
电能表健康度分析及整体运行状态预测方法
2016-11-10 09:28肖坚红赵永红薛晓茹孙承露吴少雄武文广
电网与清洁能源 2016年7期
肖坚红,赵永红,薛晓茹,孙承露,吴少雄,武文广
(1.国网安徽省电力公司,安徽合肥 230022;2.北明软件有限公司,北京 110011;3.南瑞集团公司/国网电力科学研究院,江苏南京 211106)
电能表健康度分析及整体运行状态预测方法
肖坚红1,赵永红1,薛晓茹1,孙承露2,吴少雄3,武文广3
(1.国网安徽省电力公司,安徽合肥230022;2.北明软件有限公司,北京110011;3.南瑞集团公司/国网电力科学研究院,江苏南京211106)
通过基于“厂商+批次”对电能表整体运行状态进行分析,不仅可以发现电能表的运行故障率呈现出明显的层次分布,同时还能发现家族性的问题或者缺陷,实现基于传统的人工经验诊断转变为基于机器学习智能分析预测。第一阶段:以厂商和生产批次为对象,通过对电能表状态的故障率、报废费和折旧率进行分析,将所有电能表的分析数据降维整合为“非健康度曲线”的一维数据,且利用散点图将分析对象非健康值展现。不仅能告诉我们每个批次电能表的现状,还能告诉我们哪些批次存在问题,根据不同的预警等级,确定电能表故障的严重性。第二阶段:通过对电能表工作状态和工作环境实时监测,借助机器学习中线性回归的算法,诊断、预测电能表的实际运行状态,预测电能表非健康度值变化趋势。基于上述二个阶段的分析,为电能表状态检修、备品备件等工作提供辅助决策依据。
非健康值;线性回归;数据挖掘分析;整体状态分析
随着2009年安装的智能电能表在现场的运行时间超过5 a,为满足供电公司对电能表的运行状况进行在线监控、综合分析和状态评估,合理地制订校表和轮换计划。在充分利用用电信息采集系统的计量装置在线监测与智能诊断的分析成果基础上,结合营销业务系统、计量生产调度平台的相关数据,基于大数据平台,数据挖掘和机器学习分析方法,在数据挖掘平台建模分析、评估电能表运行的整体状态和变化趋势。
1 实现原理
国网安徽省电力公司拥有2 500万只电能表,如何管理好这些电能表,目前是根据DL/T448-2000《电能计量装置技术管理规程》要求将电能表分为五类等级,I、II、III类电能表开展现场校验和定期轮换相结合,IV、V采用定期轮换。然而,通过现场校验和定期轮换来管理这些表,会存在部分电能表未到期就已出现质量问题,还有部分电能表质量较好,更换较早。安徽省电力公司利用数据挖掘技术,并基于大数据平台实现数据预处理和分析指标快速统计,通过建模分析统计电能表的非健康值,利用机器学习的线性回归算法对电能表未来的非健康值进行预测分析。实现基于“厂商+批次”对电能表整体运行状态进行分析,不仅可以发现电能表的运行故障率呈现出明显的层次分布,同时还能发现家族性的问题或者缺陷,实现由“经验驱动”转向“数据驱动”,由“计划检修”转向“状态检修”。
2 数据进行降维处理
1)原始指数据的标准化采集。p维随机向量x=(x1,x2,…,xp)T。n个样品,xi=(xi1,xi2,…,xip)T,i= 1,2,…,n,n>p构造样本阵,对样本进行如下标准化变换:

2)对标准化阵Z求相关系数矩阵。
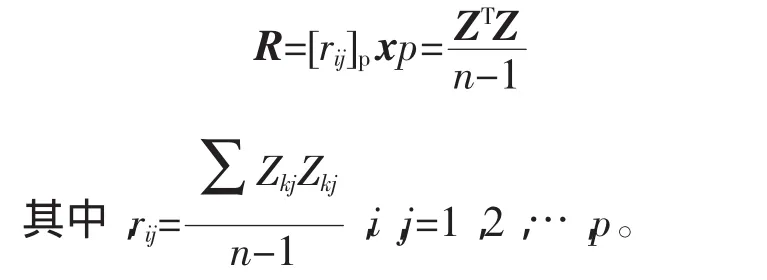
3)解样本相关矩阵R的特征方程|R-λIp|得p个特征根,确定主成分。
4)将标准化后的指标变量转换为主成分。

