学习的卫星干扰源定位系统,利用定位过程对参数的调整和定位结果的质量指标数据来训练定位系统,学习定位规则和隐含在定位数据中的模式,从而在新的定位任务中具备较好的预测和决策能力,提高系统自动化水平和定位质量。
卫星干扰源;定位;机器学习;邻星推荐
1 引言
机器学习研究的是通过计算手段从数据和经验中学习,提取数据中的重要规则和趋势,从而揭示数据的真实含义并改善系统性能。机器学习在语音和图像识别、垃圾邮件分类、基因诊断、股票预测、网页搜索、商品推荐、异常检测等方面有着广泛的应用[1]。
随着卫星定位技术的发展和卫星定位系统产生和关联数据量的增多,如何理解定位数据并从中提取出有价值的信息,是提高卫星监测和定位技术的关键。卫星干扰源定位系统的定位质量指标主要包括三个部分:定位成功率、定位准确率和定位速度。当前的卫星干扰源定位系统采用的是传统的双星定位系统或三星定位系统,操作者根据干扰信号的特征,输入或选择定位参数来建立定位任务,定位系统根据定位几何方程计算得出干扰源位置。定位系统的自动化程度较低,定位质量在很大程度上依赖于操作者的经验。以邻星选择问题为例,当定位干扰信号时,首先需要选择合适的邻星,邻星选择的优劣往往决定定位成功与否、定位精度的高低和定位结果是否稳定。经验丰富的操作者根据已经掌握的卫星参数知识(如覆盖范围、转发器频段分配、可用参考源等),以及过去在完成类似定位任务时选择邻星经验,可以对新出现的干扰信号定位预测最适合邻星;而对于经验欠缺的操作者,需要对满足可用邻星弧度范围内的多颗甚至数十颗卫星都尝试执行定位任务,才能确定出可用邻星,然后还要对不同主星-邻星组合的定位质量进行对比,才能选择出最合适的邻星。可见,卫星定位系统的邻星选择严重依赖于操作者的知识和经验,非常的耗时耗力。
卫星参数知识和干扰定位经验能够以数据的形式存储在定位系统中,通过机器学习算法,定位系统能够从已经定位的数据中归纳出各种定位规则,如邻星选择规则、参考源选择规则、定位数据异常检测规则、采样带宽/时间选择规则、定位模式(双星/三星定位)规则等。对于没有出现过的干扰信号,定位系统能够利用学习到的定位规则自动预测并为操作者推荐最适合定位参数。随着对干扰信号定位训练次数的增多,定位系统积累的数据和操作经验越来越多,系统学习的预测模型不断进行调整和优化,从而使定位质量指标越来越高。
本文提出了基于机器学习的卫星干扰源定位系统的设计思路,介绍了机器学习在定位系统的各个模块中的具体应用,并以邻星推荐为例详细介绍了一个典型应用。
2 系统功能
卫星干扰源定位系统需要多个功能模块的组合才能完成定位,为了清晰的描述如何将机器学习应用到卫星干扰源定位系统中,按照功能将定位系统拆分为以下八个模块,如表1所示,各个模块均可用机器学习的方法来实现。

表1 功能分解表
3 系统设计
本文以邻星推荐功能为例,具体介绍如何将机器学习应用到定位系统中。在目前的定位系统中,定位参数配置严重依赖于定位操作者所掌握的卫星知识和定位经验。定位系统通过一些基本的定位规则为主要的参数配置提供候选项,操作者根据以往的定位经验从候选项中选择合适的参数来完成定位任务,不同的参数配置决定了定位结果的优劣。