5)对m个主成分进行综合评价。对m个主成分进行加权求和,即得最终评价值,权数为每个主成分的方差贡献率。
3 各批次电能表的非健康值分布
3.1统计平均数法(Statistical average method)
统计平均数法是根据所选择的各位专家对各项评价指标所赋予的相对重要性系数,分别求其算术平均值,计算出的平均数作为各项指标的权重。其基本步骤是:
1)确定行业专家进行初评。将待定的电能表运行状态、报废费和折旧率权数的指标提交给各位专家,并请专家在不受外界干扰的前提下独立地给出各项指标的权数值。
2)回收专家意见。将各位专家的数据收回,并计算电能表整体运行状态涉及的各项指标的权数均值和标准差。
3)分别计算电能表整体运行状态各项指标权重的平均数。
3.2非健康值的计算公式
非健康值的计算公式为K=K1S1+K2S2+K3S3+K4S4(Si,变量;Ki,该变量对应的权重)
式中:S1,故障率;K1,故障率权值(故障包括电表倒走,电能表反向潜动等等);S2,待报废率;K2,待报废率权值;S3,报废率;K3,报废率权值;S4,折旧率;K4,折旧率权值。
3.3min-max标准化(Min-Max Normalization)
通过min-max标准化对原始数据的线性变换,使结果值映射到[0-1]之间。转换函数如下:

式中:max为样本数据的最大值;min为样本数据的最小值。转化后通过散点图展现如图1所示。
1)图1是电能表整体运行状态分析的散点图,纵坐标代表非健康度权值(越往上代表电能表运行状态越不健康),横坐标代表批次采购的时间(越往右代表采购时间越新。

图1 电能表整体运行状态分析散点图Fig.1 The scatter diagram of the overall running status analysis of energy meters
2)从这个图可以清晰看到大部分批次是遵循稳定变化的规律,即采购时间越早的批次,非健康权值越高;采购时间越晚的批次,非健康度权值越低。同一时间采购的不同厂商批次由于质量问题,也存在非健康值较大的差异。
3)处于“1”的批次是应该优先纳入计划轮换的批次;处于“2”的批次是重点关注的批次,这些批次采购时间比较晚(既运行时间不长),但存在非健康值偏高,甚至超过采购时间较早的批次,属于产品质量存在问题,计量人员应该及时予以处理。
4)处于“3”的批次是采购时间比较早,但运行相对稳定,目前处理“健康区”和“亚健康区”的范围,也属于重点关注批次,通过回归预测,判断健康度变化趋势,为轮换计划和备品备件提供参考依据。
5)处于“4”的批次都属于健康区间的批次,只是采购时间不同,由于“5”是最新采购的批次,所以非健康权值最低。
4 多元线性回归分析预测算法对健康值进行预测
4.1模型的建立
y=b0+b1x1+b2x2+…+bkxk+ey,其中,b0为常数项,ey是随机误差,b1,b2,…,bk为回归系数,b1为x2,x3,…,xk固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为x1,xk固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等。
4.2多元性回归模型的参数估计
同一元线性回归方程一样,也是在要求误差平方和(∑e2)为最小的前提下,用最小二乘法求解参数。以二元线性回归模型为例,求解回归参数的标准方程组为

解此方程可求得b0,b1,b2的数值。亦可用下列矩阵法求得
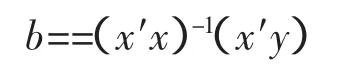
4.3多元线性回归模型的检验
多元性回归模型与一元线性回归模型一样,在得到参数的最小二乘法的估计值之后,也需要进行必要的检验与评价,以决定模型是否可以应用。
4.3.1拟合程度的测定
与一元线性回归中可决系数r2相对应,多元线性回归中也有多重可决系数r2,它是在因变量的总变化中,由回归方程解释的变动(回归平方和)所占的比重,R2越大,回归方各对样本数据点拟合的程度越强,所有自变量与因变量的关系越密切。计算公式为:
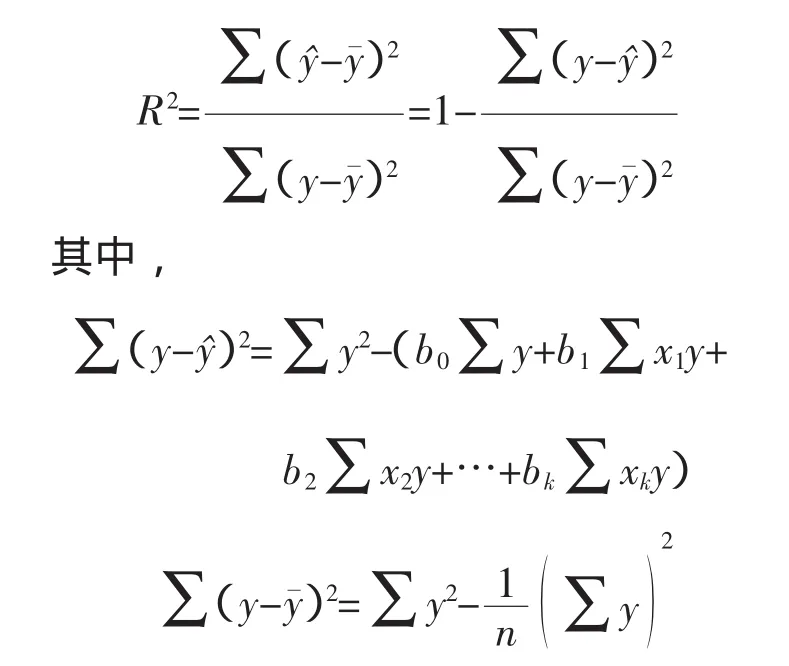
4.3.2估计标准误差
估计标准误差,即因变量y的实际值与回归方程求出的估计值yˆ之间的标准误差,估计标准误差越小,回归方程拟合程度越强。