邻星选择是卫星干扰源定位系统的参数配置中的一个关键功能和步骤。邻星是与被干扰卫星(主星)相邻的卫星,与主星同时接收干扰上行信号,然后利用经过主星和邻星转发的两路信号的相关性计算信号的到达时间差或频率差,从而计算干扰源位置[2]。邻星必须满足非常严格的限制条件:在轨道位置上与主星位置间隔在一定弧度范围内;信号所在频段、极化方式与主星上分配情况一致;该频段上的卫星在地面的上行覆盖范围与主星一致;在干扰信号对应的频段上没有在用信号;已知邻星转发器的本振频率等[3]。邻星的选择对完成定位非常重要,但是发现合适的邻星却非常困难。邻星选择的基本规则是邻星与主星位置的弧度间隔要在一定范围内,处理增益为65dB时,C频段要求间隔小于12度,Ku频段要求间隔小于7度,从而保证邻星能够接收到足够强的干扰信号旁瓣。定位系统列出满足此间隔条件的所有邻星(大约10几颗),然后操作者从中选择一颗卫星进行定位。
邻星选择的问题在于并非所有满足弧度间隔条件的邻星都能够成功定位,实际上只有少数邻星能够完成定位。在缺少卫星参数知识和定位经验的情况下,事先并不知道使用哪几颗卫星能够成功定位,因此操作者只能对所有候选的潜在邻星依次尝试定位以确定其可用性。但是,切换邻星却是一个非常耗时和复杂的工作,这需要发送指令给卫星室外控制单元,驱动电机调整卫星天线的俯仰角和极化角,重新配置和调整多个参考源。由于影响邻星选择的因素较多,其中有些参数如卫星的频段随时间变化,因此,即使是具有丰富的卫星知识和定位经验的操作者往往也无法准确的选择最适合的邻星。尤其是随着定位系统采用高增益技术,显著提高了可选邻星的弧度范围(C频段扩展到±40度;Ku频段扩展到±25度),候选邻星的数量增加到到几十多颗,操作员要掌握这么多卫星的特征信息变得极其困难,更加难以选择合适的邻星。
一种邻星推荐算法采用的决策树方法[4]。该方法根据卫星干扰源定位原理和卫星参数知识,事先严格地定义邻星选择的各项规则,通过信息检索的方式逐步筛选和缩小邻星选择范围,最后剩下的卫星满足所有的规则,即为合适的邻星。图1表示的是邻星选择决策树。
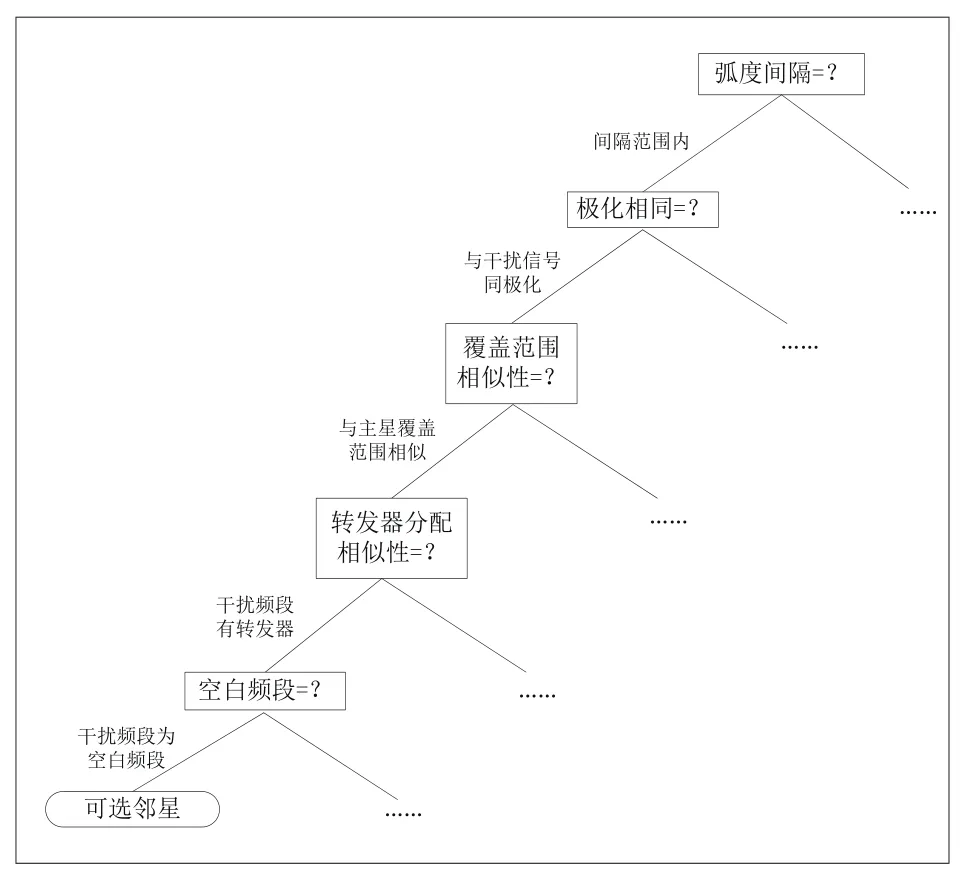
图1 邻星选择决策树
然而,邻星选择决策树仅利用了卫星参数的部分知识,无法利用操作者的经验,不足以选择最合适的邻星。某些定位因素无法通过显式的规则来定义和描述,例如,很难定义导致某些主星-邻星组合定位产生定位点漂移的因素;很难定义导致有些邻星对干扰信号的信噪比要求较高的因素。但是,这些影响因素可以通过定位数据或操作经验反应出来。在实际定位中,有时候即使满足所有的邻星选择规则也无法完成定位;有时候不满足某些邻星选择条件也能完成定位,使用邻星选择决策树定义的规则并不具备准确性和完备性。
为了解决邻星选择决策树不具备邻星推荐的准确性和完备性的问题,采用综合信息推荐方法[5],充分利用卫星参数知识和操作者定位经验,为新出现的干扰信号预测最合适的定位邻星。在实际的卫星干扰信号定位中,操作者的经验往往比定位规则更能反映出有价值的信息。根据定位经验,邻星的选择倾向于采用过去对该主星信号定位时经常能成功定位的那些卫星。若有多颗邻星可以使用,我们往往会选择那些使得可用参考源多、定位结果的精度高和稳定性强的邻星。
为了反映邻星选择对定位结果的影响,需要量化评估定位结果,建立定位性能评分表,如表2所示,将定位结果表现分为6档。
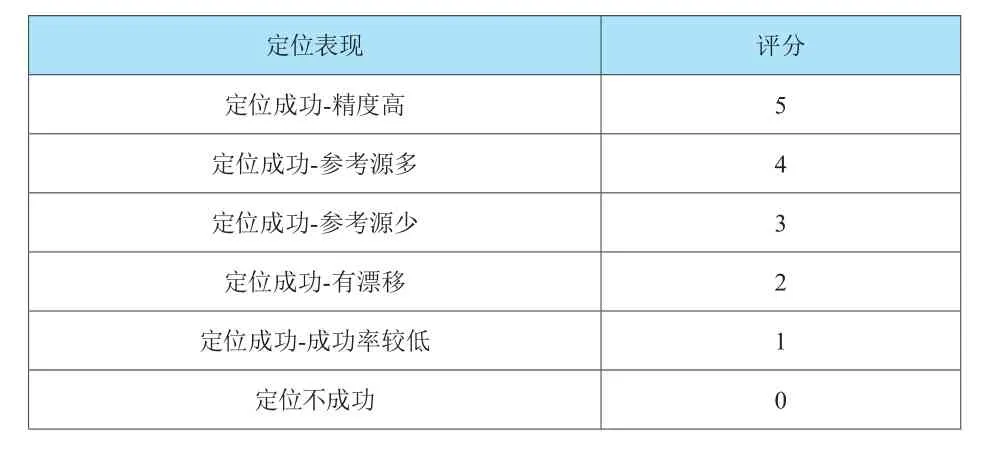
表2 定位性能评分表
每完成一次定位任务,操作者对该次定位结果做一次评分,并记录到定位系统中。在做了多次定位任务之后,可以得到该主星上不同频段所对应的邻星评分表(初始值),如表3所示,在实际定位中选择邻星时,往往并不是尝试了所有潜在邻星,对于没有选择的邻星在表3中用?表示。