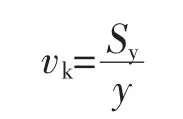
式中:k为多元线性回归方程中的自变量的个数。
4.4回归方程的显著性检验
回归方程的显著性检验,即检验整个回归方程的显著性,或者说评价所有自变量与因变量的线性关系是否密切。能常采用F检验,F统计量的计算公式为:

根据给定的显著水平a,自由度(k,n-k-1)查F分布表,得到相应的临界值Fa,若F>Fa,则回归方程具有显著意义,回归效果显著;F<Fa,则回归方程无显著意义,回归效果不显著。
4.5回归系数的显著性检验
在一元线性回归中,回归系数显著性检验(t检验)与回归方程的显著性检验(F检验)是等价的,但在多元线性回归中,这个等价不成立。t检验是分别检验回归模型中各个回归系数是否具有显著性,以便使模型中只保留那些对因变量有显著影响的因素。检验时先计算统计量ti;然后根据给定的显著水平a,自由度n-k-1查t分布表,得临界值ta或ta/2,t>t-a或ta/2,则回归系数bi与0有显著关异,反之,则与0无显著差异。统计量t的计算公式为:

其中,Cij为多元线性回归方程中求解回归系数矩阵的逆矩阵(x′x)-1的主对角线上的第j个元素。对二元线性回归而言,可用下列公式计算:
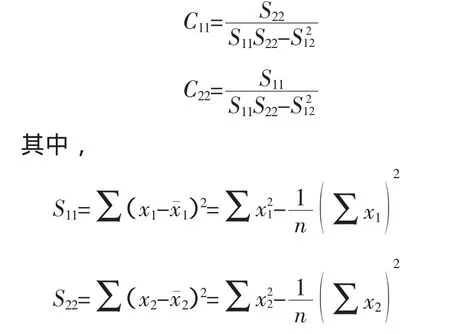