为了充分的评估邻星选择对定位结果性能的影响,我们需要得到完整的邻星评分表,这要求对未选择定位的邻星表现评分进行预测,即预测表3中的?数值。根据经验,如果两个邻星的参数特征之间具有较高的相似性,则其定位表现基本一致。因此,如果确定了邻星之间的相似性,就可以通过已知邻星的评分来预测未知邻星的评分。在机器学习中,相似性计算的常用方法有以下两种[6]:
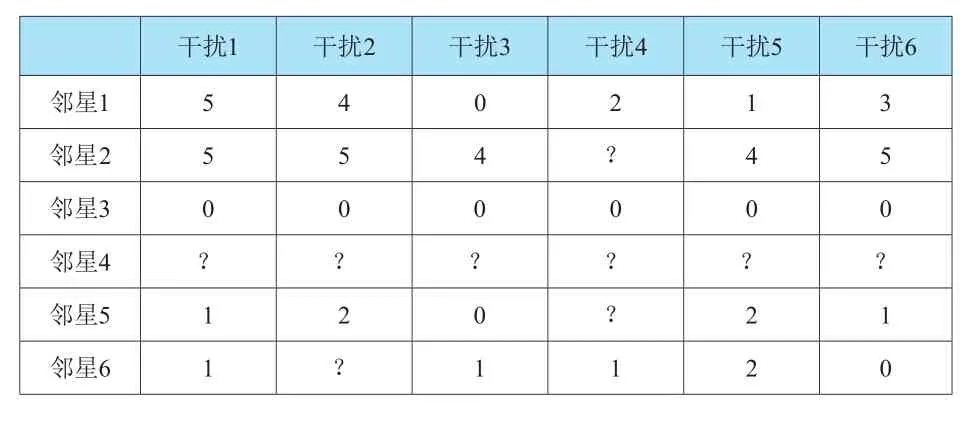
表3 邻星评分表(初始值)
(1)基于内容的相似性。根据影响定位结果表现的卫星特征参数,如卫星位置、极化方式、覆盖范围、频谱分配、卫星倾角等,归纳出卫星的特征向量x,然后计算卫星特征向量x(卫星1)到x(卫星2)…x(卫星n) n≥2之间的距离,选择距离最近的k个卫星,则使用这k个卫星作为邻星的定位表现相近,可用k个已知卫星的评分的平均值来预测剩余的那个未知卫星的评分。
(2)基于联合过滤的相似性。假设某颗主星上的干扰信号使用邻星A定位成功时,使用邻星B也常常能定位成功,则说明邻星A和邻星B具有相似性,可以用邻星A的评分表现来预测邻星B上针对某个信号的评分。
相似性计算是机器学习的过程,积累的卫星特征参数越多,定位操作的次数越多,通过相似性对未知邻星定位性能预测结果越准确。经过相似性计算后得到学习的邻星评分表,如表4所示,用评分值代替了其中的?,并新增加了全局评分,表示为每颗邻星定位结果的累加值。

表4 邻星评分表(学习值)
对于不同的主星,分别计算其对应邻星的全局评分,则可以得到所有卫星选择邻星的定位结果表现的全局矩阵,如表5所示。

表5 卫星评分矩阵
在为干扰信号推荐邻星时,使用卫星评分矩阵,按照评分排名选择分值最大的k个邻星推荐为该干扰所在主星的最佳邻星。例如:在表5的示例中,主星1推荐邻星2和邻星4;主星2推荐邻星4和邻星5.卫星评分矩阵综合利用了卫星参数特征和操作者的经验,反映出实际的选择邻星对定位结果的影响,随着定位操作次数的增多,卫星评分矩阵动态调整趋向于更优化的推荐。
4 结束语
基于机器学习的卫星干扰源定位系统综合利用各种信息,包括卫星知识、定位规则、定位操作者的经验和历史定位数据等,对定位系统的各种相关参数不断的做出调整和更新,随着定位次数的积累,定位性能不断的加强,从而实现快速稳定的发现干扰、提高定位成功率、减少定位时间、增加定位精度等系统优化。通过机器学习训练出性能良好的定位模型需要大量的定位数据积累,数据量的不足是该应用的主要限制因素,这也是目前机器学习在某些应用中面临的挑战。
[1]周志华.机器学习[M].北京:清华大学出版社,2016
[2]David Haworth, Nigel Smith, Riccardo Bardelli, et al. Interference localization for EUTELSAT satellites-the first European transmitter location system[J]. International Journal of Satellite Communications, 1997, 15(3): 155-183.
[3]郝才勇,刘恒.采用空间稀疏性的单星无源定位方法[J].电信科学,2016(4)
[4]杨善林,倪志伟.机器学习与智能决策支持系统[M].科学出版社,2006
[5]Alpaydin, Ethem. Introduction to machine learning[M]. MIT press, 2014.