4.6多重共线性判别
若某个回归系数的t检验通不过,可能是这个系数相对应的自变量对因变量的影响不显著所致,此时,应从回归模型中剔除这个自变量,重新建立更为简单的回归模型或更换自变量。也可能是自变量之间有共线性所致,此时应设法降低共线性的影响。
多重共线性是指在多元线性回归方程中,自变量之间有较强的线性关系,这种关系若超过了因变量与自变量的线性关系,则回归模型的稳定性受到破坏,回归系数估计不准确。需要指出的是,在多元回归模型中,多重共线性是难以避免的,只要多重共线性不太严重就行了。判别多元线性回归方程是否存在严重的多重共线性,可分别计算每2个自变量之间的可决系数r2,若r2>R2或接近于R2,则应设法降低多重线性的影响。亦可计算自变量间的相关系数矩阵的特征值的条件数k=λ1/λp(λ1为最大特征值,λp为最小特征值),k<100,则不存在多重共线性;若100≤k≤1 000,则自变量间存在较强的多重共线性,若k>1 000,则自变量间存在严重的多重共线性。降低多重共线性的办法主要是转换自变量的取值,如变绝对数为相对数或平均数,或者更换其他的自变量。
5 结语
该技术有利于国网安徽省电力公司保证电能表准确计量,节约人工维护成本和保证设备最大合理的使用寿命,通过预测整体电能表运行变化趋势,提前发现问题,为公司挽回了经济损失,取得效果。
[1]李绪增,冯祖洪.数据整合技术在高校数字化校园建设中的应用[J].现代电子技术,2007,30(18):105-109.LI Xuzeng,FENG Zuhong.Application of data consolidation in high school digitization campus construction[J].Modern Electronics Technique,2007,30(18):105-109.
[2]宇文肖娣.电力用户用电信息采集系统的研究与应用[D].保定:华北电力大学硕士学位论文,2011.
[3]黄杰晟,曹永锋.挖掘类改进决策树[J].现代计算机(专业版),2010(1):38-41.HUANG Jiesheng,CAO Yongfeng.Mining improved decision tree[J].Modern Computer(Professional Edition),2010(1):38-41.
[4]李净,张范,张智江.数据挖掘技术与电信客户分析[J].信息通信技术,2009,3(5):43-47.LI Jing,ZHANG Fan,ZHANG Zhijiang.Data mining technology and telecom customer analysis[J].Information and Communications Technologies,2009,3(5):43-47.
[5]李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.LI Xinhai.Using“random forest”for classification and regression[J].Chinese Bulletin of Entomology,2013,50(4):1190-1197.
[6]尚丹丹.基于虚拟机的Hadoop分布式聚类挖掘方法研究与应用[D].哈尔滨:哈尔滨理工大学,2015.
[7]詹绍康.正确应用相关回归分析[J].环境与职业医学,1997(4):238-239.ZHAN Shaokang.Correct application of correlation regression analysis[J].Journal of Labour Medicine,1997(4):238-239.
[8]JIAWEI HAN(加).数据挖掘概念与技术[M].北京:机械工业出版社,2006.
[9]毛国君.数据挖掘原理与算法[M].北京:清华大学出版社,2007.
(编辑徐花荣)
Analysis of the Health Degree of Electric Energy Meters and the Prediction Method of the Overall Running Status
XIAO Jianhong1,ZHAO Yonghong2,XUE Xiaoru1,SUN Chenglu2,WU Shaoxiong3,WU Wenguang3
(1.State Grid Anhui Electric Power Company,Hefei 230022,Anhui,China;2.Beiming Software Co.,Ltd.,Beijing 110011,China;3.NARI Technology Development Co.,Ltd.,Nanjing 211106,Jiangsu,China)
Through the comprehensive analysis of the overall running status of energy meters based on“Manufacturer plus Batch”pattern,we can find that the operation fault ratio of the energy meters has obvious layered distribution,and the problems or defects have family characteristics.This analysis helps to change the diagnostic method based on the traditional human-based experience into the machine-based learning intelligent analysis and forecasting.The first stage:with manufacturer and production batch as the object,the fault rates,scrap costs and depreciation rate of the energy meter status are analyzed and then all the analysis data of the energy meters are integrated into one-dimension data through the dimension reduction process,and the scatter plot is used for the nonhealth value show for the analysis object.This process not only shows the current status of each batch of energy meters,but also tells us which batch(or batches)has problems and identify seriousness of the meter fault by different warning degrees.The second stage:though the real-time monitoring of the working status and the working environment of the energy meter,the actual running state of the meter is diagnosed and predicted by the linear regression algorithm in the machine learning,and the change trend of the non health value of the electric energy meter is also predicted.Based on the analysis of the two stages,this paper can provide certain supplementary decision-making basis for status maintenance of energy meters and purchasing of spare parts.
the non-health value;linear regression;data mining analysis;overall state analysis
1674-3814(2016)07-0077-04
TM769
A
国家电网公司科技项目“支撑互动用电服务的用电信息采集系统技术研究及应用”(524608150061)。
Project Supported by Science and Technology Project of State Grid Corporation of China:Research andApplicationofPower Utilization Information Acquisition System for Supporting Interactive Service(524608150061).
2016-05-04。
肖坚红(1964—),女,本科,高级工程师,从事电能计量装置检测与用电信息采集管理及业务研究;
孙承露(1991—),女,本科,工程师,从事数据挖掘、大数据分析工作;
吴少雄(1984—),女,硕士,工程师,从事用电采集系统相关研究和开发;
武文广(1981—),男,硕士,工程师,从事用电信息采集系统及相关产品需求分析、系统设计方面的工作。
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
广西植物(2021年1期)2021-03-24
科学与财富(2021年3期)2021-03-08
中学生数理化·中考版(2019年12期)2019-09-23
温州大学学报(自然科学版)(2019年2期)2019-06-04
现代商贸工业(2019年5期)2019-02-18
统计与决策(2018年14期)2018-08-22
江苏农业科学(2017年10期)2017-07-21
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
山东工业技术(2016年15期)2016-12-01