[6]Mcfee B, Lanckriet G. Learning Multi-modal Similarity[J]. Journal of Machine Learning Research, 2011: 491-523.
Satellite Interference Geolocation System Based on Machine Learning
Hao Caiyong, Qian Ningtie
(Shenzhen Station of State Radio Monitoring Center, Shenzhen, 518120)
To address the problem of low automation level in satellite interference geolocation system,geolocation quality depends on the operator's experience, and the difficult of system performanceoptimization,proposed satellite interference geolocation system based on machine learning. Leverages the parameters adjustment in geolocation procedure and the quality indicators of location result to train geolocation system, learn geolocation rules and potential patterns from the location data. Then the system achieves better prediction and decision-making capacity for the new geolocation tasks, and improves the automation degree and geolocation quality.
satellite interference; geolocation; machine leaning; adjacent satelliterecommendation
10.3969/J.ISSN.1672-7274.2016.10.015
TN927文献标示码:A
1672-7274(2016)10-0052-04
郝才勇,男,1985年生,硕士,国家无线电监测中心深圳监测站工程师,主要研究卫星定位与无线电监测。钱宁铁,男,1970年生,硕士,国家无线电监测中心深圳监测站副站长,主要研究无线电监测与管理。
猜你喜欢
电气技术(2021年3期)2021-03-26
通信电源技术(2020年22期)2020-03-27
无线互联科技(2018年20期)2018-12-27
电子制作(2017年10期)2017-04-18
温州医科大学学报(2016年9期)2016-10-31
电信科学(2016年9期)2016-06-15
中国交通信息化(2016年5期)2016-06-06
现代工业经济和信息化(2016年8期)2016-05-17
工业设计(2016年6期)2016-04-17
哈尔滨医药(2015年4期)2015-12-01
